pytorch的自动梯度计算是基于其中的Variable类和Function类构建计算图,在本章中将介绍如何生成计算图,以及pytorch是如何进行反向传播求梯度的,主要内容如下:
- pytorch如何构建计算图(
Variable与Function类) Variable与Tensor的差别- 动态图机制是如何进行的(
Variable与Function如何建立计算图) - Variable的基本操作
- Variable的require_grad与volatile参数
- 对计算图进行可视化
所有源码都能在XavierLinNow/pytorch_note_CN这里获取
1. pytorch如何构建计算图(Variable与Function)
- 一般一个神经网络都可以用一个有向无环图图来表示计算过程,在pytorch中也是构建计算图来实现forward计算以及backward梯度计算。
- 计算图由节点和边组成。
- 计算图中边相当于一种函数变换或者说运算,节点表示参与运算的数据。边上两端的两个节点中,一个为函数的输入数据,一个为函数的输出数据。
- 而
Variable就相当于计算图中的节点。 Function就相当于是计算图中的边,它实现了对一个输入Variable变换为另一个输出的Variable- 因此,
Variable需要保存forward时计算的激活值。这个值是一个Tensor,可以通过.data来得到这个Variable所保存的forward时的计算值。 同时反向传导时,一个
Variable还需要保存其梯度。该梯度也是一个Variable,可以通过.grad来得到。2. Variable与Tensor差别
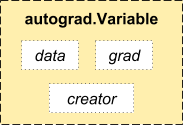
Tensor只是一个类似Numpy array的数据格式,它可以进行多种运行,但无法构建计算图Variable不仅封装了Tensor作为对应的激活值,还保存了产生这个Variable的Function(即计算图中的边),可以通过.creator(见图)来看是哪个Function输出了这个Variable- 在forward时,
Variable和Function构建一个计算图。只有得到了计算图,构建了Variable与Function与Variable的输入输出关系,才能在backward时,计算各个节点的梯度。 Variable可以进行Tensor的大部分计算- 对
Variable使用.backward()方法,可以得到该Variable之前计算图所有Variable的梯度 - Variable.data是该Variable前向传播的激活值,为一个Tensor
Variable.grad是该Variable后向传播的值,为一个Variable
3. 动态图机制是如何进行的(Variable和Function的关系)
Variable与Function组成了计算图
- Function是在每次对Variable进行运算生成的,表示的是该次运算
- 动态图是在每次forward时动态生成的。具体说,假如有Variable x,Function 。他们需要进行运算y = x x,则在运算过程时生成得到一个动态图,该动态图输入是x,输出是y,y的
.creator是* - 一次forward过程将有多个Function连接各个Variable,Function输出的Variable将保存该Function的引用(即.creator),从而组成计算图
在backward时,将利用生成的计算图,根据求导的链式法则得到每个Variable的梯度值
4. Variable的基本操作
生成Variable,Variable计算
from torch.autograd import Variable, Functionimport torch# 生成Variablex = Variable(torch.ones(2, 2), requires_grad=True) # requires_grad表示在backward是否计算其梯度print(x)print('-----------------------')# 查看Variable的属性.data, .grad, .creatorprint(x.data) # Variable保存的值print(x.grad) # 由于目前还未进行.backward()运算,因此不存在梯度print(x.creator) # 对于手动申明的Variable,不存在creator,即在计算图中,该Variable不存在父节点print('-----------------------')# Variable进行运算y = x + 2print(y)print(y.creator) # y存在x这个父节点,并且通过'+'这个Function进行连接,因此y.creator是运算+
Variable计算梯度
在引入Variable后,在forward时,我们生成了计算图,而backward就不需要我们计算了,pytorch将根据计算图自动计算梯度# 生成计算图x = Variable(torch.ones([1]), requires_grad=True)y = 0.5 * (x + 1).pow(2)z = torch.log(y)# 进行backward# 注意这里等价于z.backward(torch.Tensor([1.0])),参数表示的是后面的输出对Variable z的梯度z.backward()print(x.grad)# 此时y.grad为None,因为backward()只求图中叶子的梯度(即无父节点),如果需要对y求梯度,则可以使用`register_hook`print(y.grad)
5. Variable的require_grad与volatile参数
在创建一个Variable是,有两个bool型参数可供选择,一个是requires_grad,一个是Volatile
- requires_grad不是十分对该Var进行计算梯度,一般在finetune是可以用来固定某些层的参数,减少计算。只要有一个叶节点是True,其后续的节点都是True
- volatile=True,一般用在训练好网络,只进行inference操作时使用,其不建立Variable与Function的关系。只要有一个叶子节点是True,其后节点都是True
6. 对计算图进行可视化
生成了计算图,如何才能知道自己的计算图是否正确。可以利用graphviz包对计算图进行可视化。
步骤如下:
1. 安装graphviz包
2. 新建visualizer.py,编写如下代码from graphviz import Digraphimport reimport torchimport torch.nn.functional as Ffrom torch.autograd import Variablefrom torch.autograd import Variableimport torchvision.models as modelsdef make_dot(var):node_attr = dict(style='filled',shape='box',align='left',fontsize='12',ranksep='0.1',height='0.2')dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"))seen = set()def add_nodes(var):if var not in seen:if isinstance(var, Variable):value = '('+(', ').join(['%d'% v for v in var.size()])+')'dot.node(str(id(var)), str(value), fillcolor='lightblue')else:dot.node(str(id(var)), str(type(var).__name__))seen.add(var)if hasattr(var, 'previous_functions'):for u in var.previous_functions:dot.edge(str(id(u[0])), str(id(var)))add_nodes(u[0])add_nodes(var.creator)return dot
用如下方式进行调用
from utils.visualizer import make_dot# 生成一个计算图y = 0.5*(x + 1)^2; z = ln(y)x = Variable(torch.ones([1]), requires_grad=True)y = 0.5 * (x + 1).pow(2)z = torch.log(y)print(x)print(y)# 产生可视化计算图g = make_dot(z)g.view()
7. 例子
我们同样用一个简单的例子来说明如何使用Variable,在引入Variable后,我们已经不需要自己手动计算梯度了
from sklearn.datasets import load_bostonfrom sklearn import preprocessingfrom torch.autograd import Variable# dtype = torch.FloatTensordtype = torch.cuda.FloatTensorX, y = load_boston(return_X_y=True)X = preprocessing.scale(X[:100,:])y = preprocessing.scale(y[:100].reshape(-1, 1))data_size, D_input, D_output, D_hidden = X.shape[0], X.shape[1], 1, 50X = Variable(torch.Tensor(X).type(dtype), requires_grad=False)y = Variable(torch.Tensor(y).type(dtype), requires_grad=False)w1 = Variable(torch.randn(D_input, D_hidden).type(dtype), requires_grad=True)w2 = Variable(torch.randn(D_hidden, D_output).type(dtype), requires_grad=True)lr = 1e-5epoch = 200000for i in range(epoch):# forwardh = torch.mm(X, w1)h_relu = h.clamp(min=0)y_pred = torch.mm(h_relu, w2)loss = (y_pred - y).pow(2).sum()if i % 10000 == 0:print('epoch: {} loss: {}'.format(i, loss.data[0])) # 使用loss.data[0],可以输出Tensor的值,而不是Tensor信息# backward 我们直接使用Variable.backward(),就能根据forward构建的计算图进行反向传播loss.backward()w1.data -= lr * w1.grad.dataw2.data -= lr * w2.grad.dataw1.grad.data.zero_()w2.grad.data.zero_()

若有收获,就点个赞吧
0 人点赞
