1. 斐波那契数列
斐波那契数列(Fibonacci Sequence),又称黄金分割数列。因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”
斐波那契数列指的是这样一个数列:1、1、2、3、5、8、13、21、34、55...。它从第三项开始,每一项都等于前两项之和。而实现这个数列的算法有很多种,每种算法都有各自的特点。我们可以通过实现一个斐波那契数列,对各种算法之间的特点进一步分析
1.1 递归算法
class FibonacciSequence {// 递归法func f(n : Int) -> Int {if(n < 3) { return 1; }return f(n: n - 2) + f(n: n - 1);}}
我们使用最简单的方式考量算法的性能,通过算法的执行代码行数评估
假设:n = 3,算法需要经过两次递归,分别执行2行代码。两次递归调用分别进行return,又执行了2行代码。所以当n = 3时共执行4行代码
当n为任意数字时,我们则需要将递归展开,才能完整的统计出执行代码的行数
假设:n = 5,依次递归的结果为1、1、2、3、5。将递归方法依次展开后,它会以二叉树的形态展示
结点f(5)下,有4个非终端结点和5个叶子结点。通过二叉树我们发现,叶子结点的数量,和左侧斐波那契数列的计算结果是一致的
在二叉树中,所有的叶子结点,代表的都是return 1的那一句代码。也就是说,所有的叶子结点执行代码的行数,等于斐波那契数列的计算结果,也就是f(n)的结果
而二叉树的另一个特性,非终端结点 = 叶子结点 - 1。依据这个特性,非终端结点执行代码的行数,应该等于f(n) - 1。但是,非叶子结点代表的是f(n: n - 2) + f(n: n - 1)这行代码,由于代码中使用了两次方法递归,所以正确的公式应该为(f(n) - 1) * 2,即:2(n) - 2
递归算法的执行代码行数,公式应为:f(n) + 2f(n) - 2,即:3f(n) - 2
按照示例中n = 5代入公式进行计算,f(n)的执行结果为5,即:3 * 5 - 2 = 13
所以当n = 5时,递归算法需要执行13行代码才可以计算出结果。同理,当n = 45时,f(n) = 1134903170,执行代码的行数为:3 * 1134903170 - 2 = 3404709508
由此可见,通过递归算法实现的斐波那契数列,执行效率非常差。原因在于它会重复计算一些已知的结果,我们可以通过其他算法对其进行优化
1.2 动态规划法
动态规划(Dynamic programming,简称DP),通过把原问题分解为相对简单的⼦问题的⽅式求解复杂问题的⽅法
动态规划法的三个核心要素:
找到最优子结构(可以将问题拆解,找到最优的拆解方式)
找到算法的边界(结束条件)
状态转移方程式
代码实现:
class FibonacciSequence {// 动态规划法func f(n : Int) -> Int {var arr = [Int].init(repeating: 1, count: n + 1);for i in 3 ... n {arr[i] = arr[i - 1] + arr[i - 2];}return arr[n];}}
- 动态规划法返回结果需要执行的代码行数,初始化的代码行数 + for循环的执行次数 + 循环内部代码的执行次数 + 返回结果的代码行数 =
1 + (n - 1) + (n - 2) + 1=2n - 1。当n = 45时,执行代码的行数为:89
上述代码中,我们使用额外空间记录了每一次的执行结果,属于空间换取时间的一种做法
一个算法所使用的空间复杂度,它和时间复杂度同样重要。例如:⼀个程序花费了很多时间,但是它仍然处于运⾏中,只是需要等待更⻓的时间。但是⼀个程序占⽤⼤量内存,它可能根本⽆法运⾏。此时,我们只能降低算法的空间复杂度
上述代码中,我们每次计算只需要n - 1和n -2这两步的结果,并不需要每一次的结果都存储。所以,我们可以对算法的空间进一步优化:
class FibonacciSequence {// 动态规划法 - 空间优化func f(n : Int) -> Int {var n1 = 1;var n2 = 1;for _ in 3 ... n {let sum = n1 + n2;n1 = n2;n2 = sum;}return n2;}}
- 优化后的代码,只使用一个临时变量作为额外空间,它进一步优化了空间复杂度。但它使得循环内部的代码量变多,这会导致代码的执行次数增长至
4n
我们评估这两种算法的优劣,需要有更确切的⽅式描述我们对算法分析的结构。即:大O表示法
大O表示法的意义,允许我们对算法⾏为的所有细节不那么在意。例如:算法3虽然⽐算法2慢⼀些,但是实际开发中算法2分配数组也需要⼀部份时间。这意味着在实际时间中,两种算法彼此更接近。但是对于算法3和算法1,会很明显得出4n⽐3f(n) - 2要好得多
所以,对于算法2和算法3来说,使用大O表示法,它们的时间复杂度都是O(n)
1.3 矩阵乘法
f(n)依赖于f(n - 1)和f(n - 2),将其依赖的状态存成列向量:
目标值f(n)所在矩阵为:
根据矩阵乘法,不难发现:
令:
根据递推式得: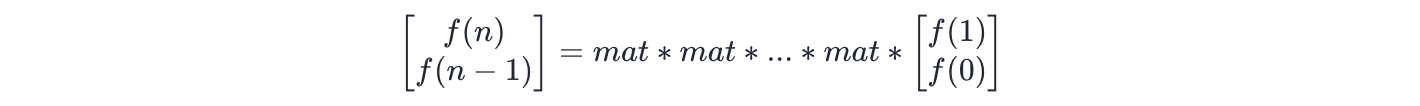
再根据矩阵乘法具有【结合律】,最终可得:
代码实现:
class FibonacciSequence {// 矩阵乘法func f(n : Int) -> Int {if(n < 3) {return 1;}let c = n - 1;var def = [[Int]].init(repeating: [Int].init(repeating: 1, count: 2), count: 2);def[1][1] = 0;var res = def;for _ in 1 ..< c {res = matrixMultiply(mat1: def, mat2: res);}return res[0][0];}fileprivate func matrixMultiply(mat1 : [[Int]], mat2 : [[Int]]) -> [[Int]] {var res = [[Int]].init(repeating: [Int].init(repeating: 0, count: 2), count: 2);for i in 0 ..< 2 {for j in 0 ..< 2 {res[i][j] = mat1[i][0] * mat2[0][j] + mat1[i][1] * mat2[1][j];}}return res;}}
时间复杂度:O(n)
空间复杂度:O(1)
由此可见,使用矩阵乘法,和动态规划法的区别并不大。我们针对时间复杂度,还可以进一步优化
1.4 矩阵快速幂
矩阵乘法在计算mat的n - 1次方时,如果直接求取,时间复杂度是O(n)。我们可以套用快速幂算法,加速这里的mat ^ (n - 1)的求解
快速幂:顾名思义,就是快速算底数的n次幂。其时间复杂度为O(log₂n),它与朴素的O(N)相比效率有了极大的提高
核心思想:就是每一步都把指数分成两半,而相应的底数做平方运算。这样不仅能把非常大的指数给不断变小,所需要执行的循环次数也变小,而最后表示的结果却一直不会变
例如:
3 ^ 10 = 3 * 3 * 3 * 3 * 3 * 3 * 3 * 3 * 3 * 3 = 590493 ^ 10 = (3 ^ 5) ^ 2 = 243 ^ 2 = 590493 ^ 5 = (3 ^ 4) * 3 = (81 * 3) = 2433 ^ 4 = (3 ^ 2) ^ 2 = 9 ^ 2 = 813 ^ 2 = (3 ^ 1) ^ 2 = 9
x ^ n,通过n计算m,即:m = n / 2如果
n为偶数,x ^ n = (x ^ m) ^ 2如果
n为奇数,x ^ n = ((x ^ m) ^ 2) * x
代码实现:
class FibonacciSequence {// 矩阵快速幂func f(n : Int) -> Int {var def = [[Int]].init(repeating: [Int].init(repeating: 1, count: 2), count: 2);def[1][1] = 0;var res = def;var odd = "";var n = n - 1;while(n > 1){odd = "\(n & 1)" + odd;n = n / 2;}for c in odd {res = matrixMultiply(mat1: res, mat2: res);if(Int("\(c)") == 1){res = matrixMultiply(mat1: res, mat2: def);}}return res[0][0];}fileprivate func matrixMultiply(mat1 : [[Int]], mat2 : [[Int]]) -> [[Int]] {var res = [[Int]].init(repeating: [Int].init(repeating: 0, count: 2), count: 2);for i in 0 ..< 2 {for j in 0 ..< 2 {res[i][j] = mat1[i][0] * mat2[0][j] + mat1[i][1] * mat2[1][j];}}return res;}}
- 使用快速幂算法来加速
x ^ n的求解,时间复杂度可优化为O(log n)
1.5 通项公式
根据斐波那契数列的通项公式: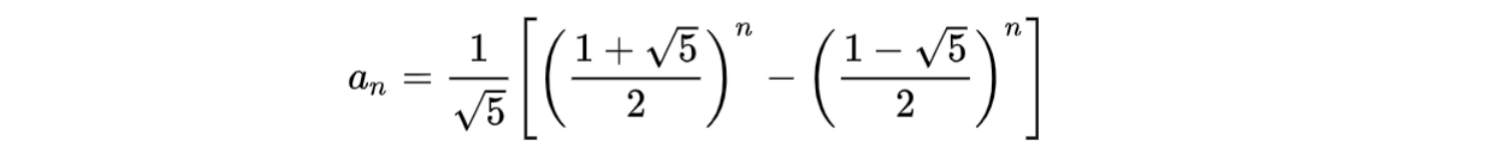
可以实现以下方法:
class FibonacciSequence {// 通项公式func f(n : Int) -> Int {let sqrt5 = sqrt(5);let res = pow((1 + sqrt5) / 2, Double(n)) - pow((1 - sqrt5) / 2, Double(n));return Int(res / sqrt5);}}
- 这种方式将时间复杂度优化至O(1)。但算法中使用了
sqrt和pow等数学函数,它们的计算也需要时间,所以它并不一定是最优算法
2. LRU算法
LRU(最近最少使⽤),是⼀种缓存淘汰算法。顾名思义,最⻓时间没有被使⽤的元素会被从缓存中淘汰
缓存有大小限制
一定是按照某种特定顺序存储数据,例如:最近最少使用的
可以使用数组进行顺序存储,或者使用链表进行链式存储
HashMap是典型的key-value存储结构,配合使用可将缓存的查找优化为O(1)缓存命中后要移动数据
2.1 方案分析
例如,我们有⼀个容量为3的缓存:
- 先后插入
数据8、9、6,此时缓存已满。如果再插入数据3,需要遵循LRU的规则,先将最⻓时间没有被使⽤的数据8删除,然后插入数据3
通过案例分析,我们发现LRU缓存的规则和队列(Queue)的数据结构很相似,它符合队列的先进先出原则。由于缓存的⼤⼩是有限的,该队列具有特定容量。当引⼊⼀个新元素时,它就会被添加到队列的尾部。而需要淘汰的元素,将被放在队列的头部
但使用队列也存在一些缺陷。由于每⼀项存储的是key-value形式,通过key取value时,需要遍历,它的时间复杂度和空间复杂度都为O(n)
2.2 方案优化
如果想将时间复杂度降低到O(1),仅使用队列是无法实现的
我们可以通过双向链表与Hash表结合使用: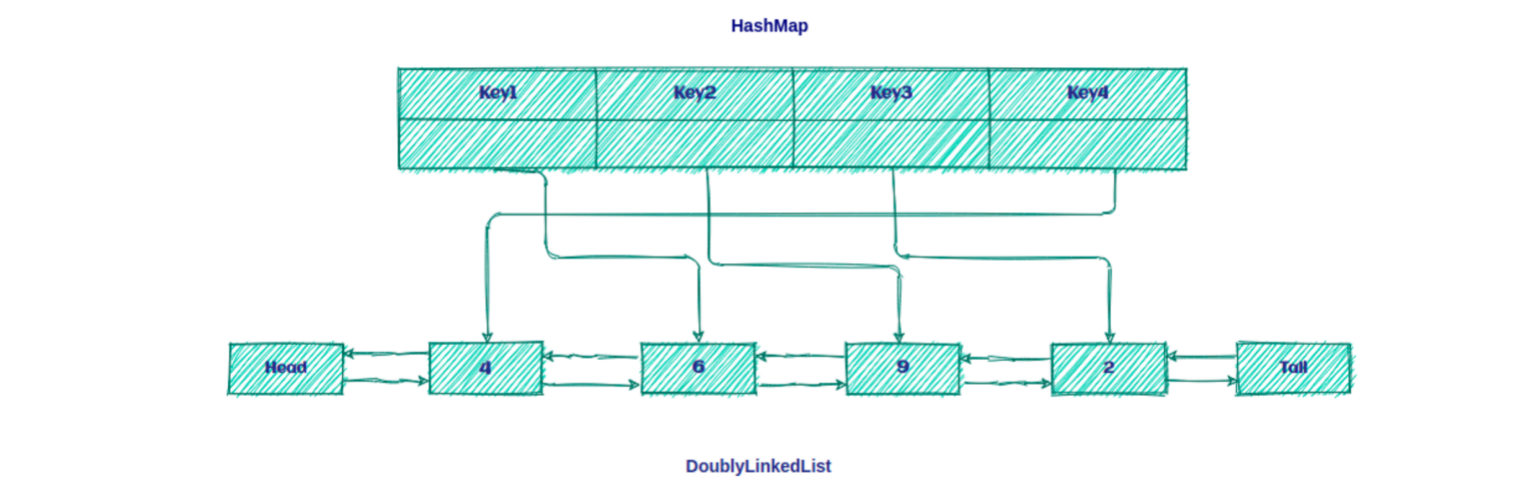
Hash表⽤来存储key-value,将缓存的查找优化到O(1)双向链表⽤来管理缓存顺序。双向链表具备头指针和尾指针,结点的数据结构中保存了前驱和后继,所以通过双向链表找到链表的头、尾,对结点进行插入、删除与移动,时间复杂度同样优化到O(1)
2.3 方案选择
使用双向链表与Hash表的方案,同样有它的缺陷。双向链表中的头结点与尾结点,以及每一个结点中的前驱和后继,都需要额外的存储空间,使内存的消耗大大提升
如果我们只需要一个⼩数据量的LRU,即使通过遍历查找,也不会过多的影响执行效率。此时可以考虑数组的使用,这样的方案代码实现简单,而且不会增加额外的空间成本
链表与数组的对比:
链表特点:查找麻烦,插⼊和删除容易
数组特点:查找容易,插⼊和删除困难
由此可见,每一种方案都会存在它的优势与劣势。所以我们要根据具体需求,从而选择出更适合的方案
2.4 数组方案
数组方案属于顺序存储,可以通过索引直接访问,不需要额外存储指针域,所以这个方案占用的内存更小。由于缓存查找需要遍历,而移动和删除操作困难,所以这个方案实现的缓存,容量不宜过大
2.4.1 缓存协议
创建LRUCacheProtocol.swift类,定义LRU缓存协议:
protocol LRUCacheProtocol {func getCacheValue() -> String;}
2.4.2 数据结构
创建LRULinear.swift类,定义缓存和结点对象的数据结构:
class LRULinear<Element: LRUCacheProtocol & Comparable> {fileprivate class Entry {var key : Element;var value : String;init(k : Element, v : String){key = k;value = v;}}// 总容量fileprivate var _numItems : Int;// 缓存数组fileprivate var _cache : [Entry]?;}
2.4.3 初始化 & 打印
实现缓存的初始化与打印方法:
class LRULinear<Element: LRUCacheProtocol & Comparable> {// 初始化init(capacity : Int){_numItems = capacity;_cache = [Entry]();}// 打印func traverse() -> String {var str = "";for entry in _cache! {str += "key:\(entry.key),value:\(entry.value)\n";}return str;}}
2.4.4 插入 & 读取
实现缓存的插入与读取:
func objectForKey(key : Element) -> String {// 1、遍历缓存for i in 0 ..< _cache!.count {// 获取当前缓存对象let entry = _cache![i];// 不匹配,跳过if(entry.key != key){continue;}// 2、匹配,更新缓存entry.value = key.getCacheValue();// 如果访问的缓存在队尾,说明是最新被使用的if(i == _numItems - 1){// 直接将缓存的值返回return entry.value;}// 否则,将该缓存从数组中删除_cache?.remove(at: i);// 然后将其重新添加至队尾,将其更新为最新使用_cache?.append(entry);// 最后将缓存的值返回return entry.value;}// 3、未能找到缓存,查看数组容量如果已满,删除头部数据,因为它是最⻓时间没有被使⽤的if(_cache!.count == _numItems){_cache?.remove(at: 0);}// 创建一个新的缓存对象let entry = Entry.init(k: key, v: key.getCacheValue());// 将其添加至队尾_cache?.append(entry);// 将缓存的值返回return entry.value;}// 3、未能找到缓存,查看数组容量如果已满,删除头部数据,因为它是最⻓时间没有被使⽤的if(_cache!.count == _numItems){_cache?.remove(at: 0);}// 创建一个新的缓存对象let entry = Entry.init(k: key, v: key.getCacheValue());// 将其添加至队尾_cache?.append(entry);// 将缓存的值返回return entry.value;}
2.4.5 代码测试
创建String+LRUCache.swift类,让String遵循LRU缓存协议:
extension String : LRUCacheProtocol {func getCacheValue() -> String{return "CacheValue-\(self)";}}
添加缓存并打印结果:
let cache = LRULinear<String>(capacity: 5);cache.objectForKey(key: "1");cache.objectForKey(key: "2");cache.objectForKey(key: "3");cache.objectForKey(key: "4");cache.objectForKey(key: "5");cache.objectForKey(key: "6");cache.objectForKey(key: "1");print("\(cache.traverse())");-------------------------//输出以下内容:key:3,value:CacheValue-3key:4,value:CacheValue-4key:5,value:CacheValue-5key:6,value:CacheValue-6key:1,value:CacheValue-1
2.5 链表 + Hash表
链表方案属于链式存储,可以很容易完成插⼊和删除操作,但是查找麻烦。使用Hash表配合,可以弥补查找的缺陷
2.5.1 链表介绍
链表是动态的线性数据结构,不可以随机访问数据,需要从头遍历。链表中的元素通常不存储在连续的位置。所以链表中的结点通常由数据 + 指针组成。所以该方案的执行效率最高,适合缓存容量较大时使用
链表种类:
单链表:
结点 = 数据 + 指针。指针指向下⼀个结点。单链表中的第⼀个结点和最后⼀个结点,分别叫做头结点和尾结点,只能从前往后遍历。尾结点是⼀个特殊的结点,它的指针总是指向NULL,代表结尾。头结点分为两种:有虚拟头结点,开发中经常使用,它的好处在于统⼀结点的操作⽅式,代码实现更⽅便
⽆虚拟头结点,在面临操作头尾结点时,需要增加额外判断,并进行特殊处理,使用相对麻烦
双向链表:
结点 = 前指针 + 数据 + 后指针,前指针和后指针分别指向当前结点的前趋结点和后继结点,允许我们从两个⽅向进⾏操作。头结点和尾结点都是虚拟结点循环链表:跟单链表相⽐,尾结点不在指向
NULL,⽽是指向头结点
对链表的操作有:
Insert插⼊结点Delete删除结点Search搜索结点
2.5.2 数据结构
创建LRULinked.swift类,定义缓存和结点对象的数据结构:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {fileprivate class Node {var key : Element?;var value : String?;// 前驱结点var prev : Node?;// 后继结点var next : Node?;init(){}init(k : Element, v : String){key = k;value = v;}}// 总容量fileprivate var _numItems : Int;// 当前长度fileprivate var _length : Int;// 虚拟头结点fileprivate var _head : Node?;// 虚拟尾结点fileprivate var _tail : Node?;// Hash表fileprivate var _hash : [Element: Node]?;}
- 为了操作方便,使用虚拟头结点和虚拟尾结点
2.5.3 初始化 & 打印
实现缓存的初始化与打印方法:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {// 初始化init(capacity : Int){_numItems = capacity;_length = 0;_head = Node();_tail = Node();_hash = [Element: Node]();// 头、尾结点默认连接在一起_head?.next = _tail;_tail?.prev = _head;}// 打印func traverse() -> String {var str = "";var node = _head?.next;// 从首元结点开始,遍历到尾结点结束,依次打印while(node?.key != nil) {str += "key:\(node!.key!),value:\(node!.value!)\n";node = node?.next;}return str;}}
2.5.4 插入 & 读取
使用头插法,将结点插入链表头部,同时插入到Hash表中:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {// 使用头插法,将结点插入链表头部,同时插入到Hash表中fileprivate func addNodeToHead(node : Node) {//将新结点插入到头结点和头结点的后继结点的中间// 当前结点的后继,指向头结点的后继结点node.next = _head?.next;// 头结点的后继结点的前驱,指向当前结点_head?.next?.prev = node;// 当前结点的前驱,指向头结点node.prev = _head;// 头结点的后继,指向当前结点_head?.next = node;// 将缓存插入到Hash表_hash![node.key!] = node;// 缓存的当前长度+1_length += 1;}}
删除链表中最长不时间被使用的缓存:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {// 从链表和Hash表中删除结点fileprivate func removeNode(node : Node) {// 将当前结点的前驱和后继相连,从而使它们和当前结点断开连接,相当于结点的删除node.prev?.next = node.next;node.next?.prev = node.prev;// 将结点从Hash表中删除_hash!.removeValue(forKey: node.key!);// 缓存的当前长度-1_length -= 1;}// 删除链表中最长不时间被使用的缓存fileprivate func removeTailNode() -> Node {// 获取尾结点let lastNode = _tail!.prev!;// 删除尾结点removeNode(node: lastNode);return lastNode;}}
将缓存移动到链表头部:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {// 将缓存移动到链表头部,表示该缓存是最长时间被使用的fileprivate func moveNodeToHead(node : Node) {// 得到首元结点let firstNode = _head!.next!;// 如果当前结点就是首元结点,说明已经是最长时间被使用的if(node.key == firstNode.key){// 什么都不做,直接返回return;}// 否则,先删除当前结点removeNode(node: node);// 然后将当前结点插入到链表头部addNodeToHead(node: node);}}
实现缓存的插入与读取:
class LRULinked<Element: LRUCacheProtocol & Comparable & Hashable> {// 插入 & 读取func objectForKey(key : Element) -> String {// 1、从Hash表中,通过key获取结点var node = _hash![key];// 判断结点是否已存在if(node != nil) {// 2、已存在,更新缓存node?.value = key.getCacheValue();// 移动结点到链表头部moveNodeToHead(node: node!);// 最后将缓存的值返回return node!.value!;}// 3、不存在,将缓存插入到链表和Hash表// 判断容量是否已满if(_length == _numItems){// 容量已满,删除链表中最长不时间被使用的缓存removeTailNode();}// 创建新结点node = Node(k: key, v: key.getCacheValue());// 将结点插入链表头部,同时插入到Hash表中addNodeToHead(node: node!);// 将缓存的值返回return node!.value!;}}
2.4.5 代码测试
添加缓存并打印结果:
let cache = LRULinked<String>(capacity: 5);cache.objectForKey(key: "1");cache.objectForKey(key: "2");cache.objectForKey(key: "3");cache.objectForKey(key: "4");cache.objectForKey(key: "5");cache.objectForKey(key: "6");cache.objectForKey(key: "1");print("\(cache.traverse())");-------------------------//输出以下内容:key:1,value:CacheValue-1key:6,value:CacheValue-6key:5,value:CacheValue-5key:4,value:CacheValue-4key:3,value:CacheValue-3
总结
斐波那契数列:
递归算法:执行效率非常差,原因在于它会重复计算一些已知的结果。时间复杂度:O(n ^ n)
动态规划法:通过把原问题分解为相对简单的⼦问题的⽅式求解复杂问题的⽅法。时间复杂度:O(n)
矩阵乘法:通过公式得知,利用
1110的矩阵进行n - 1相乘进行求解。时间复杂度:O(n)矩阵快速幂:每一步都把指数分成两半,而相应的底数做平方运算。这样不仅能把非常大的指数给不断变小,所需要执行的循环次数也变小,而最后表示的结果却一直不会变。时间复杂度:O(log₂n)
通项公式:通过通项公式直接求解,算法中使用了
sqrt和pow等数学函数,所以它并不一定是最优算法。时间复杂度:O(1)
LRU算法:
LRU(最近最少使⽤),是⼀种缓存淘汰算法。顾名思义,最⻓时间没有被使⽤的元素会被从缓存中淘汰缓存有大小限制
存储数据一定是按照最近最少使用的顺序
可以使用数组进行顺序存储,或者使用链表进行链式存储
HashMap是典型的key-value存储结构,配合使用可将缓存的查找优化为O(1)缓存命中后要移动数据
方案分析:
LRU缓存的规则和队列(Queue)的数据结构很相似,它符合队列的先进先出原则。由于缓存的⼤⼩是有限的,该队列具有特定容量。当引⼊⼀个新元素时,它就会被添加到队列的尾部。而需要淘汰的元素,将被放在队列的头部。但使用队列也存在一些缺陷。由于每⼀项存储的是key-value形式,通过key取value时,需要遍历,它的时间复杂度和空间复杂度都为O(n)方案优化:通过双向链表与
Hash表结合使用。Hash表⽤来存储key-value,将缓存的查找优化到O(1)。双向链表⽤来管理缓存顺序。双向链表具备头指针和尾指针,结点的数据结构中保存了前驱和后继,所以通过双向链表找到链表的头、尾,对结点进行插入、删除与移动,时间复杂度同样优化到O(1)。由于头结点和尾结点、前驱和后继结点都需要额外的存储空间,使内存的消耗大大提升方案选择:每一种方案都会存在它的优势与劣势。所以我们要根据具体需求,从而选择出更适合的方案
数组方案:数组方案属于顺序存储,可以通过索引直接访问,不需要额外存储指针域,所以这个方案占用的内存更小。由于缓存查找需要遍历,而移动和删除操作困难,所以这个方案实现的缓存,容量不宜过大
链表+
Hash表:链表方案属于链式存储,可以很容易完成插⼊和删除操作,但是查找麻烦。使用Hash表配合,可以弥补查找的缺陷。所以该方案的执行效率最高,适合缓存容量较大时使用

若有收获,就点个赞吧
0 人点赞
