分布式场景下,系统中的子系统或者模块间需要相互通信或者传递信号,或者传输数据。这种通信场景可以简单分为三类:
- 集群间的通信,如redis集群基于gossip的数据交换,一般直接基于TCP,一般会收敛于系统内部
- 数据传输,应用读写mysql, redis等数据系统,一般直接基于TCP,场景定制性高
- 消息传递,微服务之间相互接口调用。这种偏上层业务,需要适应复杂繁多的场景,并提供高度的可复用性,适应性,扩展性。所以一般是基于TCP再做一层封装,如http2
所谓赋能,就是能低成本大规模使用,一般有几个需求:
- 有良好的适应能力,对于部分核心能力可以通过插件实现定制化能力,适应不同的环境
- 提供关键问题的解决方案,例如高效率的并发模型,加密,压缩等
- 有足够的扩展能力,能通过配置,注入等方式灵活实现扩展功能或开启部分功能
- 足够简单,屏蔽底层细节,能无脑上手使用,不需要了解http2, protobuf, IO模型
适应能力
服务发现
- A要能得知B的可调用地址
- B的部署方式可能多种多样
负载均衡
上面解决了获取可调用地址的问题,紧接着问题又来了,如何做负载均衡?一批可调用的地址中,到底选哪个?怎么选?
常规的负载均衡算法非常多,如轮询,随机,耗时最短,加权随机等等。由于技术系统的异构性,很多时候难以简单地随机轮训。gRPC为了提供足够强的适应性,把负载均衡的策略也开放了。使用者可以在启动时设置负载均衡的对象,通过插件可以定义策略。
具体的实现相对简单:
- gRPC会将封装好的网络连接丢给负载均衡对象,当连接变化时,由PickerBuilder新build一个picker
- 每次调用前调用picker pick一个节点出来以供使用
- pick接口会返回一个done函数,rpc调用完毕后会回调,支持回传一些balancer.Doneinfo
- balance.DoneInfo里面支持一些metadata,也就是服务方可以通过http2的header回传一些key:value
- 服务方可以在返回请求时,将自己的CPU,负载等反映压力的数据写到metadata中,这些数据可以通过done函数回写到picker,供决策使用
关键问题
框架在整合编解码,网络传输等feature的同时,也需要提供部分核心功能,这些功能往往是系统刚需,存在重复劳动的地方,最常见的并发模型。
并发模型一般是针对服务方而言的,服务方需要有高效率的IO,在资源有限的情况下一方面快速地处理请求。另一个方面提供足够高的并发能力,实现高吞吐低延迟。
这些都是C10k问题的延伸,传统的服务方基于阻塞IO实现请求读写,这样一个线程/进程只能同时处理一个请求。当用户量暴增后,不能来一个请求就fork一个子进程或者线程来处理,这样资源扛不住。
所以得有更有效率的策略,得让一个线程/进程能同时多个请求,这就是诞生多路复用的需求。让一个线程同时监听多个socket状态,socket就绪才进行处理,而不是依赖操作系统的接口直接handler, 白白浪费CPU的时间(select/epoll)。
于是便诞生了大名鼎鼎鼎Reactor模型,linux环境下大量号称高并发server都实现了Reactor模型。在golang之前,大量的语言例如java, python, ruby等的rpc框架都要自己实现Refactor模型,实现高吞吐,这其实是应用层的重复劳动。golang从语言层面下沉了类似的实现,同时实现netpoller, 让golang程序的网络IO读写避免无意义的等待,和上下文切换。简单讲就是几点:
- golang runtime封装了非阻塞IO, 给应用程序暴露成阻塞IO
- 当goroutine操作一个未就绪的socket时,操作系统会返回error,runtime会拦截这个error,将该socket加入状态监控队列(可以简单认为是一个epoll), 并将该goroutine挂起
- 当监听到对应的socket可读/可写时,会将对应的goroutine找到并让其立即等待执行
- 第2,3步周而复始,从goroutine角度来看,是在操作阻塞IO,然后并没有CPU时间浪费在等待上,也没有线程上下文切换。
- 这样的结果就是golang的相关应用程序不需要实现reactor模型,来一个请求则创建一个goroutine去处理就行,这极大地简化了并发模型。
扩展能力
了解框架的人都知道,可以提供高度自由的扩展功能。一般通过几种方式提供:
自定义插件
例如上面的服务发现,负载均衡,因为gRPC天然和protobuf绑定,谈到扩展插件,就不得不提及gRPC在编码层的解耦。因为使用protobuf的前提是你得有对应的.proto文件,这样才能进行编解码。但是在有些场景下,类似代理的角色没有办法持有所有的proto,这边限制了下面的场景: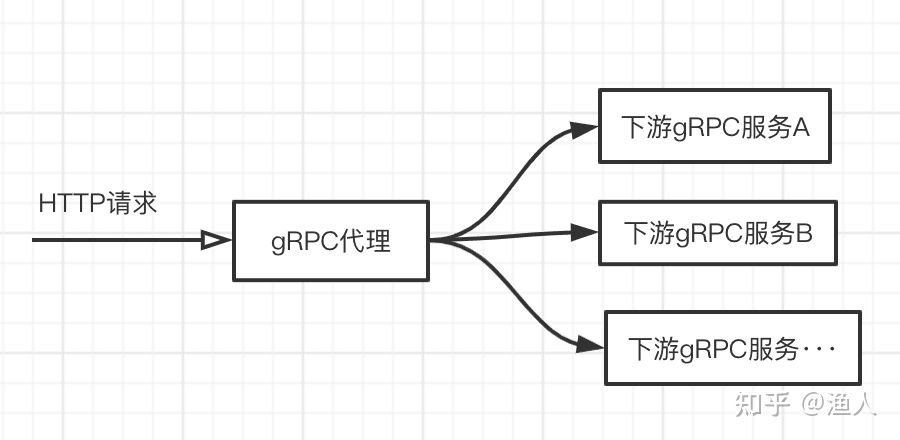
假设有一个http的场景需要调用gRPC的接口实现功能,这需要有一个近似透传的代理来实现,但都是通过protobuf包装数据,代理则要持有所有下游的proto文件,这不现实。但如果将编解码的方式解耦出来,例如通过json进行编解码,便能轻松解决问题,这带来了极大的灵活性。http和gRPC的混用融合可以产生不菲的价值,而且gRPC请求的调用调试也可以像http那样简单。
配置
gRPC可以通过option配置提供多种能力,例如:
- 自动重试
- 加密
- 压缩
- 超时定制
拦截器
拦截器可以在调用方和服务方同时存在,一般用来实现熔断,限流日志收集,open-tracing,异常捕获,数据统计,鉴权,数据注入等等多种功能。现在的大部分功能拓展能力一般是以SDK的方式独立于业务代码,但都是运行在同一个进程中。如果把上面分布式治理部分功能剥离出来集中治理优化,并和业务进程隔离部署,就是一个ServiceMesh落地雏型
参考

若有收获,就点个赞吧
0 人点赞
