- 一:概述说明
- 1 分析器指定为ngram
- 2 filter指定为ngram
- 二:配置文本分析
- 1 将 standard 分析器定义为基于标准分析器,但配置为删除预定义的英语停止词列表。
- 2 my_text 字段直接使用标准分析器,无需任何配置。此字段中不会删除任何停止字。由此产生的术语是:[The,old,brown,cow]
- 3 my_text.english 字段使用 standard 分析器,因此英语停止词将被删除。由此产生的术语是:
[old,brown,cow] - 二:内置分析器参考(Analyzer )
- 三:令牌器参考(tokenizer)
- 四:令牌过滤器参考
- 五:字符过滤器参考
- 六:规范化器(normalizer)
一:概述说明
1:概述
文本分析可以使弹性搜索执行全文检索,返回相关数据,不仅仅是精确匹配,具体可以执行以下操作实现:
- 1:令牌化(Tokenization)
- 2:规范化(Normalization)
- 3:指定文本分析器,或者自定义分析器
- 3.1 自定义分析器使您可以控制分析过程的每个步骤,包含:
- a:令牌化拆词之前对文本的更改
- b:如何将文本转换为令牌
- c:索引或搜索之前对对令牌所做的规范化更改
2:说明
分析器无论是内置的还是自定义的都只是一个包含三个较低级别的构建基块的包:字符过滤器、令牌器和令牌过滤器1:字符过滤器
:::success 分析仪可能具有零或多个字符过滤器,按顺序应用。 ::: 接收原始的字符流,通过字符过滤器,可以添加,删除,修改 原有字符流。例如:将大写统一改成小写,或者从流中取出HTML元素 - 等标识
2:令牌器
:::success 分析仪必须正好有一个令牌器. ::: 决定了文本的拆分策略3:令牌过滤器
:::success 分析仪可能具有零或更多令牌过滤器,按顺序应用。 ::: 索引流程: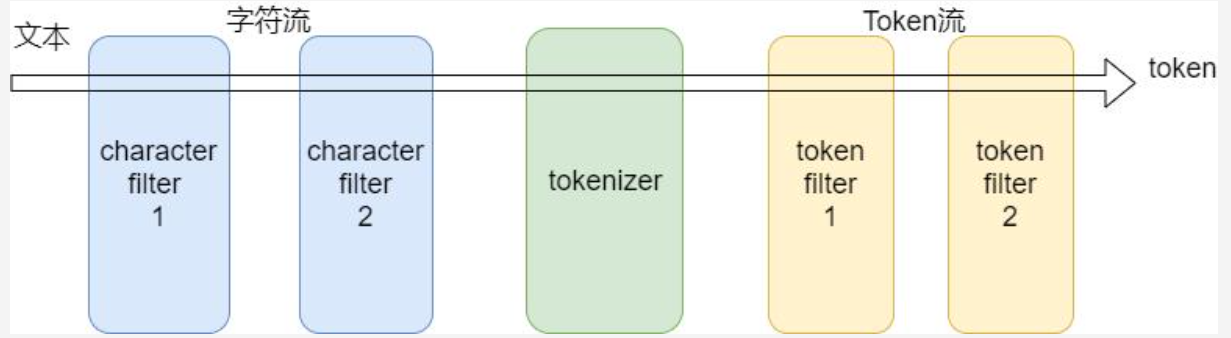
4:常用示例
1:ngram作为tokenizer和作为filter的区别
```shell1 分析器指定为ngram
PUT ngram_custom_example { “mappings”: { “properties”: { “name”: { “type”: “keyword”, “fields”: { “ngram”: {
} } } } }, “settings”: { “analysis”: { “analyzer”: { “lower_ngram_1_2”: { “filter”: ["type": "text","analyzer": "lower_ngram_1_2"
], “type”: “custom”, “tokenizer”: “my_ng_1_2” } }, “tokenizer”: { “my_ng_1_2”: { “type”: “ngram”, “min_gram”: “2”, “max_gram”: “3” } } } } }"lowercase"
- 3.1 自定义分析器使您可以控制分析过程的每个步骤,包含:
PUT ngram_custom_example/_doc/1 { “name” : “中华 人民 共和国 国歌 歌曲” }
GET ngram_custom_example/_search { “query”: { “match”: { “name.ngram”: “国 “ } } }
GET ngram_custom_example/_doc/1
GET /ngram_custom_example/_termvectors/1?fields=name.ngram
2 filter指定为ngram
PUT ngram_custom_example1 { “mappings”: { “properties”: { “name”: { “type”: “keyword”, “fields”: { “ngram”: { “type”: “text”, “analyzer”: “default” } } } } }, “settings”: { “index”: { “max_ngram_diff”: 2 }, “analysis”: { “analyzer”: { “default”: { “tokenizer”: “whitespace”, “filter”: [ “1_2_grams” ] } }, “filter”: { “1_2_grams”: { “type”: “ngram”, “min_gram”: 2, “max_gram”: 3 } } } } }
PUT ngram_custom_example1/_doc/1 { “name” : “中华 人民 共和国 国歌 歌曲” }
GET ngram_custom_example1/_doc/1
GET /ngram_custom_example1/_termvectors/1?fields=name.ngram
GET ngram_custom_example1/_search { “query”: { “match”: { “name.ngram”: “华 人 “ } } }
:::tips
以上主要区别:<br />第一种在数据流进入时,步骤如下:<br />1:转小写<br />2:token化,将原始文本设置成最小为两个单词,最大为三个词的token块
第二种在数据流进入时,步骤如下:<br />1:按空格分词<br />2:token化,将第一步操作后的文本,再次经过过滤器,设置成最小为两个单词,最大为三个词的token块<br />在<br />在实际应用场景中,如果模糊搜索:“华 人”这个词,注意中间有个空格,则第一种可以搜到,第二种,搜索不到结果,第一种更适合做类似MySQL的模糊搜索,第二种更适合做先空格分词,后token化的场景
:::
<a name="E2ZMh"></a>
#### 2:一个有 normalizer,多个analyzer,analyzer包含filter,自定义tokenizer的索引
```shell
PUT test_ik
{
"aliases": {
"test_ik_a": {}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"fields": {
"lower_keyword": {
"type": "keyword",
"normalizer": "keyword_lowercase"
},
"lower_ngram": {
"type": "text",
"analyzer": "lower_ngram_1_2"
},
"standard_1": {
"type": "text",
"analyzer": "standard"
},
"id" : {
"type" : "text",
"analyzer" : "ik"
}
}
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"max_result_window": "100000000",
"analysis": {
"normalizer": {
"keyword_lowercase": {
"filter": [
"lowercase"
],
"type": "custom"
}
},
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
},
"ngram_1_2": {
"type": "custom",
"tokenizer": "my_tokenizer"
},
"lower_ik": {
"filter": [
"lowercase"
],
"tokenizer": "ik_max_word"
},
"lower_ngram_1_2": {
"filter": [
"lowercase"
],
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": "1",
"max_gram": "2"
}
}
},
"number_of_replicas": "0"
}
}
}
3:自定义一个filter,停用词过滤器
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "whitespace",
"filter": [ "my_custom_stop_words_filter" ]
}
},
"filter": {
"my_custom_stop_words_filter": {
"type": "stop",
"ignore_case": true,
"stopwords": [ "and", "is", "the" ]
}
}
}
}
}
##
中文、日文,韩国:_cjk_
英语:_english_
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "whitespace",
"filter": [ "my_custom_stop_words_filter" ]
}
},
"filter": {
"my_custom_stop_words_filter": {
"type": "stop",
"ignore_case": true,
"stopwords":"_english_"
}
}
}
}
}
二:配置文本分析
:::info 默认情况下,搜索使用standard分析仪进行所有文本分析。standard分析仪提供大多数自然语言和使用案例的开箱即用的支持。如果您选择按standard分析仪,则无需进一步配置。
如果标准分析仪不满足需求,请审查和测试弹性搜索的其他内置分析仪。内置分析仪不需要配置,但一些支持选项可用于调整其行为。例如,您可以使用自定义停止词列表来配置standard分析仪以删除。
如果没有内置分析仪满足您的需求,您可以测试并创建自定义分析仪。自定义分析仪涉及选择和组合不同的分析器组件,更好地控制过程 :::
测试分析仪
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
配置内置分析仪
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard", #1
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "standard",
"fields": {
"english": {
"type": "text",
"analyzer": "std_english"
}
}
}
}
}
}
POST my-index-000001/_analyze
{
"field": "my_text", #2
"text": "The old brown cow"
}
POST my-index-000001/_analyze
{
"field": "my_text.english", #3
"text": "The old brown cow"
}
说明如下: :::tips
1 将 standard 分析器定义为基于标准分析器,但配置为删除预定义的英语停止词列表。
2 my_text 字段直接使用标准分析器,无需任何配置。此字段中不会删除任何停止字。由此产生的术语是:[The,old,brown,cow]
3 my_text.english 字段使用 standard 分析器,因此英语停止词将被删除。由此产生的术语是:
[old,brown,cow]
创建自定义分析器
在上述“一:概述说明“部分,有自定义配置的说明和流程,这里在增加两个示例
1:简单定义一个自定义分析器
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "Is this <b>déjà vu</b>?"
}
2:char_filter,tokenizer,filter都是自定义,示例
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"char_filter": [
"emoticons"
],
"tokenizer": "punctuation",
"filter": [
"lowercase",
"english_stop"
]
}
},
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": "[ .,!?]"
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [
":) => _happy_",
":( => _sad_"
]
}
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "I'm a :) person, and you?"
}
指定分析仪
在进行搜索时,到底用哪一种分析器进行分析呢,默认ES将进行如下判断
1:字段设置的analyzer
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
2:analysis.analyzer.default索引设置
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
}
}
}
}
}
3:指定不同的分析器
:::tips 在大多数情况下,没有必要指定不同的搜索分析器。这样做可能会对相关性产生负面影响,并导致意外的搜索结果。 :::
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
二:内置分析器参考(Analyzer )
一览
:::info
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Pattern Analyzer - 正则表达式,默认 \W+
Language - 提供了 30 多种常见语言的分词器
Fingerprint Analyzer
Customer Analyzer 自定义分词器
:::
1:Standard Analyzer
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5, #1
"stopwords": "_english_" #2
}
}
}
}
}
#1 最大token长度,默认255
#2 预先定义的停止词列表(如_english_或包含停止单词列表的阵列。默认到_none_.
2:Simple Analyzer
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_simple_analyzer": {
"tokenizer": "lowercase",
"filter": [
]
}
}
}
}
}
3:Whitespace Analyzer
PUT /whitespace_example
{
"settings": {
"analysis": {
"analyzer": {
"rebuilt_whitespace": {
"tokenizer": "whitespace",
"filter": [
]
}
}
}
}
}
4:Stop Analyzer
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_stop_analyzer": {
"type": "stop",
"stopwords": ["the", "over"]
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_stop_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
5:Keyword Analyzer
:::success 这个一般不需要配置,将字段设置成keyword类型即可。当然,如果想用分析器,可通过以下方式配置,效果是一样的 :::
PUT /keyword_example
{
"settings": {
"analysis": {
"analyzer": {
"rebuilt_keyword": {
"tokenizer": "keyword",
"filter": [
]
}
}
}
}
}
6:Pattern Analyzer
:::tips pattern分析器使用常规表达式将文本拆分为术语。常规表达应匹配令牌分离器,而不是令牌本身。常规表达默认为\W+或所有非单词字符)。
写得不好的常规表达方式可能会运行非常缓慢,甚至会抛出堆栈溢出器,并导致它运行的节点突然退出。 :::
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\\W|_",
"lowercase": true
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_email_analyzer",
"text": "John_Smith@foo-bar.com"
}
#复杂的示例:↓
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"camel": {
"type": "pattern",
"pattern": "([^\\p{L}\\d]+)|(?<=\\D)(?=\\d)|(?<=\\d)(?=\\D)|(?<=[\\p{L}&&[^\\p{Lu}]])(?=\\p{Lu})|(?<=\\p{Lu})(?=\\p{Lu}[\\p{L}&&[^\\p{Lu}]])"
}
}
}
}
}
GET my-index-000001/_analyze
{
"analyzer": "camel",
"text": "MooseX::FTPClass2_beta"
}
7:Language Analyzers
PUT /armenian_example
{
"settings": {
"analysis": {
"filter": {
"armenian_stop": {
"type": "stop",
"stopwords": "_armenian_"
},
"armenian_keywords": {
"type": "keyword_marker",
"keywords": ["օրինակ"]
},
"armenian_stemmer": {
"type": "stemmer",
"language": "armenian"
}
},
"analyzer": {
"rebuilt_armenian": {
"tokenizer": "standard",
"filter": [
"lowercase",
"armenian_stop",
"armenian_keywords",
"armenian_stemmer"
]
}
}
}
}
}
8:Fingerprint Analyzer
:::success 输入文本采用小写、标准化以删除扩展字符、排序、消除重复并连接到单个标记中。如果配置了停止字列表,也将删除停止字。 :::
POST _analyze
{
"analyzer": "fingerprint",
"tokenizer": "",
"text": "ni,hao,hao ,ma ,h,a,c,zero,next"
}
输出:
{
"tokens" : [
{
"token" : "a c h hao ma next ni zero",
"start_offset" : 0,
"end_offset" : 31,
"type" : "fingerprint",
"position" : 0
}
]
}
#1
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_fingerprint_analyzer": {
"type": "fingerprint",
"stopwords": "_english_"
}
}
}
}
}
#2
UT /fingerprint_example
{
"settings": {
"analysis": {
"analyzer": {
"rebuilt_fingerprint": {
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding",
"fingerprint"
]
}
}
}
}
}
三:令牌器参考(tokenizer)
面向单词的令牌器
Standard Tokenizer :::info standard令牌将文本划分为单词边界的术语,如 Unicode 文本细分算法所定义。它删除大多数标点符号。它是大多数语言的最佳选择。 :::
Letter Tokenizer :::info letter令牌在遇到不是字母的字符时,都会将文本分为术语。 ::: Lowercase Tokenizer :::info lowercase令牌器,如字母令牌,每当遇到不是letter的字符时,都会将文本划分为术语,但也会降低所有术语的字数。 ::: Whitespace Tokenizer :::info 每当遇到任何空白字符时,whitespace令牌器都会将文本分为术语。 ::: UAX URL Email Tokenizer :::info uax_url_email令牌器就像standard令牌,只不过它识别网址和电子邮件地址为单个令牌。 ::: Classic Tokenizer :::info classic的令牌器是英语的基于语法的令牌 ::: Thai Tokenizer :::info thai令牌器将泰文文本分割成文字 :::
ngram令牌
N-Gram Tokenizer :::info ngram令牌器在遇到任何指定字符列表(例如空白或标点符号)时,可以将文本分解为单词,然后返回每个单词的 n-克:连续字母的滑动窗口,例如quick→ [qu, ui, ic, ck]. :::
结构化文本令牌器
Keyword Tokenizer :::info keyword令牌器是一个”noop”令牌,它接受它给出的任何文本,并输出与单个术语完全相同的文本。它可以与lowercase等令牌过滤器相结合,使分析的术语正常化。
::: Pattern Tokenizer :::info pattern令牌使用常规表达方式,即在文本与单词分离器匹配时将文本拆分为术语,或者捕获匹配的文本作为术语。
::: Simple Pattern Tokenizer :::info simple_pattern令牌使用常规表达来捕获匹配的文本作为术语。它使用常规表达功能的受限子集,通常比pattern令牌器快。
::: Char Group Tokenizer :::info char_group令牌器可通过一组字符进行配置,通常比运行常规表达式更便宜。
::: Simple Pattern Split Tokenizer :::info simple_pattern_split令牌器使用与simple_pattern令牌器相同的受限常规表达子集,但会在比赛时拆分输入,而不是将匹配项作为术语返回。
::: Path Tokenizer :::info path_hierarchy令牌器具有等级值,如文件系统路径,在路径分离器上分裂,并为树中的每个组件发出一个术语,例如/foo/bar/baz → [/foo, /foo/bar, /foo/bar/baz ]. :::
四:令牌过滤器参考
#token filter是在分词后,进行的进一步处理,一般用于大小写,特殊字符等。不过一般更倾向于在分词时处理,
比如上述第一个示例中的ngram放在分词器和filter中的区别。总之,看具体场景,具体的令牌过滤器有以下
几种类型,具体用法这里不做说明。
Classic
Common grams
Conditional
Decimal digit
Delimited payload
Dictionary decompounder
Edge n-gram
Elision
Fingerprint
Flatten graph
Hunspell
Hyphenation decompounder
Keep types
Keep words
Keyword marker
Keyword repeat
KStem
Length
Limit token count
Lowercase
MinHash
Multiplexer
N-gram
Normalization
Pattern capture
Pattern replace
Phonetic
Porter stem
Predicate script
Remove duplicates
Reverse
Shingle
Snowball
Stemmer
Stemmer override
Stop
Synonym
Synonym graph
Trim
Truncate
Unique
Uppercase
Word delimiter
Word delimiter graph
五:字符过滤器参考
1:HTML Strip Character Filter
:::info html_strip字符过滤器剥离了 Html 元素, 如并解码 Html 实体 :::
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"html_strip"
]
}
}
}
}
}
2:Mapping Character Filter
:::info mapping字符过滤器用指定的替换替换指定字符串的任何事件替换。 :::
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_mappings_char_filter"
]
}
},
"char_filter": {
"my_mappings_char_filter": {
"type": "mapping",
"mappings": [
":) => _happy_",
":( => _sad_"
]
}
}
}
}
}
POST /my-index-000001/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
PUT my-index-000001/_doc/1
{
"name" : "i'm :)"
}
GET my-index-000001/_search
{
"query": {
"match": {
"name": "_happy_"
}
}
}
#以上查询输出
。。。
"hits" : [
{
"_index" : "my-index-000001",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "i'm :)"
}
}
]
。。。
GET /my-index-000001/_analyze
{
"tokenizer": "keyword",
"char_filter": [ "my_mappings_char_filter" ],
"text": "I'm delighted about it :("
}
[ I'm delighted about it _sad_ ]
3:Pattern Replace Character Filter
:::info
attern_replace字符过滤器将替换任何与常规表达式与指定替换匹配的字符。
:::
:::info
慎用,写得不好的常规表达方式可能会运行非常缓慢,甚至会抛出堆栈溢出器,并导致它运行的节点突然退出。
这种场景,也可以使用管道处理,具体可搜索ElasticSearch的setting设置管道:default_pipeline
default_pipeline将放到:速查手册12-Ingest pipelines
:::
PUT my-index-00001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
POST my-index-00001/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}
六:规范化器(normalizer)
:::info 类似于分析器,但只能产生出单个Token,而分析器是可以一对多的 另外,Normalizers会使得 文本进入引擎后,在后面的流程中得到的都是变换后的结果 举个栗子:最简单的lowercase 功能是小写化 :::
PUT index
{
"settings": {
"analysis": {
"char_filter": {
"quote": {
"type": "mapping",
"mappings": [
"« => \"",
"» => \""
]
}
},
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": ["quote"], # 1
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
# 1 过滤器支持以下几种:
arabic_normalization, asciifolding, bengali_normalization,
cjk_width, decimal_digit, elision, german_normalization,
hindi_normalization, indic_normalization, lowercase,
persian_normalization, scandinavian_folding, serbian_normalization,
sorani_normalization, uppercase.
参考地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/analysis.html

若有收获,就点个赞吧
0 人点赞
