概述
:::info
您可以使用搜索API搜索和聚合存储在Elasticsearch数据流或索引中的数据。API的查询请求主体参数接受在查询DSL中编写的查询。
关于Search API见:速查手册06-REST APIs
关于聚合见:速查手册14-聚合
关于QUERY DSL见:速查手册07-QUERY DSL
:::
:::info
下面针对搜索数据操作做一些探究。
:::
折叠搜索结果
聚合结果
GET my-index-000001/_search{"query": {"match_all": {}},"collapse": {"field": "test2.long_2" #1},"sort": [{"test2.long_2": { #2"order": "desc"}}],"from": 0 #3}explain:#1 折叠的字段:test2.long_2#2 使用test2.long_2排序#3 定义第一个折叠时的偏移量
:::tips
- 折叠仅适用于keyword或者number类型
- 返回中hits.total.value 代表聚合前的数据量,聚合后的数据总数未知
- 如果想知道折叠后的结果,可通过cardinality聚合实现,前提:cardinality和折叠,使用同一个字段,eg:例2 #1 #2
:::
例2:
```java
GET test/_search
{
“_source”: [
“id”,
“is_lastest”,
“second”,
“name”
],
“aggs”: {
“totalSize”: {
} }, “query”: { “terms”: {"cardinality": { #1 "field": "second_id" }
} }, “collapse”: { #6 第一级 “field”: “second_id”, #2 “inner_hits”: { #3"second_id": [ "2208", "196158" ]
} }, “sort”: [ {"name": "by_location", "collapse": { #4 第二级 "field": "name" }, "_source": [ "id", "is_lastest", "second", "name" ], "size": 3
} ], “from”: 0 }"second_id": { "order": "desc" }
输出结果: { “took” : 42, “timed_out” : false, “_shards” : { “total” : 1, “successful” : 1, “skipped” : 0, “failed” : 0 }, “hits” : { “total” : { “value” : 62, “relation” : “eq” }, “max_score” : null, “hits” : [ { “_index” : “test”, “_type” : “_doc”, “_id” : “53421”, “_score” : null, “_source” : { “name” : “xh2107091117”, “id” : 45897 }, “fields” : { “second_id” : [ 196158 ] }, “sort” : [ 196158 ], “inner_hits” : { “by_location” : { “hits” : { “total” : { “value” : 3, “relation” : “eq” }, “max_score” : null, “hits” : [ { “_index” : “test”, “_type” : “_doc”, “_id” : “53421”, “_score” : 1.0, “_source” : { “name” : “xh2107091117”, “id” : 45897 }, “fields” : { “name” : [ “xh2107091117” ] } }, { “_index” : “test”, “_type” : “_doc”, “_id” : “53371”, “_score” : 1.0, “_source” : { “name” : “testName”, “id” : 45868 }, “fields” : { “name” : [ “testName” ] } }, { “_index” : “test”, “_type” : “_doc”, “_id” : “53390”, “_score” : 1.0, “_source” : { “name” : “text”, “id” : 45873 }, “fields” : { “name” : [ “text” ] } } ] } } } }, { “_index” : “test”, “_type” : “_doc”, “_id” : “50735”, “_score” : null, “_source” : { “name” : “apk”, “id” : 380 }, “fields” : { “second_id” : [ 2208 ] }, “sort” : [ 2208 ], “inner_hits” : { “by_location” : { “hits” : { “total” : { “value” : 59, “relation” : “eq” }, “max_score” : null, “hits” : [ { “_index” : “test”, “_type” : “_doc”, “_id” : “50735”, “_score” : 1.0, “_source” : { “name” : “apk”, “id” : 380 }, “fields” : { “name” : [ “apk” ] } }, { “_index” : “test”, “_type” : “_doc”, “_id” : “44901”, “_score” : 1.0, “_source” : { “name” : “testName2”, “id” : 43066 }, “fields” : { “name” : [ “testName2” ] } }, { “_index” : “test”, “_type” : “_doc”, “_id” : “51399”, “_score” : 1.0, “_source” : { “name” : “testName3”, “id” : 43066 }, “fields” : { “name” : [ “testName3” ] } } ] } } } } ] }, “aggregations” : { “totalSize” : { “value” : 1 } } }
<a name="CfETO"></a>
### 折叠后的topN
:::info
如果想获取折叠后,同值字段的前几条数据,可通过inner_hits获取。见例2 #3
:::
<a name="B2Zw4"></a>
### 和search_after搭配使用
例3
```java
GET /my-index-000001/_search
{
"query": {
"match": {
"message": "GET /search"
}
},
"collapse": {
"field": "user.id"
},
"sort": [ "user.id" ],
"search_after": ["dd5ce1ad"]
}
二级折叠不支持inner_hits
这句的意思是,看例2#4和#6处,这里的collapse位于#6的下一级,如果这里再定义inner_hits,例如:
例4
"collapse": {
"field": "second_id",
"inner_hits": {
"name": "by_location",
"collapse": {
"field": "name",
"inner_hits": { #1
"name": "by_location"
}
},
"_source": [
"id",
"is_lastest",
"second",
"name"
],
"size": 3
}
},
# 由于#1处,inner_hits处于第二级collapse下,则报错如下
{
"error": {
"root_cause": [
{
"type": "parsing_exception",
"reason": "Invalid token in the inner collapse",
"line": 28,
"col": 25
}
],
"type": "x_content_parse_exception",
"reason": "[28:25] [collapse] failed to parse field [inner_hits]",
"caused_by": {
"type": "x_content_parse_exception",
"reason": "[28:25] [inner_hits] failed to parse field [collapse]",
"caused_by": {
"type": "parsing_exception",
"reason": "Invalid token in the inner collapse",
"line": 28,
"col": 25
}
}
},
"status": 400
}
筛选搜索结果
post_filter
GET /shirts/_search
{
"query": {
"bool": {
"filter": {
"term": { "brand": "gucci" }
}
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
},
"color_red": {
"filter": {
"term": { "color": "red" }
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
},
"post_filter": {
"term": { "color": "red" }
}
}
# post_filter是对聚合后的结果再次进行过滤,性能消耗较大,且不适用缓存,看场景而用。
query rescorer
:::info 可用于优化match_phase ::: query rescorer仅对query和post_filter阶段返回的Top-K结果执行第二个查询。每个分片上将检查的文档数量可以通过window_size参数控制,该参数默认为10。 默认情况下,原始查询和rescore查询的分数线性组合,以生成每个文档的最终_score。可以分别使用query_weight和rescore_query_weight来控制原始查询和rescore查询的相对重要性。两者都默认为
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : {
"window_size" : 50,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}
}
可以使用score_mode控制分数组合的方式:
| 分数模式 | 描述 |
|---|---|
| total | 添加原始分数和rescore查询分数。默认值。 |
| multiply | 将原始分数乘以rescore查询分数。对function query重新调整有用。 |
| avg | 平均原始分数和rescore查询分数。 |
| max | 取最大原始分数和rescore查询分数。 |
| min | 取最初得分和rescore查询得分的分钟。 |
Multiple Rescores
也可以按顺序执行多个重新扫描:
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : [ {
"window_size" : 100,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}, {
"window_size" : 10,
"query" : {
"score_mode": "multiply",
"rescore_query" : {
"function_score" : {
"script_score": {
"script": {
"source": "Math.log10(doc.likes.value + 2)"
}
}
}
}
}
} ]
}
突出显示(高亮)
简单示例
GET /_search
{
"query": {
"match": { "content": "kimchy" }
},
"highlight": {
"fields": {
"content": {}
}
}
}
GET ljh_text/_search
{
"query": {
"match": {
"content": {
"query": "父亲"
}
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "父亲",
"slop": 1
}
}
},
"rescore_query_weight": 10
}
},
"_source": false,
"highlight": {
"order": "score",
"tags_schema":"styled",
"fields": {
"content": {
"type": "unified",
"fragment_size": 150,
"number_of_fragments": 3,
"highlight_query": {
"bool": {
"must": {
"match": {
"content": {
"query": "父亲"
}
}
},
"should": {
"match_phrase": {
"content": {
"query": "父亲",
"slop": 1,
"boost": 10.0
}
}
},
"minimum_should_match": 0
}
}
}
}
}
}
参数使用示例
以上示例参数解释
| 参数 | 含义 | 备注 |
|---|---|---|
| #1 no_match_size | 即使字段中没有关键字命中,也可以返回一段文字,该参数表示从开始多少个字符被返回。 | |
| #2 encoder | 转义HTML,默认default,不转义 | 比如设置为html, 会被转义成:<div> |
| #3 number_of_fragment | 返回结果最多可以包含几段不连续的文字。默认是5。 | |
| #4 fragment_size | 返回的每个片段,文本长度,默认150 | |
| #5 pre_tags,post_tags | 标记 highlight 的开始,结束 标签 | |
| #6 order | 文本中,片段是否按分数排序 | 如果有需求要求更匹配的段落优先展示,可设置 |
| highlight—>type | 使用的高亮模式:unified, plain, or fvh. 默认为 unified。 | |
| highlight->tags_schema | 设置为使用内置标记模式的样式。 | 设置后,返回数据变成”””包着的数据 |
高亮优化
高亮查询渲染所有高亮数据,性能消耗较大,可通过rescore优化
GET ljh_text/_search
{
"query": {
"match": {
"content": {
"query": "父亲"
}
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "父亲",
"slop": 1
}
}
},
"rescore_query_weight": 10
}
},
"_source": false,
"highlight": {
"order": "score",
"fields": {
"content": {
"fragment_size": 150,
"number_of_fragments": 3,
"highlight_query": {
"bool": {
"must": {
"match": {
"content": {
"query": "父亲"
}
}
},
"should": {
"match_phrase": {
"content": {
"query": "父亲",
"slop": 1,
"boost": 10.0
}
}
},
"minimum_should_match": 0
}
}
}
}
}
}
长时间运行的搜索
:::info Elasticsearch 7.7 版本带来一个新的特性,search 过程允许异步执行,客户端发送完 search 请求后,Elasticsearch 服务端给客户端返回一个 id,以后客户端拿这个 id 来获取 search进度,并且支持返回“部分”结果,这对于 UI 交互相关的查询请求非常友好,例如绘图过程可以逐步的显示出来。使用示例 :::
近实时搜索
写入流程
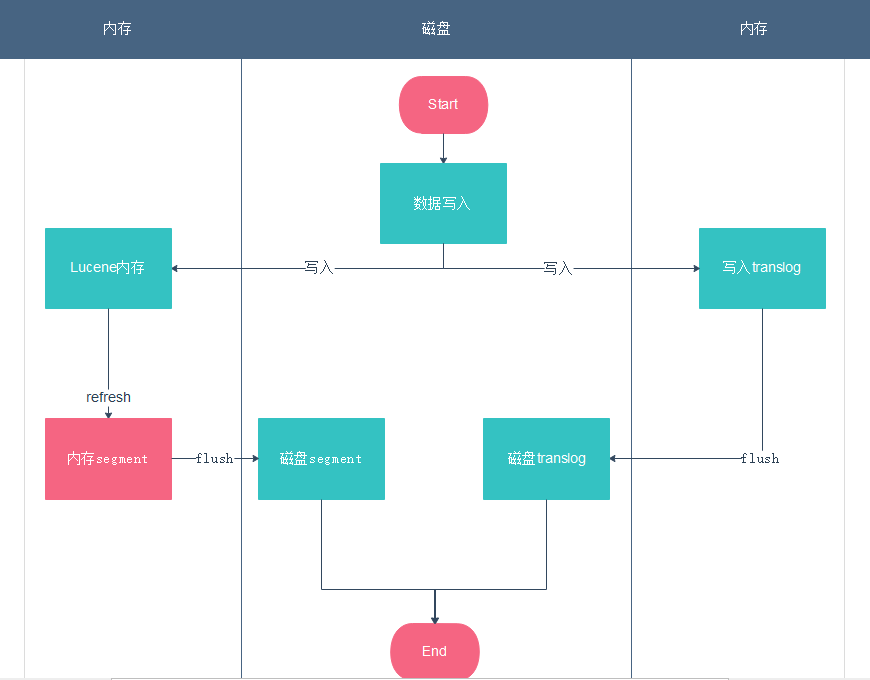 :::info
1:数据写入Lucene内存和translog
:::info
1:数据写入Lucene内存和translog
2:经过设置的refresh时间,默认1秒,Lucene内存转segment,reopen,此时可搜索
3:经过设置的flush时间,默认30分钟,内存中的segment写磁盘,历史translog清空,完成一次刷新。
由于经过1秒才从Lucene内存转到可搜索的segment,所以es是近实时的搜索
:::
分页搜索结果
方式1:from+size
GET /_search
{
"from": 5,
"size": 20,
"query": {
"match": {
"user.id": "kimchy"
}
}
}
方式2:scroll_id滚动搜索
:::tips
不再建议使用卷轴 API 进行深度填充。如果需要在超过 10,000 次点击时保持索引状态,请使用具有时间点 (PIT)search_after参数。 :::
POST /my-index-000001/_search?scroll=1m
{
"size": 100,
"query": {
"match": {
"message": "foo"
}
}
}
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
# 清除滚动
DELETE /_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
方式3:search_after
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos"}},
{"_shard_doc": "desc"}
]
}
返回
{
"pit_id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"took" : 17,
"timed_out" : false,
"_shards" : ...,
"hits" : {
"total" : ...,
"max_score" : null,
"hits" : [
...
{
"_index" : "my-index-000001",
"_id" : "FaslK3QBySSL_rrj9zM5",
"_score" : null,
"_source" : ...,
"sort" : [
"2021-05-20T05:30:04.832Z",
4294967298
]
}
]
}
}
再次请求
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos"}}
],
"search_after": [
"2021-05-20T05:30:04.832Z",
4294967298
],
"track_total_hits": false
}
检索内部命中 inner_hits
:::info
用于join的父子类型和nested嵌套查询时,返回具体匹配的那个对象
inner_hits中支持的参数:from,size,sort,name
:::
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"number": 1
},
{
"author": "nik9000",
"number": 2
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": { "comments.number": 2 }
},
"inner_hits": {}
}
}
}
检索所选字段
跨群集搜索
搜索多个数据流和索引
搜索分片路由
搜索模板
对搜索结果排序
参考:↓
博文:https://www.cnblogs.com/gmhappy/p/11864048.html
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-your-data.html

若有收获,就点个赞吧
0 人点赞
