Prometheus 是一个开源监控系统,它本身已经成为了云原生中指标监控的事实标准 。
k8s集群监控体系演变史
第一版本:Cadvisor+InfluxDB+Grafana
只能从主机维度进行采集,没有Namespace、Pod等维度的汇聚功能
第二版本: Heapster+InfluxDB+Grafana
heapster负责调用各node中的cadvisor接口,对数据进行汇总,然后导到InfluxDB , 可以从cluster,node,pod的各个层面提供详细的资源使用情况。
第三版本:Metrics-Server + Prometheus
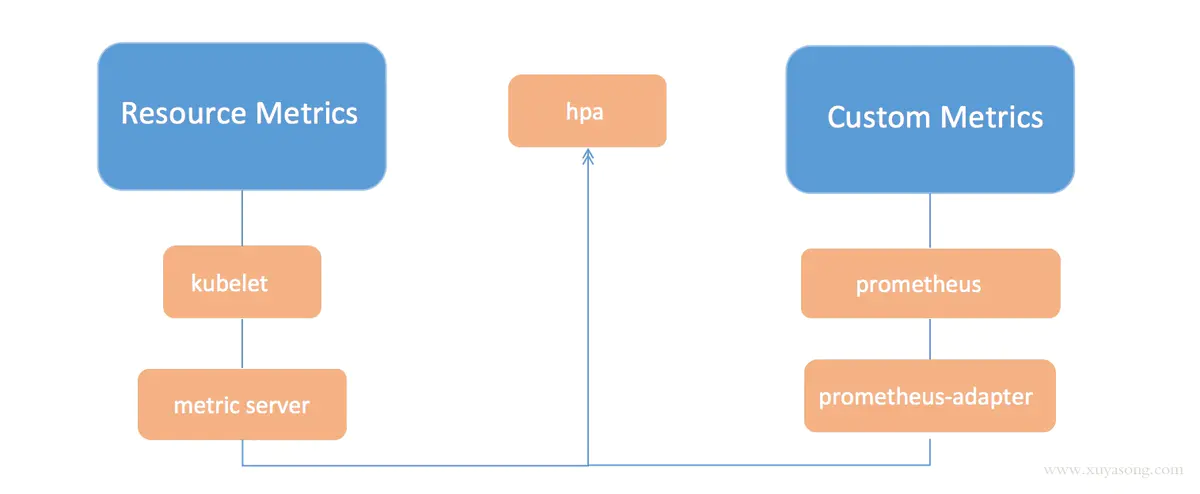
k8s对监控接口进行了标准化,主要分了三类:
Resource Metrics
对应的接口是 metrics.k8s.io,主要的实现就是 metrics-server,它提供的是资源的监控,比较常见的是节点级别、pod 级别、namespace 级别、class 级别。这类的监控指标都可以通过 metrics.k8s.io 这个接口获取到
Custom Metrics
对应的接口是 custom.metrics.k8s.io,主要的实现是 Prometheus, 它提供的是资源监控和自定义监控,资源监控和上面的资源监控其实是有覆盖关系的。
自定义监控指的是:比如应用上面想暴露一个类似像在线人数,或者说调用后面的这个数据库的 MySQL 的慢查询。这些其实都是可以在应用层做自己的定义的,然后并通过标准的 Prometheus 的 client,暴露出相应的 metrics,然后再被 Prometheus 进行采集
External Metrics
对应的接口是 external.metrics.k8s.io。主要的实现厂商就是各个云厂商的 provider,通过这个 provider 可以通过云资源的监控指标
Prometheus架构

Prometheus Server
监控、告警平台核心,抓取目标端监控数据,生成聚合数据,存储时间序列数据
exporter
由被监控的对象提供,提供API暴漏监控对象的指标,供prometheus 抓取
node-exporter
blackbox-exporter
redis-exporter
mysql-exporter
custom-exporter
…
pushgateway
提供一个网关地址,外部数据可以推送到该网关,prometheus也会从该网关拉取数据
Alertmanager
接收Prometheus发送的告警并对于告警进行一系列的处理后发送给指定的目标
Grafana
配置数据源,图标方式展示数据
Prometheus时间序列数据库(TSDB)
# http://localhost:9090/metrics$ kubectl -n monitor get po -o wideprometheus-dcb499cbf-fxttx 1/1 Running 0 13h 10.244.1.132 k8s-slave1$ curl http://10.244.1.132:9090/metrics...# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.# TYPE promhttp_metric_handler_requests_total counterpromhttp_metric_handler_requests_total{code="200"} 149promhttp_metric_handler_requests_total{code="500"} 0promhttp_metric_handler_requests_total{code="503"} 0
tsdb(Time Series Database)
其中#号开头的两行分别为:
HELP开头说明该行为指标的帮助信息,通常解释指标的含义
TYPE开头是指明了指标的类型
- counter 计数器
- guage 测量器
- histogram 柱状图
-
其中非#开头的每一行表示当前采集到的一个监控样本:
promhttp_metric_handler_requests_total表明了当前指标的名称
- 大括号中的标签则反映了当前样本的一些特征和维度
-
每次采集到的数据都会被Prometheus以time-series(时间序列)的方式保存到内存中,定期刷新到硬盘。如下所示,可以将time-series理解为一个以时间为X轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu=”cpu0”,mode=”idle”}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu=”cpu0”,mode=”system”}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . .
v
<————————— 时间 ————————>在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
指标(metric):metric name和描述当前样本特征的labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value): 一个float64的浮点型数据表示当前样本的值。在形式上,所有的指标(Metric)都通过如下格式标示:
{ 指标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total - 表示当前系统接收到的HTTP请求总量)。
- 标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。
Prometheus:定期去Tragets列表拉取监控数据,存储到TSDB中,并且提供指标查询、分析的语句和接口。
无论是业务应用还是k8s系统组件,只要提供了metrics api,并且该api返回的数据格式满足标准的Prometheus数据格式要求即可。
其实,很多组件已经为了适配Prometheus采集指标,添加了对应的/metrics api,比如
CoreDNS:
$ kubectl -n kube-system get po -owide|grep corednscoredns-58cc8c89f4-nshx2 1/1 Running 6 22d 10.244.0.20coredns-58cc8c89f4-t9h2r 1/1 Running 7 22d 10.244.0.21$ curl 10.244.0.20:9153/metrics

若有收获,就点个赞吧
0 人点赞
