字数: 预计阅读时长:
优化方向
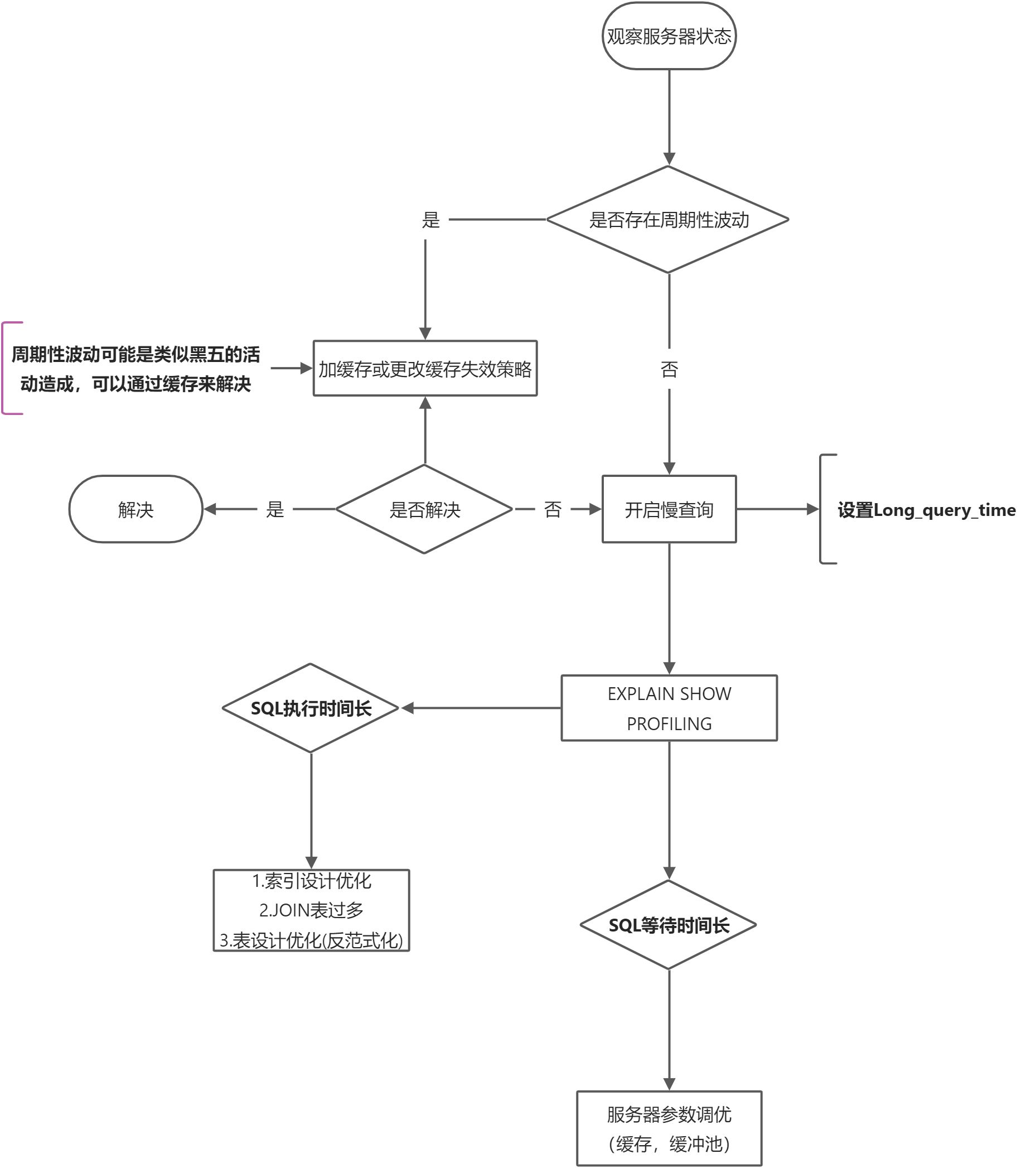
查看系统性能参数
常见参数
- Connection: MySQL服务器的连接次数
- Uptime : 服务器上线时间
- Slow_queries : 慢查询的条数
show status \G;mysql> SHOW status like '%slow_queries%';+---------------+-------+| Variable_name | Value |+---------------+-------+| Slow_queries | 0 |+---------------+-------+1 row in set (0.00 sec)
查询成本
```sql mysql> select * from tb1; +———+———-+ | id | name | +———+———-+ | 1 | name1 | | 2 | name2 | | 3 | name3 | +———+———-+ 3 rows in set (0.00 sec)
mysql> show status like ‘last_query_cost’; +————————-+—————+ | Variable_name | Value | +————————-+—————+ | Last_query_cost | 0.549000 | +————————-+—————+ 1 row in set (0.00 sec)
```sql+----------+| Value |+----------+| 0.549000 |+----------+# value指这条语句用到的页的数量
:::info SQL查询从页的加载角度看:
位置决定效率页的位置可能在磁盘 / 内存 / 数据库缓冲池中,缓冲池的效率最高。IO顺序决定效率顺序IO效率远高于随机IO。 :::性能分析工具
慢查询日志
相关参数
超过阈值的为慢查询mysql> show variables like '%long%query%';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+
慢查询日志默认关闭,通过修改以下参数 [Global | Session] 开启。
mysql> show variables like '%slow_query_log%';+---------------------+-------------------------------------------+| Variable_name | Value |+---------------------+-------------------------------------------+| slow_query_log | OFF || slow_query_log_file | /var/lib/mysql/VM-xavier-CentOS7-slow.log |+---------------------+-------------------------------------------+2 rows in set (0.00 sec)
注意:如果不加Global ,操作的是session级别的变量,下一个会话会失效。
以上修改在mysqld服务重启后失效。 修改/etc/my.cnf 可永久生效
分析工具mysqldumpslow
[root@VM-xavier-CentOS7 mysql]# mysqldumpslow -a -t 5 /var/lib/mysql/VM-xavier-CentOS7-slow.logReading mysql slow query log from /var/lib/mysql/VM-xavier-CentOS7-slow.logCount: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hostsDied at /usr/bin/mysqldumpslow line 162, <> chunk 1.
查看执行成本:show profile
也可以在 information_schema 的 profiling 表中查看。 :::info 功能开启 ::: 该功能默认关闭,我们可在会话级别开启
mysql> show variables like '%profiling%';+------------------------+-------+| Variable_name | Value |+------------------------+-------+| have_profiling | YES || profiling | OFF || profiling_history_size | 15 |+------------------------+-------+3 rows in set (0.00 sec)
:::info 指令演示 :::
mysql> show profiles;+----------+------------+-----------------------------------+| Query_ID | Duration | Query |+----------+------------+-----------------------------------+| 1 | 0.00174550 | show variables like '%profiling%' || 2 | 0.00013850 | select database() || 3 | 0.00065250 | show databases || 4 | 0.00101425 | show tables || 5 | 0.00025675 | select * from tb1 |+----------+------------+-----------------------------------+5 rows in set, 1 warning (0.00 sec)
mysql> show profile for query 5;+--------------------------------+----------+| Status | Duration |+--------------------------------+----------+| starting | 0.000074 || Executing hook on transaction | 0.000005 || starting | 0.000007 || checking permissions | 0.000007 || Opening tables | 0.000030 || init | 0.000006 || System lock | 0.000009 || optimizing | 0.000005 || statistics | 0.000012 || preparing | 0.000015 || executing | 0.000040 || end | 0.000005 || query end | 0.000004 || waiting for handler commit | 0.000007 || closing tables | 0.000007 || freeing items | 0.000015 || cleaning up | 0.000012 |+--------------------------------+----------+17 rows in set, 1 warning (0.00 sec)
EXPLAIN
- 功能 :查看执行计划。
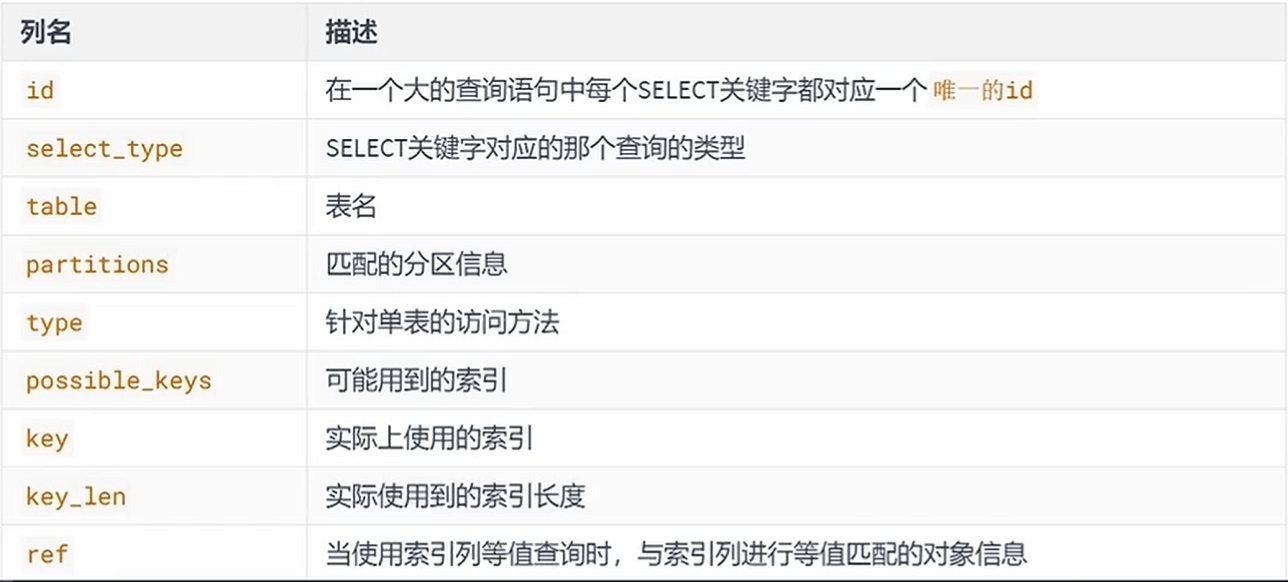

字段解析
Table
- 每个
SELECT的FROM子句中可以包含若干张表,每张表都对应执行计划中的一条记录。 ,EXPLAIN有两条结果")
- 多表时:靠前的table是驱动表,靠后的是被驱动表
:::info
对Union操作,需要临时表去重
:::

id
- 每一个
SELECT对应着一个 id 。 - 同一个
SELECT关键字中的表拥有相同的id值 - 例:子查询
:::info
优化器Optimizer 可能对子查询重写,转为多表查询
子查询类似与嵌套循环,复杂度为O(n^2)。而多表查询为O(n)。 ::: :::success 小结:
- id相同的为一组,从上往下顺序执行
- 在所有组中,id值越大,优先级越高 :::
select_type
一个大查询语句包含多个小查询, select_type 指对应的
SELECT的类型。 :::success SIMPLE :::普通查询,连接查询都是 SIMPLE类型
 :::success
UNION 操作中的 select_type
:::
:::success
UNION 操作中的 select_type
:::
- PRIMARY: UNION操作中最左边的
SELECT - UNION :UNION操作中其他的
SELECT - UNION RESULT: 临时表
 :::success
不能转为多表连接的子查询
:::
:::success
不能转为多表连接的子查询
:::
- 不相关子查询
- 外层查询select_type为 PRIMARY
- 内层子查询 select_type 为 SUBQUERY.
- 相关子查询
- 外层查询select_type为 PRIMARY
- 内层子查询 select_type 为 DEPENDENT_SUBQUERY.
:::success
UNION作为内层查询
:::
| id | Table | select_type | sql | 备注 | | —- | —- | —- | —- | —- | | 1 | table3 | PRIMARY | SELECT FROM table3 | 最外层查询最晚执行 | | 2 | table1 | DEPENDENT_SUBQUERY | SELECT FROM table1 | 子查询先执行 | | 3 | table2 | DEPENDENT_UNION | SELECT * FROM table2 | 子查询先执行 | | NULL |SELECT * FROM table3 WHERE XXIN (SELECT col FROM table1 UNION SELECT col FROM table2);
| | | |
:::success Derived :::
- 场景:用 查询结果 作为
FROM子句中的表时,select_type为 DERIVED.
:::success MATERIALIZED ::: 略。SELECT col FROM (SELECT * FROM tb1 WHERE ...) AS derived_table;
Type**
- 标志执行查询时的访问类型
:::info
const
:::
- 通过主键或二级索引与常量做等值比较
:::info
eq_ref
:::

 :::info
ref
:::
:::info
ref
:::
- 通过普通二级索引与常量做等值比较
:::info index_merge :::
- 索引合并 (例如 WHERE … OR … 而两个条件都有索引)
:::info
Unique_subquery
:::


- 查询优化器可能将
**IN**转为EXISTS - 过程:用
ALL访问方式访问 s1 表,key2 的值与 subquery 做等值比较。
:::info Range :::
- 用索引做范围查询
:::info Index :::
- 当可以使用索引覆盖,但需要scan全部索引记录时,type为
**index**.
Key_len
- key_len :用到的索引长度
- 注:对联合索引参考价值更大,若联合索引得到充分利用,那么通过where筛选剩下的记录就越少,读取的页就更少,IO次数更少,性能更高。
Ref
- 当使用索引列等值查询时,与索引列进行等值匹配的对象信息。
- 可能取值
- const — 等值匹配的是常量
- db1.tb1.col — 等值匹配的是数据表db1的表tb1的列col
- func — 函数
Rows**
- 预估需要读取的行数
Filtered**
- 过滤百分比
Extra**
- 额外的执行信息 :::info 详情参见帮助文档 :::
EXPLAIN 格式
:::info JSON格式:可以获取具体的成本信息 :::
mysql> explain format = JSON select * from tb1 where id = 2\G;*************************** 1. row ***************************EXPLAIN: {"query_block": {"select_id": 1,"cost_info": {"query_cost": "1.00"},"table": {"table_name": "tb1","access_type": "const","possible_keys": ["PRIMARY"],"key": "PRIMARY","used_key_parts": ["id"],"key_length": "4","ref": ["const"].....................
:::info TREE :::
- EXPLAIN FORMAT = TREE […..] ```sql mysql> explain format = Tree select from tb1 where id = 2\G; ** 1. row * EXPLAIN: -> Rows fetched before execution (cost=0.00..0.00 rows=1)
1 row in set (0.00 sec)
---<a name="JFqAt"></a>### Show warnings1. 在 `explain`之后紧接着用 `**show warnings**`1. `**message**`是重点,**可以看到mysql 改写后的sql语句**。```sqlmysql> explain select * from tb1 where id = 2;+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | tb1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.00 sec)mysql> show warnings;+-------+------+--------------------------------------------------------------------------------------+| Level | Code | Message |+-------+------+--------------------------------------------------------------------------------------+| Note | 1003 | /* select#1 */ select '2' AS `id`,'name2' AS `name` from `main_db1`.`tb1` where true |+-------+------+--------------------------------------------------------------------------------------+1 row in set (0.00 sec)
Trace:分析优化器执行计划
mysql> show variables like '%opti%tr%';+------------------------------+----------------------------------------------------------------------------+| Variable_name | Value |+------------------------------+----------------------------------------------------------------------------+| optimizer_trace | enabled=off,one_line=off || optimizer_trace_features | greedy_search=on,range_optimizer=on,dynamic_range=on,repeated_subselect=on || optimizer_trace_limit | 1 || optimizer_trace_max_mem_size | 1048576 || optimizer_trace_offset | -1 |+------------------------------+----------------------------------------------------------------------------+5 rows in set (0.01 sec)
:::info 该计划信息 在 information_schema 数据库的 OPTIMIZER_TRACE 表中 :::
mysql> show tables like '%opt%';+--------------------------------------+| Tables_in_information_schema (%OPT%) |+--------------------------------------+| OPTIMIZER_TRACE |+--------------------------------------+1 row in set (0.01 sec)
Sys schema系统视图
:::info 在 Sys 数据库中 有一些便于开发和运维快速定位问题的视图 :::
mysql> show tables like '%ind%';+---------------------------+| Tables_in_sys (%ind%) |+---------------------------+| schema_index_statistics || schema_redundant_indexes || schema_unused_indexes || x$schema_index_statistics |+---------------------------+4 rows in set (0.00 sec)mysql> select * from sys.schema_index_statistics limit 1\G;*************************** 1. row ***************************table_schema: main_db1table_name: tb1index_name: PRIMARYrows_selected: 5select_latency: 104.30 usrows_inserted: 0insert_latency: 0 psrows_updated: 0update_latency: 0 psrows_deleted: 0delete_latency: 0 ps1 row in set (0.00 sec)

若有收获,就点个赞吧
0 人点赞
