特点
适合格式化文本,对文本做较复杂的格式化操作
语法
awk [options] ‘pattern{action}’ file
说明
awk是逐行处理的,默认以换行符为标记识别每一行。每一行都会以分隔符去分割,如果没有指定分隔符,默认使用空格作为分隔符(多个连续的空格视为一个),$0表示当前行,$NF表示当前行分割的最后一列,⚠️NF和$NF不一样,NF表示当前行被分割后一共有几个字段
awk包含两种特殊的pattern:BEGIN 和 END,BEGIN指定了处理文本之前进行的操作,END制定了处理文本之后执行的操作,如下图所示,下图示例中返回的结果,更像是一张表的内容,表头、表中和表尾。

输入分隔符field separator,简称FS,默认是空格,每一行都会以分隔符去分割。
输出分隔符output field separator,简称OFS,定义了awk将每行分割后输出在屏幕上的时候以什么做为分隔符,默认也是空格
输入/输出分隔符
输入分隔符示例:
如果文本中没有空格,我们可以自己指定分隔符,下面使用-F参数指定分隔符,以#符进行分割
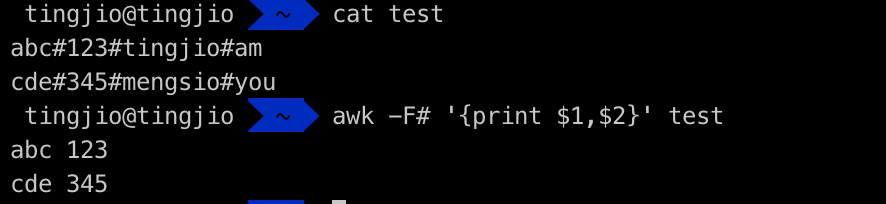
除了上面的方式,还可以使用awk内置的FS定义分割符,⚠️使用变量定义时,需要使用-v参数
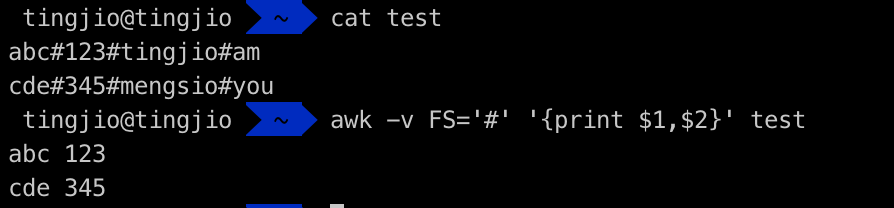
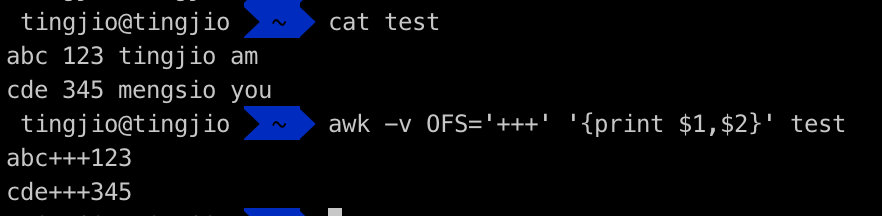
输出分隔符示例:
当awk为我们在屏幕上输出显示每一列的时候,使用空格隔开(见上面两个示例),其实这隔空格,就是awk的默认输出分隔符,我们也可以使用OFS自己定义输出分隔符,使用变量定义的时候,需要使用-v参数
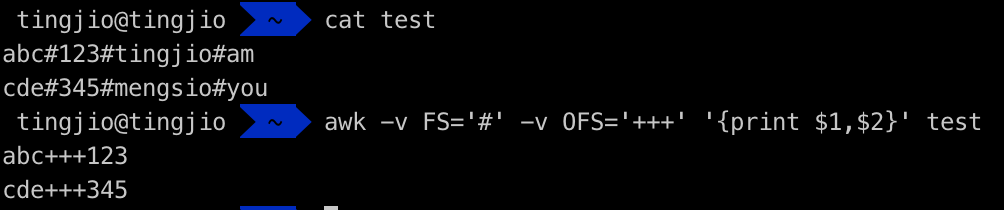
现在可以同时使用输入分隔符和输出分隔符来格式化输出内容
awk内置变量
内置变量NR表示每一行的行号,NF表示每行被分割后的字段数量,test文本中有2行,每行可以分割出4列
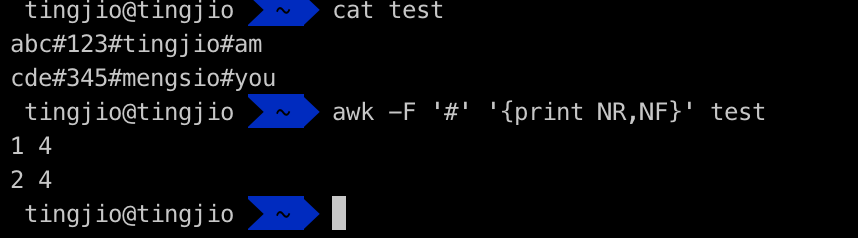
⚠️:在bash中,引用变量时使用””$,但是在awk中,除了$0,$1这样的变量,FS、OFS等其他内置变量和自定义变量使用时,都不需要使用“$”,可以直接引用变量名
RS输入行分隔符,awk的默认输入行分隔符是我们所理解的回车换行,如果想要自己定义换行符,看下面示例
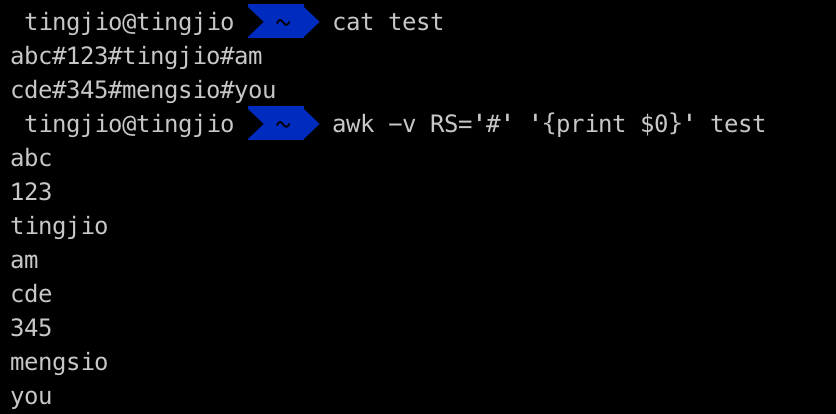
ORS输出行分隔符,awk输出信息显示到屏幕时,默认回车换行符为输出行分隔符,我们以+++作为输出行分隔符,当awk输出信息想要换行时,就会行“另起一行”,但“另起一行”的动作被我们换成了输出(+++),所以结果显示如下

FILENAME,显示文件名

awk自定义变量
方法一:
与设置内置变量一样设置自定义变量

方法二:
可以直接在程序中定义,变量定义与动作之间要用”;”隔开

awk模式(pattern)
awk的语法是awk [options] ‘pattern{action}’ file
对于option,前面我们用过-F 和-v,对于action,我们用过print,对于pattern,最开始说过BEGIN 和 END两种模式,那么,模式到底是什么,我们可以理解为条件,前面说过awk是逐行处理的,只有满足条件(匹配模式)的行才会被处理(如下所示),当没有指定模式时,即空模式,空模式会匹配每一行内容。

awk使用正则时,用”/正则/“表示,常见的正则模式用法:
awk [options] '/正则表达式/{action}' fileawk [options] '/正则1/,/正则2/{action}' file # 匹配正则1与正则2之间的所有数据awk [options] '$2~/正则/{action}' file # 第2列与正则匹配,则执行actionawk [options] '$2!~/正则/{action}' # 第2列与正则不匹配,则执行action
示例
# 在百度中分别搜索配置文件baidu.keyword中的关键字,并显示出各搜索结果的数据条数while read line ;do echo $line;curl -s http://www.baidu.com/s?wd=$line ;done < baidu.keyword | grep -o "结果约[0-9,]*"# 以‘|’分割字符串,后面输出的$0表示全部内容,$1表示分割的第一部分,依次类推echo "123|456|789" | awk -F '|' '{print $0}' #不指定分隔符时默认以空格分割#显示在百度中搜索关键字得到的数据数curl -s http://www.baidu.com/s?wd=mp3 | grep -o "结果约[0-9,]*" | awk -F '约' '{print $2}'curl -s http://www.baidu.com/s?wd=mp3 | grep "条评价" | awk -F 'data-from="ps_pc4">' '{print $2}' | awk -F '条' '{print $1}'#将每行第二个数打印出来并且输出第二个数的总和(BEGIN和END用法),awk是以line为单位进行处理,BEGIN中的命令会每行循环执行echo -e '1|2|3\n4|5|6\n7|8|9' | awk -F '|' 'BEGIN{a=0}{print $2;a=a+$2}END{print a}'awk '$2~/xxx/' #字段匹配(在awk分割出来的字段中再进行精准匹配)awk '$2!~/xxx/' #匹配非xxx字段的数据#查找日志中状态码非200的链接并统计出现的次数awk '$9!~/200/{print$7}' /tmp/nginx.log |sed -E 's/[0-9]{3,}/_d_/g' | sort | uniq -c| sort | less#统计topics/XXX/接口的平均响应时间awk '$7~/topics\/[0-9]+$/{sum+=$(NF-1)}END{print sum/NR}' nginx.loggrep /topics/[0-9]+ nginx.log |awk 'BEGIN{x=0}{x+=$(NF-1)}END{print "平均时间:" x/NR}'

若有收获,就点个赞吧
0 人点赞
