准备安装文件、安装包提取位置
百度云盘链接:https://pan.baidu.com/s/1NpN6moRiNU2quh878UaRYw
密码:askm
1.安装spark单节点
>1.安装spark单节点解压安装包tar -zxvf spark-2.4.5-bin-hadoop2.7.tar.gz2.配置spark环境vim /etc/profileexport SPARK_HOME=spark-2.4.5-bin-hadoop2.7export PATH=$PATH:${SPARK_HOME}/bin3.配置spark的conf配置 进入spark的conf目录cp spark-env.sh.template spark-env.shvim spark-env.shSPARK_LOCAL_IP=服务器IP地址4.进入bin目录 启动sparksh spark-shell --master=local5.防火墙打开8080 端口浏览器访问服务器IP:PORT
2高可用spark集群搭建
192.168.80.153 master worker node01
192.168.80.154 master worker node02
192.168.80.155 worker node03
zookeeper的服务一定是奇数个数 且必须是奇数个数 1.容错率,zookeeper需要保证集群有半数的服务能够投票。 2.防脑裂 脑裂集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的leader节点,导致原有的集群出现多个leader节点的情况,这就是脑裂
用zookeeper来进行master选举机制
当spark集群其中一个节点宕机
由zookeeper进行选举出来master、保证spark服务可以正常运行
1.安装zookeeper
安装包在百度云盘可以下载找到zookeeper的安装包
tar -zxvf zookeeper.tar.gz
进入conf目录修改配置文件
cd zookeeper/conf
修改zoo_example.conf文件问zoo.conf 如果2个文件同时存在 zookeeper启动会报错
mv zoo_example.conf zoo.conf
vim zoo.conf
添加如下内容
配置日志存放目录
dataLogDir=/opt/zookeeper/logs
配置数据存放目录
dataDir=/opt/zookeeper/data
#2888是Leader选举的端口 3888 是zookeeper之间通信的端口
server.0=node01:2888:3888
server.1=node02:2888:3888
server.2=node03:2888:3888`
:wq #保存并且退出
采用scp命令传送文件到其他另外2台服务器
scp -r zookeeper root@node02:/usr/local/
scp -r zookeeper root@node03:/usr/local
分别进入zookeeper的bin目录下面启动zookeeper
./zkServer.sh
./zkServer.sh status #查看当前zookeeper在集群当中的角色 leader 或者follower
测试是否能正常选举 找到leader节点
关闭leader节点 查看剩下2台服务器是否选举出来了leader 如果正常选举出来了leader则表示成功
安装spark集群跟单节点安装相比需要多一步操作 进入spark的conf文件
编辑slaves的文件
cp slaves.template slaves
vim slaves
#添加如下节点
node01
node02
node03
#修改spark-env.sh 删除 单节点的时候的SPARK_LOCAL_IP
SPARK_LOCAL_DIRS=/usr/local/spark-2.4.5-bin-hadoop2.7/tmp
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export JAVA_HOME=/usr/local/java8
#recoveryMode表示发生故障的时候使用zookeeper服务进行故障转移
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
执行启动命令 在master节点
./start-all.sh
在另外2台执行
./start-master.sh --启动备用master
node01节点目前为启用状态
node02 目前节点为备用状态
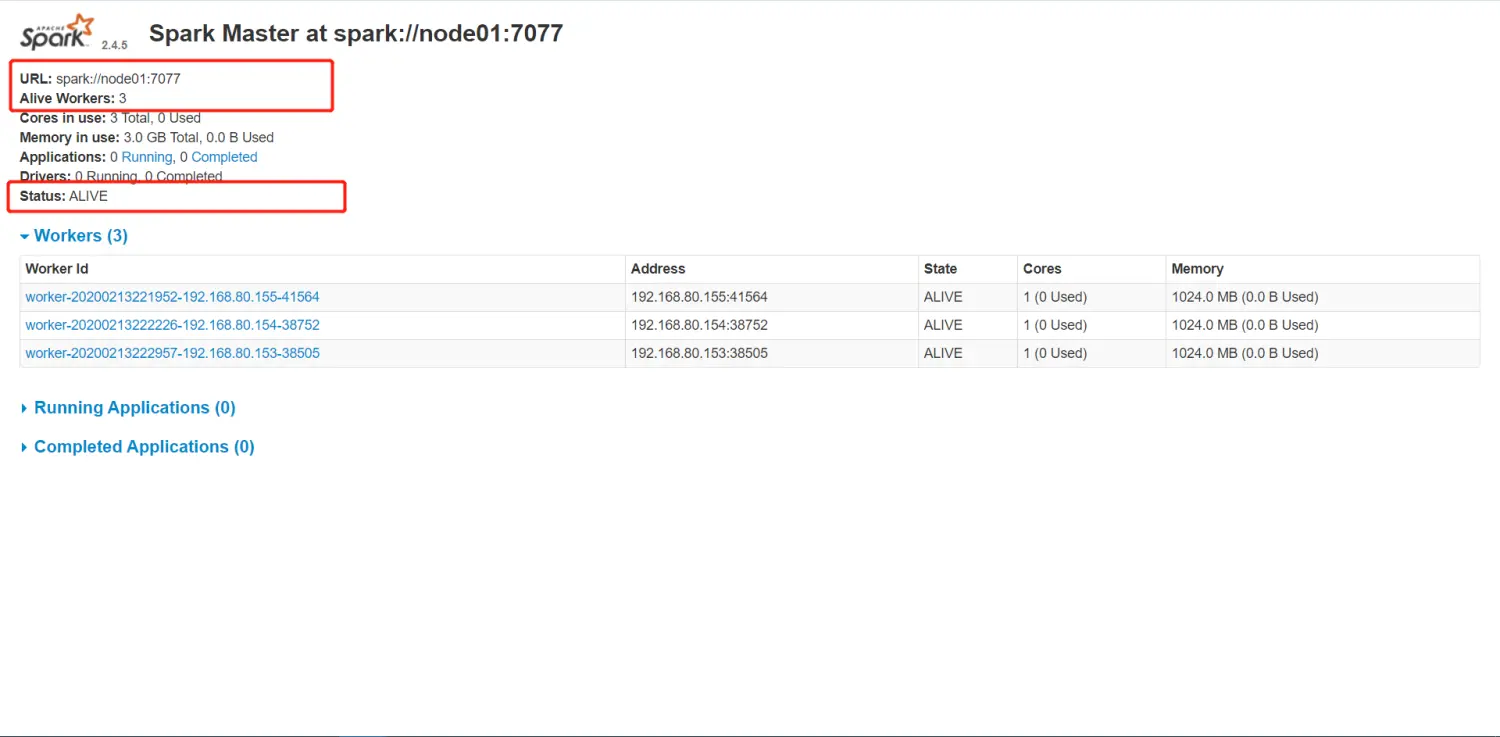
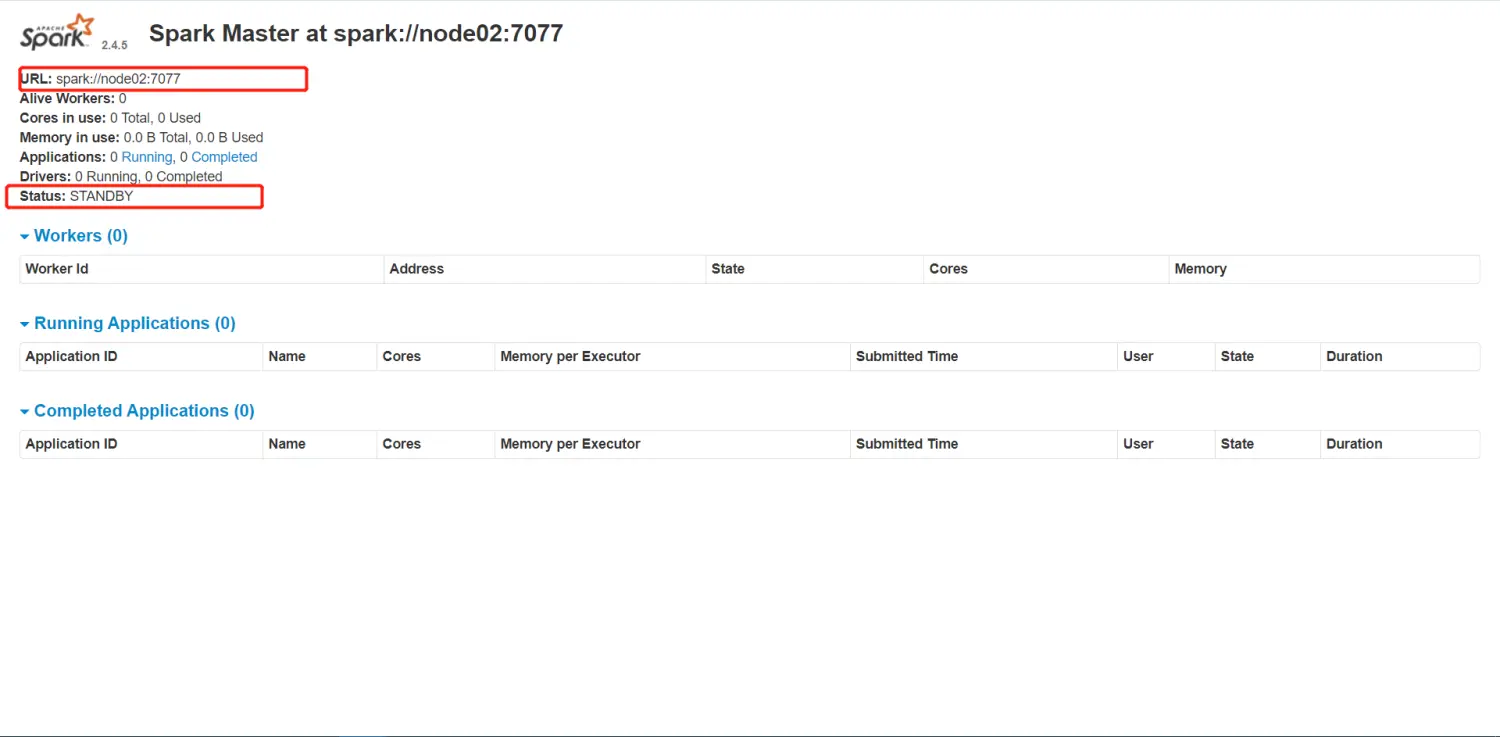
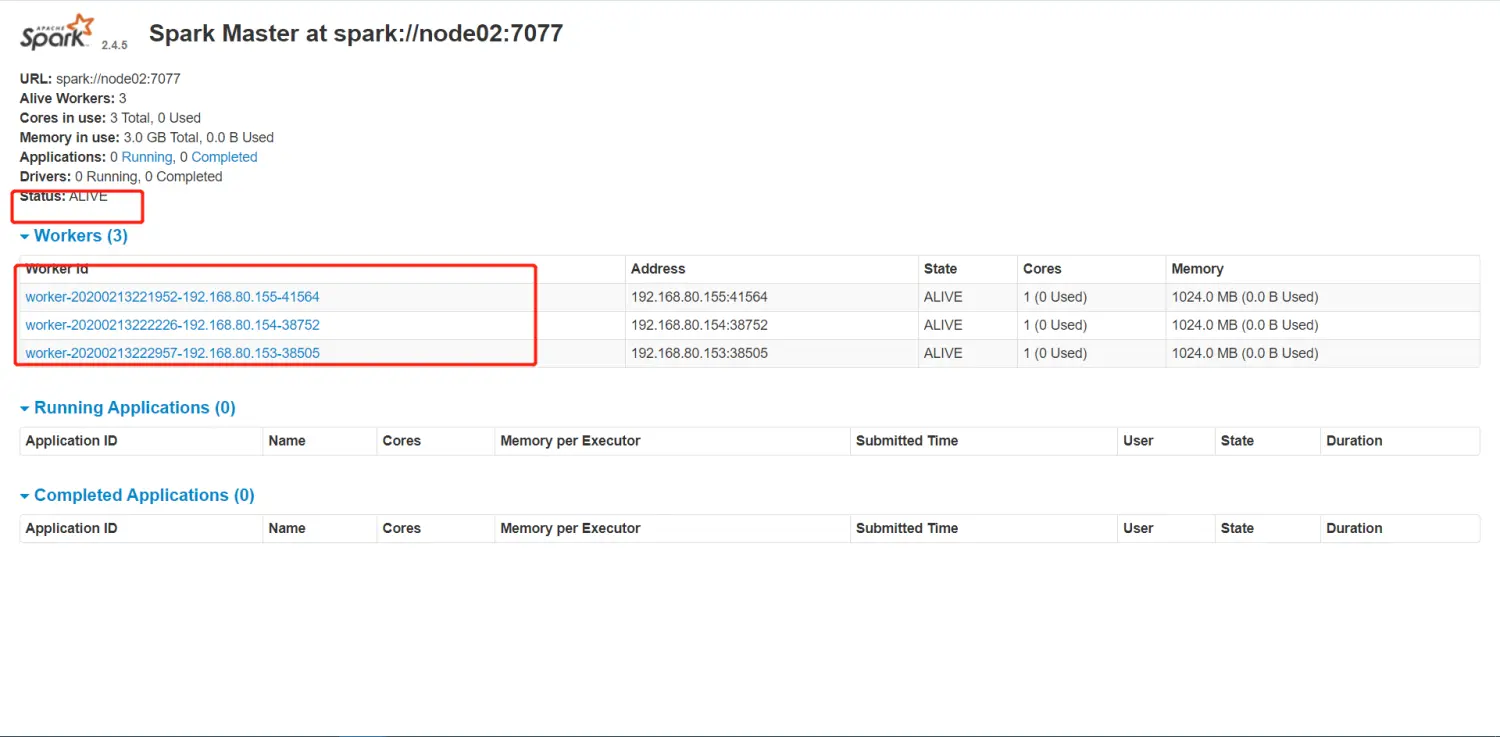
关闭掉 node01的master 过一段时间再看node02节点 是否已经转移过来
发现node02节点已经被激活 节点被转移过来了

若有收获,就点个赞吧
0 人点赞
