2.1 模型表示
回归问题:预测真实值输出
分类问题:预测离散值输出
线性回归是监督学习问题
- m=训练样本的数量
- x=输入变量/输入特征
- y=输出变量/目标变量
- (x,y)=一个训练样本
- Hypothesis:假设函数h(x)=Θ_0+Θ_1*x
- 参数:Θ_0, Θ_1
- 代价函数:平方误差函数/平方误差代价函数J(Θ_0,Θ_1)
2.2 代价函数

J(Θ_0,Θ_1)代价函数即等高线图
2.3 梯度下降
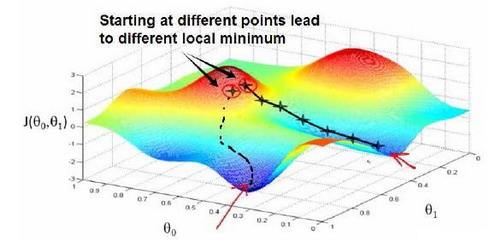
如果起始点偏移了一些,就会得到一个完全不同的局部最优解

- 其中是
 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=a&id=v3wzI)学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=a&id=v3wzI)学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。 - 计算完同时更新Θ_0,Θ_1才是正确实现方法,注意右侧的错误方法,这会导致计算Θ_1时使用更新后的Θ_0,导致计算错误。
- 如果
 太小,即学习速率太小,它会需要很多步才能到达全局最低点。
太小,即学习速率太小,它会需要很多步才能到达全局最低点。 - 如果
 太大,那么梯度下降法可能会越过最低点,一次次越过最低点,会导致无法收敛,甚至发散。
太大,那么梯度下降法可能会越过最低点,一次次越过最低点,会导致无法收敛,甚至发散。
2.4 线性回归的梯度下降
数据量较大的情况下,梯度下降法比正规方程 (normal equations) 要更适用一些。

若有收获,就点个赞吧
0 人点赞
