RAII的英文全拼是Resource Acquisition Is Initialization的简称,利用的就是C++构造的对象最终会被销毁的原则。在构造时获取对应的资源,在对象声明周期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。—其实就是构造申请内存,析构的时候释放 这个过程
堆heap,动态分配内存的区域,这个堆跟数据结构里的堆不是一回事(自己初学的时候搞混过)。堆的内存 malloc申请 必须手动free释放。
C++ 标准里一个相关概念是自由存储区,英文是 free store(其实就是之前内存分配学的 内存池的可用部分),特指使用 new 和 delete 来分配和释放内存的区域。new 和 delete 操作的区域是 free store ,malloc 和 free 操作的区域是 heap。
栈stack,指函数调用过程中产生的局部变量所在的区域,这个栈和数据结构中的栈高度相似 都满足后入先出。
堆
auto ptr = new std::vector();
调用expression new申请一个vector的堆上内存,先调用op new(底层调用 malloc)申请内存,再调用 placement new在已申请的堆上内存构造对象。
void foo(){bar* ptr = new bar();…delete ptr;}
很简单的new和delete,但是中间省略的代码有两种可能导致delete ptr无法执行,导致内存泄漏
1 中间省略的代码抛出异常导致最后的delete ptr无法执行
2 这个代码不符合c++的惯用法,在c++里有99%的可能性不需要堆上内存,因为其new和delete在同一个{}域内,用局部变量(栈上内存)就行了。
更常见也更合理的c++代码,new分配内存和free释放内存不写在一个函数中
栈
下面用一段代码来说明c++里函数调用、本地变量如何使用栈。其具体过程取绝于OS架构,具体细节可能不同但是原理上相同都是后入先出
void foo(int n){…}void bar(int n){int a = n + 1;foo(a);}int main(){…bar(42);…}
main中调用bar(42)后栈内的变化如下图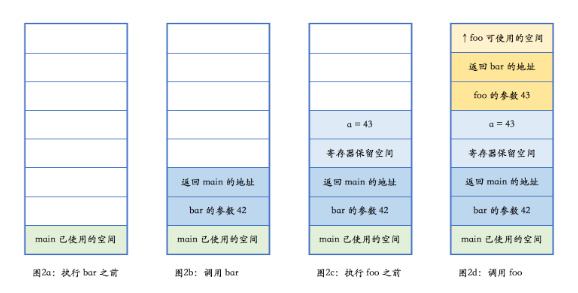
在x86以及其他架构中栈内存是向低地址增长的,所以上图的上部为低地址。上图中有颜色的部分叫做栈帧(stack frame),GCC CLANG的命令行参数中提到fomit-frame-pointer一般就是指栈帧。
栈的变化,首先将调用的bar函数的实参由右向左压栈(c++编译器一般从右到左压栈),bar只有一个最左实参42压栈。再将bar函数的返回地址压栈(main bar函数的下一行语句的地址),上面的栈是main函数的栈。
进入bar函数,将会为bar函数分配其专属栈空间(但是空间上还是连续的,main的栈顶就是bar的栈底),进入bar函数 申请bar函数的局部变量a(调整栈指针 分配出—划出函数内的局部变量所需的空间 局部变量的内存就在栈上和函数执行所需要的其他数据在一起 当函数执行完成后这些局部变量内存也和函数的其他保存记录一起释放)…执行语句如果遇到函数一样像上面一样开新的函数栈,如果遇到return ,esp(执行指针)指回深层函数的栈底(浅层函数的栈顶),接着就是从弹出的返回地址恢复现场。
栈上内存的分配极为简单,就是向低地址移动栈指针。栈上内存的释放也极为简单。函数结束时向高地址移动栈指针,由于后进先出的执行过程不可能出现内存碎片(申请—向低地址移,函数结束(作用域结束)—向高地址移)。
上面例子中的局部变量为简单类型(int float…)在c++中称为POD类型(Plain Old Data),对于非POD的对象(class)类型的局部变量一样堆在栈上分配,编译器会在代码的合适位置插入构造(创建对象时 不是直接就是调用构造函数)和析构的调用。 尤其重要的是编译器会自动调用栈上对象的析构函数(临时对象的生命周期只在那一行语句,那行语句结束自动调用析构 普通局部对象的生命周期在作用域结束自动调用析构 在函数执行发生异常时也会自动调用析构),对于异常时的析构函数调用有一个专门的术语叫栈展开(stack unwinding)
补充 MSCV编译含异常的c++代码需要 调用命令时指定EHsc参数
下面这段代码演示栈展开
#include <stdio.h>//puts函数类似于 cout输出字符串class Obj {public:Obj() { puts("Obj()"); }~Obj() { puts("~Obj()"); }};void foo(int n){Obj obj;if (n == 42)throw "life, the universe and everything";//故意在n=42抛出一个字符串}int main(){try {foo(41);foo(42);}catch (const char* s) {//n = 42时抛出的字符串 会被这里捕获puts(s);}}
执行的结果
Obj()
~Obj()//foo函数结束 其中obj对象自动析构
Obj()
~Obj()//发生throw 函数提前结束 obj对象自动析构
life, the universe and everything
foo(42)顺序 构造函数-throw-析构函数-catch内容
编译器的自动析构机制 保证了不管是否发生异常obj的析构函数都会自动执行
RAII
c++虽然支持将对象保存在栈上,但是很多情况下,对象不能,或不应该存在栈上。1 对象很大 2 对象的大小在编译时不能确定只能运行到了才知道 3 对象作为函数的返回值(如果返回的是 栈上对象 则在函数结束后自动析构了 并没有意义 所以一定要返回堆上对象的指针或引用)
例如下面这个工厂模式的例子,函数返回的是堆上对象的指针 这是正确的
enum class shape_type {circle,triangle,rectangle,…};class shape { … };class circle : public shape { … };class triangle : public shape { … };class rectangle : public shape { … };shape* create_shape(shape_type type){//返回的类型设置为父类指针 实际返回的是子类对象地址//父类指针指向子类对象--c++中的多态 使用返回的父类指针会优先调用所指向子类内的成员…switch (type) {case shape_type::circle:return new circle(…);case shape_type::triangle:return new triangle(…);case shape_type::rectangle:return new rectangle(…);…}}
如果返回类型是 shape(直接返回shape而不是shape),实际却返回一个 circle,编译器不会报错,但结果多半是错的。这种现象叫对象切片(object slicing),是 C++ 特有的一种编码错误。这种错误不是语法错误,而是一个对象复制相关的语义错误,也算是 C++ 的一个陷阱了
因为create_shape返回的是堆上内存,我们必须要保证要及时delete以防止内存泄漏。*我们可以利用栈上对象的栈展开行为来自动调用析构函数,但这是个堆上对象,如何变为栈上对象,只需要像下面的例子将堆上对象包装一层,并在包装类的栈上对象的析构函数中释放堆上对象内存,这样在栈对象生命作用域结束堆上内存自动析构,就不会发生内存泄漏。—挺聪明的做法 保证堆上内存在栈上包装对象的作用域结束后 也一起结束,
//传入堆上内存 构造栈上对象,栈上对象在函数结束自动析构,在析构中会释放堆上内存
class shape_wrapper {public:explicit shape_wrapper(shape* ptr = nullptr): ptr_(ptr) {}//ptr 是在外部从堆上申请的内存~shape_wrapper(){// shape_wrapper类型的栈上对象的生命周期结束时的栈展开,会自动调用这个析构函数,析构函数就将之前的堆上内存释放了//回收外部申请的内存ptrdelete ptr_;//delete 先调用*ptr的析构函数 在调用op delete--frees释放内存}shape* get() const { return ptr_; }private:shape* ptr_;};void foo(){…shape_wrapper ptr_wrapper(create_shape(…));//传入堆上内存 构造栈上对象,栈上对象在函数结束自动析构,在析构中会释放堆上内存…}
类似于shape_wrapper和其析构行为,这就是RAII的基本用法(shape_wrapper 差不多就是个最简单的智能指针了),这种清理不限于释放堆上内存,也可以
1 析构时关闭文件 fstream的析构就会这么做
2 析构时释放同步锁
3 析构时释放其他重要的系统资源
合理的做法
std::mutex mtx;void some_func(){//在使用互斥锁时我们就因该像shape_wrapper包装堆上内存一样使用guard去包装互斥锁std::lock_guard<std::mutex> guard(mtx);// 做需要同步的工作}//不合理的做法std::mutex mtx;void some_func(){mtx.lock();// 做需要同步的工作……// 如果发生异常或提前返回,// 下面这句不会自动执行。// 发生异常 互斥锁不会被释放 没有线程能拿到锁 将产生饿死 不断地死循环mtx.unlock();}
补充回忆侯捷老师讲expression new/delete时所会做的事
// new circle(…){//先申请内存再构造void* temp = operator new(sizeof(circle));try {circle* ptr =static_cast<circle*>(temp);ptr->circle(…);//这么调用构造函数并不是合法的c++ 只有exp new能这么做return ptr;}catch (...) {operator delete(ptr);throw;}}//deleteif (ptr != nullptr) {//先析构 再调用op deleteptr->~shape();// 这么调用析构okoperator delete(ptr);}
—本节课的思考和总结
1 凡生命周期超出当前函数的,一般需要用堆(或者使用对象移动传递)。反之,生命周期在当前函数内的,就该用栈。
2 全局静态和局部静态的变量是存储在哪个区域?看很多书是静态存储区,但静态存储区又是什么区?堆?
静态存储区既不是堆也不是栈,而是……静态的。意思是,它们是在程序编译、链接时完全确定下来的,具有固定的存储位置(暂不考虑某些系统的地址扰乱机制)。堆和栈上的变量则都是动态的,地址无法确定。3 thread local的变量存储在哪个区?因为线程是动态创建的,理解这个变量内存也应该动态分配的,线程结束内存自动释放?难道也是堆?
thread_local和静态存储区类似,只不过不是整个程序统一一块,而是每个线程单独一块。用法上还是当成全局/静态变量来用,但不共享也就不需要同步了。
4 类的大小是怎么定的呢?一般都是看类的成员变量占用字节数再根据是否虚类看是否加4字节(虚函数表指针),但是类里面有很多成员函数,这些成员函数不占空间吗,如果有静态成员变量或者静态成员函数呢?
非静态数据成员加上动态类型所需的空间。注意后者不一定是4,而一般是指针的大小,在64位系统上是8字节。还有,要考虑字节对齐的影响。静态数据成员和成员函数都不占个别对象的空间。
5 C++中一个空类class A {};的大小是多少
1个字节, 如果一个空类被继承,它在子类里不占任何字节。从这个意义上说,在C++里私有继承比组合更加经济。
6 为什么c++中的强制类型转换要用xxx_cast而不用(类型)这种c语言中的强转方法
static_cast:这是一种常用且相对安全的转换方式,常见场合:不同类型的整数之间转换,void* 到特定类型指针的转换,父类指针到子类指针的转换(可能进行偏移量修正),强制调用类里的 operator 类型 转换函数。
const_cast:专门用来去掉 const 或 volatile 修饰的类型转换,主要用在调用 const 不正确的 C 接口上。
dynamic_cast:C++ 专有的转换方式,用来安全地把父类的指针或引用转换成子类的指针或引用。会判断实际的运行期类型是否满足要求,不满足时转换失败,得到空指针(指针的情况)或异常(引用的情况)。
reinterpret_cast:最不安全的转换方式,让编译器不管三七二十一硬转,很可能会得到错误的结果,也可能跟编译器的优化打架。
很明显,这些转换的安全程度不一,取不同的名字意图更明显,也便于搜索,可以方便在代码出问题的时候进行查找。很多 C++ 编码规范里不允许使用 C 风格的强制类型转换,并可能禁用某些类型的转换,特别是 reinterpret_cast,通常不允许使用。

若有收获,就点个赞吧
0 人点赞
