ndarray对象
Numpy最重要的特点是N维数组对象ndarray,它是一系列同类型数据的集合
创建一维数组
- 方式一:直接传入列表 d = np.array([1, 2, 3])
- 方式二:传入range生成序列 d = np.array(range(10))
方式三:使用numpy自带的np.arange()生成数组 d = np.arange(0, 10, 2)
创建二维数组
一般方式:d = np.array([[1, 2], [3, 4], [5, 6]])
常用属性
- 创建数组:d = np.array([[1, 2], [3, 4], [5, 6]])
- 获得属性
- d.ndim:获取数组的维度 —> 2
- d.shape:获取数组的形状 —> (3, 2)
- d.size:获取数组中元素的个数 —> 6
调整数组的形状
```python import numpy as np
four = np.array([[1, 2, 3], [4, 5, 6]])
four.shape = (3, 2) # 对原数组进行调整 print(four)
four = four.reshape(3, 2) # 返回一个新数组 print(four)
four = np.resize(four, (3, 2)) # 如果新数组大小大于原始大小,则包含原始数组中的元素的副本 print(four)
five = four.reshape((2, 3), order=’F’) # 以列的顺序展开 print(five)
six = four.flatten() # 以行的顺序展开 print(six)
‘’’ [[1 2] [3 4] [5 6]]
[[1 2] [3 4] [5 6]]
[[1 5 4] [3 2 6]]
[1 2 3 4 5 6] ‘’’
<a name="jLSJm"></a>### 将数组转成list1. 创建数组:d = np.array([1, 2, 3, 4, 5])1. 转成list:a = d.tolist()<a name="JMMO9"></a>### 数据类型- 创建指定数据类型的数组:d = np.array([1, 2, 3], dtype=np.int16)- 获取数组的数据类型:print(d.dtype) --> int16- 获取数组中每个元素的字节长度:print(d.itemsize) --> 2- 调整数组的数据类型:d = d.astype(np.int64)- [数据类型的详细说明](https://www.runoob.com/numpy/numpy-dtype.html)<a name="QqKye"></a>## 数组的计算<a name="zlOWk"></a>### 广播机制- 广播是numpy对不同形状的数组进行数值计算的方式,当运算中的两个数组的形状不同时,将自动触发广播机制- 举例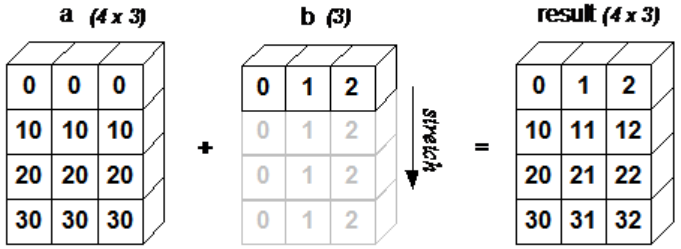- 规则- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加1补齐- 输出数组的形状是输入数组形状的各个维度上的最大值- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为1时,则这个数组能够用来计算,否则报错- 当输入数组的某个维度的长度为1时,沿着此维度运算时都用此维度上的第一组值- 简单理解:两个数组运算,把维度较小的数组扩展成与维度较大的数组相同的维度,如果两个数组的每个维度的值相等或者有一个是1,则可以运算,否则报错<a name="NH0KU"></a>### 数组和数的计算```pythond = np.arange(6).reshape((2, 3))print(d)print(d + 2)print(d * 2)print(d / 2)'''[[0 1 2][3 4 5]][[2 3 4][5 6 7]][[ 0 2 4][ 6 8 10]][[0. 0.5 1. ][1.5 2. 2.5]]'''
数组和数组的计算
d1 = np.arange(6).reshape((2, 3))d2 = np.arange(10, 16).reshape((2, 3))print(d1 + d2)print(d1 * d2)'''[[10 12 14][16 18 20]][[ 0 11 24][39 56 75]]'''
d1 = np.arange(6).reshape((2, 3))
d2 = np.arange(10, 13)
d3 = np.arange(10, 12).reshape((2, 1))
print(d1)
print(d2)
print(d3)
print(d1 + d2) # 行形状相同
print(d1 * d3) # 列形状相同
'''
[[0 1 2]
[3 4 5]]
[10 11 12]
[[10]
[11]]
[[10 12 14]
[13 15 17]]
[[ 0 10 20]
[33 44 55]]
'''
数组中的轴
最外层的轴最小,最里层的轴最大,轴从0开始
a = np.array([[1, 2, 3], [4, 5, 6]])
print(np.sum(a, axis=0))
# [5 7 9]
a = np.arange(27).reshape((3, 3, 3))
print(a)
'''
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]]
[[ 9 10 11]
[12 13 14]
[15 16 17]]
[[18 19 20]
[21 22 23]
[24 25 26]]]
'''
b = np.sum(a, axis=0)
print(b)
'''
[[27 30 33]
[36 39 42]
[45 48 51]]
'''
c = np.sum(a, axis=1)
print(c)
'''
[[ 9 12 15]
[36 39 42]
[63 66 69]]
'''
d = np.sum(a, axis=2)
print(d)
'''
[[ 3 12 21]
[30 39 48]
[57 66 75]]
'''
查:数组的索引和切片
对于一维数组
- 创建数组:d = np.arange(10)
- 索引:print(d[2]) —> 2
- 切片:print(d[2:7:2]) —> [2 4 6]
对于二维数组
```python import numpy as np
d = np.arange(12).reshape(3, 4) print(d) ‘’’ [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] ‘’’
print(d[1]) # 取一行
[4 5 6 7]
print(d[:, 1]) # 取一列
[1 5 9]
print(d[1:]) # 取连续的多行 ‘’’ [[ 4 5 6 7] [ 8 9 10 11]] ‘’’
print(d[1:3]) # 取连续的多行,左闭右开 ‘’’ [[ 4 5 6 7] [ 8 9 10 11]] ‘’’
print(d[:, 1:]) # 取连续的多列 ‘’’ [[ 1 2 3] [ 5 6 7] [ 9 10 11]] ‘’’
print(d[:, 0:4:2]) # 取连续的多列,左闭右开带步长 ‘’’ [[ 0 2] [ 4 6] [ 8 10]] ‘’’
print(d[[0, 2]]) # 取不连续的多行 ‘’’ [[ 0 1 2 3] [ 8 9 10 11]] ‘’’
print(d[:, [0, 2, 3]]) # 取不连续的多列 ‘’’ [[ 0 2 3] [ 4 6 7] [ 8 10 11]] ‘’’
print(d[2, 3]) # 取一个值
11
print(d[[1, 1, 2], [1, 2, 3]]) # 取多个值
[5 6 11]
print(d[1:3, 2:4]) # 取一块区域的值 ‘’’ [[ 6 7] [10 11]] ‘’’
<a name="vXJNi"></a>
## 改:修改数组中的数值
<a name="JJG0w"></a>
### 通过索引和切片
```python
import numpy as np
t = np.arange(12).reshape(3, 4)
print(t)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
'''
t[1, :] = 0 # 修改某一行的值
print(t)
'''
[[ 0 1 2 3]
[ 0 0 0 0]
[ 8 9 10 11]]
'''
t[:, 1] = 0 # 修改某一列的值
print(t)
'''
[[ 0 0 2 3]
[ 0 0 0 0]
[ 8 0 10 11]]
'''
t[1:3, :] = 2 # 修改连续多行
print(t)
'''
[[0 0 2 3]
[2 2 2 2]
[2 2 2 2]]
'''
t[:, 1:4] = -1 # 修改连续多列
print(t)
'''
[[ 0 -1 -1 -1]
[ 2 -1 -1 -1]
[ 2 -1 -1 -1]]
'''
t[1:3, 2:4] = -2 # 修改连续的多行多列
print(t)
'''
[[ 0 -1 -1 -1]
[ 2 -1 -2 -2]
[ 2 -1 -2 -2]]
'''
t[[0, 1], [0, 3]] = -3 # 修改多个不相邻的点
print(t)
'''
[[-3 -1 -1 -1]
[ 2 -1 -2 -3]
[ 2 -1 -2 -2]]
'''
通过布尔索引
布尔索引通过布尔运算(如比较运算符和逻辑运算符)来获取符合指定条件的元素的数组
import numpy as np
t = np.arange(12).reshape(3, 4)
print(t)
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
'''
print(t < 8)
'''
[[ True True True True]
[ True True True True]
[False False False False]]
'''
t[t < 8] = 0
print(t)
'''
[[ 0 0 0 0]
[ 0 0 0 0]
[ 8 9 10 11]]
'''
t = np.arange(12).reshape(3, 4)
print(t[(t > 2) & (t < 6)])
# [3 4 5]
t[(t > 2) & (t < 6)] = 0 # 与
print(t)
'''
[[ 0 1 2 0]
[ 0 0 6 7]
[ 8 9 10 11]]
'''
t[(t < 2) | (t > 6)] = 0 # 或
print(t)
'''
[[0 0 2 0]
[0 0 6 0]
[0 0 0 0]]
'''
t[~(t > 1)] = -1 # 非
print(t)
'''
[[-1 -1 2 -1]
[-1 -1 6 -1]
[-1 -1 -1 -1]]
'''
其他方法
import numpy as np
# clip方法
t = np.arange(12).reshape(3, 4)
t = t.clip(6, 10) # 小于6的元素用6更换,大于10的元素用10更换
print(t)
'''
[[ 6 6 6 6]
[ 6 6 6 7]
[ 8 9 10 10]]
'''
# 三目运算符
# 用法:np.where(condition, x, y) --> 数组中的元素满足condition时,更换为x,否则更换为y
score = np.array([[80, 88], [82, 81], [75, 81]])
score = np.where(score > 80, 100, 0)
print(score)
'''
[[ 0 100]
[100 100]
[ 0 100]]
'''
数组的添加、删除、去重
增:numpy.append()方法
- 语法格式:numpy.append(arr, values, axis=None)
- 参数说明
- arr:输入数组
- values:要向arr添加的值
- axis:默认为None,当axis无定义时,返回一维数组 ```python import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]]) print(a) ‘’’ [[1 2 3] [4 5 6] ‘’’
print(np.append(a, [7, 8, 9]))
[1 2 3 4 5 6 7 8 9]
print(np.append(a, [[7, 8, 9]], axis=0)) ‘’’ [[1 2 3] [4 5 6] [7 8 9]] ‘’’
print(np.append(a, [[5, 5, 5], [7, 8, 9]], axis=1)) ‘’’ [[1 2 3 5 5 5] [4 5 6 7 8 9]] ‘’’
<a name="wsaCV"></a>
### 增:numpy.insert()方法
- 语法格式:numpy.insert(arr, obj, values, axis=None)
- 参数说明
- arr:输入数组
- obj:在指定位置插入值的索引
- values:要插入的值
- axis:默认为None,当axis无定义时,则数组会被展开
```python
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6]])
print(a)
'''
[[1 2]
[3 4]
[5 6]]
'''
print(np.insert(a, 3, [11, 12]))
# [ 1 2 3 11 12 4 5 6]
print(np.insert(a, 1, [11, 12], axis=0))
'''
[[ 1 2]
[11 12]
[ 3 4]
[ 5 6]]
'''
print(np.insert(a, 1, [7, 8, 9], axis=1))
'''
[[1 7 2]
[3 8 4]
[5 9 6]]
'''
print(np.insert(a, 1, [7], axis=1)) # 广播机制
'''
[[1 7 2]
[3 7 4]
[5 7 6]]
'''
删:numpy.delete()方法
- 语法格式:numpy.delete(arr, obj, axis=None)
- 参数说明
- arr:输入数组
- obj:要从输入数组删除的子数组
- axis:默认为None,当axis无定义时,则数组会被展开 ```python import numpy as np
a = np.arange(12).reshape(3, 4) print(a) ‘’’ [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] ‘’’
print(np.delete(a, 5))
[ 0 1 2 3 4 6 7 8 9 10 11]
print(np.delete(a, 1, axis=1)) ‘’’ [[ 0 2 3] [ 4 6 7] [ 8 10 11]] ‘’’
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(np.delete(a, np.s[1, 3])) # [ 1 3 5 6 7 8 9 10] print(np.delete(a, np.s[::2])) # [ 2 4 6 8 10]
<a name="dYpKz"></a>
### 去重:numpy.unique()方法
- 语法格式:numpy.unique(arr, return_index, return_inverse, return_counts)
- 作用:用于去除数组中的重复元素
- 参数说明
- arr:输入数组,如果不是一维数组则会展开
- return_index:如果为true,返回新数组元素在旧数组中的下标,并以数组形式存储
- return_inverse:如果为true,返回旧数组元素在新数组中的下标,并以数组形式存储
- return_counts:如果为true,返回新数组元素在旧数组中的出现次数,并以数组形式存储
```python
import numpy as np
a = np.array([5, 2, 6, 2, 7, 5, 6, 8, 2, 9])
print(a) # [5 2 6 2 7 5 6 8 2 9]
u = np.unique(a)
print(u) # [2 5 6 7 8 9]
u, indices = np.unique(a, return_index=True)
print(u) # [2 5 6 7 8 9]
print(indices) # [1 0 2 4 7 9]
u, indices = np.unique(a, return_inverse=True)
print(indices) # [1 0 2 0 3 1 2 4 0 5]
u, indices = np.unique(a, return_counts=True)
print(indices) # [3 2 2 1 1 1]
数组的其他操作
数组的连接
- numpy.concatenate((a1, a2, …), axis=None):沿指定轴连接数组

- numpy.stack((a1, a2, …), axis=None):沿指定轴连接数组

- numpy.hstack((a1, a2, …)):沿水平方向堆叠数组
- numpy.vstack((a1, a2, …)):沿垂直方向堆叠数组

数组的分割
- numpy.split(array, indices_or_sections, axis=None)
- 作用:将一个数组按指定轴进行切分
- indices_or_sections:如果是一个整数,就用该数平均切分;如果是一个数组,就作为沿轴切分的位置

- numpy.hsplit(array, indices_or_sections):将一个数组沿水平方向进行切分

- numpy.hsplit(array, indices_or_sections):将一个数组沿水平方向进行切分

数组的翻转
- numpy.transpose(array):对数组进行转置
- array.T:对数组进行转置,不同之处在于原数组改变了
- numpy.rollaxis(array, axis=None, start=0):将数组中指定的轴滚动到指定位置 ```python import numpy as np
a = np.arange(8).reshape(2, 2, 2) print(a) ‘’’ [[[0 1] [2 3]] [[4 5] [6 7]]] ‘’’
b = np.rollaxis(a, 2, 0) print(b) ‘’’ [[[0 2] [4 6]] [[1 3] [5 7]]] ‘’’
c = np.rollaxis(a, 2, 1) print(c) ‘’’ [[[0 2] [1 3]] [[4 6] [5 7]]] ‘’’
- numpy.swapaxes(array, axis1, axis2):交换数组中的两个轴
```python
import numpy as np
a = np.arange(8).reshape(2, 2, 2)
print(a)
'''
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
'''
b = np.swapaxes(a, 0, 2)
print(b)
'''
[[[0 4]
[2 6]]
[[1 5]
[3 7]]]
'''
数组的其他函数
数学函数
- numpy.sqrt(array):平方根函数
- numpy.squre(array):平方函数
- numpy.exp(array):指数函数
- numpy.log/log10/log2(array):对数函数
- numpy.abs/fabs(array):绝对值函数
- numpy.cos/cosh/sin/sinh/tan/tanh(array):三角函数
- numpy.sign(array):计算各元素的正负号
- numpy.isnan(array):判断各元素是否为NaN
- numpy.isinf(array):判断各元素是否为Inf
- numpy.modf(array):计算各元素的整数部分和小数部分,返回两个数组
- numpy.ceil(array):将各元素向上取整
- numpy.floor(array):将各元素向下取整
- numpy.trunc(array):将各元素向0取整
- numpy.rint(array):将各元素四舍五入取整
numpy.around(array, decimals):将各元素按指定位数四舍五入
算术函数
numpy.add(array1, array2):两个数组相加
- numpy.subtract(array1, array2):两个数组相减
- numpy.multiply(array1, array2):两个数组相乘
- numpy.divide(array1, array2):两个数组相除
- numpy.mod/remainder(array1, array2):两个数组相取模
- numpy.reciprocal(array):返回逐元素的倒数
numpy.power(array1, array2):将第一个数组的元素作为底数,第二个数组的对应元素作为指数,返回幂
统计函数
numpy.amax(array, axis=None):计算数组中的元素沿指定轴的最大值
- numpy.amin(array, axis=None):计算数组中的元素沿指定轴的最小值

- numpy.ptp(array, axis=None):计算数组中的元素沿指定轴的最大值与最小值的差
- numpy.mean(array, axis=None):计算数组中的元素沿指定轴的平均值
- numpy.mean(array, weight, axis=None, returned=false)
- 作用:根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值
- 如果returned参数设为true,则还会返回权重的和

- numpy.std(array, axis=None):计算数组中的元素沿指定轴的标准差,std = sqrt(mean((x - x.mean())**2))
- numpy.var(array, axis=None):计算数组中的元素沿指定轴的方差,var = mean((x - x.mean())**2)
- numpy.argmax(array, axis=None):计算数组中的元素沿指定轴的最大元素的索引
- numpy.argmin(array, axis=None):计算数组中的元素沿指定轴的最小元素的索引
- numpy.nonzero(array):计算数组中非零元素的索引

- numpy.where(条件):计算数组汇总满足给定条件的元素的索引
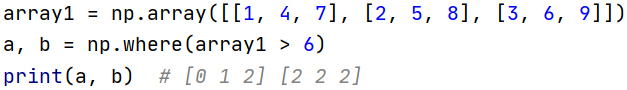
- numpy.sort(array, axis=None, kind=’quicksort’, order=None)
- sort:指明要排序的字段
- 作用:返回数组的排序副本

numpy.argsort(array, axis=None):返回数组中各元素从小到大排序的索引值
生成随机数
numpy.random.rand(d0, d1, …, dn):根据给定维度生成[0, 1)之间的随机浮点数所构成的数组
- numpy.random.randint(low, high=None, size=None, dtype):根据给定维度生成[low, high)之间的随机整数所构成的数组,可以指定数据数据类型,默认数据类型是numpy.int
- numpy.random.randn(d0, d1, …, dn):根据给定维度生成标准正态分布的随机浮点数所构成的数组
- numpy.random.normal(loc=0.0, scale=1.0, size=None):根据给定维度生成服从期望为loc、标准差为scale的正态分布的随机浮点数所构成的数组,如果不提供size,则返回一个服从该分布的随机数
- numpy.random.uniform(low, high=None, size=None):根据给定维度生成均匀分布的数组
numpy.random.seed(a):设置种子,这样每次生成的随机数都相同,其中a是个整数
nan和inf
基本介绍
inf表示无穷大的数据,对应的 - inf 就表示无穷小的数据
- nan表示缺失的数据,任何数据与其运算结果都是nan
- inf和nan都是float类型,因此创建数组时需要指定数据类型


nan的性质
- 两个nan是不相等的:np.nan == np.nan # False
- 因此可以借此和numpy.count_nonzero(array)统计数组中nan的个数
- np.isnan(array):判断数组中的元素是否是nan ```python import numpy as np
t = np.arange(12, dtype=np.float32).reshape(3, 4) t[2, 3] = np.nan
print(t != t) ‘’’ [[False False False False] [False False False False] [False False False True]] ‘’’
print(np.count_nonzero(t != t)) # 1
print(np.isnan(t)) ‘’’ [[False False False False] [False False False False] [False False False True]] ‘’’
print(np.count_nonzero(np.isnan(t))) # 1
t[np.isnan(t)] = 0 print(t) ‘’’ [[ 0. 1. 2. 3.] [ 4. 5. 6. 7.] [ 8. 9. 10. 0.]] ‘’’
<a name="wkGjx"></a>
### nan的应用
```python
import numpy as np
t = np.arange(24).reshape(4, 6).astype('float')
t[1, 3:] = np.nan
print(t)
'''
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. nan nan nan]
[12. 13. 14. 15. 16. 17.]
[18. 19. 20. 21. 22. 23.]]
'''
for i in range(t.shape[1]): # 遍历每一列
temp_col = t[:, i] # 获取该列数据
nan_count = np.count_nonzero(temp_col != temp_col) # 获取该列数据中为nan的元素个数
if nan_count:
temp_col_not_nan = temp_col[temp_col == temp_col] # 获取该列数据中不为nan的其他元素
temp_col[np.isnan(temp_col)] = np.mean(temp_col_not_nan) # 进行修改
print(t)
'''
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. 13. 14. 15.]
[12. 13. 14. 15. 16. 17.]
[18. 19. 20. 21. 22. 23.]]
'''
副本和视图
副本
- 副本是数据的完整拷贝,如果对副本进行修改,不会影响到原始数据,物理内存也不在同一位置
- ndarray.copy()会创建一个副本,Python序列的切片操作也是产生副本 ```python import numpy as np
a = np.array([1, 2]) print(a) # [1 2]
b = a.copy() print(b) # [1 2]
print(b is a) # False
b[0] = 100 print(b) # [100 2] print(a) # [1 2]
<a name="EJaPE"></a>
### 视图
- 视图是数据的一个别称或引用,通过该别称或引用便可访问、操作原始数据。如果对视图进行修改,会影响到原始数据
- ndarray.view()会返回一个视图,numpy的切片操作也是返回原始数据的视图
- 注意:视图的维数变化不会改变原始数据的维数
```python
import numpy as np
a = np.arange(4).reshape(2, 2)
print(a)
'''
[[0 1]
[2 3]]
'''
b = a.view()
print(b)
'''
[[0 1]
[2 3]]
'''
print(id(a)) # 1642898806784
print(id(b)) # 1642587437056
----------------------------------------------
b.shape = (1, 4)
print(b) # [[0 1 2 3]]
print(a)
'''
[[0 1]
[2 3]]
'''
----------------------------------------------
b[0, 1] = 100
print(b) # [[0 100 2 3]]
print(a)
'''
[[ 0 100]
[ 2 3]]
'''
从文件存取数据
numpy.loadtxt()方法
- 语法格式:loadtxt(fname, dtype=
, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, encoding=’bytes’) 参数说明
语法格式:numpy.savetxt(fname, array, fmt=’%d’, delimiter=’,’)

若有收获,就点个赞吧
0 人点赞
