- 1、 会判断哪些串是某个文法所产生的句子
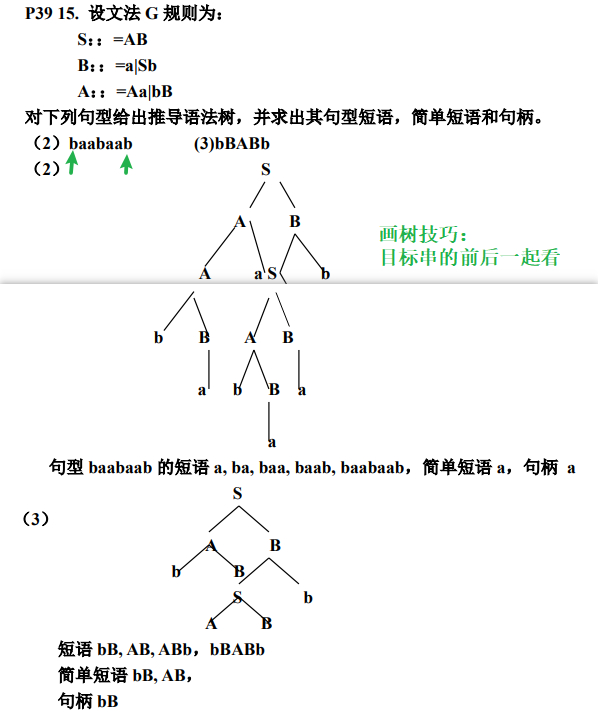
- 2、 给定一个文法和一个句型,能画出生成该句型的语法树,并指出该句型中的全部短语、简单(直接)短语、句柄
- 3、 会证明一个文法是二义性文法
- 4、 会判断乔姆斯基文法的类型
- 5、 会写出一个文法的压缩过文法
- 6、 会画出一个正规文法(左右线性文法/3型文法)的状态转换图,并写出其对应的有穷自动机
- 7、 会实现左右线性文法间的转换
- 8、 会判断两个正规式是否等价
- 9、 会写出一个正规式对应的转换系统,并能对其确定化,画出确定化后的状态转换图,且能判断该状态转换图是否可以化简
- 10、给出自然语言所描述的一种形式语言,能够画出能识别该语言的状态转换图,并写出能够产生该语言的正规表达式
- 11、会用扩充的BNF方法和改写法消除文法的左递归
- 12、会构造LL(1)分析表,并能够利用该分析表分析符号串
- 13、会找出一个句型的活前缀
- 14、能认识各类LR项目
- 15、给定一个LR文法,会构造其识别活前缀的LR(1)项目所对应的DFA, 会构造其LR(1)分析表,会判断该 LR(1)文法是否是LALR(1)文法,并说明理由
- 16、会写出一个不含布尔表达式的条件语句的逆波兰式形式(POST)
- 17、会写出一个含有布尔表达式的条件语句对应的四元式序列
2022年6月《编译原理》期末考试大纲
1、 会判断哪些串是某个文法所产生的句子

2、 给定一个文法和一个句型,能画出生成该句型的语法树,并指出该句型中的全部短语、简单(直接)短语、句柄
:::warning
- 短语:
A =+> β,非终结符 A 加号推导(1 步或多步)出 β(β∈(VN∩VT)*+)。- 直接短语:
A => β,非终结符 A 直接推导(1 步)出 β。- 句柄:(一个句型的)最左直接短语。
- 直接短语:
短语:相对于某棵树父节点的叶子们
0 型文法 / 短语文法 / 图灵机:
**α -> β**- 且 α 中要求至少一个非终结符。
- 1 型文法 / 上下文有关文法 / 线性界限自动机:
**α -> β**- 在 0 型文法的基础上额外要求:
|α| <= |β|,即左侧长度短;(与课本定义不同) - 特例:
S -> ε,S 不能出现在右部(这里就是指开始符号)。
- 在 0 型文法的基础上额外要求:
- 2 型文法 / 上下文无关文法 / 非确定下推自动机:
**A -> β**- 在 1 型文法的基础上额外要求:
A ∈ VN,即要求左侧只能为一个非终结符。 - 特点是采用栈式工作方式。
- 在 1 型文法的基础上额外要求:
- 3 型文法 / 正规文法(左右线性文法) / 有限自动机:
**A -> Bα | α**或**A -> αB | α**- 在 2 型文法的基础上额外要求:
B ∈ VN,α ∈ VT*,即要求右侧为唯一的非终结符,加上终结符组成的字;或仅为终结符组成的字。
- 在 2 型文法的基础上额外要求:

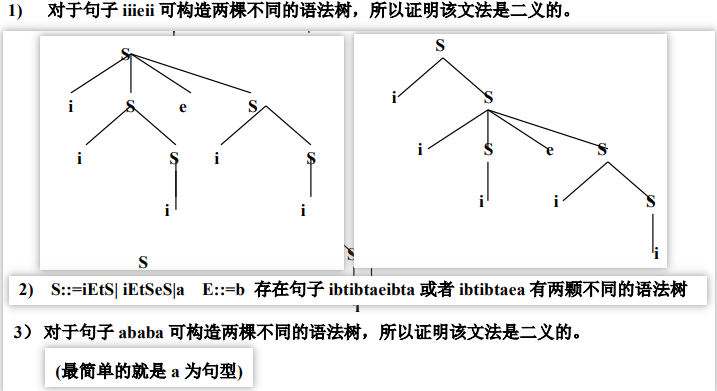
四种文法能力比较:对产生式限制逐渐加深,描述能力渐弱。 ::: :::info 方法:
- 左侧除了一个终结符外还有别的(最多1型),看看是否有左边比右边长(0型),检查
S->ε,有且右侧出现(0型,否则1型)。 - 左侧只有一个终结符,

- 文法中不含形如
**A -> A**的产生式(非必要且必导致二义文法); - 除了开始符号终结符 S,其它非终结符 A:
- 必须在产生式右部出现,否则 A 不可达;
- 必须能推导出终结符号串,否则 A 无法终止;
这样的规则并未包含在 2、3 型文法的定义中,但从实用角度是有必要的。
:::
:::info
方法:删除不满足上述条件的产生式(/规则),以及相关联的产生式(/规则)。
:::

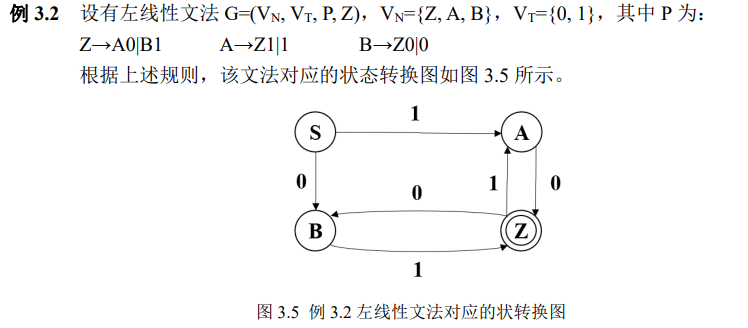
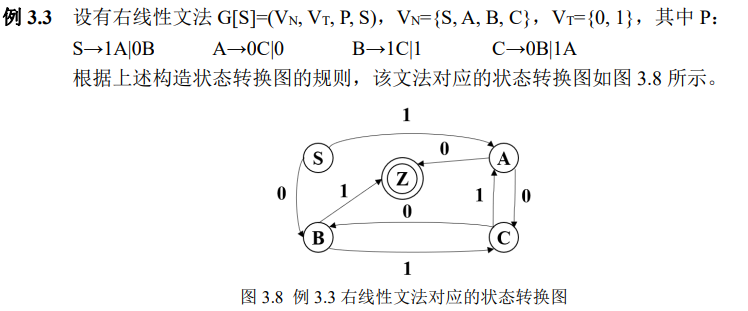
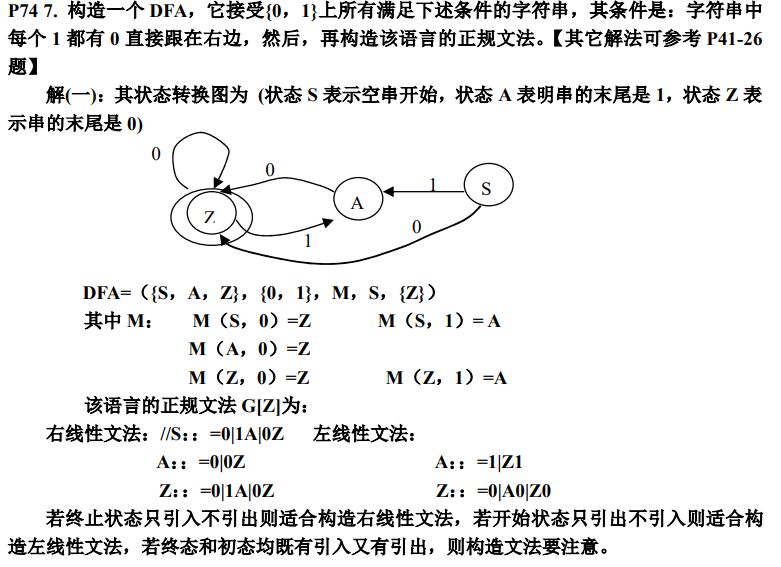
6、 会画出一个正规文法(左右线性文法/3型文法)的状态转换图,并写出其对应的有穷自动机
:::warning
文法 G = (VT, VN, P, S)
有限自动机 **M = (S, ∑, f, S0, SF)**, M 所识别的字的全体记为 L(M),M 本质是正规式?
- M:一个实例
- S:状态集(有穷、非空)
- ∑:输入字母表(有穷),每个元素称为输入字符
- f:状态转换函数(通俗讲是文法转换关系)
- 确定有限自动机 DFA:是 S 接受 ∑ 中一个字符到 S 的单值映射(函数)。由于某个状态接受一个字符会得到一个确定的新状态,因此称为确定有限自动机。
- 非确定有限自动机 NFA:是 S 接受 ∑ 中一个字符到 S 子集的多值映射。
- S0:初始状态、唯一初态,S0 ∈ S
SF:终止状态集合,SF ∈ S ::: :::info 状态转换图的画法:
左线性文法
**A -> Bα | α**对应归约过程,需增加初始状态 S- 如:B 接受 α 归约 A,S 接受 α 归约 A
右线性文法
**A -> αB | α**对应推导过程,需增加接受状态 Q- 如:A 接受 α 推出 B,A 接受 α 推出 Q
:::
 :::info
有穷自动机的构造方法:
:::info
有穷自动机的构造方法:
根据有限自动机 M,状态(非终结符)逐一匹配字符(终结符)。对应状态转换图上的各状态转换。
- 如:A 接受 α 推出 B,A 接受 α 推出 Q
:::
右线性文法:直接根据文法规则确定状态转换关系。
- 左线性文法:将文法转换成右线性文法,或根据状态转换图确定转换关系。
(tou:这道题这么出肯定考左线型,要不然状态转换图是不必要的)
:::

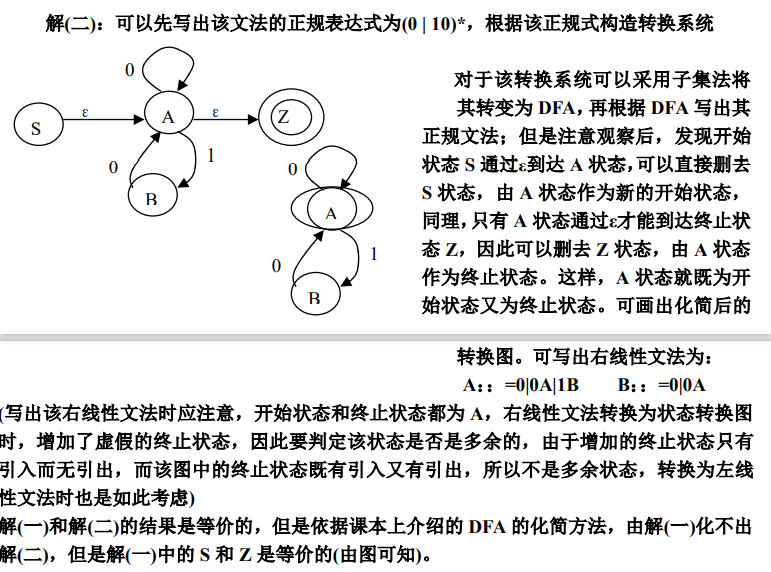
7、 会实现左右线性文法间的转换
:::info
方法1:左、右线性文法的转换公式: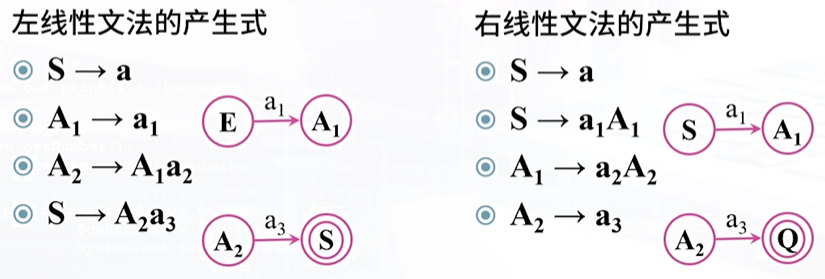
方法2:方法1不好读懂,实际上公式不过是根据左右线性文法的特性(即借助状态转换图的转换关系):
- 左线性文法
A -> Bα | α对应归约过程,需增加初始状态 S- 转换右线性文法的时候,要删去 S,补充 Q
- 右线性文法
A -> αB | α对应推导过程,需增加接受状态 Q


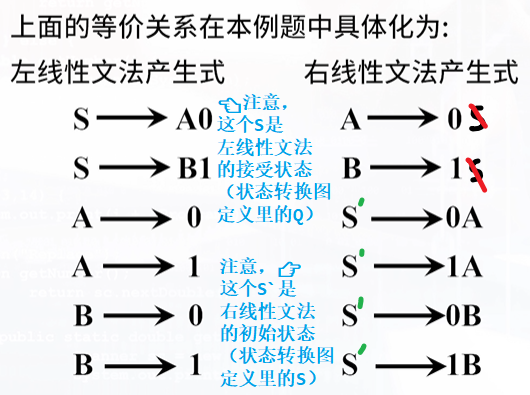


 :::
:::info
正规式等价 <=> 正规集相同(转换为集合的等价证明)
:::
:::
:::info
正规式等价 <=> 正规集相同(转换为集合的等价证明)
:::



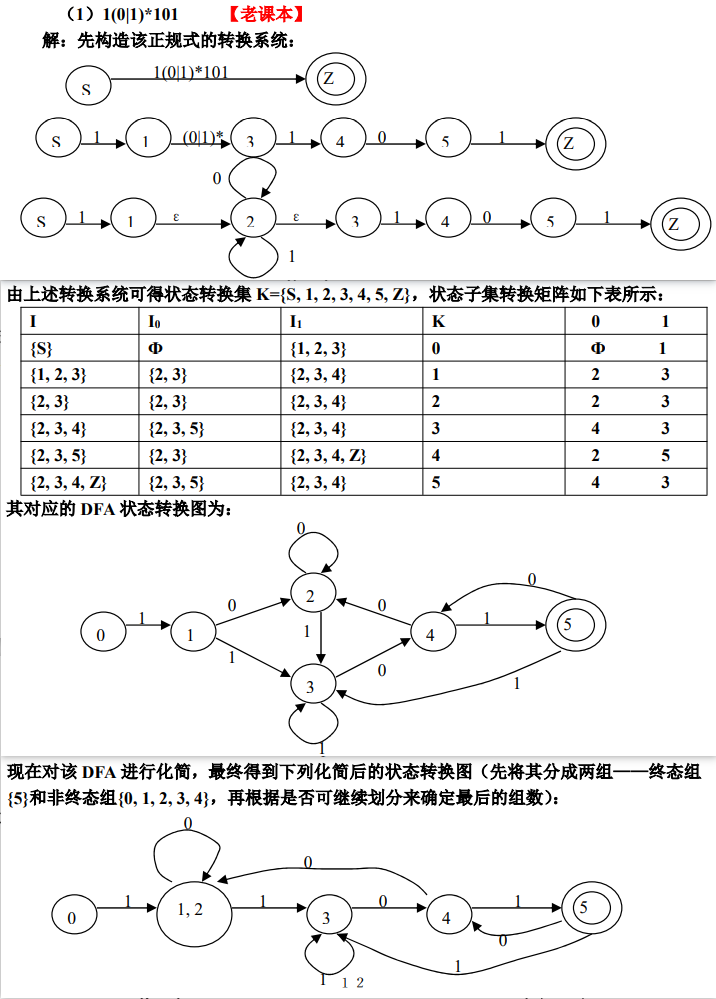
9、 会写出一个正规式对应的转换系统,并能对其确定化,画出确定化后的状态转换图,且能判断该状态转换图是否可以化简
:::info 正规式的转换系统是一个具有唯一开始状态 S 和唯一最终状态 Z 的一种特殊状态图。其条件是:
- 没有弧向开始状态 S 引入;
- 没有弧从终止状态 Z 引出;
- 转换系统的弧可以用空符号 ε 标记;
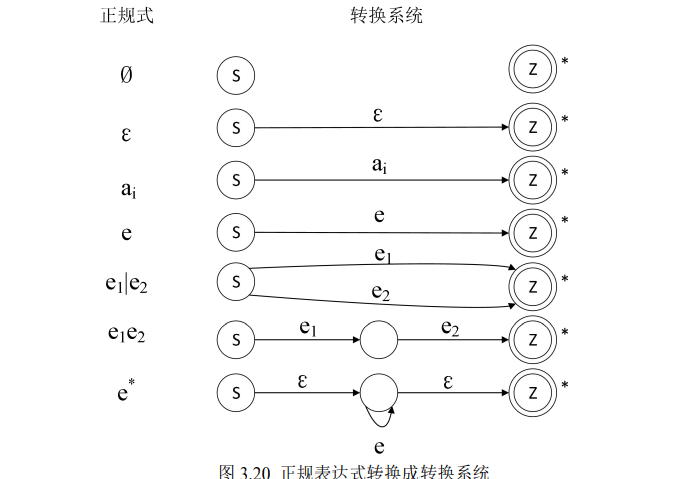
显然,得到的转换系统仍然是一个 NFA(至少有 ε)?
:::
:::info
NFA 确定化,I 与 Ia 的 ε-closure 定义:
不难看出,通过 ε-closure 可以找齐所有等价状态(I),和等价的下一个状态(Ia)。
NFA 确定化:状态转换表
示例: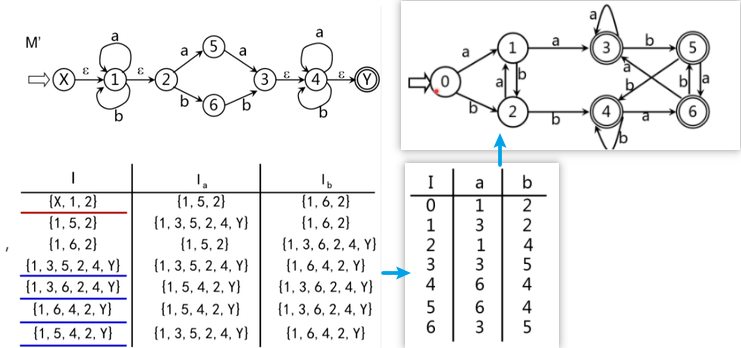 :::
:::info
DFA 化简:划分状态集
:::
:::info
DFA 化简:划分状态集
- 关键:消去等价状态
- def:

- def:
- 思想:划分状态集(使两个子集的状态是可区别的)
- 首先划分的对象:终态和非终态
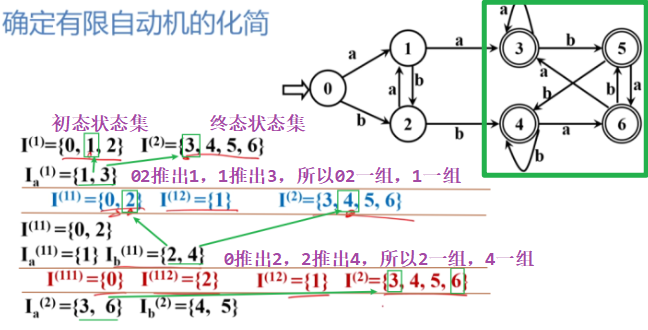
 :::
:::
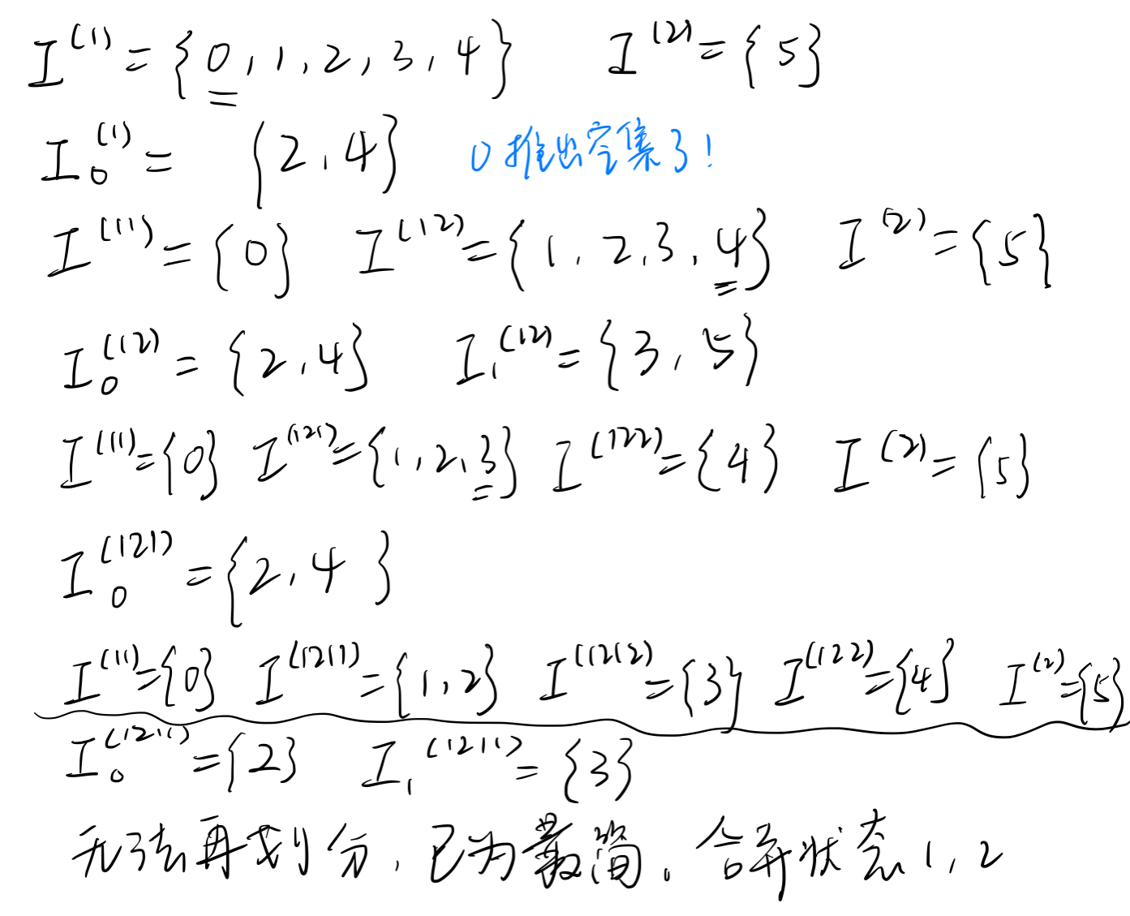
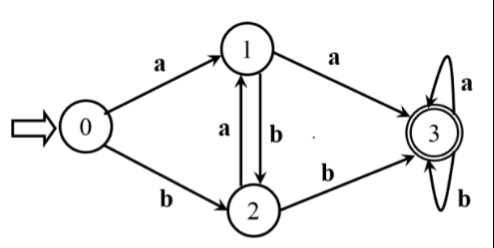
10、给出自然语言所描述的一种形式语言,能够画出能识别该语言的状态转换图,并写出能够产生该语言的正规表达式
:::tips
我觉得正规表达式可以直接看出来吧…那画转换系统好像也没啥问题
:::
11、会用扩充的BNF方法和改写法消除文法的左递归
:::info
消除直接左递归:
方法1:扩充 BNF 规则:
方法2:改写法规则:A -> Aα | β 转换为:
**A -> βA'****A' -> αA' | ε**
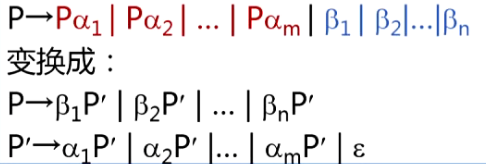 :::
:::

 :::info
消除间接左递归:代入,转换为直接左递归。
:::info
消除间接左递归:代入,转换为直接左递归。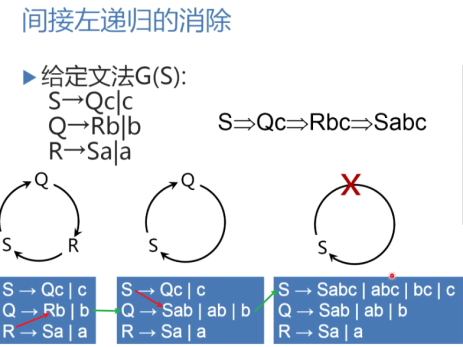 :::
:::

12、会构造LL(1)分析表,并能够利用该分析表分析符号串
:::tips
构造 LL(1) 文法的分析表 => 证明是 LL(1)文法 => 构造 FIRST 集合和 FOLLOW 集合
:::
:::info
求每个文法符号的 FIRST 集合:
总结:
**X = a | ε****X -> a...****X -> Y...**,则First(Y)\{ε} ∈ First(X)**X -> Y1Y2Y3...Yi-1Yi...**,且只有 Yi 不含 ε。则First(Yi)\{ε} ∈ First(X)**X -> Y1Y2Y3...Yi**,大家都含 ε。则{ε} ∈ First(X)- 循环检查存在 345 情况的候选式直到没更新。
技巧:若产生式右部候选的首部是VN,代入,直至所有产生式首部都是VT,再找 FIRST 集合,只用执行上述 12 步骤了!
构造任意符号串的 FIRST 集合,类似。
:::
:::info
求每个文法符号的 FOLLOW 集合:
总结:
**# ∈ FOLLOW(S)****A -> αBβ****First(β)**没有包含 ε,则FIRST(β)\{ε} ∈ FOLLOW(B)**First(β)**包含 ε (同下)
**A -> αB**,则FOLLOW(A) ∈ FOLLOW(B)- 循环检查存在 2b、3 的情况
:::
:::info
证明是 LL(1) 文法:LL(1) 文法的定义:
 :::
:::info
构造分析表:
:::
:::info
构造分析表:
总结:
对于每个产生式**A-> α**,其中α ∈ VN ∩ VT,另外 a,b 属于 VT
- 添加到 M[A, a],条件是:
a ∈ First(α) - 添加到 M[A, b],条件是:
**ε ∈ First(α)**&&b ∈ Follow(A)
即,只要 First(α) 含有 ε,则考虑 Follow(A)。
最终剩余部分是无法到达的,出错标志。
:::



13、会找出一个句型的活前缀
:::warning
规范归约:(自下而上的分析过程)从句子开始,每次替换句柄的归约结果序列。最左归约。
规范推导:规范规约的逆过程。最右推导。
规范句型:规范推导的结果。
字:即字符串,空字即 ε。
前缀:字的任意首部。
活前缀:规范句型的前缀,不含句柄之后的任何符号。
eg.规范句型 abc 中若 b 为句柄,则活前缀有:ε、a,ab(ab 为句柄答案也一样)
:::
14、能认识各类LR项目
:::warning
- 归约项目
A -> **α**·- 接受项目
**S'** -> **α**·,S’ 是文法拓广后的开始符号
- 接受项目
- 移进项目
A -> α·**a**β - 待约项目
A -> α·**B**β
 :::
:::
15、给定一个LR文法,会构造其识别活前缀的LR(1)项目所对应的DFA, 会构造其LR(1)分析表,会判断该 LR(1)文法是否是LALR(1)文法,并说明理由
:::info 构造识别活前缀的 DFA:(通过有效项目)
- 计算项目集的闭包 CLOSURE =>有效项目的定义与性质(直接写)


- 计算项目集的状态转换函数 GO =>直观描述为:项目集接受一个文法符号进入下一个状态 (直接写)

- 项目集状态序号依据:广度优先原则
通俗描述:
- 读入项目点
·后的文法符号,进入下一个状态。 - 若点
·后是非终结符,则根据有效项目的定义与性质补充新的项目。
示例: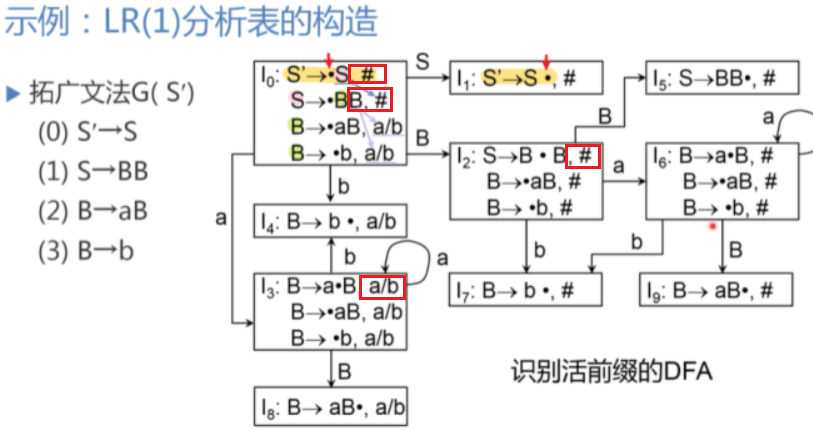
搜索符的描述:
- 每次读入文法符号进入下一个状态后,继承(保留)原来的搜索符。
每次根据有效项目的定义与性质补充新的项目时,新项目的向前搜索符是“新项目左侧非终结符在原项目位置右侧的待约符号串∪向前搜索符”的 FIRST 集合。(看图和 CLOSURE 闭包中的定义) ::: :::info 构造 LR(1) 分析表 => ACTION 表 + GOTO 表
分析表取识别活前缀的 DFA 中项目集的序号(下标)作为状态。
构造 ACTION 子表:
接受:VT 、没有东西可以接受时; 输出:移进/归约动作;若项目集 k 读入终结符 a 进入项目集 j(即 GO(Ik,a) = Ij ),则移进:
**ACTION[k,a] = sj**- 若项目集 k 是终态(不再读入任何 VN 或 VT),对于项目集中唯一的一个归约项目
[A -> α·, a](对应文法的第 j 个产生式)(且不是[S'->S·, #]),执行归约操作:**ACTION[k,a] = rj** - (2的特例)若这个归约项目是初态项目,即
**[S'->S·, #]**,则**ACTION[k,#] = acc** - 其余:空,即报错标志。
构造 GOTO 子表:
接受:VN 时; 输出:状态(下标);
- (对比 1)若项目集 k 读入非终结符 A 进入项目集 j(即 GO(Ik,A) = Ij ),则指向状态:
GOTO[k,A]=j - 其余:空,即报错标志。
示例: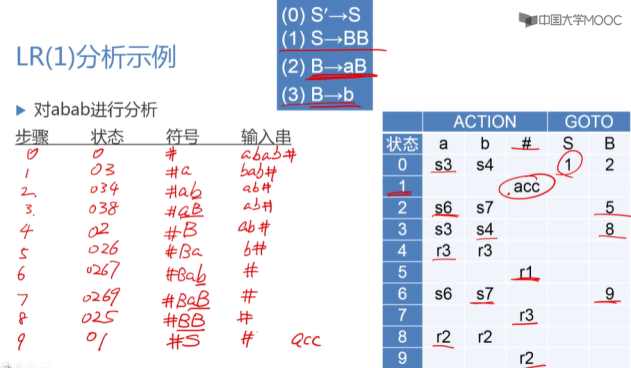 :::
:::info
判断是否为 LALR(1) 文法 / 转换成 LALR(1) 文法:合并同心集
:::
:::info
判断是否为 LALR(1) 文法 / 转换成 LALR(1) 文法:合并同心集
同心集:在LR(1)项目集规范族中,去掉搜索符(展望串)后完全一样的的两个项目集。
- 根据 LR(1) 识别活前缀的 DFA,找到所有同心集。
- 对每一组同心集,观察 ACTION 表,关注出现“归约-归约”合并的地方,如果归约的产生式不是同一个,则无法合并!无法转化为 LALR(1) 文法!
- 如若都满足,继续构造 LALR(1) 分析表,合并规则如下。

16、会写出一个不含布尔表达式的条件语句的逆波兰式形式(POST)


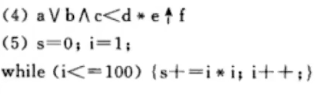
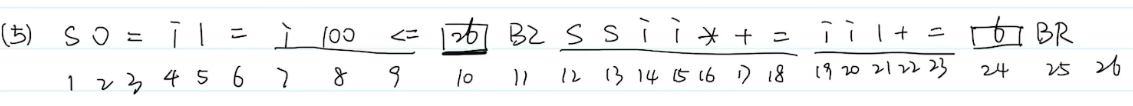

17、会写出一个含有布尔表达式的条件语句对应的四元式序列
:::warning
四元式: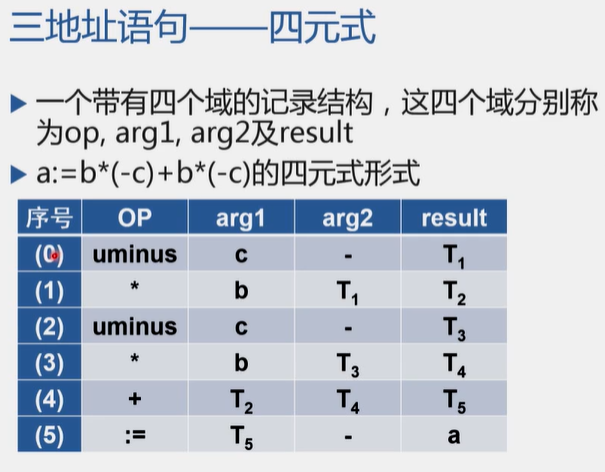 :::
:::info
:::
:::info
 :::
:::



若有收获,就点个赞吧
0 人点赞
