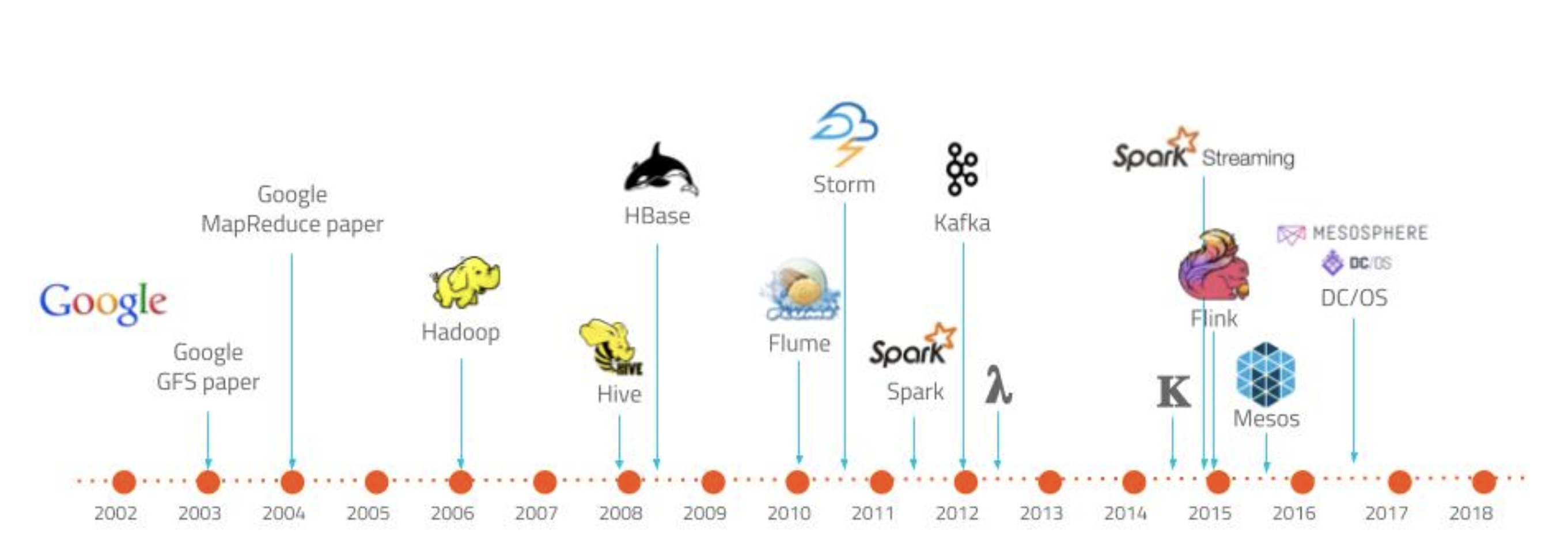
1、大数据技术发展
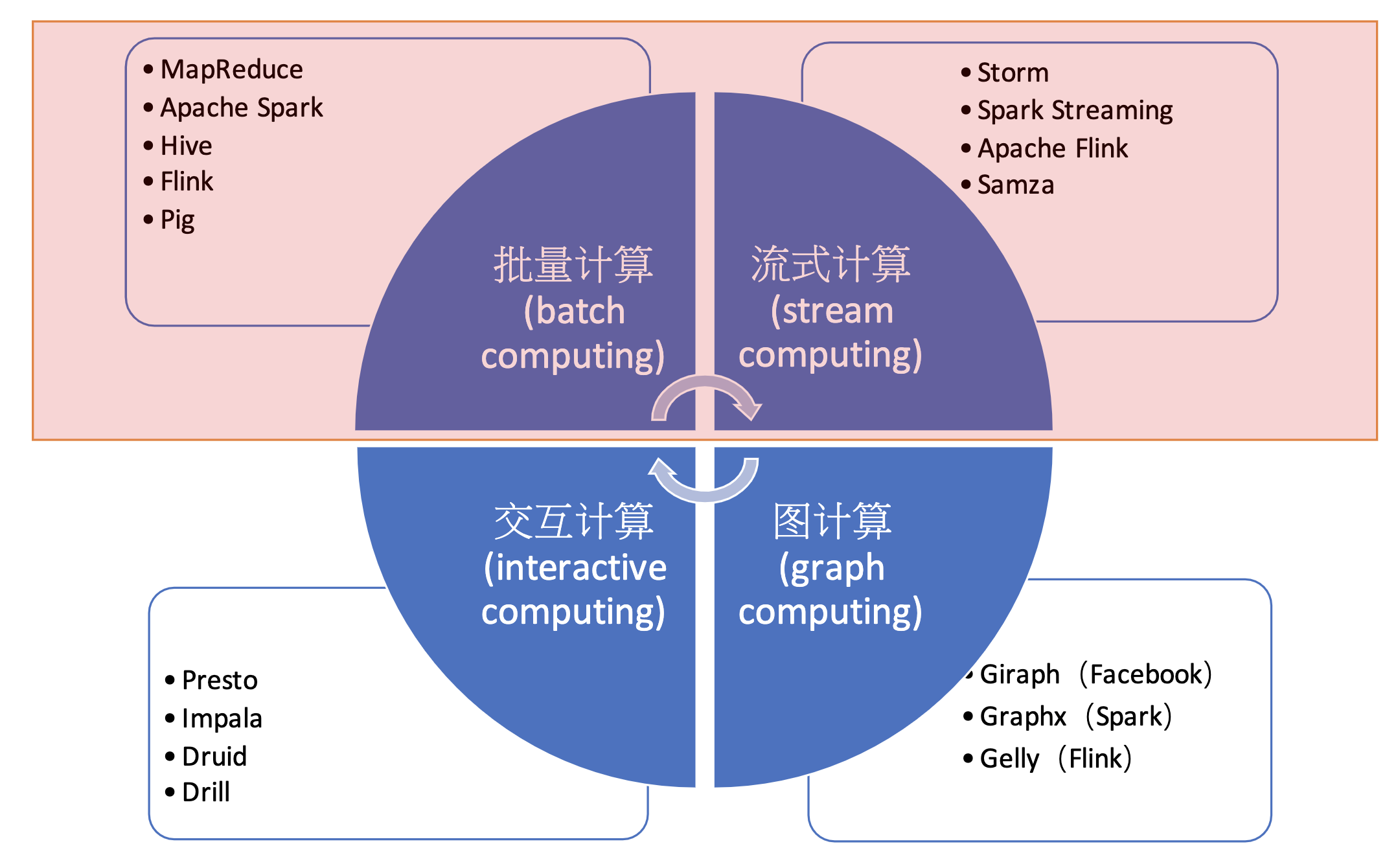
2、流计算与批计算的对比
- 数据时效不同
- 流计算:实时,低延时
- 批计算:非实时,高延迟
- 数据特征不同
- 流计算:动态,没有边界
- 批计算:静态数据
- 应用场景不同
- 流计算:实时场景,时效性比较高的场景,例如实时推荐、业务监控等
- 批计算:实时性要求不高、离线计算的场景,例如数据分析、离线报表
- 运行方式不同
- 流计算:任务持续进行
- 批计算:任务一次性完成或周期性执行
3、流计算成为主流的原因
- 数据处理时延要求越来越高,实时性要求越来越高
- 流式处理技术日趋成熟,同时越来越容易上手
- 批计算带来的计算和存储成本
- 批处理本身是一种特殊的流计算,批和流本身就是相辅相成的——lambda架构
4、流计算框架
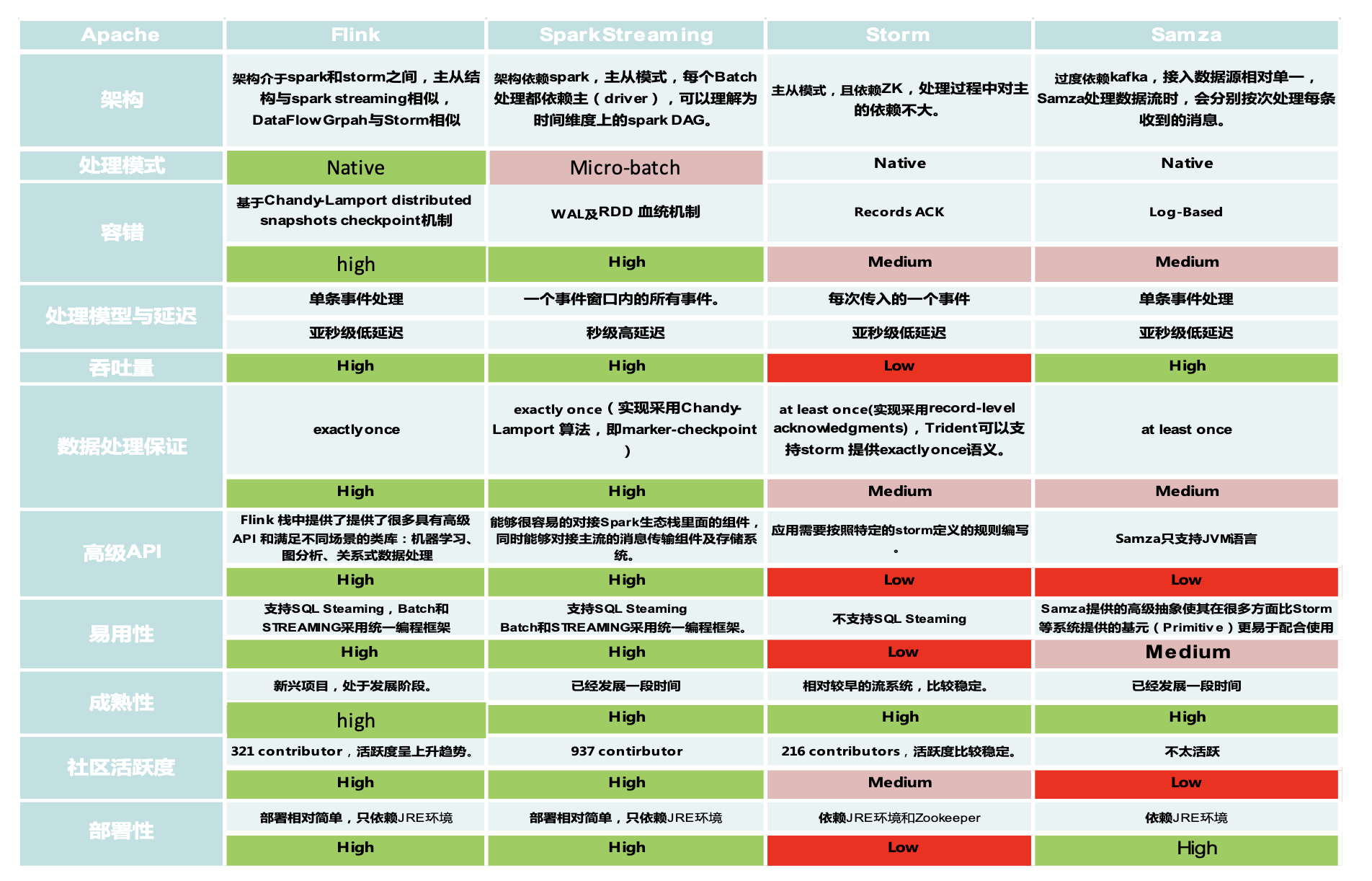
1)storm
- 最早使用的流处理框架,社区比较成熟
- 支持原生的流处理,即单事件来处理数据流
- 延迟性低(毫秒级)
- 消息保障能力弱:at-least-once
- 吞吐量比较低

2)spark streaming
- 属于spark API的扩展
- 以固定的时间间隔(例如几秒)处理一段段的批处理作业(微批处理)
- 延时性较高(秒级),能够保证Exactly once
- 具有非常高的吞吐
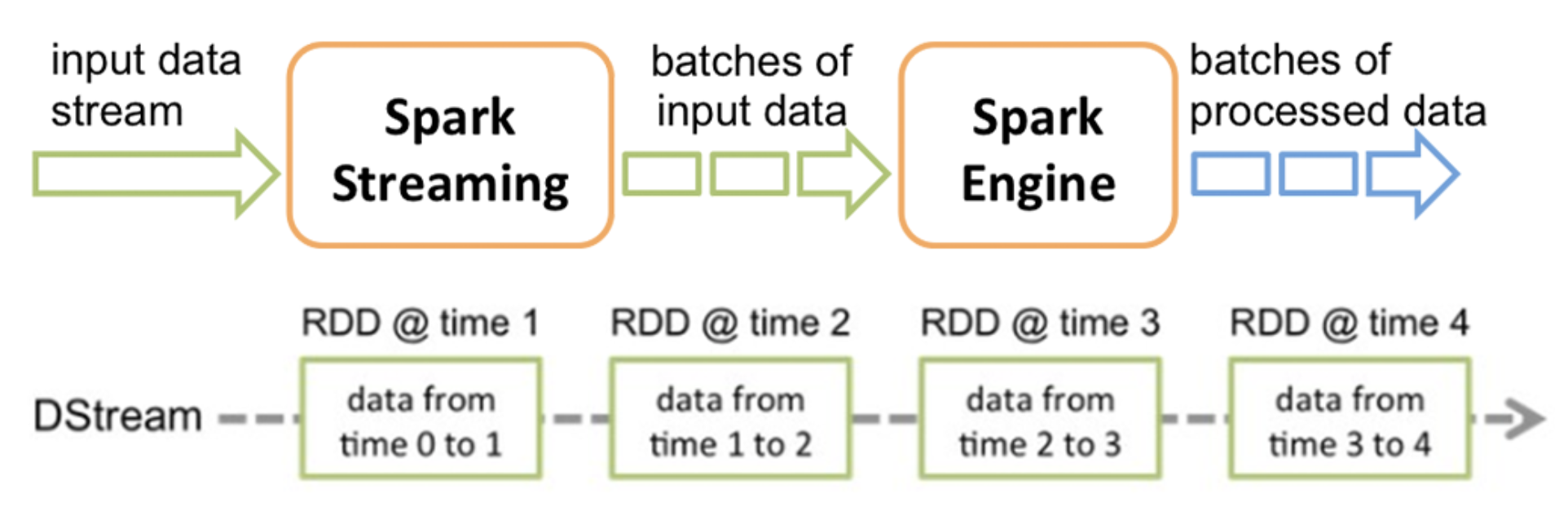
3)flink
- 采用DataFlow Model
- 延时性较低(毫秒),能够保证Exactly once
- 具有非常高的吞吐
- 支持原生流处理
流计算框架选型
- 低延迟:毫秒级延迟
- 高吞吐:每秒千万级
- 准确性:Exactly-once
- 易用性:提供SQL、Table等API


5、流计算框架比较

若有收获,就点个赞吧
0 人点赞
