编码——解码
Encoder-Decoder是一个模型构架,是一类算法统称,并不是特指某一个具体的算法,在这个框架下可以使用不同的算法来解决不同的任务。首先,编码(encode)由一个编码器将输入序列转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标译文。
回顾一下,算法设计的基本思路:将现实问题转化为一类可优化或者可求解的数学问题,利用相应的算法来实现这一数学问题的求解,然后再应用到现实问题中,从而解决了现实问题。(比如,我们想解决一个词性标注的任务(现实问题),我们转化成一个BIO序列标注问题(数学模型),然后设计一系列的算法进行求解,如果解决了这个数学模型,从而也就解决了词性标注的任务)。
Encoder :编码器,如下: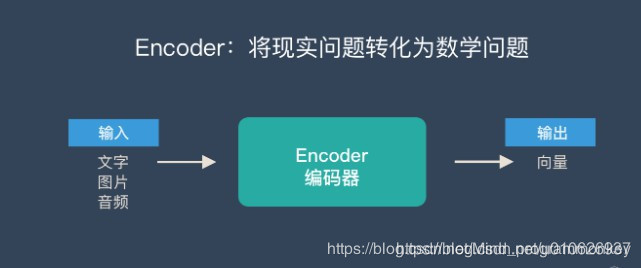
Decoder:解码器,如下:

合并起来,如下: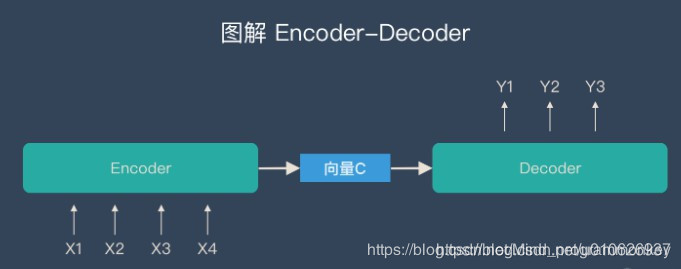
几点说明
不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
信息丢失的问题
通过上文可以知道编码器和解码器之间有一个共享的向量(上图中的向量c),来传递信息,而且它的长度是固定的。这会产生一个信息丢失的问题,也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。如果编码过程产生的不是一个固定长度的向量而是一系列向量,是不是会保留更多的信息呢。

若有收获,就点个赞吧
0 人点赞
