1. 树的基本语术

Degree:度,结点所拥有的⼦树个数称为结点的度Level:层次,根为第0层,根的孩⼦为第1层。若某结点在第i层,那么其⼦树的根就在第i + 1层Height of node:结点的⾼度,该结点到叶⼦结点,最⻓路径的边数Height of tree:树的⾼度 = 根结点的⾼度Depth of node:结点的深度,从根结点到该结点的路径中,边的数量Ancestor: 祖先,结点的祖先(Ancestor)是从根(Root)到该结点所经分⽀(Branch)上的所有结点路径:在⼀棵树中,⼀个结点到另⼀个结点之间的通路,称为路径
2. 树的种类
⼆叉树
- 霍夫曼树(最优⼆叉树)
⼆叉搜索树
平衡搜索树
⾃平衡⼆叉搜索树
AVL树
红⿊树(2-3树)
多路搜索树
多路平衡搜索树
B树
B+树
2-3树
2-3-4树
2.1 ⼆叉搜索树
⼆叉查找树(BST:Binary Search Tree)是⼀种特殊的⼆叉树,它改善了⼆叉树结点查找的效率
对于任意⼀个结点
n其左⼦树(
left subtree)下的每个后代结点(descendant node)的值都⼩于结点n的值其右⼦树(
right subtree)下的每个后代结点的值都⼤于结点n的值其左⼦树和右⼦树也是⼆叉搜索树
时间复杂度:⼀般情况插⼊、搜索和删除操作O(logn),最坏情况O(n)
空间复杂度:O(n)
遍历类型:
前序遍历:
Parent-LeftChild-RightChild中序遍历:
LeftChild-Parent-RightChild后序遍历:
LeftChild -RightChild-Parent
2.2 ⾃平衡⼆叉搜索树
2.2.1 AVL树

时间复杂度:插⼊、搜索和删除操作O(logn)
空间复杂度:O(n)
平衡因⼦:⼆叉树中每个结点的左⼦树和右⼦树的⾼度差
如果结点仅有⼀个⼦结点,则⽆⼦结点侧的⾼度为
-1AVL树中每个结点的平衡因⼦应该是
+1、0或-1
对于任意⼀个结点
n平衡因⼦的绝对值不超过
1结点
n的左⼦树的⾼度与右⼦树的⾼度的差⾄多是1
在每次插⼊或删除后,如果任何结点的平衡因⼦不遵循 AVL 平衡属性
左旋
右旋
左右旋
右左旋
2.2.1 红⿊树
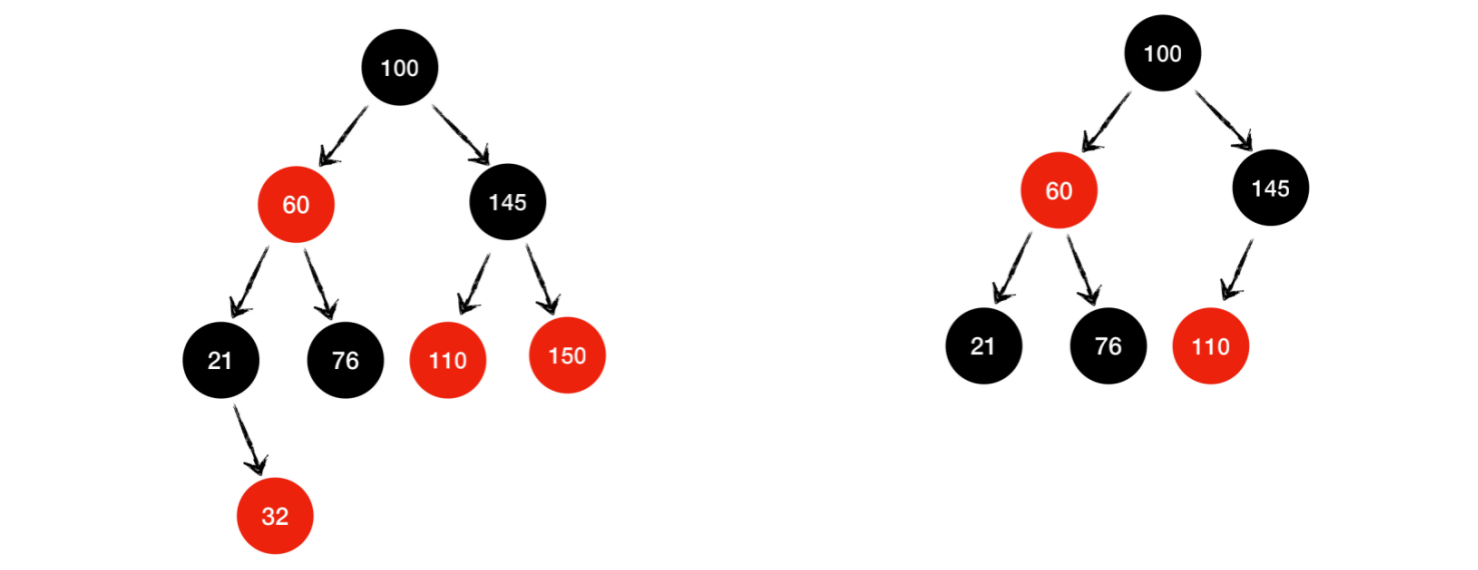
时间复杂度:插⼊、搜索和删除操作O(logn)
空间复杂度:O(n)
红⿊树还添加了⼀种特殊类型的结点 ,称为
NIL结点。NIL结点将做为红⿊树的伪叶⼦结点出现对于任意⼀个结点
n结点的颜⾊只能是红⾊或者⿊⾊
根结点是⿊⾊的
从根到任何叶结点的每条路径必须具有相同数量的⿊⾊结点
没有两个红⾊结点可以相邻,即⼀个红⾊结点不能是另⼀个红⾊结点的⽗结点或⼦结点
NIL结点的颜⾊是⿊⾊如果结点的颜⾊是红⾊,则其⼦结点均为⿊⾊
在每次插⼊或删除后,如果任何结点的平衡因⼦不遵循平衡属性
左旋
右旋
2.2.3 AVL树 VS 红⿊树
红⿊树是不符合AVL树的平衡条件的,即每个结点的左⼦树和右⼦树的⾼度最多差
1的⼆叉查找树红⿊树是⽤⾮严格的平衡来换取增删结点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决
AVL是严格平衡树,因此在增加或者删除结点的时候,根据不同情况,旋转的次数⽐红⿊树要多。所以红⿊树的插⼊效率更⾼
AVL在查询频繁的系统⾥⽐红⿊树更⾼效,原因是AVL树的平均⾼度⽐红⿊树更⼩
3. 堆结构
堆是⾼级数据结构,主要⽤来排序和实现优先级队列
3.1 关键属性
堆本质上是⼆叉树,但是必须满⾜两个条件:
是完全⼆叉树
left child = 2 * parent + 1right child = 2 * parent + 2parent = floor((child - 1) / 2)
结点必须根据顺序存储
3.2 ⼤顶堆 & ⼩顶堆

⼤顶堆:⽗结点的值⼤于等于⼦结点的值。所以根结点始终等于当前堆值最⼤的元素
⼩顶堆:⽗结点的值⼩于等于⼦结点的值。所以根结点始终等于当前堆值最⼩的元素
3.3 完全⼆叉树 & 满⼆叉树

满⼆叉树
⼆叉树除了叶结点外所有结点都有两个⼦结点
⼀个深度为
k(>=-1)且有2 ^ (k + 1) - 1个结点的⼆叉树称为完美⼆叉树
完全⼆叉树
⼆叉树中除去最后⼀层结点为满⼆叉树,且最后⼀层的结点依次从左到右分布
完全⼆叉树从根结点到倒数第⼆层满⾜完美⼆叉树,最后⼀层可以不完全填充,其叶⼦结点都靠左对⻬
4. 堆排序
堆排序算法的最坏性能为:O(N*log(N))
堆排序算法是所有排序算法中最坏性能中表现最好的排序算法
由于堆是完全⼆叉树,可以统计每⼀层的结点:
0层包含根结点1层包含根结点的⼦结点L层包含L-1层结点的⼦结点如果在当前完全⼆叉树在
L层只有⼀个结点,整棵树⼀共有N个结点:2 ^ 0 + 2 ^ 1 + … + 2 ^ (L - 1) + 1 = 2 ^ L <= N <= 2 ^ 0 + 2 ^ 1 + … + 2 ^ L = 2 ^ (L + 1) - 1
L <= log(N) < L + 1
可以得出结论,从根到任何叶⼦的最⻓分⽀最多包含log(N)个结点
任何仅访问单个分⽀上的结点的算法复杂度都是:O(log(N))
4.1 添加元素
向堆⾥添加F, E, D, C, B, A,并且F > E > D > C > B > A ,实现⼩顶堆
在下⼀个可能的位置添加⼀个具有新值的结点,将树保持为完全⼆叉树
将新结点与其⽗结点进⾏⽐较,当新结点⼩于⽗结点时,交换结点
重复上⼀步,直到新结点⼩于⽗结点或成为根结点
4.1.1 思路分析
添加元素的顺序为:F, E, D, C, B, A
添加第1个元素F,直接作为根结点
添加第2个元素E,与父结点F进行比较,如果<= F,则交换
添加第3个元素D,与父结点E进行比较,如果<= E,则交换
添加第4个元素C,与父结点F进行比较,如果<= F,则交换
此时结点C依然存在父结点D,继续比较。如果<= D,则再交换
按照上述逻辑,循环往复,将所有结点插入,形成小顶堆
4.1.2 代码实现
基本函数:
enum HeapType : Int {case Big = 1case Small = 2};class Heap<Element: Comparable> {fileprivate var _arr : [Element];fileprivate var _heapType : HeapType;init(heapType: HeapType) {_heapType = heapType;_arr = [Element]();}// 交换函数fileprivate func swap(i : Int, j : Int) {let tmp = _arr[i];_arr[i] = _arr[j];_arr[j] = tmp;}// 打印元素func traverse() {var str = "";for i in 0..<_arr.count {str += "\(_arr[i]), ";}print("\(str)");}}
辅助方法:
class Heap<Element: Comparable> {// 返回父结点索引值fileprivate func getParentIndex(index: Int) -> Int{// 根结点没有父结点,返回-1if(index == 0){return -1;}return (index - 1) / 2;}// 返回左孩子索引值fileprivate func getLeftIndex(index: Int) -> Int{return index * 2 + 1;}// 返回右孩子索引值fileprivate func getRightIndex(index: Int) -> Int{return index * 2 + 2;}// 根据【大/小顶堆】的特性,实现比较方法fileprivate func compare(curr: Element, target: Element) -> Bool {if(_heapType == HeapType.Big){return curr >= target;}return curr <= target;}}
添加元素:
class Heap<Element: Comparable> {// 添加元素func add(element: Element) {// 添加新元素_arr.append(element);// 获取最后一个元素的索引值let index = _arr.count - 1;// 当前结点与⽗结点⽐较,将其调整至符合堆的特性parentSwap(index: index);}// 当前结点与⽗结点⽐较,将其调整至符合堆的特性func parentSwap(index: Int) {// 传入当前结点var currIndex = index;// 获取该结点的父节点的索引值var parentIndex = getParentIndex(index: currIndex);// 如果父节点为-1,表示当前结点为根结点,停止遍历while(parentIndex != -1){// 比较当前结点与父结点,如果父节点更符合堆的特性,不需要交换,退出循环if(!compare(curr: _arr[currIndex], target: _arr[parentIndex])){break;}// 否则,当前结点更符合堆的特性,与父节点交换swap(i: currIndex, j: parentIndex);// 当前结点赋值为父节点currIndex = parentIndex;// 寻找新的父节点,准备下一轮遍历parentIndex = getParentIndex(index: currIndex);}}}
4.2 删除元素
从堆⾥删除A, B, C, D, E, F
待删除结点与最后⼀个结点交换,先临时保存待删除结点,然后将其删除
比较待删除结值与最后⼀个结点
如果待删除结点大于最后⼀个结点,比较交换后结点与其原先父节点,如果有必要,交换
如果待删除结点小于最后⼀个结点,比较交换后结点与其原先子节点,如果有必要,交换
重复上⼀步,直到⽗结点⼩于其原先⼦结点
4.2.1 思路分析
删除元素的顺序为:A, B, C, D, E, F
删除第1个元素A,将待删除元素与最后一个元素交换,然后将元素A删除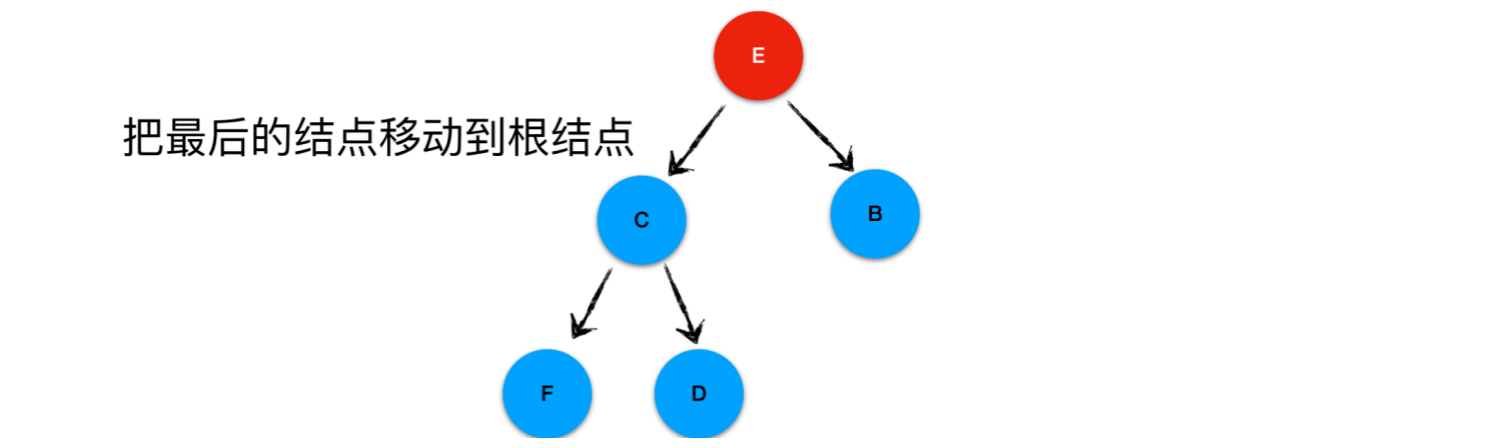
元素E与它的左、右孩子对比,其中B在这三个结点中最符合小顶堆特性,故此E与B交换
删除第2个元素B,将待删除元素与最后一个元素交换,然后将元素B删除
元素D与它的左、右孩子对比,其中C在这三个结点中最符合小顶堆特性,故此D与C交换
按照上述逻辑,循环往复,可将所有结点删除
4.2.2 堆化
⽤O(n)的时间把⼀个乱序的数组变成⼀个堆,这一过程称之为堆化
将⼀个数组当成⼀个完全⼆叉树,然后从最后⼀个⾮叶⼦节点开始,逐个对⾮叶⼦节点进⾏下沉操作
当删除元素时,如果待删除结点小于最后⼀个结点,则比较交换后结点与其原先子节点,此时进行的就是堆化处理
4.2.3 代码实现
堆化:
class Heap<Element: Comparable> {// 堆化 - ⾮叶⼦节点与左、右孩子比较,逐个对⾮叶⼦节点进⾏下沉操作,将其调整至符合堆的特性fileprivate func heapify(index: Int) {// 记录当前索引值var currIndex = index;// 获取左孩子的索引值var leftIndex = getLeftIndex(index: currIndex);// 判断左孩子如果越界,证明当前结点为叶子结点,停止遍历while(leftIndex < _arr.count){// 将交换目标的索引值,赋值为当前索引值var targetIndex = currIndex;// 如果左孩子相比当前结点更符合堆的特性if(compare(curr: _arr[leftIndex], target: _arr[targetIndex])){// 将交换目标的索引值,赋值为左孩子的索引值targetIndex = leftIndex;}// 获取右孩子的索引值let rightIndex = getRightIndex(index: currIndex);// 如果右孩子的索引值没有越界// 并且右孩子相比当前结点更符合堆的特性if(rightIndex < _arr.count && compare(curr: _arr[rightIndex], target: _arr[targetIndex])){// 将交换目标的索引值,赋值为右孩子的索引值targetIndex = rightIndex;}// 如果交换目标的索引值为当前索引值,表示当前结构符合堆的特性if(targetIndex == currIndex){// 退出循环break;}// 否则,交换当前元素与目标元素swap(i: currIndex, j: targetIndex);// 将当前索引值赋值为目标元素的索引值currIndex = targetIndex;// 寻找新的左孩子,准备下一轮循环leftIndex = getLeftIndex(index: currIndex);}}}
删除元素:
class Heap<Element: Comparable> {// 删除指定元素func remove(element: Element) {// 寻找该元素在数组中首次出现的索引值let index = _arr.firstIndex(of: element);// 未找到,不作处理if(index == nil){return;}// 按照索引位置删除元素remove(index: index!);}// 删除索引位置的元素func remove(index: Int) {// 如果索引越界,不作处理if(index >= _arr.count){return;}// 如果当前数组只有一个元素,或者删除的是最后一个元素if(_arr.count == 1 || index == _arr.count - 1){// 直接删除即可_arr.remove(at: index);return;}// 获取最后一个元素的索引值let lastIndex = _arr.count - 1;// 获取待删除元素let curr = _arr[index];// 获取最后一个元素let last = _arr[lastIndex];// 将待删除元素与最后一个元素交换swap(i: index, j: lastIndex);// 将待删除元素删除_arr.remove(at: lastIndex);// 如果删除结点相比最后一个结点不符合堆的特性if(!compare(curr: curr, target: last)){// 使用交换后的新结点与原父结点⽐较,将其调整至符合堆的特性parentSwap(index: index)return;}// 否则,删除结点相比最后一个结点更符合堆的特性,进行堆化处理heapify(index: index);}}
总结
树的基本语术:
Degree:度,结点所拥有的⼦树个数称为结点的度Level:层次,根为第0层,根的孩⼦为第1层。若某结点在第i层,那么其⼦树的根就在第i + 1层Height of node:结点的⾼度,该结点到叶⼦结点,最⻓路径的边数Height of tree:树的⾼度 = 根结点的⾼度Depth of node:结点的深度,从根结点到该结点的路径中,边的数量Ancestor: 祖先,结点的祖先(Ancestor)是从根(Root)到该结点所经分⽀(Branch)上的所有结点路径:在⼀棵树中,⼀个结点到另⼀个结点之间的通路,称为路径
树的种类:
⼆叉树
- 霍夫曼树(最优⼆叉树)
⼆叉搜索树
平衡搜索树
⾃平衡⼆叉搜索树
AVL树
红⿊树(2-3树)
多路搜索树
多路平衡搜索树
B树
B+树
2-3树
2-3-4树
堆结构:
堆本质上是⼆叉树,但是必须满⾜两个条件:
是完全⼆叉树
left child = 2 * parent + 1right child = 2 * parent + 2parent = floor((child - 1) / 2)
结点必须根据顺序存储
⼤顶堆 & ⼩顶堆
⼤顶堆:⽗结点的值⼤于等于⼦结点的值。所以根结点始终等于当前堆值最⼤的元素
⼩顶堆:⽗结点的值⼩于等于⼦结点的值。所以根结点始终等于当前堆值最⼩的元素
完全⼆叉树 & 满⼆叉树
满⼆叉树
⼆叉树除了叶结点外所有结点都有两个⼦结点
⼀个深度为
k(>=-1)且有2 ^ (k + 1) - 1个结点的⼆叉树称为完美⼆叉树
完全⼆叉树
⼆叉树中除去最后⼀层结点为满⼆叉树,且最后⼀层的结点依次从左到右分布
完全⼆叉树从根结点到倒数第⼆层满⾜完美⼆叉树,最后⼀层可以不完全填充,其叶⼦结点都靠左对⻬
堆排序:
堆排序算法的最坏性能为:O(N*log(N))
堆排序算法是所有排序算法中最坏性能中表现最好的排序算法
任何仅访问单个分⽀上的结点的算法复杂度都是:O(log(N))
添加元素:
在下⼀个可能的位置添加⼀个具有新值的结点,将树保持为完全⼆叉树
将新结点与其⽗结点进⾏⽐较,当新结点⼩于⽗结点时,交换结点
重复上⼀步,直到新结点⼩于⽗结点或成为根结点
删除元素:
待删除结点与最后⼀个结点交换,先临时保存待删除结点,然后将其删除
比较待删除结值与最后⼀个结点
如果待删除结点大于最后⼀个结点,比较交换后结点与其原先父节点,如果有必要,交换
如果待删除结点小于最后⼀个结点,比较交换后结点与其原先子节点,如果有必要,交换
重复上⼀步,直到⽗结点⼩于其原先⼦结点
堆化:
⽤O(n)的时间把⼀个乱序的数组变成⼀个堆,这一过程称之为堆化
将⼀个数组当成⼀个完全⼆叉树,然后从最后⼀个⾮叶⼦节点开始,逐个对⾮叶⼦节点进⾏下沉操作
当删除元素时,如果待删除结点小于最后⼀个结点,则比较交换后结点与其原先子节点,此时进行的就是堆化处理

若有收获,就点个赞吧
0 人点赞
