Intro
单节点的Redis存在以下问题:
- 数据丢失问题:通过数据持久化解决+主从(数据冗余)
- 并发能力问题:搭建主从集群,实现读写分离
- 存储能力问题:即便搭建了主从集群,其存储上限仍是单节点上限。因此需要搭建分片集群,通过插槽机制实现动态扩容。
- 故障恢复问题:单节点易发生单点故障,利用Redis哨兵,实现健康检测和自动恢复。或者在分片集群架构下,利用主节点之间的心跳检测自动做
**Failover**。Advanced Chapter
Distributed Cache
Persistence Policy
RDB(Redis Database Backup)
也可以叫
**Redis数据快照**,即把内存中的数据拷贝一份写入磁盘。当Redis实例故障重启后,从磁盘读取文件,恢复数据。################################ SNAPSHOTTING ################################# Save the DB to disk.## save <seconds> <changes>## Redis will save the DB if both the given number of seconds and the given# number of write operations against the DB occurred.## Snapshotting can be completely disabled with a single empty string argument# as in following example:## save ""## Unless specified otherwise, by default Redis will save the DB:# * After 3600 seconds (an hour) if at least 1 key changed# * After 300 seconds (5 minutes) if at least 100 keys changed# * After 60 seconds if at least 10000 keys changed## You can set these explicitly by uncommenting the three following lines.## save 3600 1# save 300 100# save 60 10000
23599:M 26 May 2022 16:10:24.067 * Saving the final RDB snapshot before exiting.23599:M 26 May 2022 16:10:24.072 * DB saved on disk23599:M 26 May 2022 16:10:24.072 * Removing the pid file.23599:M 26 May 2022 16:10:24.072 # Redis is now ready to exit, bye bye...
23599:M 26 May 2022 16:09:33.771 * Loading RDB produced by version 6.2.723599:M 26 May 2022 16:09:33.771 * RDB age 950392 seconds23599:M 26 May 2022 16:09:33.771 * RDB memory usage when created 0.84 Mb23599:M 26 May 2022 16:09:33.771 # Done loading RDB, keys loaded: 0, keys expired: 0.23599:M 26 May 2022 16:09:33.771 * DB loaded from disk: 0.011 seconds23599:M 26 May 2022 16:09:33.771 * Ready to accept connections
异步持久化
指Redis的
**bgsave**。bgsave开始时会fork主进程得到子进程( 子进程共享主进程的内存数据 ),完成fork后读取内存并写入RDB文件。
fork 就是fork页表
- copy-on-write 假设极端情况:在RDB过程中,Redis中的数据都被修改了一遍,就会造成占用内存翻倍。

AOF( Append Only File)
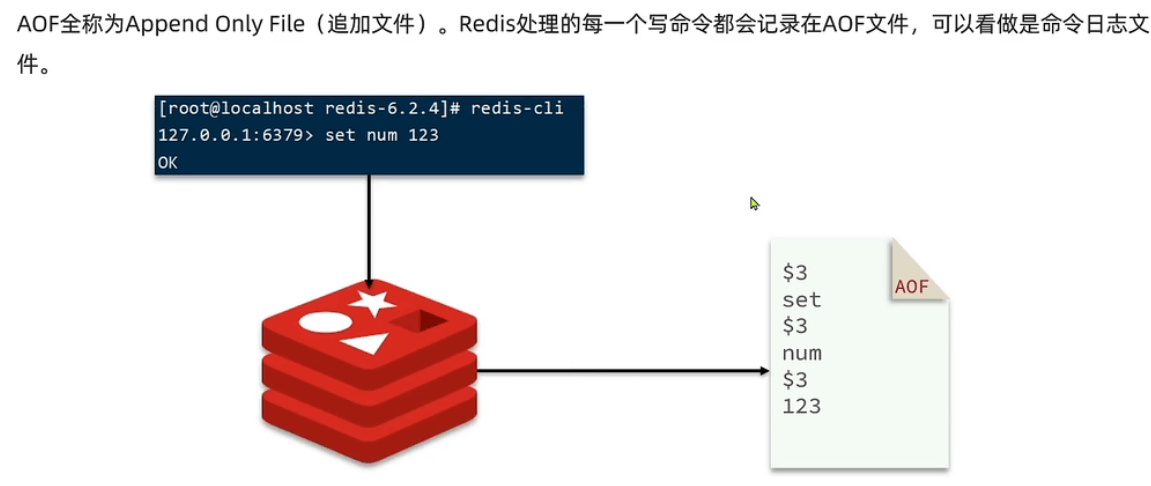
# The fsync() call tells the Operating System to actually write data on disk# instead of waiting for more data in the output buffer. Some OS will really flush# data on disk, some other OS will just try to do it ASAP.## Redis supports three different modes:# If unsure, use "everysec".# appendfsync alwaysappendfsync everysec #default option# appendfsync n
- AOF比RDB大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

总结:
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗和IO资源 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
- RDB 持久化( bgsave ),有一定时间间隔,会造成一定时间内的数据不安全。
- AOF持久化,默认每秒调用fsync() 告诉OS执行刷盘操作,将AOF缓冲区中的数据(这里指命令)刷盘到磁盘中去,仅有1s的数据不安全。
- AOF的 rewriteaof可以在
redis.conf文件中找到相关配置
Master-Slave
集群搭建步骤
tag:#主从集群搭建#搭建#md
RedisClusterSetUp.pdf
注意:需要在 replica的配置文件中配置 **masterauth**才能成功连接。
主从结果测试
127.0.0.1:6379> INFO replication# Replicationrole:masterconnected_slaves:2slave0:ip=121.5.43.28,port=6380,state=online,offset=28,lag=1slave1:ip=121.5.43.28,port=6381,state=online,offset=28,lag=1
127.0.0.1:6380> set num 123(error) READONLY You can't write against a read only replica.
Synchronization
Full Synchronization

Partial Resynchronization

**repl_baklog**是循环数组,slave宕机太久,master的offset会发生覆盖,导致slave无法增量同步,只能执行全量同步。- 全量 同步可以选择
**diskless_syc**即不启用bgsave再将.rdb文件发送给从节点,而是直接通过网络传输数据 - 因此,主从同步可以进行以下优化

Sentinel
作用

服务状态监控

选取新的master
选取规则:
故障恢复


哨兵集群搭建
RedisClusterSetUp.pdf
:::danger
注意:需要配置 **sentinel auth-pass <pswd>** !!!!!
:::
分片集群(Redis Cluster)
结构
前言:主从集群可以实现高并发读,但不能满足高可用。因此哨兵集群出现了,可以实现master和slave之间的自动切换,做故障的自动恢复,保证高可用,但仍有问题存在。
问题:
- 海量数据 存储。
- 主从和哨兵都只有一个主节点,存储容量上限是主节点。
- 高并发 写
- 主从和哨兵只有一个主节点负责写,高并发性能差

分片集群搭建
Tag :
Slots
Tag:#散列插槽slots


- 根据CRC16算法可以根据key的有效部分计算出对应的插槽值,
get,set数据时根据插槽自动切换节点。
故障转移
Redis Cluster doesn’t need sentinels cuz masters themselves send ping to each other every certain interval.
Auto Transfer
If one master goes done,it’s first marked disconnect then fail. Then other masters vote to elect a new master from it’s slaves automatically.
Manual Transfer
In certain occasions where we want specific machine to be master,we can use **FAILOVER**command to fail the master and let the slave take place (safely, bcz they will synchronize data) 

若有收获,就点个赞吧
0 人点赞
