Simple-Nested-Loop-Join简单嵌套循环连接
select *from usersleft join user_infos info on users.id = info.user_id
伪代码逻辑
for(user : users) {
for(info: infos) {
if(user.id == info.user_id) {
表1和表2连接
}
}
}
通过伪代码我们可以得知算法效率为 ,也就是对于user表来说需要扫描n次,而对于info表需要扫描n*r次
,也就是对于user表来说需要扫描n次,而对于info表需要扫描n*r次
Index-Nested-Loop-Join索引嵌套循环循环连接
伪代码逻辑
for(user: users) {
List<Long> 索引字段集合 = 索引查找非驱动表(user);
for(info: 索引字段集合) {
表1和表2连接
}
}
图示

说明
其实如果你要查的表2字段在索引行中全部包含了,就不会走第二个循环了(俗称的回表)
Block-Nested-Loop-Join块嵌套循环连接
伪代码逻辑
// 一次将部分user放入buffer中
for(someUsers : users) {
for(info: infos) {
if(someUsers.contains(info.user_id)) {
连接匹配上的两列
}
}
}
图示
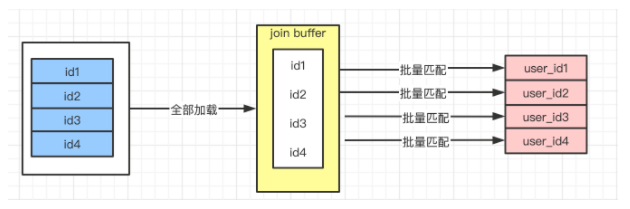
说明
someUsers取得数量个数其实是不确定的,块的大小确定,由系统中**join_buffer_size=256k**确定,因此我们说优化尽量选出需要的列,这样能够减少每条记录的大小,从而让buffer中存在更多的记录。

若有收获,就点个赞吧
0 人点赞
