原始SQL
SELECT d_asset_id AS assetId, COUNT(tb_analysis_merge_event.id) eventCountFROM tb_analysis_merge_eventLEFT JOIN tb_asset_relation AS relation1 ON tb_analysis_merge_event.s_asset_id = relation1.asset_idLEFT JOIN tb_asset_relation AS relation2 ON tb_analysis_merge_event.d_asset_id = relation2.asset_idWHERE tb_analysis_merge_event.create_time >= '2021-03-14 00:00:00'AND tb_analysis_merge_event.create_time <= '2022-04-14 00:00:00'AND relation1.type = 1AND relation2.type = 1AND (relation1.relate_id = 1357590660078198786 OR relation2.relate_id = 1357590660078198786)GROUP BY d_asset_id;
使用explain extend查看执行计划及MYSQL优化器优化后的SQL
优化后的SQL
select `bladex`.`tb_analysis_merge_event`.`d_asset_id` AS `assetId`,
count(`bladex`.`tb_analysis_merge_event`.`id`) AS `eventCount`
from `bladex`.`tb_analysis_merge_event`
join `bladex`.`tb_asset_relation` `relation1`
join `bladex`.`tb_asset_relation` `relation2`
where ((`bladex`.`tb_analysis_merge_event`.`s_asset_id` = `bladex`.`relation1`.`asset_id`) and
(`bladex`.`relation2`.`asset_id` = `bladex`.`tb_analysis_merge_event`.`d_asset_id`) and
(`bladex`.`relation2`.`type` = 1) and (`bladex`.`relation1`.`type` = 1) and
(`bladex`.`tb_analysis_merge_event`.`create_time` >= '2021-03-14 00:00:00') and
(`bladex`.`tb_analysis_merge_event`.`create_time` <= '2022-04-14 00:00:00') and
((`bladex`.`relation1`.`relate_id` = 1357590660078198786) or
(`bladex`.`relation2`.`relate_id` = 1357590660078198786)))
group by `bladex`.`tb_analysis_merge_event`.`d_asset_id`
优化器为什么会这样优化?
区别
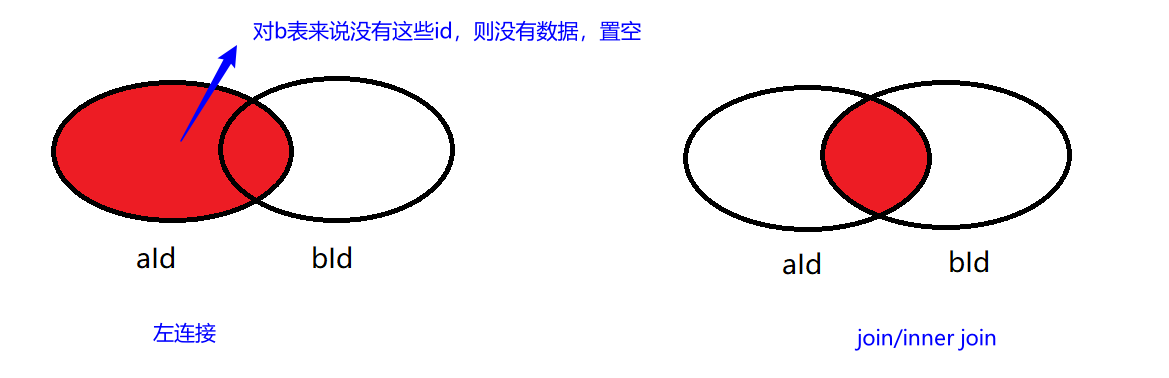
- join 等价于 inner join,是返回两个表中都符合条件的行
- left join 是返回左表中所有的行以及右表中符合条件的行
- right join 是返回右表中所有的行以及左表中符合条件的行 ```sql
表A记录如下: aID aNum 1 a20050111 2 a20050112 3 a20050113 4 a20050114 5 a20050115
表B记录如下: bID bName 1 2006032401 2 2006032402 3 2006032403 4 2006032404 8 2006032408
1.left join sql语句如下: select * from A left join B on A.aID = B.bID
结果如下: aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404 5 a20050115 NULL NULL
(所影响的行数为 5 行) 结果说明: left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的. 换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
B表记录不足的地方均为NULL.
2.join sql语句如下: select * from A inner join B on A.aID = B.bID
结果如下: aID aNum bID bName 1 a20050111 1 2006032401 2 a20050112 2 2006032402 3 a20050113 3 2006032403 4 a20050114 4 2006032404
结果说明:
很明显,这里只显示出了 A.aID = B.bID的记录.这说明inner join并不以谁为基础,它只显示两表同时都满足符合条件的记录.
<a name="OmF7O"></a>
## 效率
一般认为inner join要比left join快,可以从两方面考量
<a name="PwUsD"></a>
### 数据量
inner join只取两个表的交集,一般来说比left join数据量要小一些
<a name="J1LPL"></a>
### 小表驱动大表
mysql默认采用nested-loop-join算法进行连接,该算法类似一个三层循环,inner join会选用小表作为第一层循环,从而达到减少循环的目的,而left join会始终选择左表作为第一层循环,如果左表比较大,那么我们就需要循环更多次,因而效率下降。
<a name="Y3l4Q"></a>
# SQL执行逻辑

```sql
select `bladex`.`tb_analysis_merge_event`.`d_asset_id` AS `assetId`,
count(`bladex`.`tb_analysis_merge_event`.`id`) AS `eventCount`
from `bladex`.`tb_analysis_merge_event`
join `bladex`.`tb_asset_relation` `relation1`
join `bladex`.`tb_asset_relation` `relation2`
where ((`bladex`.`tb_analysis_merge_event`.`s_asset_id` = `bladex`.`relation1`.`asset_id`) and
(`bladex`.`relation2`.`asset_id` = `bladex`.`tb_analysis_merge_event`.`d_asset_id`) and
(`bladex`.`relation2`.`type` = 1) and (`bladex`.`relation1`.`type` = 1) and
(`bladex`.`tb_analysis_merge_event`.`create_time` >= '2021-03-14 00:00:00') and
(`bladex`.`tb_analysis_merge_event`.`create_time` <= '2022-04-14 00:00:00') and
((`bladex`.`relation1`.`relate_id` = 1357590660078198786) or
(`bladex`.`relation2`.`relate_id` = 1357590660078198786)))
group by `bladex`.`tb_analysis_merge_event`.`d_asset_id`;
为什么会采用这样的执行逻辑呢?

若有收获,就点个赞吧
0 人点赞
