- 一、数制码制类
- 二、计算机组成基础知识
- 三、运算方法和运算器构成
- 四、指令集
- 五、16原型机设计
- 5. 指令中周期的含义 FT ST DT ET
- 6. !!!基于如下计算机的结构,能够分析出不同指令的数据通路,例如实现R2=R1+R0,
- 六、存储器结构
- 七、mips32设计
- 1.对于MIPS32 指令执行的流程总体步骤
- 2.MIPS32 内部的可用寄存器数量和位数
- 3.RISC和CISC构架,二者区别;MIPS属于什么构架
- 4.寄存器堆的结构,32个32位寄存器,两路数据出口,一路数据入口,两路出口的选择线,一路数据输入选择线
- 5.单周期和多周期cpu的特点
- 6.指令中数据通路设计的基本流程
- 7.单周期cpu的设计
- 8.控制器设计的不同结构:
- 9.组合逻辑和微程序控制器的特点
- 10.单周期cpu(组合)控制器的设计步骤
- 11.简化控制器设计难度的有效方法
12.多周期cpu的特点- 13.多周期cpu相对于单周期cpu的特点
- 14.多周期cpu的设计思路,流程
- 15.微程序控制控制信号产生的原理
- 16.一条微指令的结构,包含哪几个字段
- 17.能够根据给出的数据通路图设计出合理的微程序段(某一条指令)
- 18.能够根据给出的不同器件的延时时间评价单周期或多周期cpu在不同频率下的性能
19.多周期cpu的特点- 20.流水过程的含义
- 21.评价流水线性能的参数
- 22.常见超线程,多核的cpu以及特征
- 八、总线技术
- 九、IO设备

一、数制码制类
1.数制转换,牵涉到二进制,十进制,十六进制的转换
(数制底下不用想补足8位之类的事情,±该有就有,不要考虑什么最高位01代表正负数)
1310=( )16=( )2
-3F16=( )10=( )2
110102=( )16=( )10
-101102=( )16=( )10
2.简单BCD码变换
(常规BCD码不考虑负数,除非是某些设备特殊定义定义,本课程不讨论该型BCD码)。
本课程BCD码主要讨论压缩型BCD码(一个字节表示2个BCD码)
(10010011B)BCD = ( )10
(93H)BCD = ( )10
(34)10 = ( H)BCD
3.码制转换:原反补移码变换
(关于码制转换一定要注意字长),
其中移码要注意是移动了多少数据(这个没有固定数值,只要有数值位移都叫移码)
8位字长情况下,完成下列码制转换
+54 = ( )原 = ( )补
-93 = ( )原 = ( )补
+43 = ( )对于+128的移码 = ( )补
-200 = ( )原 = ( )对于+128的移码
4.!!!校验码
奇偶校验(注意奇校验和偶校验是不同的校验):增加冗余项使码中“1”的个数恒为奇偶
CRC校验:
海明码校验:取偶为例,从1开始编号;检验时按p4p3p2p1顺序无错给0有错给1得到0-1序列就是错误位置
1)被校验数据如下1001000110100101,对该数据做奇校验,偶校验。
1001000110100101 奇校验位,1001000110100101 偶校验位
2)CRC校验名称,在给定的生成多项式前提下计算被校验数的CRC码
被校验数为1101 生成多项式选用1001 ,求该数的CRC校验码
3)海明码的计算,海明不等式,完整海明码
被校验数据为10110010110,则根据海明不等式需要添加的校验位的个数为 位, 写出增加了校验位的海明码,校验位通过异或获得。(偶校验!)
4)自行设计简单的检错校验码,
这里要明白校验码的目的和实现手段。
比如累加校验、取异或/同或/与/或的操作都可以作为校验手段。
5.!!!浮点数的转换
要求能够根据IEEE754单精度浮点计算真实值和浮点数之间的转换

二、计算机组成基础知识
1.!!!计算机组成的五大部件
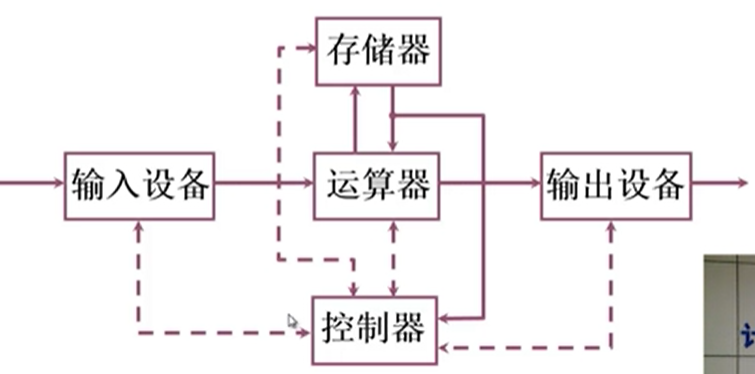
2.通常说的计算机的位数指的是什么
CPU中运算器的位数还是cpu中通用寄存的位数?
CPU位数 = CPU中寄存器的位数 = CPU能够一次并行处理的数据宽度 = 机器字长 = 数据总线宽度 =
≥ 操作系统位数 = 其所依赖的指令集位数(据指针类型的位数来定的)
3.影响计算机的性能指标的因素:9个小点
2量2时2效率3宽
| 吞吐量 | 某一时间间隔内能够处理的信息量 |
|---|---|
| 响应时间 | |
| 利用率 | |
| 处理器字长 | CPU(寄存器)位数 |
| 总线宽度 | 一般指CPU中运算器与寄存器之间进行互连的内部总线二进制位数。 |
| 存储容量 | 主存(内存/Memory)、辅存容量 |
| 存储器带宽 | 单位时间内从存储器读出的二进制数信息量 |
| 主频 CPU时钟周期 |
|
| CPU执行时间 | 执行一段程序 |
http://blog.sina.com.cn/s/blog_932ca1b2010174e6.html
4.!!!CPI含义,计算,MIPS计算
CPI:执行1条指令 需要的 时钟周期数
MIPS:单位时间内执行的指令数目
注意:CPI不随CPU频率变化而变化、与构架、程序设计有关
1)某计算机执行如下测试程序,求该计算机的CPI
| 指令类型 | 指令数目 | 每条指令时钟周期 |
|---|---|---|
| 整数指令 | 40000 | 2 |
| 传送指令 | 40000 | 1 |
| 控制指令 | 10000 | 1 |
| 浮点指令 | 10000 | 4 |
CPI=(400002+400001+100001+100004)/(40000+40000+10000+10000)=1.7
2)如1)所示,该CPU频率为100M,求出MIPS,CPU构架不变情况下,改变频率为200M,则MIPS和CPI的变化情况
MIPS变成2倍,CPI不变
3)能够简单分析不同系列cpu性能好坏,主要从MIPS角度
MIPS定义->主频高、CPI小
5)能够简单提出提高CPU性能的方法
不可改变测试程序中的指令配比。
提高频率:减少每条指令的周期数。更熟练的工人
增加制程:更多的工人:增加相同面积晶体管数量;7nm,14nm
提高吞吐量:一次性开多架飞机送货:并行运算;4核8核cpu(但受制于最终统一汇总验收货物时间)
为什么不把工厂造大:CPU的面积大,晶体管之间的距离变大,电信号传输的时间就会变长,运算速度自然就慢了。
重学计算机组成原理(三)- 进击,更强的性能! - 云+社区 - 腾讯云 (tencent.com)
三、运算方法和运算器构成
1.!!!能够绘制一位全加器的结构图和真值表
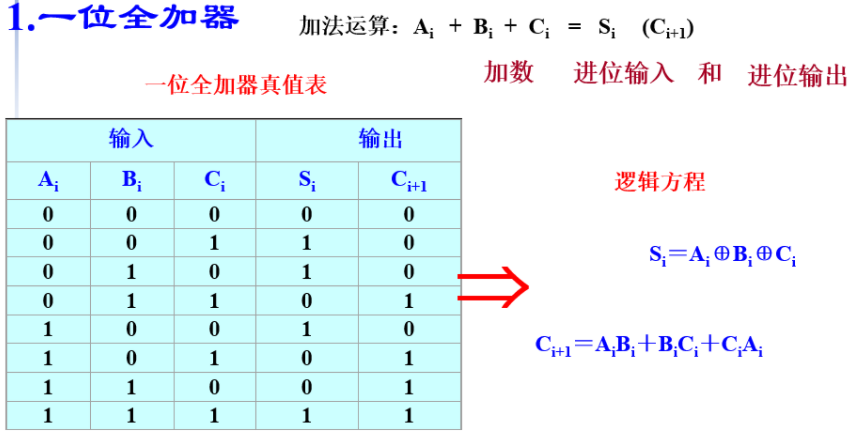
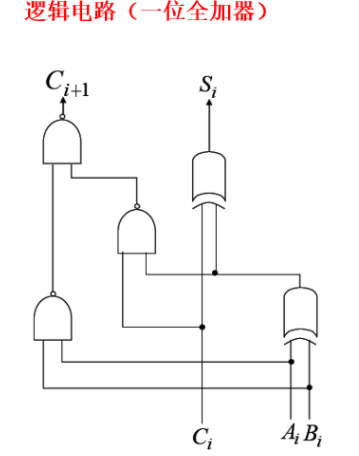
2.能够使用一位全加器构成8位全加器
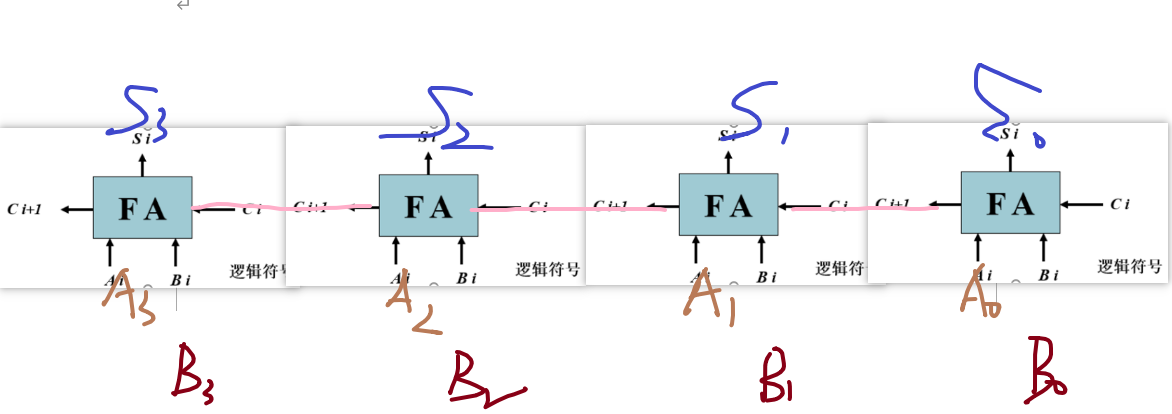
3.有符号数和无符号的溢出检验方法和判定电路
无符号:当最高为向更高位有进位(或借位)时产生溢出。
有符号:最高位进位⊕次高位进位(是标志寄存器的OF位判断方法以及加法器实现方法)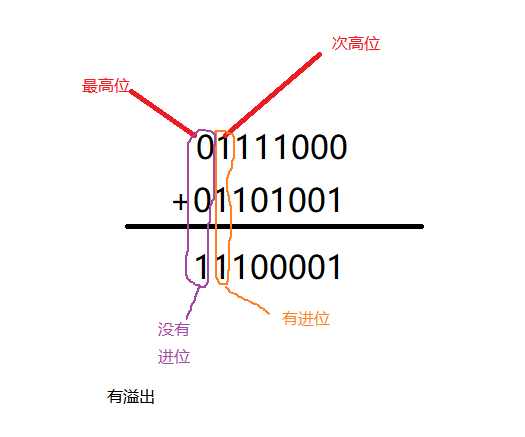
https://www.pianshen.com/article/3926818255/
以及:
4.!!!!基于补码的减法器的设计,如何从加法器扩展到减法器
5.一位乘法器的基本原理
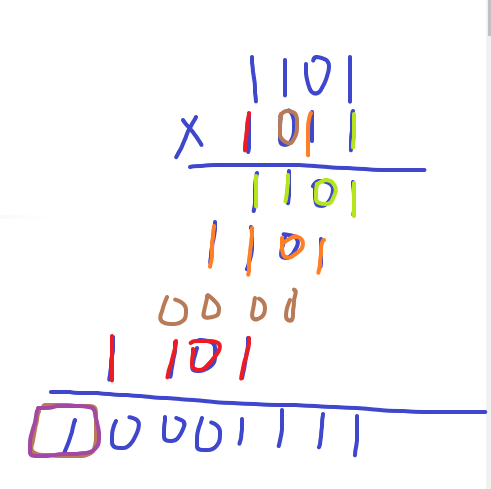
硬件乘法器的实现本质是“移位相加”。对于二进制,乘数和被乘数的每一位非0即1,相当于乘数中的每一位分别和被乘数的每一个体位进行与运算,并产生其相应的乘积位。这些局部乘积左移一位与上次的和相加。即从乘数的最低位开始,若其为1,则被乘数左移一位并与上一次的和相加;若为0,左移后以全零相加,如此循环至乘数的最高位。
四、指令集
1.掌握最基本的MIPS32指令集
| ADD | |
|---|---|
| SUB | |
| OR | |
| AND | |
| ADDI | |
| ANDI | |
| BEQ | 如果相等,发生转移 |
| J | 跳转(无条件转移) |
| SW | 存操作数 |
| LW | 取操作数(从内存读进寄存器) |
等
编程要用到的指令集会给
2.!!!能够编写基于1的小程序段
MIPS可以通过赋值的方法赋值,但唯独没有赋值这项功能。
如
$1=$0-$0 但不能$1=0;
又如
ADDI $1,$0,100 实现$1=100的功能
再如
lw $S1,imm($2) 实现取操作数
lw $s1,$s2($s3) 就是从地址[$s3+$s2]处加载一个字的内容到寄存器$s1
x: .word 0 是定义一个变量x(x实际上是一个标号),大小为一个字,初始值为0
lw $s1,x($s2) 是从地址[x+$2]处加载一个字的内容到寄存器$s1
MIPS指令
3.MIPS32的每条指令的长度,是否固定长度?
固定32位:R / I(立即数) / J(转移)
4.!!!按操作数的类型分,MIPS32指令集可分为 R,I,J型指令,掌握不同类型指令的格式(位段)表
| [31:26]
op
操作码 | | | [25:21]
rs | | [20:16]
rt
| [15:11] rd 目标寄存器 |
[10:6] sa 移位时用的常数 |
[5:0] func 功能码 |
|||||||
|---|---|---|---|---|---|---|---|---|---|
| [31:26] op |
[25:21] rs |
[20:16] rt 目标寄存器 |
[15:0] imm |
||||||
| [31:26] op |
[25:0] address |
5. 程序员、计算机使用者能使用的计算机(指令?微指令?微命令?)
五、16原型机设计
1.CPU的设计步骤(详见16位机设计,5步骤)
拟定指令系统:格式、寻址方式、指令类型设置
确定总体结构: 寄存器、ALU、数据通路设置
安排时序:寄存器传送级
拟定指令流程和微命令序列:
形成控制逻辑:微程序or硬布线技术(组合逻辑、时序逻辑)
2.74LS181和74LS182的作用
181能执行16种算术运算和16种逻辑运算 (编码器,函数产生器)
182:超前进位产生器

3.设计计算机时,主要将计算机分为哪些部件设计(运算器,寄存器,控制器,存储器)
4. IR,MDR,MAR,PC的名称及作用
主存:
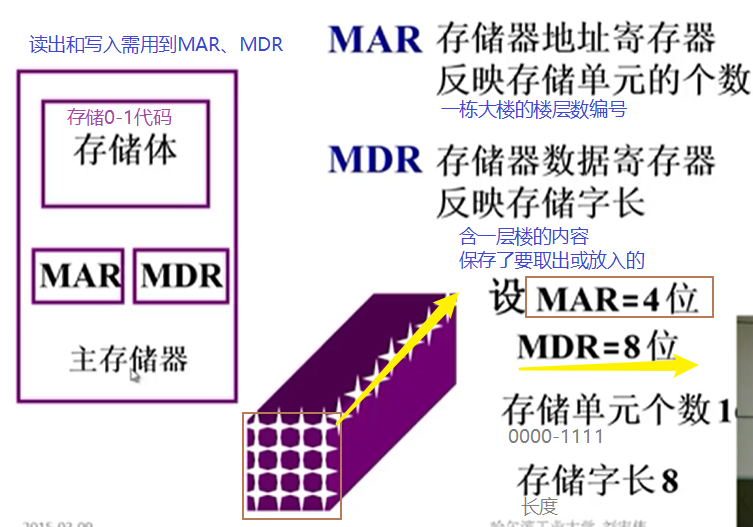
控制器
IR:指令寄存器
PC(程序计数器/指令指针)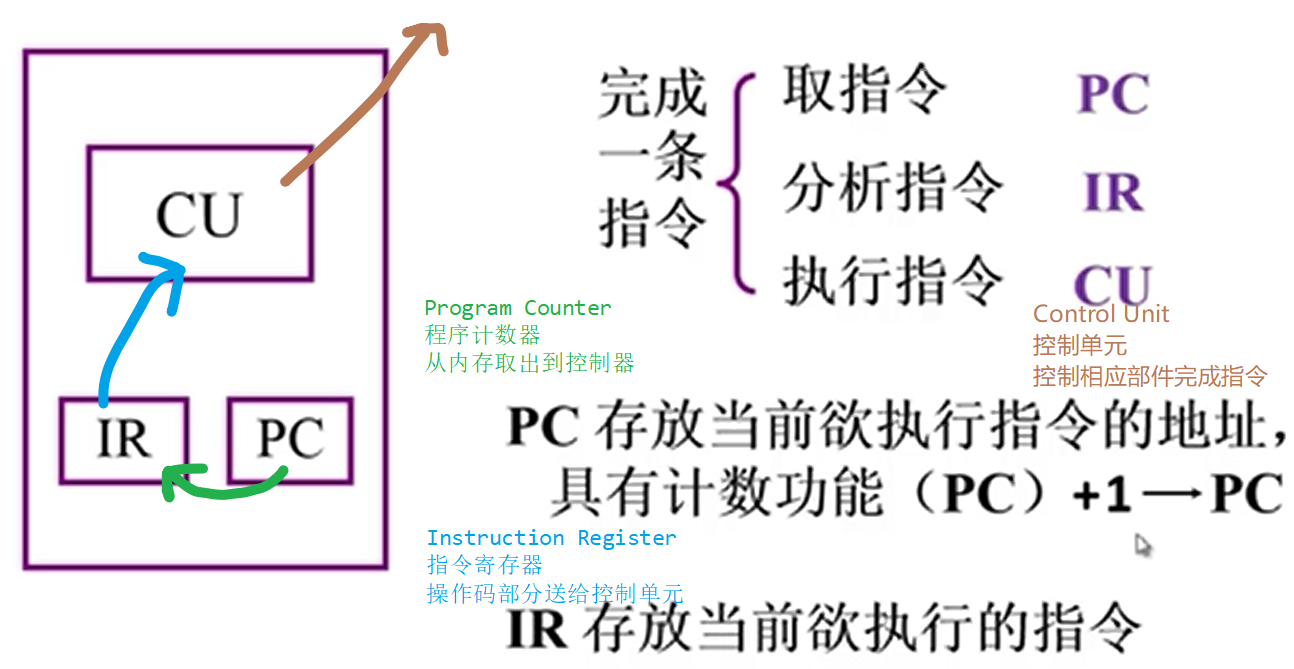
5. 指令中周期的含义 FT ST DT ET
FT取指周期
ST源周期
DT目标周期
ET执行周期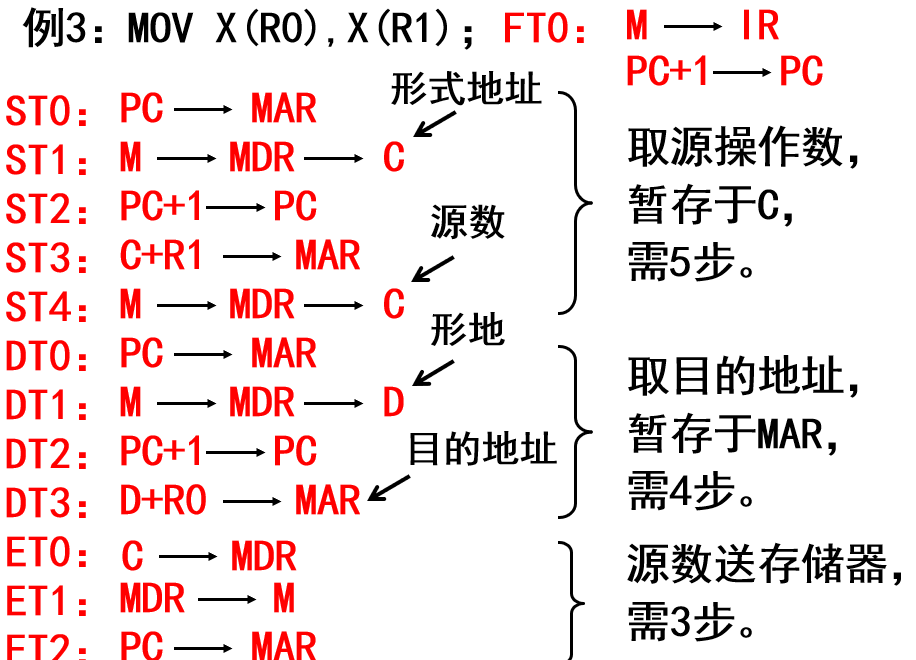
6. !!!基于如下计算机的结构,能够分析出不同指令的数据通路,例如实现R2=R1+R0,
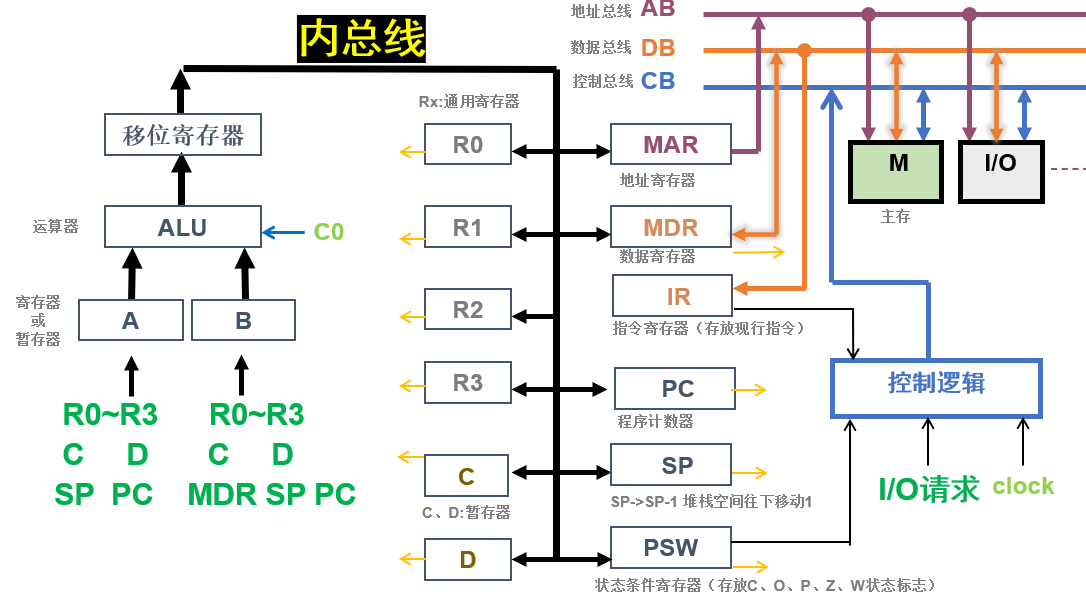

六、存储器结构
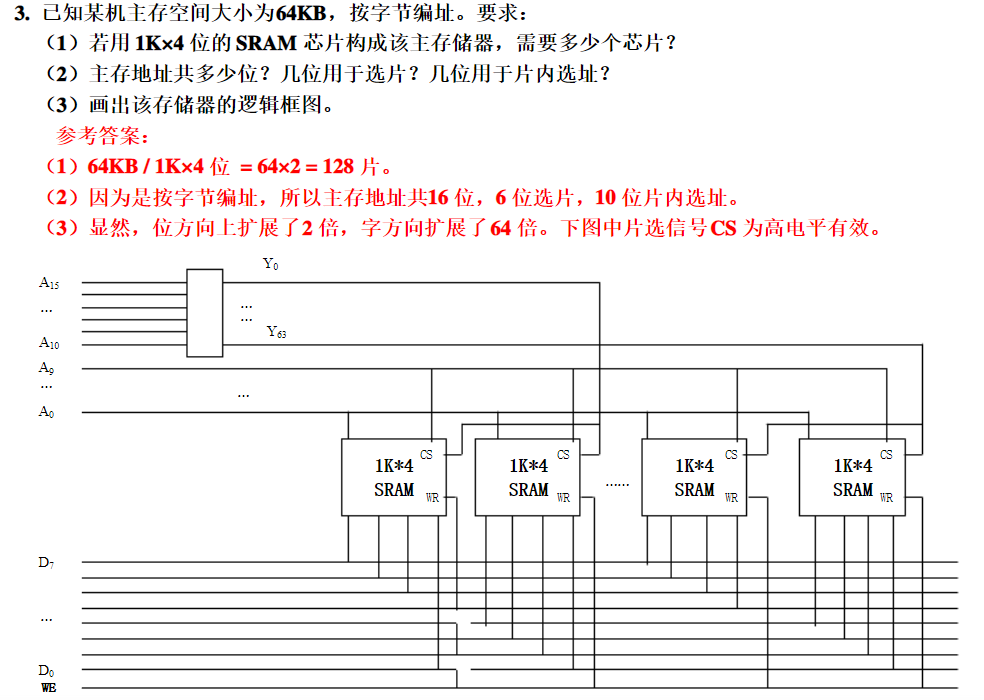
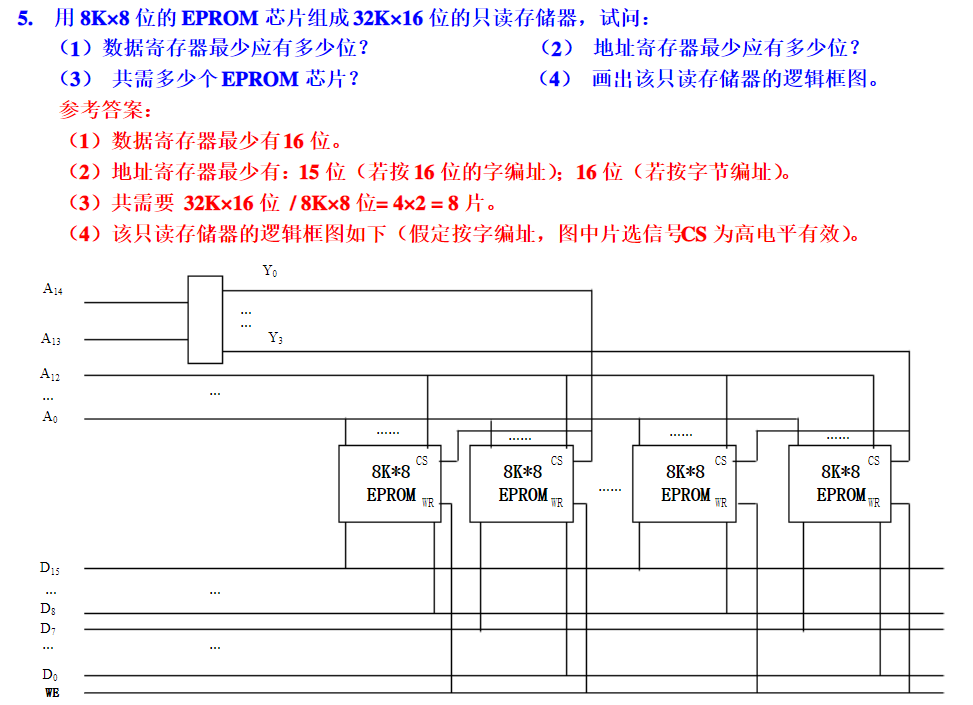
1.半导体存储器的分类
2!!!半导体存储器的扩展
能计算字扩展,位扩展,字位扩展的芯片数量,能够绘制字扩展或者位扩展的连线图,连线仅限于必要信号线
给出芯片(有多余,自选适用部分)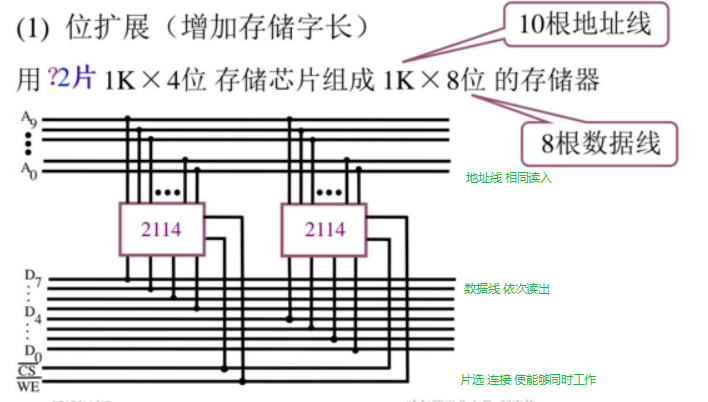
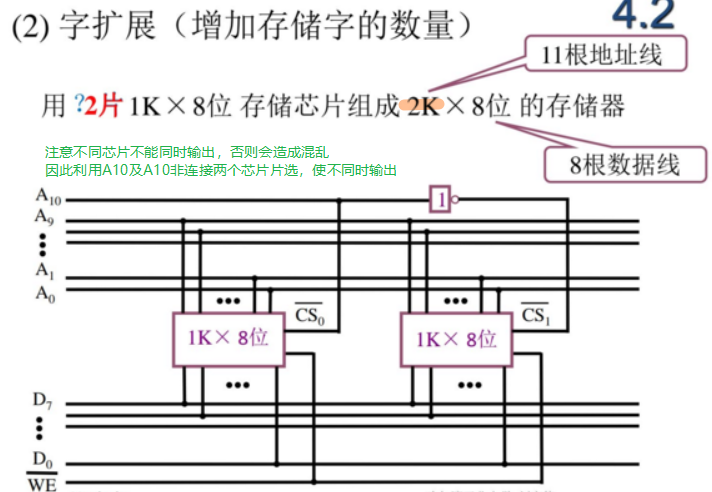
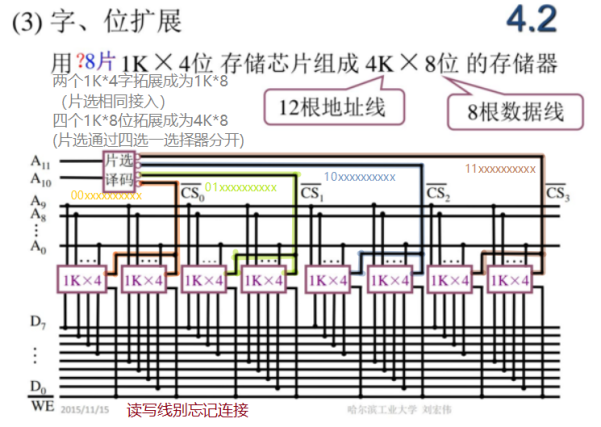
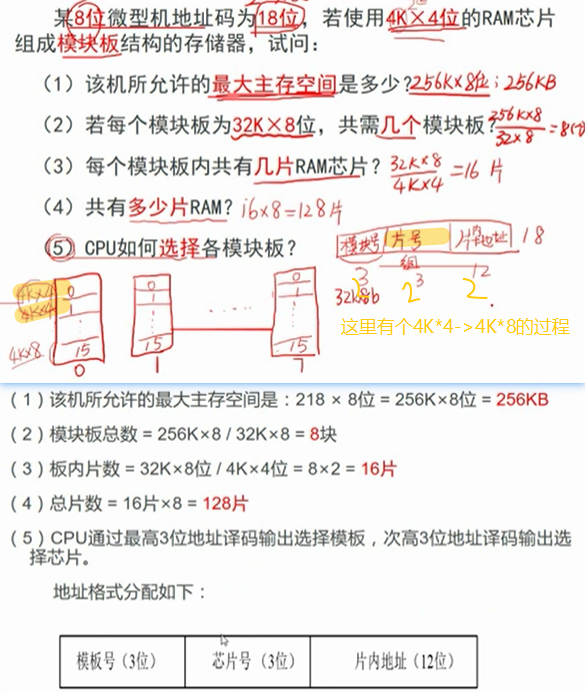
3.存储器的分级管理
三级存储体系包括哪些,基于的基本原理(程序局部性原理)
高速缓冲存储器、主存储器、辅助存储器
即:Cache存储器、主存、辅存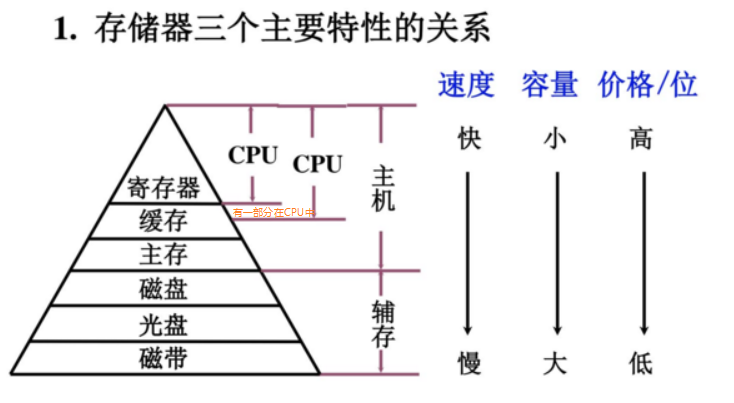
4.!!!cache-主存系统的组织结构
映射方式,替换方式(替换方式基于全相连映射),
要掌握给定访问块序列情况下,不同替换方式下的命中率。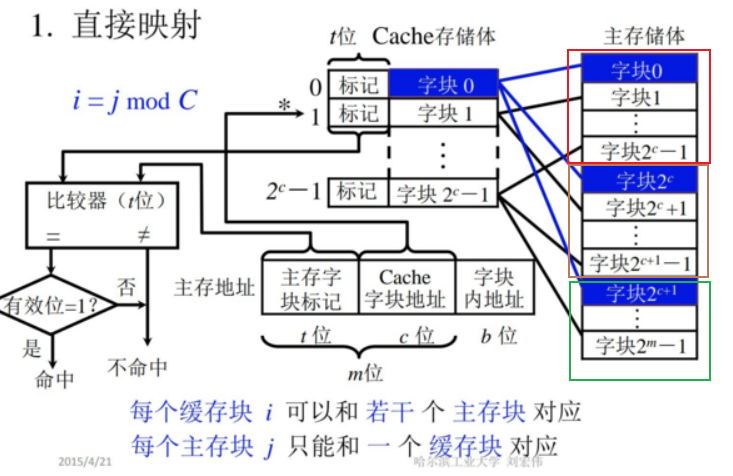
缺点:Cache利用率不高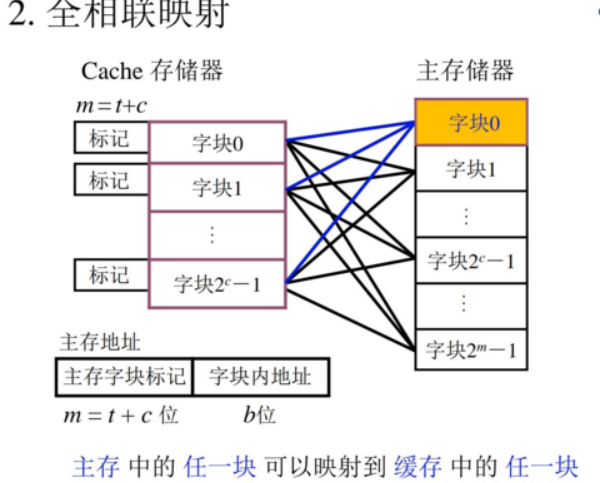
缺点:比较器长度长,速度慢(全部要比较)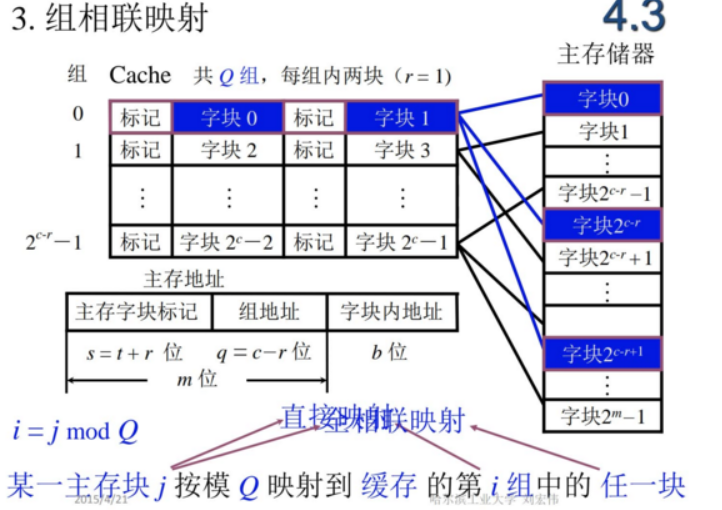
当Q=1时,变成全相联;
当r=1时,变成直接映射。
实际计算机中有多个Cache,靠近CPU的往往强调速度,会用直接映射或路数少的组相联映射;远离CPU的可能会倾向于使用全相联以提高利用率。
替换算法
先进先出FIFO算法:替换最早放入的
近期最少使用LRU算法:替换最少使用的(计数器)
LRU: 最近最少使用,以最近一次访问时间为参考。
LFU: 最近一次被访问次数最少的数据,以次数为参考。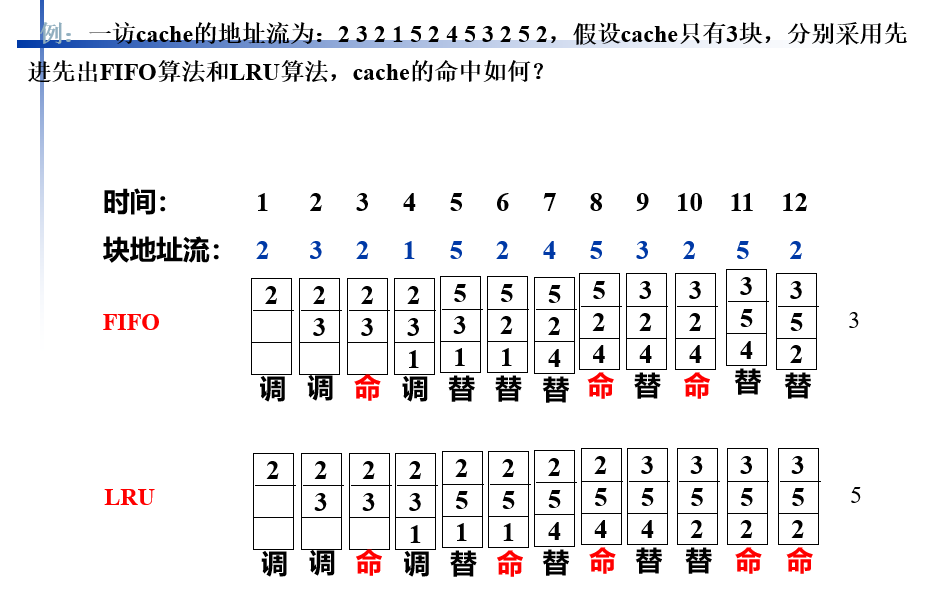
LRU命中率最高
5.cache的写操作方法

6.虚拟内存系统的作用
把外存(辅存)当做内存(主存)来使用,提高资源使用率
读写速度远低于内存
7.!!主存-虚存系统与cache-主存系统的异同点
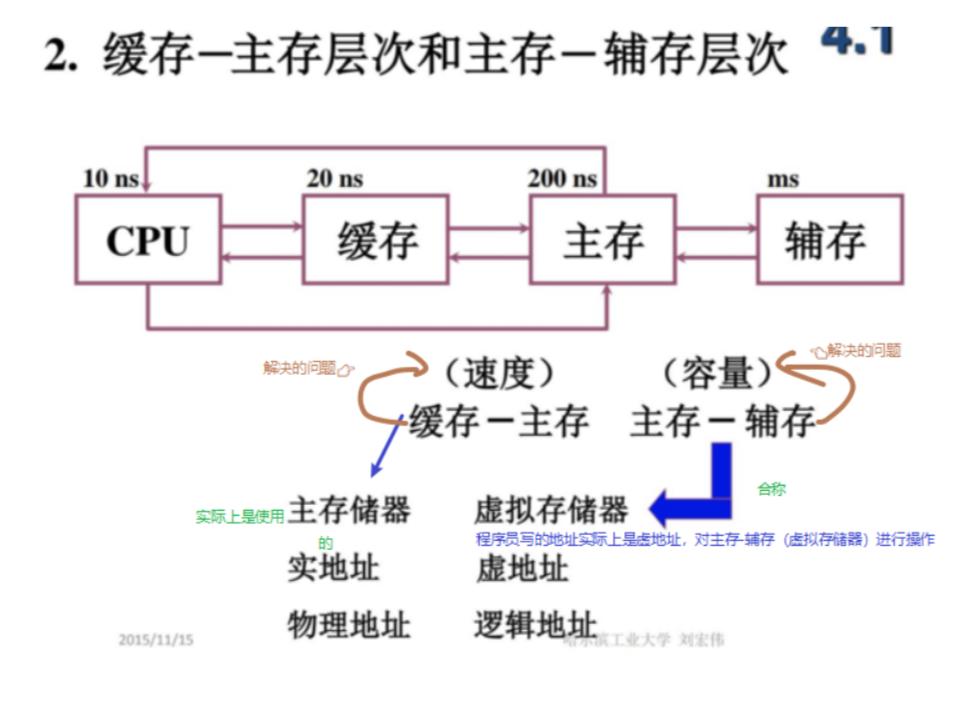
不同点:
- 解决问题不同:一个是找东西(速度),一个是存东西(容量)
- 数据通路不同:cache-主存存储体系中cpu可以直接访问主存,但是主存缓存体系CPU不可以直接访问辅存,只能访问主存(需要通过调页解决)
- 透明性不同:cache管理由硬件完成,虚拟内存管理对程序员透明
- 未命中的损失程度不同:cache争取的时间5-10倍,而主存存储速度是辅存的k倍
共同点:
- 目的相同:提高存储器件性价比而构造的分层存储体系
- 原理相同:把最近常用的信息块从慢大的存储器调入快小的存储器
七、mips32设计
1.对于MIPS32 指令执行的流程总体步骤
取指令
分析指令
取操作数
执行指令
2.MIPS32 内部的可用寄存器数量和位数
3.RISC和CISC构架,二者区别;MIPS属于什么构架
MIPS属于RISC架构。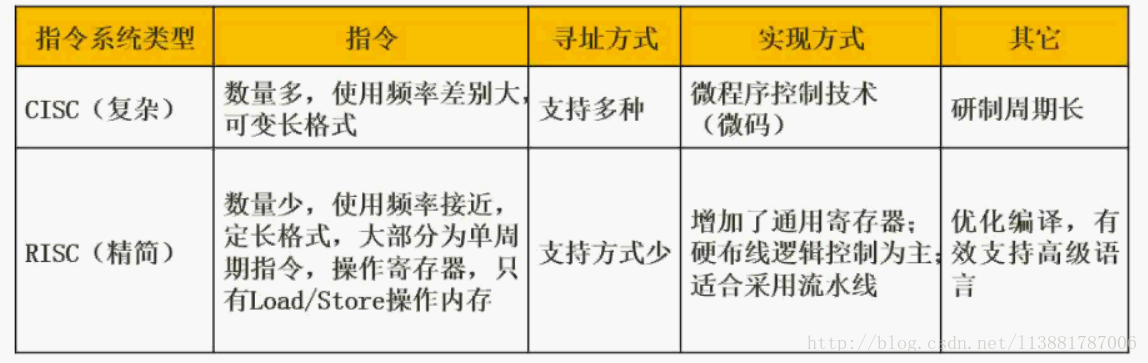
https://blog.csdn.net/l13881787006/article/details/78023136
CISC寻址方式多、微程序控制、定制指令硬件
RISC针对寄存器操作、硬布线技术
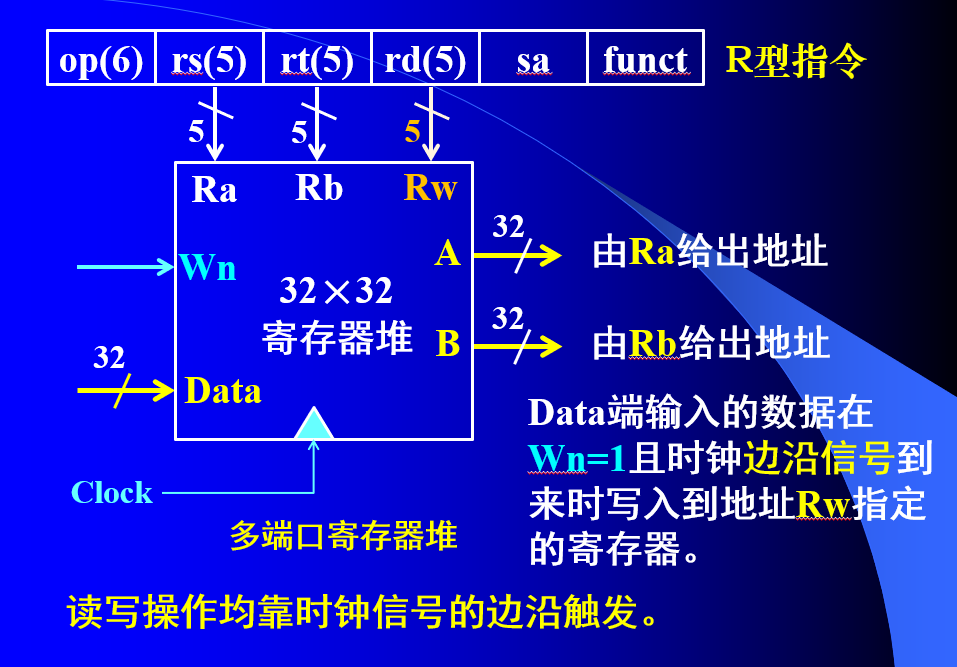
4.寄存器堆的结构,32个32位寄存器,两路数据出口,一路数据入口,两路出口的选择线,一路数据输入选择线
5.单周期和多周期cpu的特点
单周期CPU:一个时钟周期完成一条指令,如果一个程序有多条指令,则时钟周期的时间根据执行时间最长的那条指令为主。执行一条指令就需要一个时钟周期则CPI为1。
多周期CPU:一条指令被分成了若干个阶段,假设为n个,每执行一条指令需要花费n个时钟周期,所以执行一条指令就需要n个时钟周期CPI为n。
多周期CPU比单周期CPU的优势在于:因为一个程序的不同指令所需要的执行时间是不同的,所以如果按照单周期处理的话,无论什么指令我都按照最长的那条指令去处理,
(由单指令的最长时间决定)
可能我只要占用CPU1s,但是你给了我100s,其中99sCPU都在等待,闲着没事干,这完全是在浪费CPU。多周期CPU就是程序中的每一条指令要多少时间我就给你多少时间,比如第一条指令要是2s,那我就给你2s的CPU,第二条指令要5s,我就给你5s,多周期CPU完成这2条指令一共是7s,如果是单周期总时间就需要10s,多周期的CPU的效率比单周期高吧。
(部件共享)
但是多周期CPU也有缺点,就是同一时间不能运行多条指令无法实现CPU并行工作,因为有的时候一个程序执行的不同指令可能用的是CPU中的不同部件,如果可以让CPU中的所有部件都能不闲着那效率不就更高了,所以就有了指令流水线。
(高级技术:指令流水线的基础)
6.指令中数据通路设计的基本流程
7.单周期cpu的设计
1)取指模块结构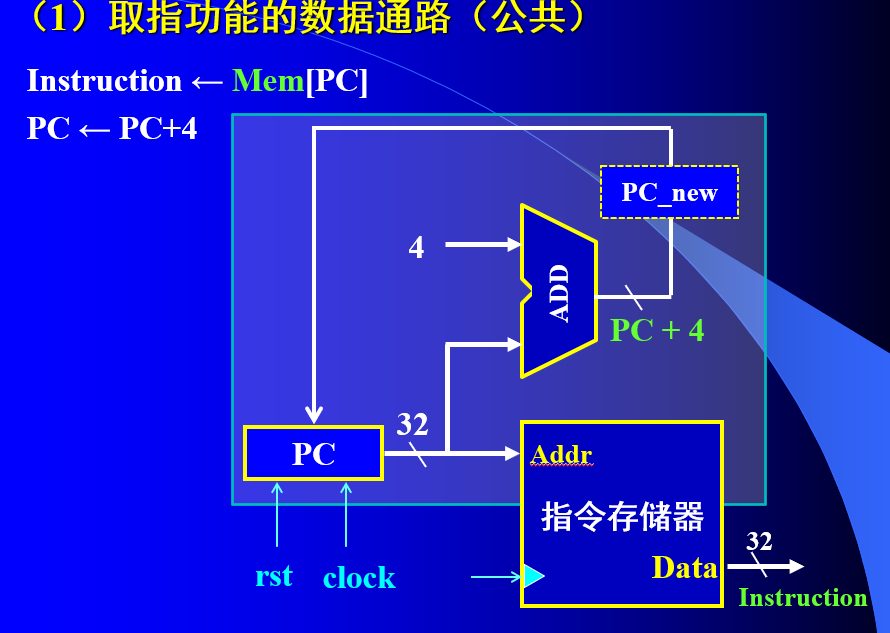
2)多路选择器的作用
用多路选择器,整合冗余通路。
8.控制器设计的不同结构:
硬布线技术(组合,时序),微程序控制;
单周期(硬布线的组合)、多周期(可以硬布线的时序,但更常用微程序控制)
cpu通常搭配的控制器结构
9.组合逻辑和微程序控制器的特点
组合逻辑控制方法中
- 优点:思路简单,可用于实现任一指令系统。
- 缺点:设计和调试代价很大,难于修改和扩充
微程序控制器
- 优点:微程序设计标准化程度高(规整)、可灵活地修改和扩充。
- 缺点:但速度比硬布线方法慢一些。
10.单周期cpu(组合)控制器的设计步骤
11.简化控制器设计难度的有效方法
最常见的是采用两级(或更多级)的控制器设计方法
12.多周期cpu的特点
13.多周期cpu相对于单周期cpu的特点
14.多周期cpu的设计思路,流程

15.微程序控制控制信号产生的原理
由ROM实现
微程序控制器的工作原理:
是依据读来的机器指令的操作码找到与之对应的一段微程序的入口地址,并按由指令具体功能所确定的次序,逐条从控制存储器中读出微指令,以“驱动”计算机各功能部件正确运行。
微程序控制的基本思想:
就是仿照通常的解题程序的方法,把操作控制信号编成所谓的“微指令”,存放到一个只读存储器里.当机器运行时,一条又一条地读出这些微指令,从而产生全机所需要的各种操作控制信号,使相应部件执行所规定的操作。
16.一条微指令的结构,包含哪几个字段
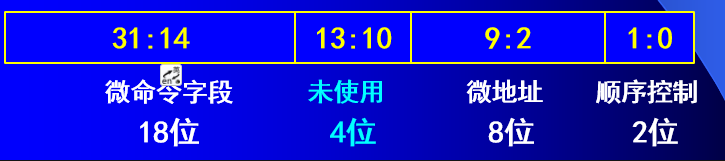
vs机器指令:操作码+地址码
17.能够根据给出的数据通路图设计出合理的微程序段(某一条指令)
18.能够根据给出的不同器件的延时时间评价单周期或多周期cpu在不同频率下的性能
19.多周期cpu的特点
20.流水过程的含义

21.评价流水线性能的参数

22.常见超线程,多核的cpu以及特征
超线程技术是一种同步多线程技术(SMT),使CPU可分别执行来自多个线程的指令。
多核技术:一个处理器芯片集成多个CPU
八、总线技术
1.总线按功能分类
- 片内总线:芯片中
- 系统总线:计算机各部件信息传输
- 数据总线DB 双向 与机器字长、存储字长有关
- 地址总线AB 单向 与存储地址、I/O地址有关
- 控制总线CB 有出有入 中断请求、总线请求 总线允许、中断确认
- 通信(I/O)总线:计算机系统之间,或与其它仪表等通信
- 传输方式:串行/并行
2.总线按在系统中的层次分类,内部,系统,IO
片内、系统、I/O3.总线性能评价指标

4.总线带宽计算,同带宽下总线的评价
提高频率才是王道。
5.总线总裁方式分类
按照总线仲裁电路的位置不同,仲裁方式分为集中式仲裁和分布式仲裁两类。九、IO设备
1.基本磁盘结构

2.磁盘相关计算
字节 扇区 磁道 磁头

https://wenku.baidu.com/view/532f9517aa00b52acec7cab5.html

若有收获,就点个赞吧
0 人点赞
