Kubernetes网络的IPVlan方案
https://kernel.taobao.org/2019/11/ipvlan-for-kubernete-net/
背景及问题
云上构建容器网络一般有overlay bypass VPC和基于VPC两种方式。overlay方案的优点是不受vpc网络配额、创建响应速度的影响(例如路由表、路有条目数的限制,弹性网卡数量及创建速度限制等),缺点是因为多了一次的网络加解封装的开销,会使得网络复杂性的提升和性能的下降,也无法直接利用VPC提供的网络能力(如负载均衡、安全组等)。
基于VPC构建可以利用VPC原生的网络功能,性能较高、功能丰富,但同时需要处理VPC自身带来的一些限制。目前主要有VPC路由、弹性网卡、ENI多IP三种方案。VPC路由的方案受限于路由表创建数量支持的容器数量有限;弹性网卡方案性能可以接近vpc原生的网络性能但单台node上pod的数量存在限制;平衡性能和容器数量,ENI多IP应该是三个方案中最好的一种。基于ENI多IP构建容器网络一般有bridge, 策略路由, macvlan, ipvlan等多种方案,如下图。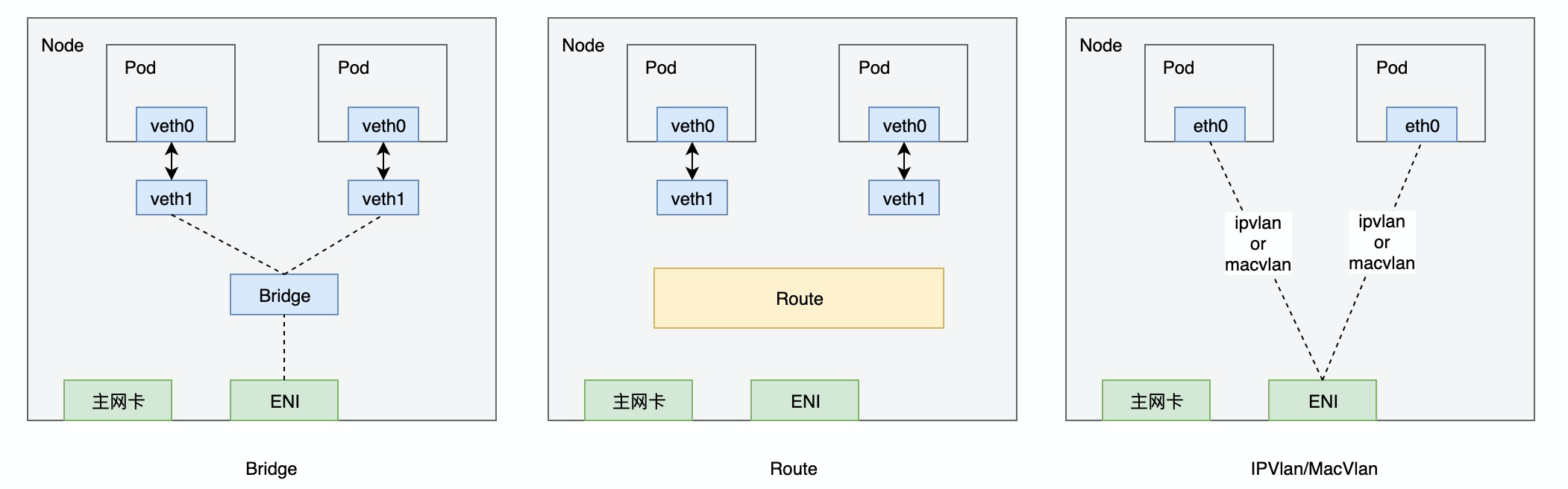
而因VPC往往会检测进入报文的源mac,使得bridge, macvlan无法很好的适配ENI多IP。策略路由通过了三层网络联调,不存在mac的问题,但性能下降较多。ipvlan可以较好的解决mac的问题,性能也不错,但在适配k8s的service网络却在不少问题。kube-proxy依赖host namespace的3层处理(iptables或ipvs),而ipvlan本身无法和host namespace交互而导致:
- L2模式下入出流量不会经过host namespace网络,无法支持kube-proxy
- L3模式但入方向不经过host namespace网络,无法支持kube-proxy
- L3S模式下入、出均经过host namespace的三层网络,但又会带来以下新的问题:
- 当service的client和server POD在一个master时,server的response报文会走ipvlan datapath, service访问失败
- L3S模式下流量从4层进入interface,无法支持kata等安全容器
- 当client和server在同一node时,导致同一方向流量多次进出host conntrack,datapath复杂,和iptables/ipvs也存在兼容性问题
考虑以上问题,设计了新的ipvlan方案,保证性能和高密度的优点同时使其可以兼容k8s的service网络。
方案设计
考虑Datapath的简洁性,方案采用ipvlan l2模式。通过linux route和tc识别service流量并导流到新的兼容kube-proxy的路径。方案设计如下图: 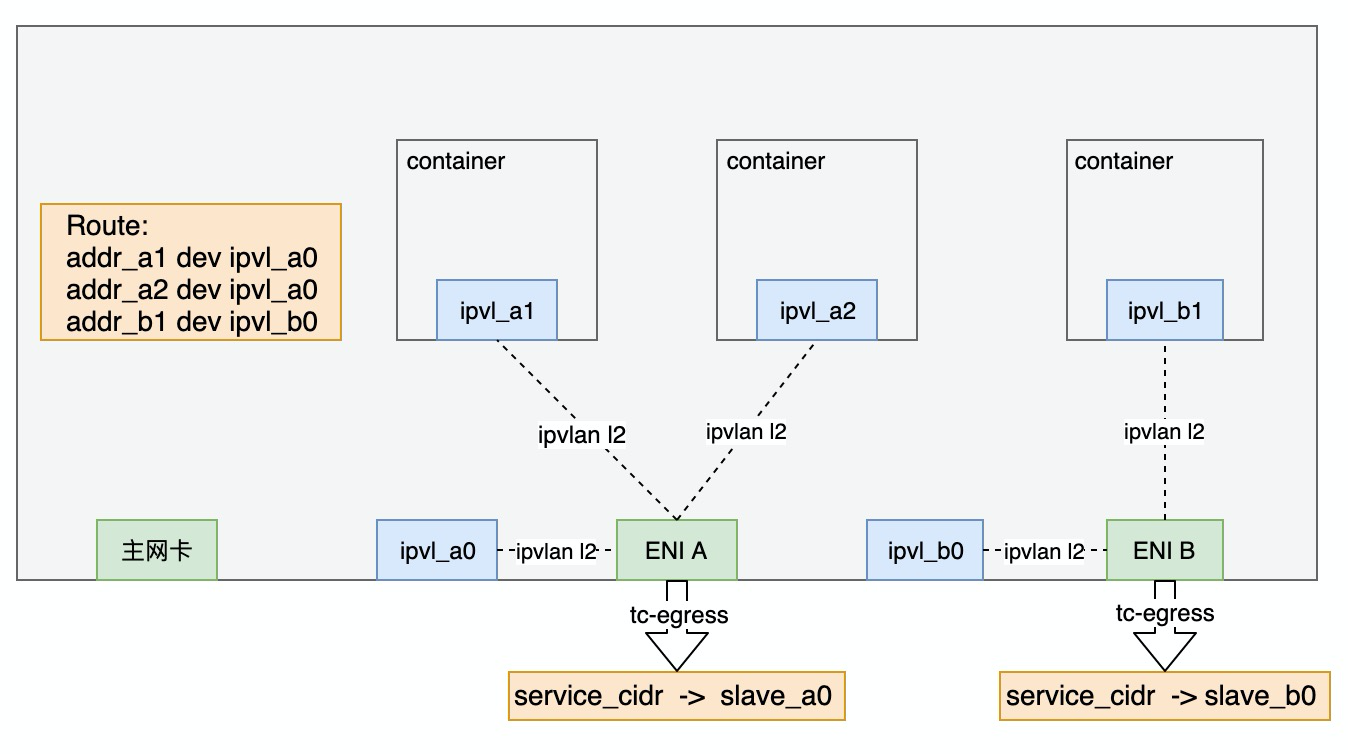
为每个ENI额外创建一个ipvlan子接口,置于host的namespace,例如图中的ipvl_a0, ipvl_b0。IP地址配置主网卡IP+32位掩码地址并设置scope为host。
MASTERIP=1.1.1.1/32 #主网卡IP地址ip link add link a0 name ipvl_a0 type ipvlan mode l2ip link add link b0 name ipvl_b0 type ipvlan mode l2ip link set ipvl_a0 upip link set ipvl_b0 upip addr add $MASTERIP scope local dev ipvl_a0ip addr add $MASTERIP scope local dev ipvl_b0
host namespace中配置host到Pod的路由,下一跳设置为host namespace中的slave接口
IP_A1= # ipvl_a1地址IP_A2= # ipvl_a2地址IP_B1= # ipvl_b1地址ip route add $IP_A1/32 dev ipvl_a0ip route add $IP_A2/32 dev ipvl_a0ip route add $IP_B1/32 dev ipvl_a0
每张eni网卡设置tc egress规则,将目的ip为service段的流量重定向到init namespace的slave网卡的ingress方向。考虑性能,使用无锁的clsact qdisc。
tc qdisc add dev $ENIA clsacttc filter add dev $ENIA egress proto ip u32 \match ip dst $SERVICE_CIDR \action tunnel_key unset pipe \action tc_mirred ingress redirect dev ipvl_a0
Datapath分析
Pod流量分析
跨Node的Pod间互访和普通的ipvlan l2路径相同,不做讨论。
同Node内Pod间互访,属于同一ENI则走ipvlan快速路径,属于不同ENI则通过vpc在eni间转发流量访问。 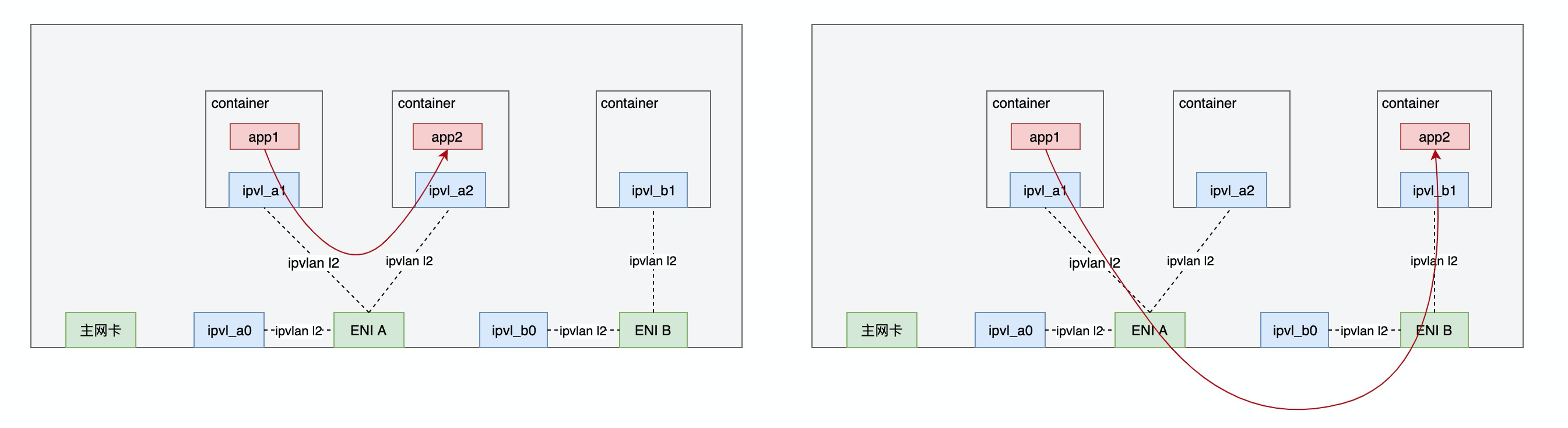
同Node内Node访问Pod, 通过查找路由表进入ipvlan的转发逻辑实现访问,Pod访问Node借助VPC在ENI网卡和主网卡间转发实现。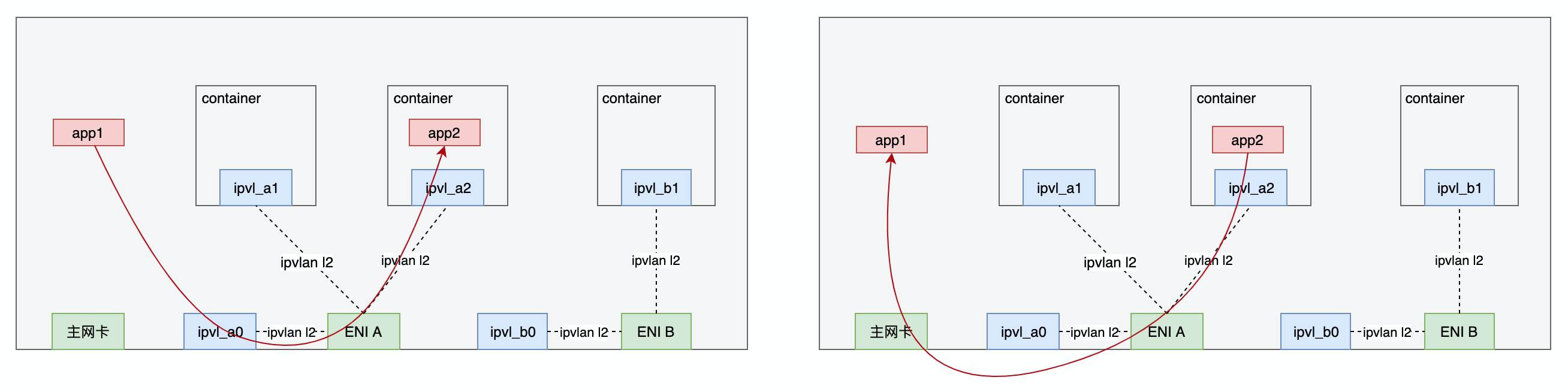
Service流量分析
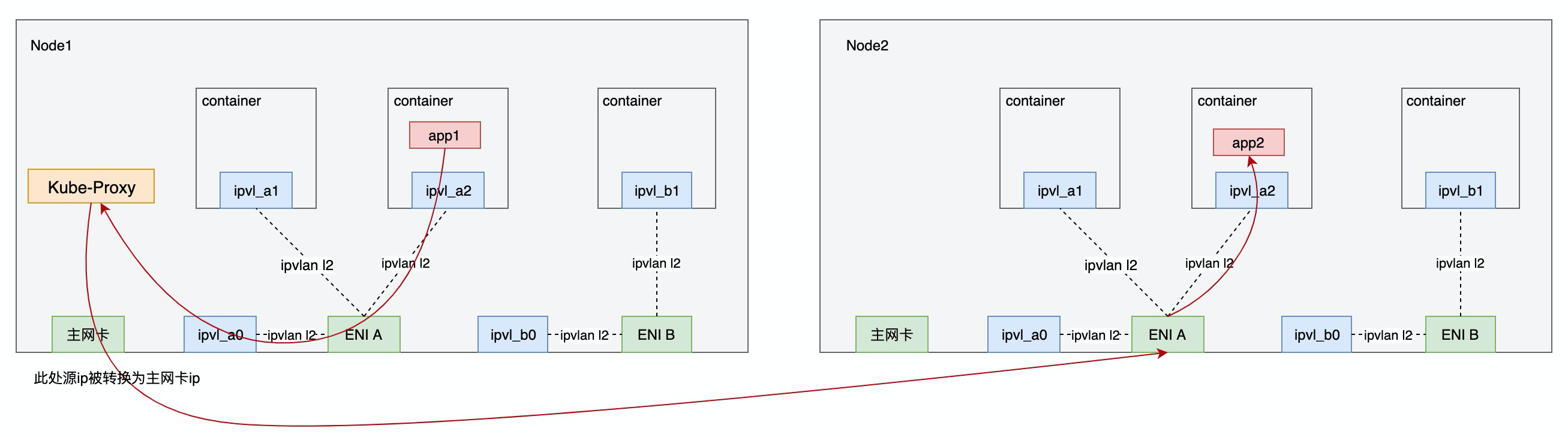
跨Node的Pod间互访,Request方向的流量处理可分三个阶段:
- 流量从Pod到ENI网卡的tc egress filter时,依据目的ip被识别为service流量,重定向到host namespace,从而进入kube-proxy的处理流程.
- kube-proxy(iptables或ipvs)依据负载均衡策略查找backend pod,修改目的ip为backend pod ip, 修改源地址为主网卡地址,经vpc转发至目的端ENI网卡。
- 经目的端ENI网卡的ipvlan处理进入backen pod。
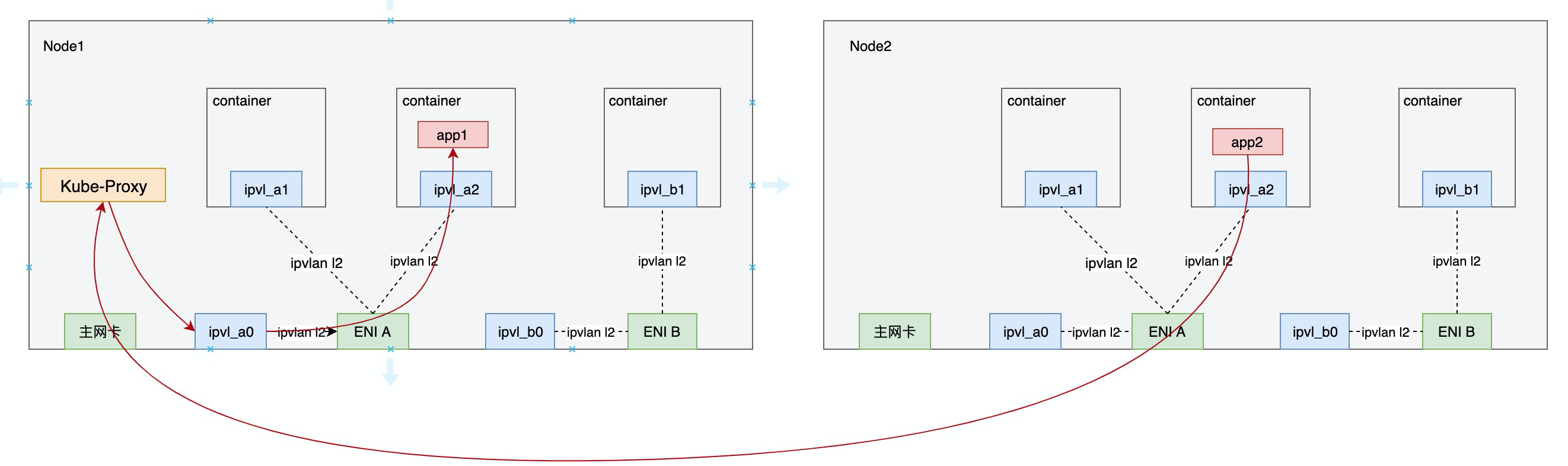
response方向与request方向相反:
- 流量从Backend Pod经ENI进入VPC,并转发至源Node的主网卡,进入kube-proxy
- 经kube-proxy处理,转换源ip为service ip, 目的ip为源pod ip,发送至host namespace的ipvlan slave网卡
- 经ipvlan处理进入源pod
跨Node的Node与Pod互访类似,不做进一步讨论。
同Node的Pod间互访分为两种情况,属于同一ENI和属于不同ENI。对于不同ENI的流量和跨Node Pod互访类似,不做进步一步讨论。
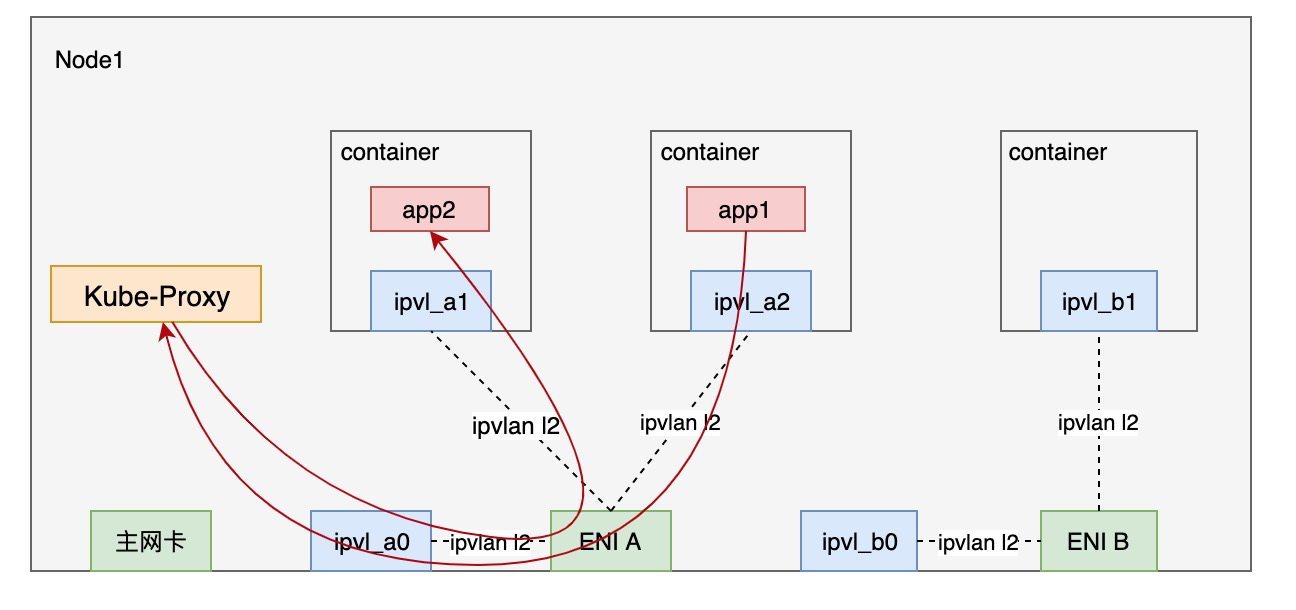
同一ENI下service流量处理Request方向分两个阶段:
- 流量从Pod到ENI网卡,被tc egress filter识别为service流量,重定向至host namespace。
- kube-proxy(iptables或ipvs)修改目的ip为backend pod ip,修改源地址为主网卡ip地址,经host namespace的slave网卡转发到backend pod
](pod-to-service-same-node.png)
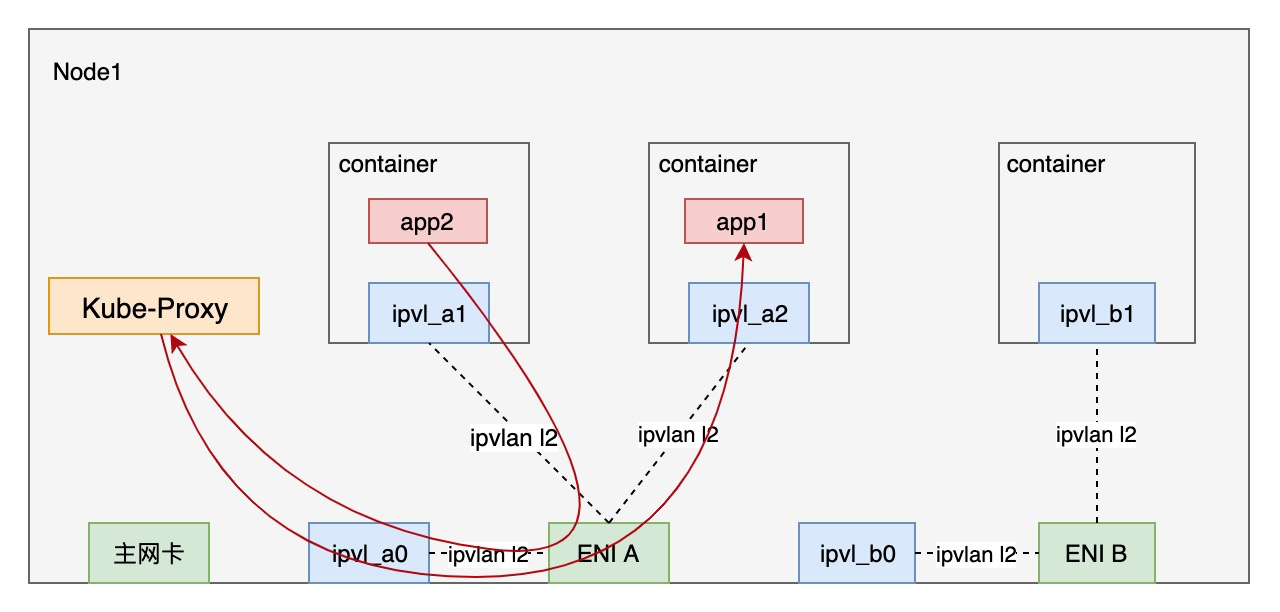
同一ENI下service流量的response方向相反:
- 流量从Backend Pod经ipvlan处理进入host namespace。
- kube-proxy修改源地址为service ip, 目的地址为源pod ip,经host namespace slave网卡进入源Pod.
性能测试
我们申请阿里云的神龙裸金属机型,对IPVlan、策略路由、ENI等三种容器网络方案做了性能对比,结果如下。
时延
时延采用ping,netperf做了测试。ping测试了普通模式和洪泛模式,netperf测试了tcp_rr, udp_rr两种模式。结果如下: 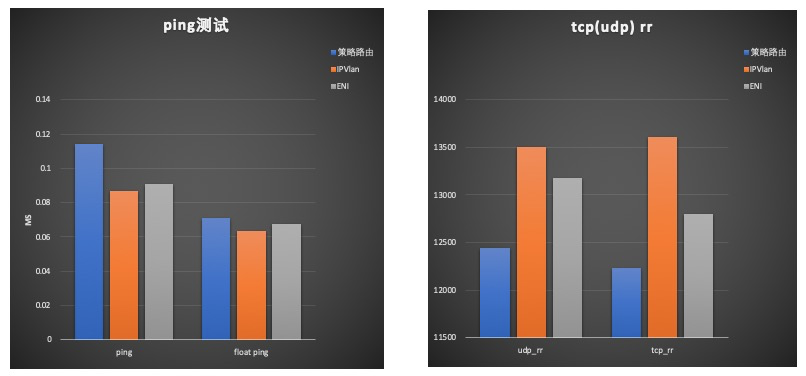 其中IPVlan, ENI模式较为接近。策略路由普通ping模式下约有20ns增加,洪泛ping模式7ns增加;udp_rr下降约8%、tcp_rr下降约10%。
其中IPVlan, ENI模式较为接近。策略路由普通ping模式下约有20ns增加,洪泛ping模式7ns增加;udp_rr下降约8%、tcp_rr下降约10%。
带宽
带宽测试采用netperf测试了tcp_stream和不同包长下的udp_stream, 结果如下: 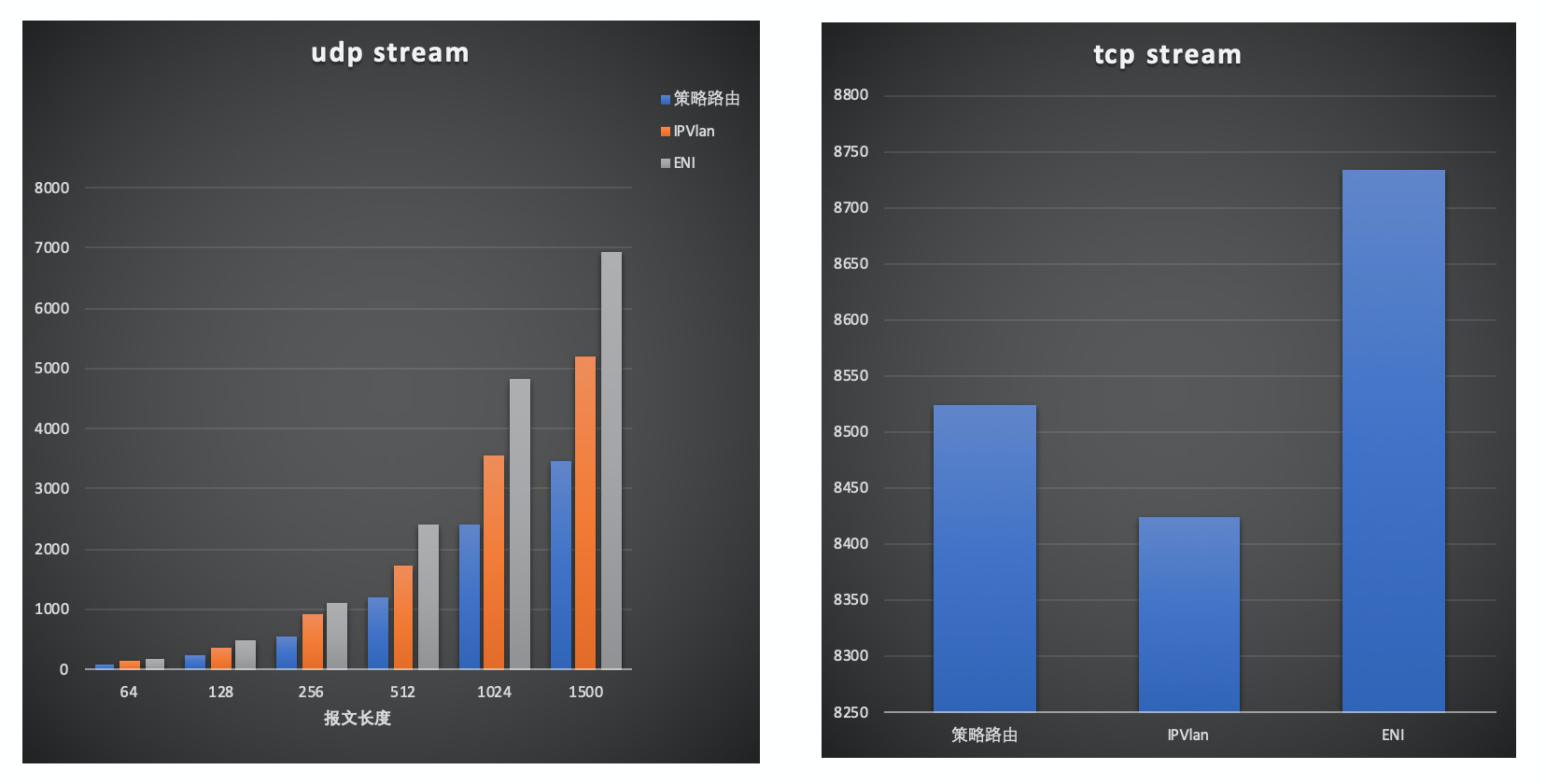
其中udp stream模式下ENI,IPVlan较为接近约0.02%以下,策略路由约7%左右。吞吐IPVlan比ENI约有25%下降,策略路由相比ENI约有50%下降。 tcp stream模式下由于gso, gro的加速,吞吐较为接近。
总结
在VPC ENI多IP基础上,我们通过IPVlan实现了一种既提高了单台ecs容器创建密度,又兼具性能和兼容K8S

若有收获,就点个赞吧
0 人点赞
