1:支持的语言
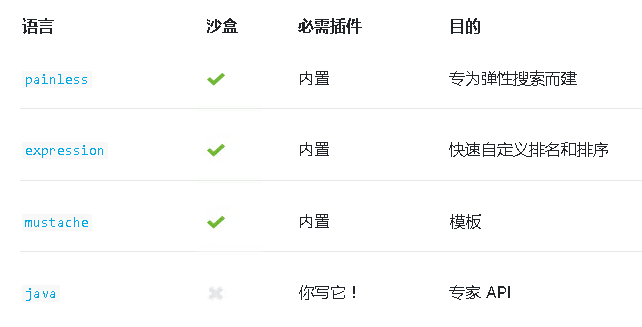
2:推荐的语言
推荐使用painless,这也是默认值。painless有以下优点: :::info 1:安全:确保集群的安全至关重要。为此,无痛使用细粒度的允许列表,其粒度低至类的成员。任何不属于允许列表的都会导致汇编错误。有关每个脚本上下文的可用类、方法和字段的完整列表,请参阅无痛 API 参考。 ::: :::info 2:性能: 无痛直接编译到 JVM 字形码中,以利用 JVM 提供的所有可能的优化。此外,无痛通常避免在运行时需要额外较慢检查的功能。 ::: :::info 3:简单:无痛实现一个语法与自然熟悉任何人与一些基本的编码经验。无痛使用 Java 语法的子集,并提供一些额外的改进,以提高可读性和删除样板。 :::
3:如何写
语法
"script": {"lang": "...","source" | "id": "...","params": { ... }}
简单的查询示例
PUT my-index-000001/_doc/1{"my_field": 5}GET my-index-000001/_search{"script_fields": {"my_doubled_field": {"script": { #1"source": "doc['my_field'].value * params['multiplier']", #2"params": {"multiplier": 2 #3}}}}}#1 script对象#2 script源#3 script参数
缩短脚本
:::info
1:默认painless,无需指定
2:return关键字无需写,自动使用
3:get方法被[]替换,类似于js语言,或者类似map类型的取值方式
4:一般情况下,分号也可以省略。但是,有些地方为了消除歧义,需要加上分号
:::
GET my-index-000001/_search
{
"script_fields": {
"my_doubled_field": {
"script": {
"lang": "painless",
"source": "return doc['my_field'].value * params.get('multiplier');",
"params": {
"multiplier": 2
}
}
}
}
}
简短后
GET my-index-000001/_search
{
"script_fields": {
"my_doubled_field": {
"script": {
"source": "doc['my_field'].value * params['multiplier']",
"params": {
"multiplier": 2
}
}
}
}
}
使用脚本更新文档
PUT my-index-000001/_doc/1
{
"counter" : 1,
"tags" : ["red"]
}
#1 增加计数器
POST my-index-000001/_update/1
{
"script" : {
"source": "ctx._source.counter += params.count",
"lang": "painless",
"params" : {
"count" : 4
}
}
}
#2 处理list
POST my-index-000001/_update/1
{
"script": {
"source": "ctx._source.tags.add(params['tag'])",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
# 避免tags.tag 不存在,先脚本判断
POST my-index-000001/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params['tag'])) { ctx._source.tags.remove(ctx._source.tags.indexOf(params['tag'])) }",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
# 避免tags字段不存在,判断
POST my-index-000001/_update/1
{
"script": {
"source": "if (ctx._source.tags != null && ctx._source.tags.contains(params['tag'])) { ctx.op = 'delete' } else { ctx.op = 'none' }",
"lang": "painless",
"params": {
"tag": "green"
}
}
}
3.1 脚本、缓存和搜索速度
:::info
1:增加脚本缓存大小,脚本的大小限制为 65,535 字节。设置script.max_size_in_bytes的价值,以增加该软限制
2:优化字段,减少script,优化方式有很多,可以在项目中,录入数据时处理。如果录入时不能通过代码层面控制,可以通过pipeline处理,具体pipeline用法,见:速查手册12-Ingest pipelines,此方式可以很方便的处理数据录入前的处理一些处理。
:::
3.2 解剖数据
:::info
这个根据官网的例子无法运行,暂不考虑。主要就是讲了类似于elk的操作,将结构化数据,按一定的格式拆分后,再进行搜索。官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/dissect.html。
关于elk的示例,可以参考:核心配置02 elk
:::
4:常见脚本和使用案例
:::info 运行时字段支持版本,7.11,暂不做梳理。主要是做一个运行时字段的正则匹配,使用elk也可以做。 :::
5:脚本和安全性
:::info
- 修改默认的 Elasticsearch 集群名称
- 不要暴露 Elasticsearch 在公网上
- 不要以 root 身份运行 Elasticsearch
- 定期对 Elasticsearch 进行备份
- 安装Elasticsearch的权限系统插件-SearchGuard
- 利用操作系统防火墙设置规避9200端口开放问题
SearchGuard具体见:
https://docs.search-guard.com/latest/search-guard-versions
https://github.com/floragunncom/search-guard
比较方便的方式有两种
1:使用xpack —收费
2:使用内网,不对公网开放 — 常用
3:使用SearchGuard —暂未使用过,后续再进行测试
:::

若有收获,就点个赞吧
0 人点赞
