常用监控对象的指标采集
对于集群的监控一般我们需要考虑以下几个方面:
- 内部系统组件的状态:比如 kube-apiserver、kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 业务容器指标的监控(容器CPU、内存、磁盘等)
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
监控配置
监控coreDNS,修改target配置:
```yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-config namespace: monitor data: prometheus.yml: | global:
scrape_configs:scrape_interval: 15sscrape_timeout: 15s
- job_name: ‘prometheus’
static_configs:
- targets: [‘localhost:9090’]
- job_name: ‘coredns’
static_configs:
- targets: [‘10.96.0.10:9153’]
$ kubectl apply -f prometheus-configmap.yaml
重建pod生效
$ kubectl -n monitor delete po prometheus-dcb499cbf-fxttx
<a name="K82pr"></a>### 监控kube-apiserverapiserver自身也提供了/metrics 的api来提供监控数据,可以通过手动配置如下job来试下对apiserver服务的监控```yaml...- job_name: 'kubernetes-apiserver'static_configs:- targets: ['10.96.0.1']scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
监控节点主机 node_exporter https://github.com/prometheus/node_exporter
分析:
- 每个节点都需要监控,因此可以使用DaemonSet类型来管理node_exporter
- 添加节点的容忍配置
-
创建node-exporter服务
apiVersion: apps/v1kind: DaemonSetmetadata:name: node-exporternamespace: monitorlabels:app: node-exporterspec:selector:matchLabels:app: node-exportertemplate:metadata:labels:app: node-exporterspec:hostPID: truehostIPC: truehostNetwork: truenodeSelector:kubernetes.io/os: linuxcontainers:- name: node-exporterimage: prom/node-exporter:v1.0.1args:- --web.listen-address=$(HOSTIP):9100- --path.procfs=/host/proc- --path.sysfs=/host/sys- --path.rootfs=/host/root- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/)- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$ports:- containerPort: 9100env:- name: HOSTIPvalueFrom:fieldRef:fieldPath: status.hostIPresources:requests:cpu: 150mmemory: 180Milimits:cpu: 150mmemory: 180MisecurityContext:runAsNonRoot: truerunAsUser: 65534volumeMounts:- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootmountPath: /host/rootmountPropagation: HostToContainerreadOnly: truetolerations:- operator: "Exists"volumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: roothostPath:path: /
部署
$ kubectl create -f node-exporter.yaml$ kubectl -n monitor get po
如何添加到Prometheus的target中?
配置一个Service,后端挂载node-exporter的服务,把Service的地址配置到target中
- 带来新的问题,target中无法直观的看到各节点node-exporter的状态
把每个node-exporter的服务都添加到target列表中
- 带来新的问题,集群节点的增删,都需要手动维护列表
- target列表维护量随着集群规模增加
Prometheus的服务发现与Relabeling
之前已经给Prometheus配置了RBAC,有读取node的权限,因此Prometheus可以去调用Kubernetes API获取node信息,所以Prometheus通过与 Kubernetes API 集成,提供了内置的服务发现分别是:Node、Service、Pod、Endpoints、Ingress配置job,添加node-exporter到target中
...- job_name: 'kubernetes-sd-node-exporter'kubernetes_sd_configs:- role: node
重建查看效果:
$ kubectl apply -f prometheus-configmap.yaml$ kubectl -n monitor delete po prometheus-dcb499cbf-6cwlg
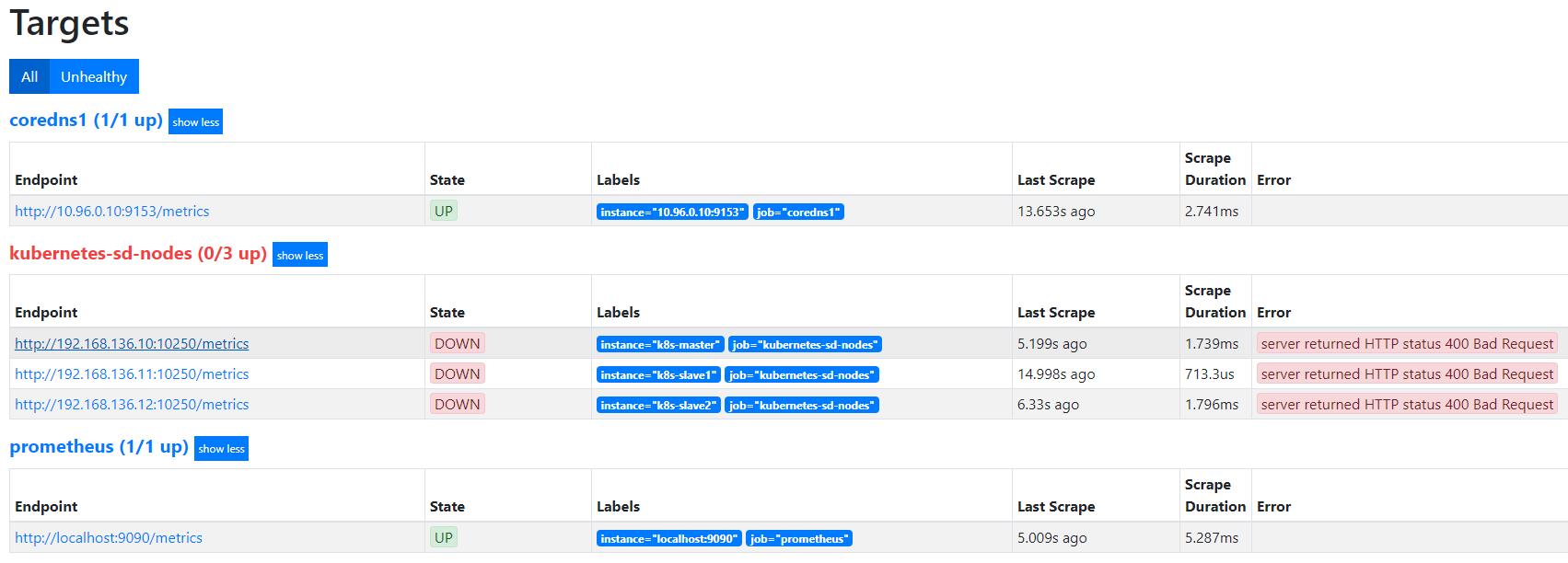
默认访问的地址是http://node-ip/10250/metrics,10250是kubelet API的服务端口,说明Prometheus的node类型的服务发现模式,默认是和kubelet的10250绑定的,而我们是期望使用node-exporter作为采集的指标来源,因此需要把访问的endpoint替换成http://node-ip:9100/metrics。
在真正抓取数据前,Prometheus提供了relabeling的能力。怎么理解?
查看Target的Label列,可以发现,每个target对应会有很多Before Relabeling的标签,这些__开头的label是系统内部使用,不会存储到样本的数据里,但是,我们在查看数据的时候,可以发现,每个数据都有两个默认的label,即:
instance的值其实则取自于addressprometheus_notifications_dropped_total{instance="localhost:9090",job="prometheus"}
这种发生在采集样本数据之前,对Target实例的标签进行重写的机制在Prometheus被称为Relabeling。
因此,利用relabeling的能力,只需要将address替换成node_exporter的服务地址即可。
再次更新Prometheus服务后,查看targets列表及node-exporter提供的指标,node_load1...- job_name: 'kubernetes-sd-node-exporter'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace
cadvisor监控指标的采集
cAdvisor 的指标访问路径为#IP为api-server的serviceIP
分析:https://10.96.0.1/api/v1/nodes/<node_name>/proxy/metricshttps://10.96.0.1/api/v1/nodes/k8s-master/proxy/metricshttps://10.96.0.1/api/v1/nodes/k8s-slave1/proxy/metricshttps://10.96.0.1/api/v1/nodes/k8s-slave2/proxy/metrics
每个节点都需要做替换,可以利用Prometheus服务发现中 node这种role
- job_name: 'kubernetes-sd-cadvisor'kubernetes_sd_configs:- role: node
默认添加的target列表为:address metrics_path
http://192.168.136.10:10250/metrics
http://192.168.136.11:10250/metrics
http://192.168.136.12:10250/metrics
抓取的地址是相同的,可以用10.96.0.1做固定值进行替换address- job_name: 'kubernetes-sd-cadvisor'kubernetes_sd_configs:- role: noderelabel_configs:- target_label: __address__replacement: 10.96.0.1action: replace
目前为止,替换后的样子:
http://10.96.0.1/metrics
http://10.96.0.1/metrics
http://10.96.0.1/metrics
需要把找到node-name,来做动态替换metrics_path- job_name: 'kubernetes-sd-cadvisor'kubernetes_sd_configs:- role: noderelabel_configs:- target_label: __address__replacement: 10.96.0.1action: replace- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
目前为止,替换后的样子:
http://10.96.0.1/api/v1/nodes/k8s-master/proxy/metrics
http://10.96.0.1/api/v1/nodes/k8s-slave1/proxy/metrics
http://10.96.0.1/api/v1/nodes/k8s-slave2/proxy/metrics
加上api-server的认证信息- job_name: 'kubernetes-sd-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- target_label: __address__replacement: 10.96.0.1- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
重新应用配置,然后重建Prometheus的pod。查看targets列表,查看cadvisor指标,比如container_cpu_system_seconds_total
综上,利用node类型,可以实现对daemonset类型服务的目标自动发现以及监控数据抓取。
集群Service服务的监控指标采集
比如集群中存在100个业务应用,每个业务应用都需要被Prometheus监控。
每个服务是不是都需要手动添加配置?有没有更好的方式?
- job_name: 'kubernetes-sd-endpoints'kubernetes_sd_configs:- role: endpoints
添加到Prometheus配置中进行测试:
$ kubectl apply -f prometheus-configmap.yaml$ kubectl -n monitor delete po prometheus-dcb499cbf-4h9qj
此使的Target列表中,kubernetes-sd-endpoints下出现了N多条数据,
可以发现,实际上endpoint这个类型,目标是去抓取整个集群中所有的命名空间的Endpoint列表,然后使用默认的/metrics进行数据抓取,我们可以通过查看集群中的所有ep列表来做对比:
$ kubectl get endpoints --all-namespaces
但是实际上并不是每个服务都已经实现了/metrics监控的,也不是每个实现了/metrics接口的服务都需要注册到Prometheus中,因此,我们需要一种方式对需要采集的服务实现自主可控。这就需要利用relabeling中的keep功能。
我们知道,relabel的作用对象是target的Before Relabling标签,比如说,假如通过如下定义:
- job_name: 'kubernetes-sd-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__keep_this_service__]action: keepregex: “true”
那么就可以实现target的Before Relabling中若存在keep_this_service,且值为true的话,则会加入到kubernetes-endpoints这个target中,否则就会被删除。
因此可以为我们期望被采集的服务,加上对应的Prometheus的label即可。
问题来了,怎么加?
查看coredns的metrics类型Before Relabling中的值,可以发现,存在如下类型的Prometheus的标签:
meta_kubernetes_service_annotation_prometheus_io_scrape=”true”
meta_kubernetes_service_annotation_prometheus_io_port=”9153”
这些内容是如何生成的呢,查看coredns对应的服务属性:
$ kubectl -n kube-system get service kube-dns -o yamlapiVersion: v1kind: Servicemetadata:annotations:prometheus.io/port: "9153"prometheus.io/scrape: "true"creationTimestamp: "2020-06-28T17:05:35Z"labels:k8s-app: kube-dnskubernetes.io/cluster-service: "true"kubernetes.io/name: KubeDNSname: kube-dnsnamespace: kube-system...
发现存在annotations声明,因此,可以联想到二者存在对应关系,Service的定义中的annotations里的特殊字符会被转换成Prometheus中的label中的下划线。
我们即可以使用如下配置,来定义服务是否要被抓取监控数据。
- job_name: 'kubernetes-sd-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true
这样的话,我们只需要为服务定义上如下的声明,即可实现Prometheus自动采集数据
annotations:prometheus.io/scrape: "true"
有些时候,我们业务应用提供监控数据的path地址并不一定是/metrics,如何实现兼容?
同样的思路,我们知道,Prometheus会默认使用Before Relabling中的__metrics_path作为采集路径,因此,我们再自定义一个annotation,prometheus.io/path
annotations:prometheus.io/scrape: "true"prometheus.io/path: "/path/to/metrics"
这样,Prometheus端会自动生成如下标签:
__meta_kubernetes_service_annotation_prometheus_io_path="/path/to/metrics"
我们只需要在relabelconfigs中用该标签的值,去重写_metrics_path的值即可。因此:
- job_name: 'kubernetes-sd-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)
有些时候,业务服务的metrics是独立的端口,比如coredns,业务端口是53,监控指标采集端口是9153,这种情况,如何处理?
很自然的,我们会想到通过自定义annotation来处理,
annotations:prometheus.io/scrape: "true"prometheus.io/path: "/path/to/metrics"prometheus.io/port: "9153"
如何去替换?
我们知道Prometheus默认使用Before Relabeling中的address进行作为服务指标采集的地址,但是该地址的格式通常是这样的
address=”10.244.0.20:53”
address=”10.244.0.21”
我们的目标是将如下两部分拼接在一起:
- 10.244.0.20
- prometheus.io/port定义的值,即__meta_kubernetes_service_annotation_prometheus_io_port的值
因此,需要使用正则规则取出上述两部分:
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2
需要注意的几点:
- address中的:53有可能不存在,因此,使用()?的匹配方式进行
- 表达式中,三段()我们只需要第一和第三段,不需要中间括号部分的内容,因此使用?:的方式来做非获取匹配,即可以匹配内容,但是不会被记录到$1,$2这种变量中
- 多个source_labels中间默认使用;号分割,因此匹配的时候需要注意添加;号
此外,还可以将before relabeling 中的更多常用的字段取出来添加到目标的label中,比如:
- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name
因此,目前的relabel的配置如下:
- job_name: 'kubernetes-sd-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name
验证一下:
更新configmap并重启Prometheus服务,查看target列表。
kube-state-metrics监控
已经有了cadvisor,容器运行的指标已经可以获取到,但是下面这种情况却无能为力:
我调度了多少个replicas?现在可用的有几个?
多少个Pod是running/stopped/terminated状态?
Pod重启了多少次?
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。因此,需要借助于kube-state-metrics来实现
指标类别包括:
- CronJob Metrics
- DaemonSet Metrics
- Deployment Metrics
- Job Metrics
- LimitRange Metrics
- Node Metrics
- PersistentVolume Metrics
- PersistentVolumeClaim Metrics
- Pod Metrics
- kube_pod_info
- kube_pod_owner
- kube_pod_status_phase
- kube_pod_status_ready
- kube_pod_status_scheduled
- kube_pod_container_status_waiting
- kube_pod_container_status_terminated_reason
- …
- Pod Disruption Budget Metrics
- ReplicaSet Metrics
- ReplicationController Metrics
- ResourceQuota Metrics
- Service Metrics
- StatefulSet Metrics
- Namespace Metrics
- Horizontal Pod Autoscaler Metrics
- Endpoint Metrics
- Secret Metrics
- ConfigMap Metrics
部署: https://github.com/kubernetes/kube-state-metrics#kubernetes-deployment
$ wget https://github.com/kubernetes/kube-state-metrics/archive/v1.9.7.tar.gz$ tar zxf v1.9.7.tar.gz$ cp -r kube-state-metrics-1.9.7/examples/standard/ .$ ll standard/total 20-rw-r--r-- 1 root root 377 Jul 24 06:12 cluster-role-binding.yaml-rw-r--r-- 1 root root 1651 Jul 24 06:12 cluster-role.yaml-rw-r--r-- 1 root root 1069 Jul 24 06:12 deployment.yaml-rw-r--r-- 1 root root 193 Jul 24 06:12 service-account.yaml-rw-r--r-- 1 root root 406 Jul 24 06:12 service.yaml# 替换namespace为monitor$ sed -i 's/namespace: kube-system/namespace: monitor/g' standard/*$ kubectl create -f standard/clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics createdclusterrole.rbac.authorization.k8s.io/kube-state-metrics createddeployment.apps/kube-state-metrics createdserviceaccount/kube-state-metrics createdservice/kube-state-metrics created
如何添加到Prometheus监控target中?
apiVersion: v1kind: Servicemetadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "8080"labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7name: kube-state-metricsnamespace: monitorspec:clusterIP: Noneports:- name: http-metricsport: 8080targetPort: http-metrics- name: telemetryport: 8081targetPort: telemetryselector:app.kubernetes.io/name: kube-state-metrics
$ kubectl apply -f standard/service.yaml

若有收获,就点个赞吧
0 人点赞
