1. 概述
KMP算法主要用来解决模式匹配的问题。核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的
本质是通过一个next数组,里面包含了模式串的局部匹配信息,找到模式串中各位置最适合的回溯位置
KMP算法的时间复杂度为O(m + n)
例如:查找出模式串在主串第⼀次出现的位置
主串:S = "banananobano"模式串:T = "nano"
2. BF算法
BF算法是普通的模式匹配算法,即暴力(Brute Force)算法
BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和T的第二个字符。若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果
BF算法是一种蛮力算法,时间复杂度:O(m * n)
代码实现:
class Solution {func getPosition(s: String, t: String) -> Int {// 控制主串的索引值for i in 0..<s.count {// 控制主串与模式串对比的位置var j = 0;// i + j位置不能超过主串长度// j位置不能超过模式串长度// 使用模式串位置j的字符,与主串位置i + j的字符对比while(i + j < s.count && j < t.count && s[i + j] == t[j]){// 满足以上条件,进行下一个字符的对比j += 1;}// 判断对比的位置是否达到了模式串长度if(j == t.count){// 达到,表示匹配成功,返回模式串在主串中的位置return i + 1;}// 否则,匹配失败// 判断主串未对比的剩余长度是否小于模式串长度if(s.count - i - 1 < t.count){// 小于,表示主串剩余的字符不够模式串长度,没必要继续比对// 结束循环break;}}// 返回位置不存在return -1;}}
2.1 ⾃动机与状态
BF的解题思路很像一部自动机,内置了几种状态,当输入的主串进入自动机,匹配到不同状态,我们就会得到一个相应的结果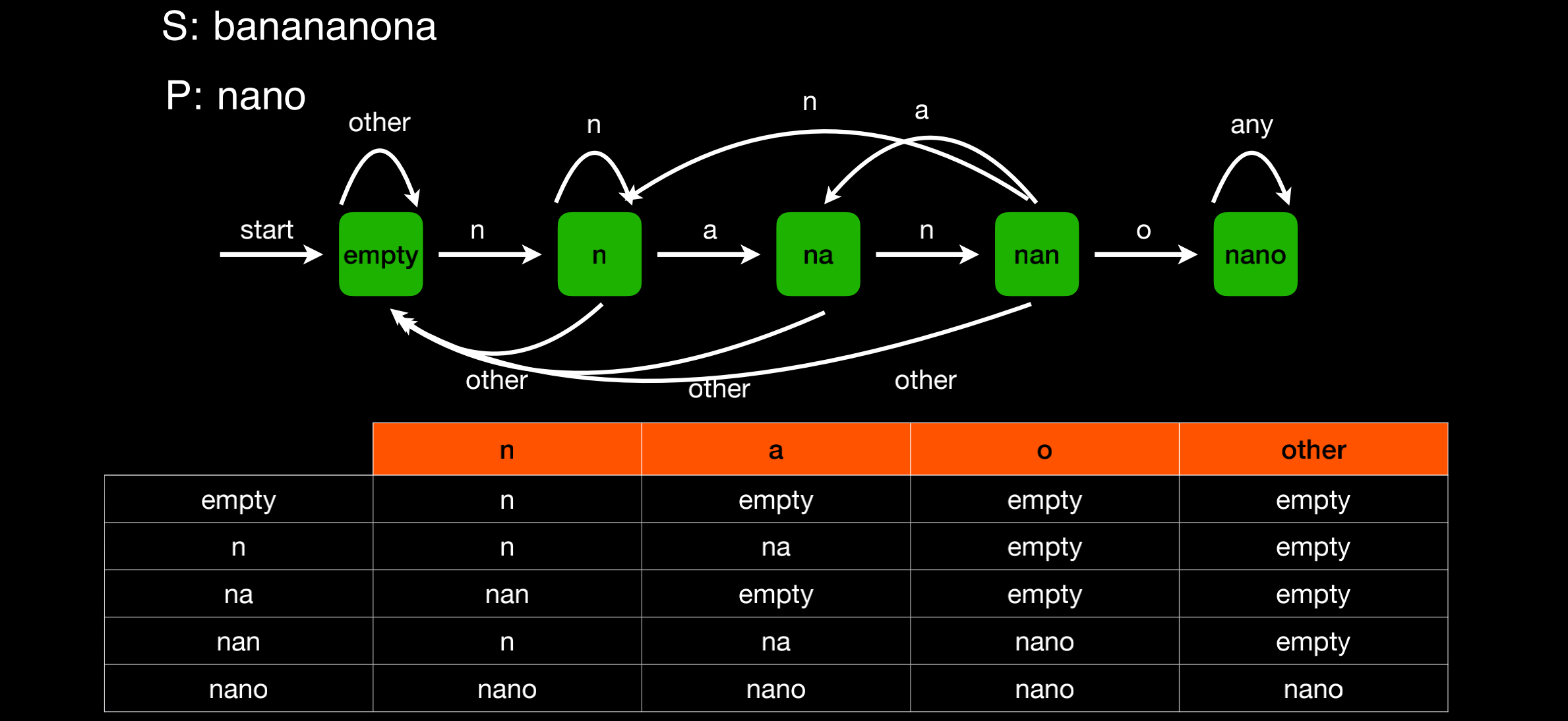
每一行中的第一列,表示内置的状态,一共有五种状态
第一行中,除了列头,其余四列表示进入的四种字符,每种字符对应不同状态,返回不同的结果
示例:
当状态为空时,进入的字符为n,命中第二行空的状态,符合第二列字符n,记录n的结果
假设再进入一个字符n,命中第三行n的状态,符合第二列字符n,覆盖n的结果
如果此时进入字符a,命中第三行n的状态,符合第三列字符a,记录na的结果
如果此时进入其他字符,例如:x,命中第三行na的状态,符合最后一列字符other,由于匹配失败,结果被清空
2.2 冗余对比
使用BF算法时,会出现一些冗余对比
在第3轮对比中,使用模式串的起始字符n与主串中字符a对比,此时就是一次冗余对比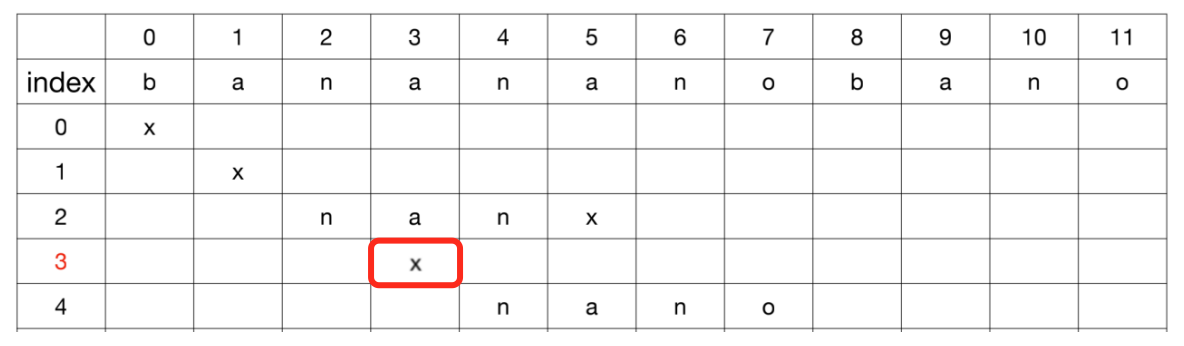
- 因为在
第2轮对比中,主串的2 ~ 4位置与模式串的nan匹配成功。所以,主串的位置3属于已知字符a,它一定不会与模式串的首字符n匹配
假设:可以跳过主串的位置3对比。直接进入主串位置4的n与模式串的起始字符n对比,仍然是一次冗余对比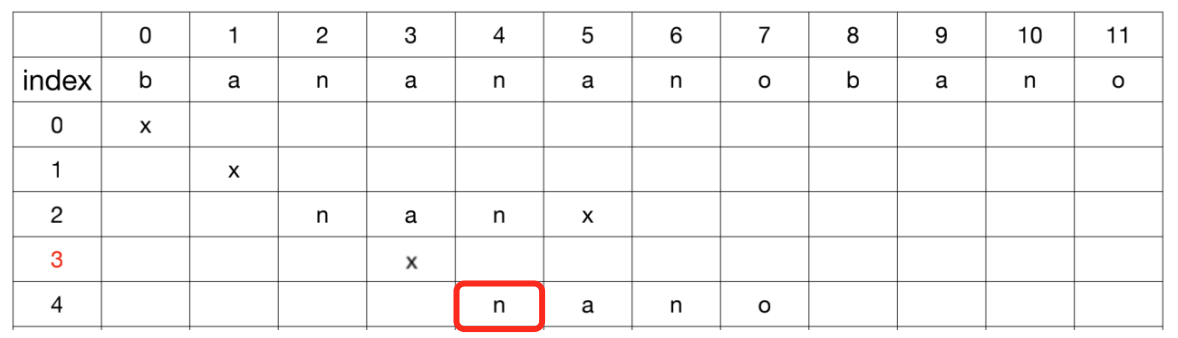
- 同样在
第2轮对比中,主串的位置4属于已知字符n,一定可以匹配模式串的首字符n,所以该字符的对比也可以跳过
从已知信息中得知,主串位置3与模式串起始字符一定匹配失败,所以应该跳过。而另一个线索,主串的位置4与模式串的首字符一定匹配成功,所以也应该跳过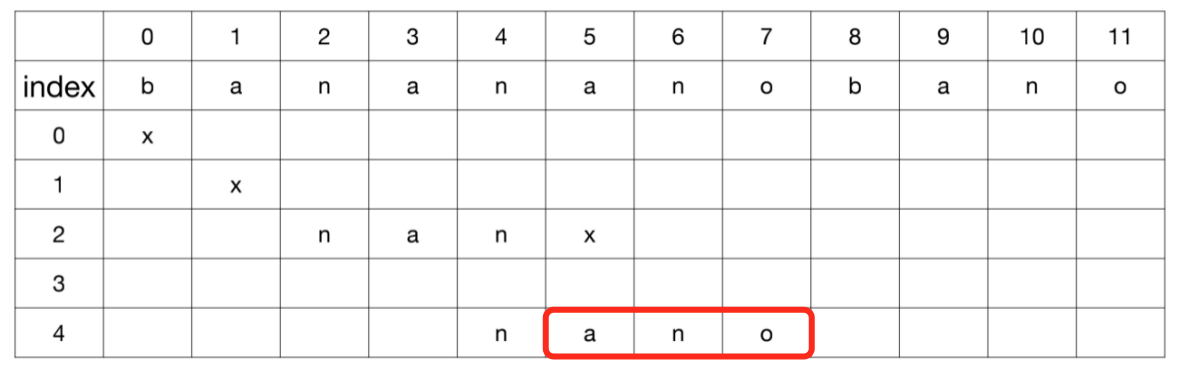
我们观察模式串,可以发现它的后缀与自身的前缀有重叠的字符n,此时重叠部分可以作为已知信息,使得下一次对比可以回溯到一个更为合理的位置上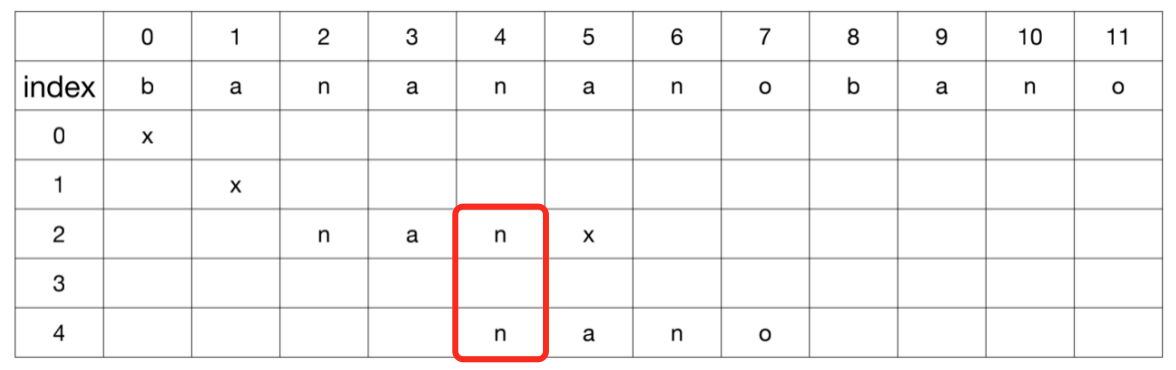
3. 重叠部分
KMP算法:主要用来解决模式匹配的问题。我们要找到模式串已匹配部分中的最大重叠值,并回溯到合理位置,需要基于以下两个规则:
模式串的后缀与前缀重叠的最⻓部分为
n,不允许模式串完全重叠。例如:ababa的最大重叠值为3,重叠部分为aba要跳过
i的值 = 最⼤重叠值
伪代码实现:优化主串和模式串的回溯位置,避免已知的重叠部分在下一轮对比中冗余对比
func getPosition(s: String, t: String) -> Int {var i = 0;var j = 0;while(i < s.count) {while(i + j < s.count && j < t.count && s[i + j] == t[j]){j += 1;}if(j == t.count){return i + 1;}// 最⼤重叠值j = overlap(t: "模式串中已匹配部分");// 如果c大于0,表示有重叠部分i += max(1, j);}// 返回位置不存在return -1;}
假设
overlap方法可以获取到模式串中已匹配部分的最⼤重叠值,当匹配失败后,将模式串j回溯到最⼤重叠值位置,将主串i后移最⼤重叠值位置主串后移时,如果
c为0表示没有重叠,则正常后移一位
使用KMP算法的时间分析:
⼀个外循环和⼀个内循环,所以看起来时间可能仍然是O(m * n)
T[i + j] == P[j]要么返回为真,要么为假返回为真时,会作为重叠部分在接下来的迭代中跳过
所以
S中的每个位置都只会涉及到⼀次⽐较外循环的每次迭代最多有⼀个错误⽐较
KMP算法最多进⾏2n次⽐较,并且花费时间O(n)
4. next数组
KMP的本质,就是通过一个next数组,里面包含了模式串的局部匹配信息,找到模式串中各位置最适合的回溯位置
对于主串和模式串的回溯位置,主串的i值始终向后移动。常规情况进行i + 最⼤重叠值处理,遇到特殊情况进行i + 1处理
对于模式串的j值,常规情况会根据最⼤重叠值进行回溯,遇到特殊情况回溯到起始位置
而j值的回溯过程,则类似于一部状态自动机的运转:
根据模式串nano,我们手动计算出每一个字符匹配失败后的回溯位置
n:-1,当首字符匹配失败,使用-1标记。-1会触发特殊处理,分别进行i + 1和j = 0na:0,当字符a匹配失败,将j值回溯到位置0,与主串继续匹配nan:0,当字符n匹配失败,将j值回溯到位置0,与主串继续匹配nano:1,当字符o匹配失败,将j值回溯到位置1,与主串继续匹配
5. 代码实现
获取next数组,预先计算出模式串中每一个子串的最大重叠值:
class Solution {// 获取模式串中每一个子串的最⼤重叠值fileprivate func overlap(t: String) -> [Int] {// 按照模式串长度创建next数组,默认填充-1var next = [Int].init(repeating: -1, count: t.count);// 从起始位置到小于n - 1位置,因为最⼤重叠值记录在n + 1位置for i in 0..<t.count - 1 {// 获取当前位置的最⼤重叠值let prev = next[i];// 假定当前字符是重叠的,最⼤重叠值+1var curr = prev + 1;// 如果最⼤重叠值等于0,表示没有重叠,无需修正// 否则,表示有重叠,需要检查假定是否成立// 查看当前字符与重叠位置的字符是否真的匹配// 由于重叠值记录的是重叠字符的长度,所以索引值要-1while(curr > 0 && t[i] != t[curr - 1]) {// 不匹配,修正最⼤重叠值// 从next数组中找到上一个位置的最⼤重叠值,同样假定当前字符是重叠的,在此基础上+1// 进入下一轮对比,如果不匹配,继续向前找,找到next[0]为止curr = next[curr - 1] + 1;}// 将最⼤重叠值赋值给next数组的n + 1位置next[i + 1] = curr;}// 返回next数组return next;}}
实现kmp算法,只需要进行主串的遍历,而i值永远向后移动:
class Solution {// kmp算法func kmp(s: String, t: String) -> Int {// 获取next数组let next = overlap(t: t);// 控制主串的索引值,永远向后移动var i = 0;// 控制模式串的索引值,根据next数组回溯var j = 0;// i位置不能超过主串长度while(i < s.count) {// 判断主串与模式串当前字符是否匹配成功if(s[i] == t[j]){// 成功,则i与j各自+1// 准备进行主串与模式串下一个字符的对比i += 1;j += 1;// 判断对比的位置是否达到了模式串长度if(j == t.count){// 达到,表示匹配成功,返回模式串在主串中的位置return i - j + 1;}// 还有后续字符需要对比,跳过循环,准备进入下一轮对比continue;}// 匹配失败,将j值设置为回溯位置j = next[j];// 如果j值为-1,触发特殊逻辑if(j == -1){// i值后移一位i += 1;// j值回到初始位置j = 0;}// 判断主串未对比的剩余长度是否小于模式串长度if(s.count - i - 1 < t.count){// 小于,表示主串剩余的字符不够模式串长度,没必要继续比对// 结束循环break;}}// 返回位置不存在return -1;}}
总结
概述:
KMP算法主要用来解决模式匹配的问题。核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的本质是通过一个
next数组,里面包含了模式串的局部匹配信息,找到模式串中各位置最适合的回溯位置KMP算法的时间复杂度为O(m + n)
重叠部分:
模式串的后缀与前缀重叠的最⻓部分为
n,不允许模式串完全重叠。例如:ababa的最大重叠值为3,重叠部分为aba要跳过
i的值 = 最⼤重叠值
代码实现:
获取
next数组,预先计算出模式串中每一个子串的最大重叠值next[0]固定为-1,表示特殊流程的标记i从起始字符开始遍历,next[i + 1]需要根据模式串的子串,通过前缀与后缀的匹配找到最大重叠值next[i]位置的最大重叠值,计算的是0 ~ i - 1范围的子串。例如:i = 4,next[i] = 2,模式串为ababc,计算重叠范围的子串实际上是abab子串在遍历过程中,每次都假定子串是重叠的,在上一个最大重叠值的基础上
+1,如果重叠值大于0,需要检查假定是否成立验证假定成立的依据,如果当前字符与
最大重叠值 - 1位置的字符相等,则表示假定成立否则,将其修正为
上一个最大重叠值 + 1。再次验证,直到假定成立,或者修正到next[0] + 1为止
实现
kmp算法,只需要进行主串的遍历,而i值永远向后移动当前字符匹配成功,则
i与j分别+1匹配失败,将
j值赋值为next[j]中的回溯位置如果
j为-1,触发特殊流程,i值向后移动一位,j值回到起始位置,继续下一轮的对比否则,
i值不变,j值移动到适当的回溯位置,继续下一轮的对比

若有收获,就点个赞吧
0 人点赞
