Flink诞生于柏林工业大学,原名StratoSphere。Flink是跟Storm一样的,都是一个流处理框架。目前是大数据行业一门火热的技术。
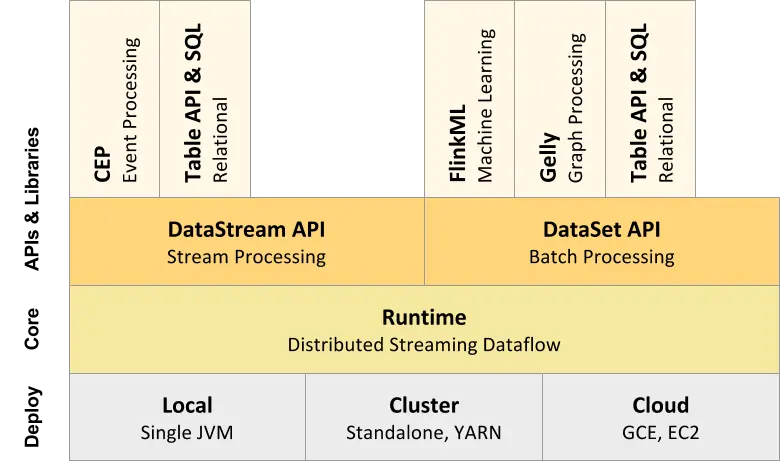
Flink的核心架构
Flink采用分层的架构由上倒下由Api层、Runtime以及物理部署层组成
API&Libraries层
这一层主要提供编程API和顶层类库:
- 编程API:提供对进行流处理的DataStream API。对批处理提供DataSet API
- 顶层类库:包括用域复杂事件处理的CEP库;用于结构化数据查询的SQL&Table库,以及基于批处理的机器学习库FlinkML和图形处理库Gelly
RrunTime核心层
Flink分布式计算框架的核心实现,作业转换,任务调度,资源分配,任务执行等功能,基于这一层时间,可以在流式引擎下同时运行流处理程序和批处理程序。
物理部署层
Flink的物理部署层,用于支持在不同平台上部署运行Flink应用
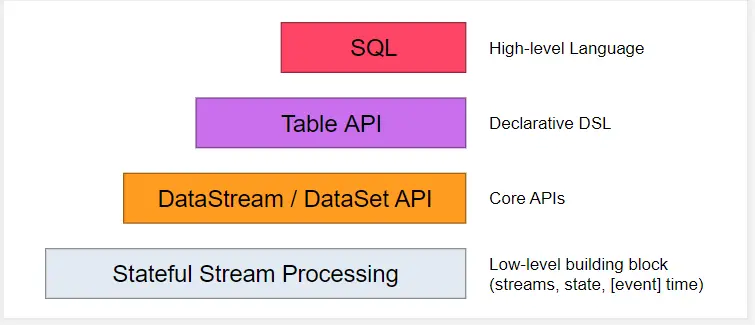
Flink分层API,对于上面介绍的API&Libraries这一层,Flink又进行了更为具体的划分如下
1.SQL&TABLE API
SQL&Table API同时适用于处理批处理和流处理,这意味着你可以对有界数据和无界的数据流进行查询,并产生结果。除了基本查询还支持多样化查询的需求。
2. DataStream&DataSet API
Flink核心API,提供数据读取,数据转换等常用操作的封装,支持Java或者Scala调用
3.Stateful Streaming
最低级别的抽象,通过Process Function函数内嵌到DataStreamAPI中,Process Function是Flink提供的最底层API,具有灵活性,允许开发者对于时间和状态进行细粒度控制。
Flink集群架构
Flink核心架构的第二层是Runtime层,该层采用Master-slave结构主从结构,其中Master部分包含Dispatcher、ResourceManager和JobManager,而Slave负责TaskManager进程。
JobManager:
Jobmanager接受由Dispatcher传递过来的执行程序,程序包含作业图,逻辑数据流图,以及其他文件。JobManagers将JobGraph转换成执行图,然后想ResourceManager申请资源执行任务,一旦申请到资源,就将执行图分发给对应的TaskManagers.
TaskManagers:
TaskManagers负责实际的任务执行,每个TaskManagers都拥有一定数量的slots。Slot是一组固定大小的资源合计。TaskManagers启动后,会将其所拥有的slots注册到ResourceManager上,由ResourceManager管理
Dispatcher
负责接受客户端提交的程序,传递给JobManager。初次之外还提供WEB UI,用于监控作业执行的情况。
ResourceManager
ResourceManager:负责管理slots并协调集群资源。ResourceManager接受来自JobManager的资源请求,并将存在空闲的slots的TaskManagers分配给JobManager执行任务。Flink基于不通的平台,提供不同的资源管理器,当没有足够的solts会向第三方平台发起会话请求资源。
Task &SubTask
TaskManagers实际执行的是SubTask,而不是Task。
SubTask的意思是一个Task可以按照其并行度分为多个SubTask。组件通讯
Flink的所有组件基于Actor System来进行通讯。Actor system是多种角色的actor的容器,它通过调度,配置,日志记录等多种服务,并包含一个可以启动actor的线程池,如果actor是本地的,则消息通过共享内存进行共享,但如果actor是远程的,则通过RPC的调用来传递信息。
Flink的优点
- Flink能够同时支持流处理和批处理。
- 基于内存的计算,能够保持高吞吐和低延迟,具有优越表现
- 能够完美保持一致性和正确性
- 分层API,满足各个层次的开发需求
- 支持高可用配置,能够提供安全性和稳定性的保证
- 多样化的部署方式,支持本地、远端、云端多种部署方案
- 具有横向扩展架构、可以动态扩容
- 活跃极高的社区和完善的生态圈。
Flink集群模式安装
Standalone Cluster HA模式是Flink自带的以中集群模式。
下载安装包
链接:https://pan.baidu.com/s/152n2PGnjnLvEkx3eaUFI4Q
提取码:d5dn
#上传安装包至服务器tar -zxvf flink-1.10.0-bin-scala_2.11.tgz#配置环境变量vim /etc/profileexport FLINK_HOME=/usr/local/flink-1.10.0export PATH=${PATH}:${FLINK_HOME}/bin#进入conf配置目录cd flink-1.10.0/conf/vim flink-conf.yaml#选择主节点jobmanager.rpc.address:node01# 配置使用zookeeper来开启高可用模式high-availability: zookeeper# 配置zookeeper的地址,采用zookeeper集群时,可以使用逗号来分隔多个节点地址high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181# 在zookeeper上存储flink集群元信息的路径high-availability.zookeeper.path.root: /flink# 高可用集群存储文件夹high-availability.storageDir: hdfs://hadoop001:8020/flink/recovery# flink zookeeper 根目录high-availability.zookeeper.path.root: /flinkstate.backend: filesystemstate.checkpoints.dir: hdfs://node01:8020/flink-checkpointsstate.savepoints.dir: hdfs://node01:8020/flink-checkpoints# web ui端口rest.port: 8081web.submit.enable: true# The port under which the web-based HistoryServer listens.historyserver.web.port: 8082#修改slaves配置文件,将node02和node03配置为slave节点node02node03#修改master节点node01node02#将配置好的flink安装包分发到其他两台服务器上scp -r flink-1.10.0 root@node02:/usr/local/scp -r flink-1.10.0 root@node03:/usr/local/
启动Flink集群
cd flink-1.10.0/bin
./start-cluster.sh
#启动报错
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
#缺少hadoop的jar依赖 从官网下载hadoop的依赖jar
https://flink.apache.org/downloads.html#apache-flink-1100
链接:https://pan.baidu.com/s/1YSMDytYcD4ZyYCZG18rD2A
提取码:kvcn
#上传jar到flink的lib目录下面
scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar root@node02:/usr/local/flink-1.10.0/lib
scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar root@node03:/usr/local/flink-1.10.0/lib
#重新启动
./start-cluster.sh
关于Flink的配置大家可以参考官网有关说明文档。


若有收获,就点个赞吧
0 人点赞
