开篇词
- 数据分析最重要的是给企业和业务带来价值
- 大部分都在做利用SQL取数写数据报告的工作,被动地接受需求,怎么从客户、门店、销售的维度去分析差异的数据,该怎么去做产品的规划、客户的画像、投入的预算等等,这些不是跑跑SQL、做excel就可以完成的
- 只有真正挖掘数据背后隐藏的价值,才能帮助你脱离低价值感的机械数据岗位。
- 主动寻找数据价值,数据分析能力在不断“破圈”
怎样才能学好数据分析?
一些知识开始越学越乱,明明看了很多资料,却还是很难搞懂实际业务场景。
深入行业去体会实际场景,用excel做数据分析。在业务工作中不断掌握了Python、SPSS、Hadoop和各种BI工具等技能。对数据进行清洗、加工和可视化的操作,尝试分析业务,对业务的了解浮于表面,脑海中没有具体场景。
学习业务部门的知识,包括流程梳理、业务模型、指标体系建立等,主键承接业务部门的数据项目分析需求,比如采集人力数据做销售人员绩效分析。HRDA,
按照“先基础、后实践”的原则,将课程内容分为了三个模块


进阶:《数据分析实战训练营》—拉勾教育
导读:如何从目标出发,探究数据分析的本质?
- 问题 — 业务需求层
- 获取 — 数据采集层
- 数据 — 数据层
- 分析手段 — 数据处理层
- 业务价值 — 输出层
数据分析,是针对某个问题,将获取后的数据用分析手段加以处理并发现业务价值的过程
目标思维,数据分析一定要有目标,
- 最近产品更新了一个功能,业务想让你分析以下用户对这个功能的使用情况是如何的,如果你没有目标思维,直接将业务的问题当成了分析的目的,你就会从数据库取数,最后你就会发现这些数据并不是业务想要的
- 功能的使用人数,这个需求的真正核心目的是什么?明确业务需求,分析目的,拆解目标,目的是分析这个功能的价值,考虑用什么样的目标去衡量这个价值,活跃率、留存率、新用户需求、用户类型都是可以考虑的。
- 找数据也是数据分析的基础工作之一,搞清楚数据在哪,怎么取出来
- 数据来源
- 纸质数据 : 保密性强、不好保存、不好查取、不好删改
- Excel :方便存储、容易处理、自动化差、容易谬误
- 爬虫 : 公开数据、安全性差、价值性低
- 软件系统 : 数据规则、自动化高 、流程复杂
- 数据库: 海量数据、方便存储、方便提取、不易清洗
- 获取
- SQL 结构化的查询语言,SQL是数据分析工作的基础性工作之一
- 数据
- 数据库数据: 业务数据、日志数据、系统数据、行业数据
- 数据场景:
- 点:确定指标
- 线:确定指标与业务逻辑的关系
- 面:确定业务流程或结构
- 体:构建整体数据分析训练
- 清洗后的数据:脏数据的排除、重复数据检索、无效数据去除、筛选数据指标、整合核心数据
- 分析手段
- 描述分析
- 数据分析思维:分析思维包括对比、趋势、细分等,基础思维和目标、演绎推理、归纳总结等数理思维
- 数理分析
- 挖掘分析
- 建模分析
- 数据分析的本质是什么呢
- 对比:横向对比(竞争对手)、纵向对比(自身差异)、同比对比、时空对比
- 趋势:周期趋势(周、月)、行业趋势、外部环境趋势
- 细分:指标细分(销售个数、单个成本、工作时长)、维度细分
- 发现数据中隐藏的很多信息,卖的好可能起的早或进的货更好,可能食堂饭菜不好吃,学生流量大,所以真正的意义是:找异常、找原因、找趋势
- 描述分析
- 业务价值
- 数据分析的起点是问题与目标,数据分析的终点就是业务价值,数据分析应关注业务与企业的价值点,数据分析就是为了实现业务价值,数据可视化、数据分析报告要紧紧贴合业务
- 如何将企业的盈利时间拉长?
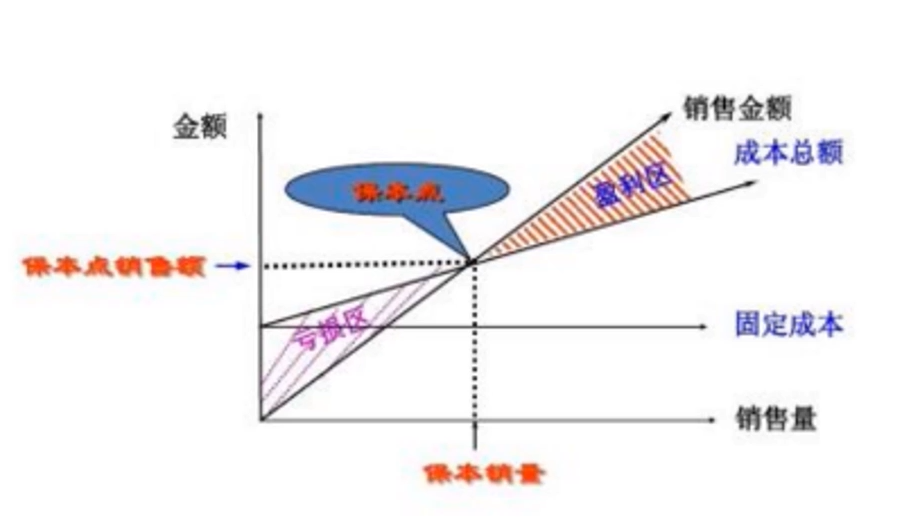
- 盈利时间拉长需要提高用户的持续粘性,优化用户体验
- 如何提高单位时间的盈利率?
- 提高企业创造价值的效率
- 如何将企业的盈利时间拉长?
- 数据分析的起点是问题与目标,数据分析的终点就是业务价值,数据分析应关注业务与企业的价值点,数据分析就是为了实现业务价值,数据可视化、数据分析报告要紧紧贴合业务
- 数据来源
- 总结:
集中趋势
- 众数
- 平均数
- 分位数
- 离散趋势
- 极值与极差
- 平均差
- 方差
- 标准差
- 分位差
- 分布
- 峰态
- 偏度
数据分析干嘛要学统计学呢?
案例分析:
二战德国的面粉由政府管理,政府每天发放固定的面粉量由指定的工厂进行面包的制作,然后将面包发放到市民手中。 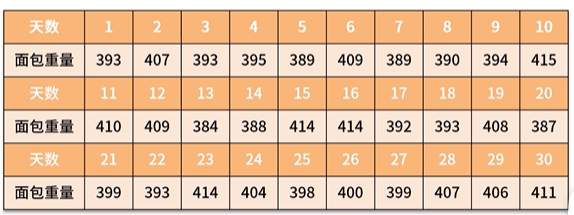
统计学是数据分析的理论基础之一,平均数、众数、中数、四位数等都是统计学中描述型统计的知识。
描述性统计:定量去描述某些数据的特点,如今年的销售额比去年提高了50%
在进行数据分析时,可量化的指标要量化,不可量化的要定义指标或者公式进行量化,从数据中找结果,而不是感觉中找差异,避免主观化、抛开经验和惯性思维
三个分类
- 集中趋势:反映一些数据向某一中心靠拢的程度,常用的指标主要由 — 众数、平均数和分位数
- 众数:数据集合中出现频次最多的数据,数据的趋势越集中,众数的代表性越好,但缺乏唯一性。
- 平均数:平均数代表某个数据集的整体水平,缺点:很容易受极值的影响
- 分位数: 分位数是将某个事件的发生概率按照等分的原则分成几个等值的点
- 包括中位数(即二分位数)、四分位数、百分位数
- 四分位数:将数据等分为四部分,把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值,分割后通过5个数值来描述数据的整体分布情况
- 优点:对不不同类别数据的整体情况、识别出可能的异常值;缺点:无法反映数据的波动大小
- 下界:最小值;下四分位数Q1;中位数Q2;上四分位数Q3;上界:最大值;
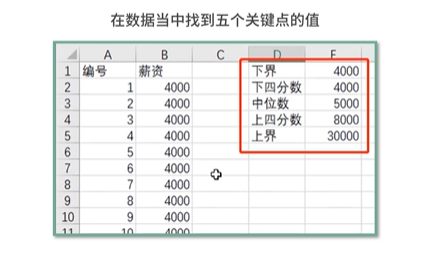
- EXCEL实践练习
- 箱型图是四分位数的专用可视化图形工具,能显示出一组数据的最大值、最小值、中位数、上下四分位数
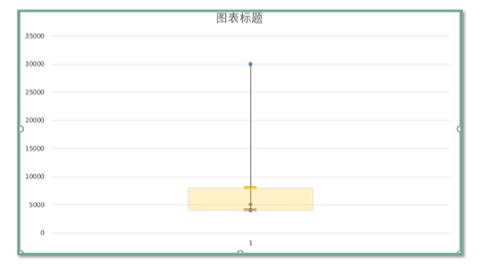
- 离散趋势:反映了各变量原理其中心值的程度
- 常用的指标有极值、方差、标准差、平均差、分位差等
- 极值:最大值、最小值
- 极差:最大观察值与最小观测值之差
- 平均差:计算出每个值与平均值的差值,最后计算所有差值的平均值。 表示每个数值偏离平均值的程度
- 方差: 每个值与平均值的差 平方,然后除以总数据量的值,方差与数据离散程度正相关。
- 标准差:将方差进行平方根,表示数据与期望值的偏离程度
- 分位差:其数值越小表明数据越集中,数值越大表明数据越离散,四分位差 = (第三个四分位数-第一个四分位数)/2
- EXCEL 描述分析库
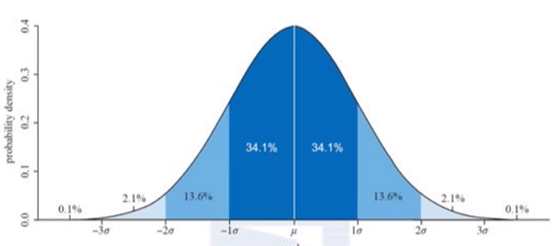
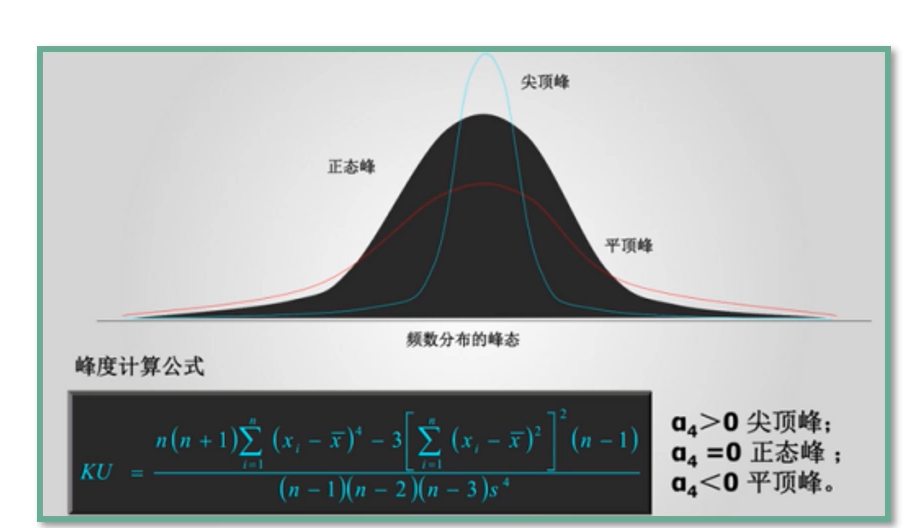
- 分布 — 峰态
- 峰态 — 反映了峰部的尖部,用来评估一组数据的分布形状的高低程度的指标
- 当峰值==0时,分布和正态分布基本一致
- 当峰值>0时,分布形态高狭
- 当峰值<0时,分布形态低阔
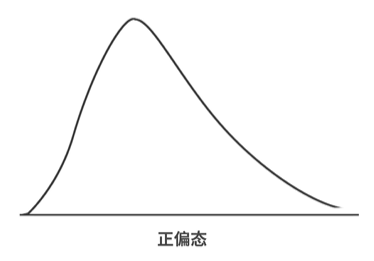
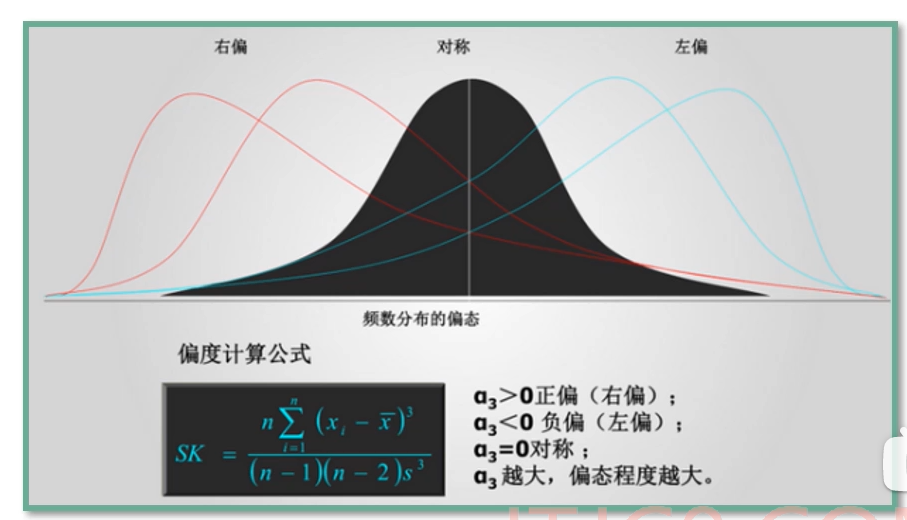
- 偏度 — 峰值与平均值的偏离程度,一般用SK表示
- SK<0,左偏,也叫负偏
- SK>0, 右偏,也叫正偏
- 通过分布,可以预测某个事件有没有可能发生
- 峰态 — 反映了峰部的尖部,用来评估一组数据的分布形状的高低程度的指标

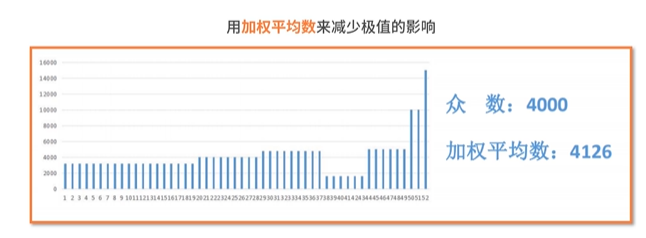
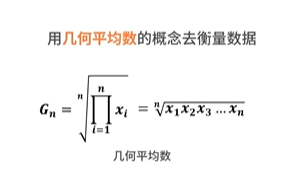

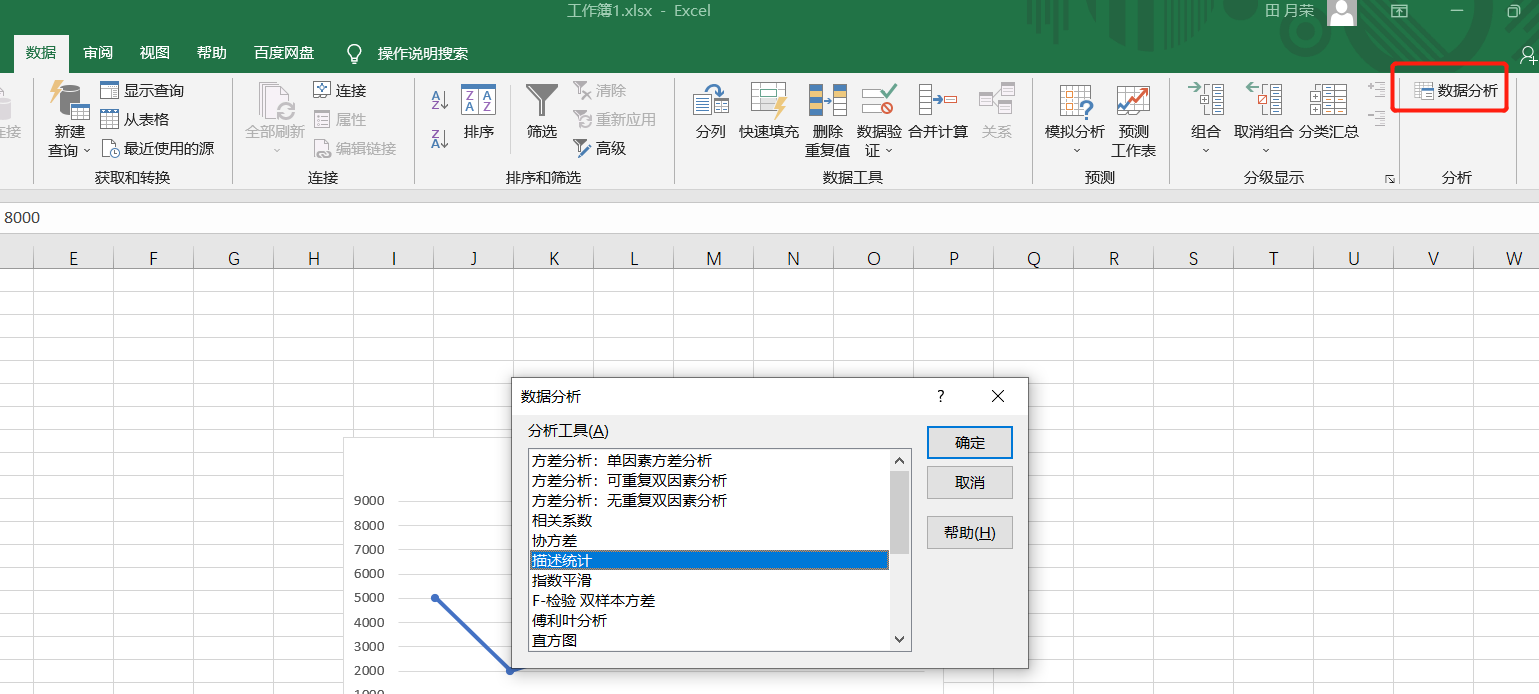
总结:讲解了统计学基础中描述性统计的内容,包括集中趋势离散趋势和分布的具体含义与指标形式
思考:数据量较小或者分组数相近的时候,中位数往往比众数更有说服力,思考为什么?
02 未来事件如何用数据进行预测
本讲通过概率分布和假设检验的讲解,配合案例,用数据预测未来事件
推理统计
- 概率分布
- 离散型概率分布
- 二项分布
- 几何分布
- 泊松分布
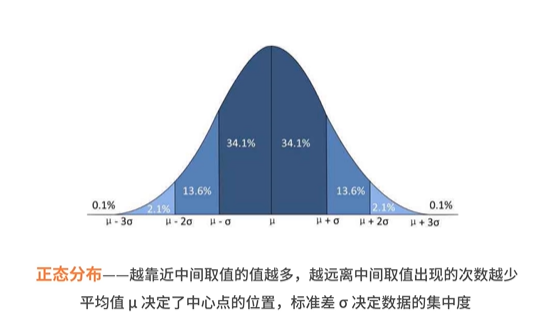
- 连续型概率分布:正态分布
- 离散型概率分布
- 假设检验
- 定义
- 流程
推理性统计:通过样本数据去推理总体数据特性的方法,用部分数据特征去推理整体数据特征,类似归纳推理
概率分布
- 离散型分布:每一次随机事件发生都是独立的、不连续的、不受其他事件影响的
- 二项分布、几何分布、泊松分布
- 二项分布:发生次数固定、求成功次数概率的事件,但要保证这些事情的结果只有两种结果,非A即B
- 抛硬币
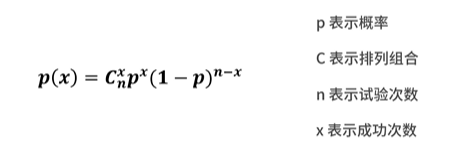

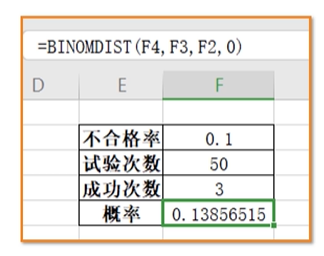
- 几何分布 — 求试验几次才能获得第一次成功的概率
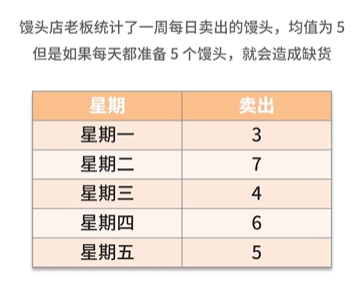
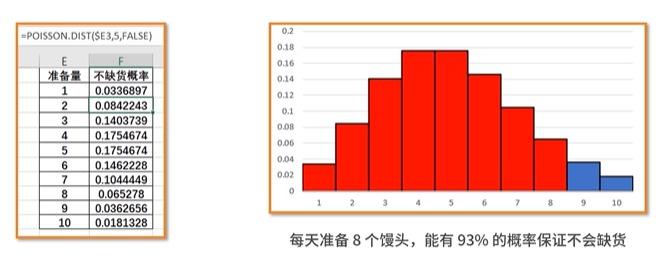
- 泊松分布 — 在一定的时间内,某个事件发生N次的概率分布

连续型概率:数据之间是有联系、呈现一定规律,而且事件之间不独立的概率
如果统计以下某个班级的学术身高情况,你需要将每个人的身高统计下来,这就是描述性统计,即“研究表面”
- 如果预测一下明天是否会下雨,你可能需要统计最近几天的天气情况,然后计算出明天下雨的概率,这就是推理性统计,即“推测本质”
- 思考:推理性统计和描述性统计两种方法哪个更有说服力呢?
03 资源投入怎么分配更合理
回归模型
主要解决 — 原因诊断问题,属于研究某个或者某些元婴能够对目标造成多大程度影响的一种算法。
例,影响在线销售额的因素




什么是相关性分析?
在确定衡量某个变量时一定要遵循“先定性、再定量”的原则,要先做相关性分析,再做回归分析。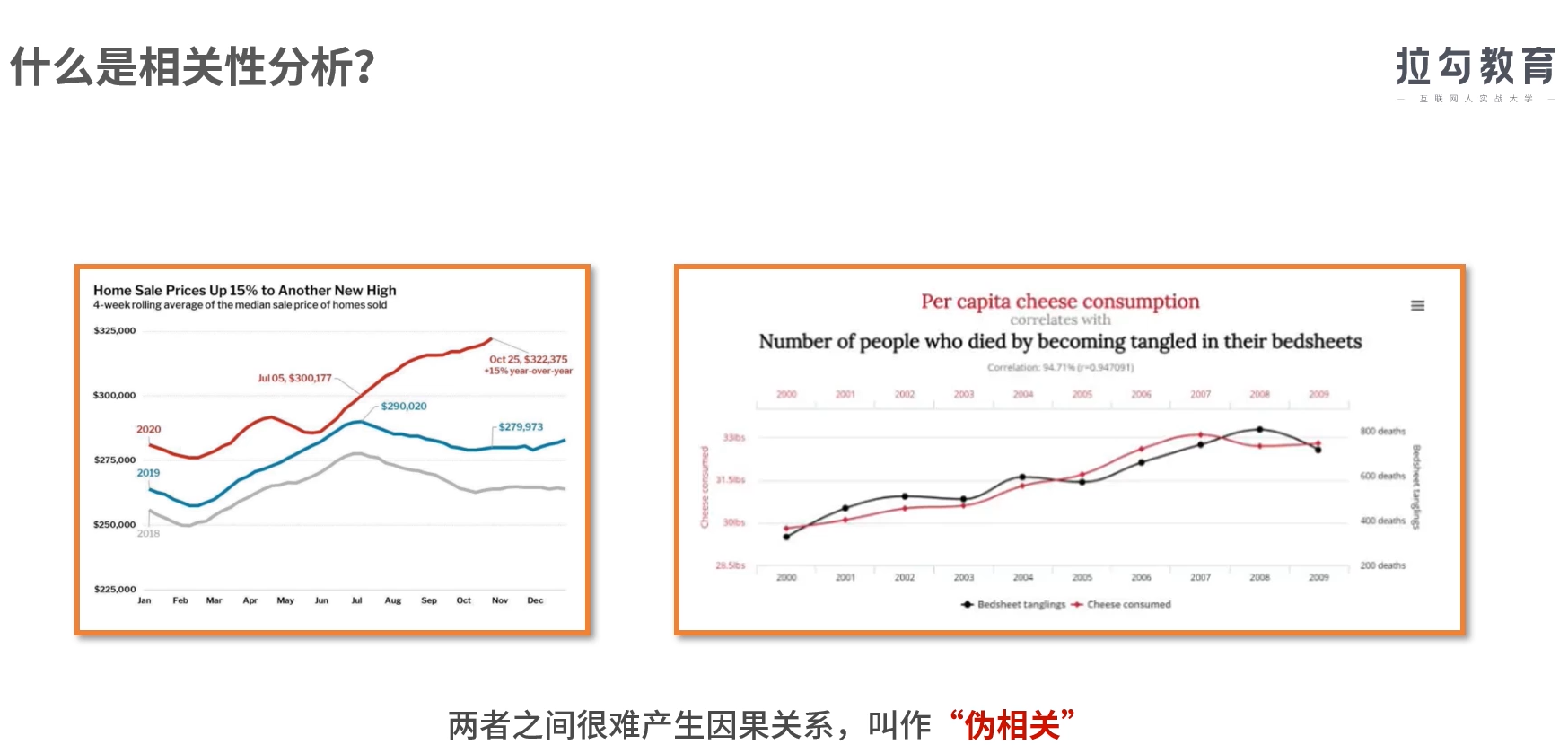
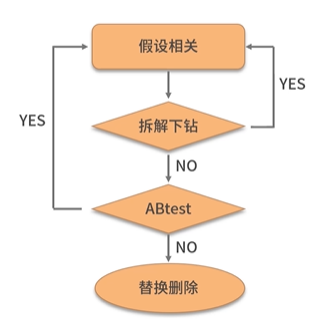 ABTest:控制单一变量实验
ABTest:控制单一变量实验
拆分方法之金字塔原理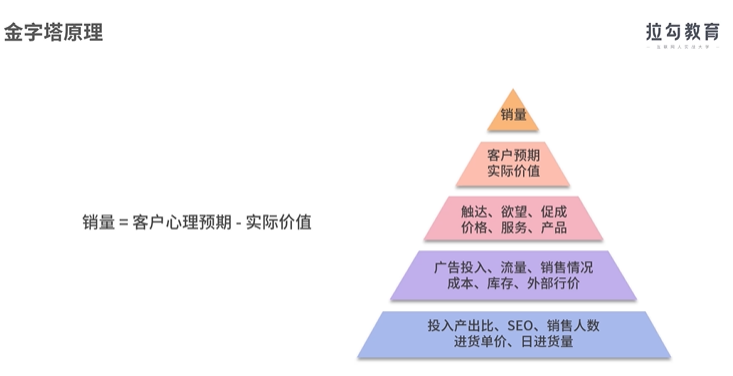

回归模型建立的过程

目的:找到销量与其他因素之间的因果关系并尝试进行定量表示
- 注意:想要得到变量和变量之间的因果关系,用相关性去替代因果性
确定变量:Y代表销量,X代表着客单量、库存、广告投入等能够影响核心业务指标 — 销量的因素
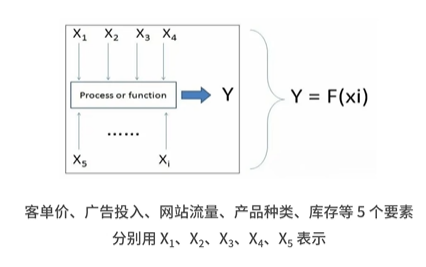
建立回归模型
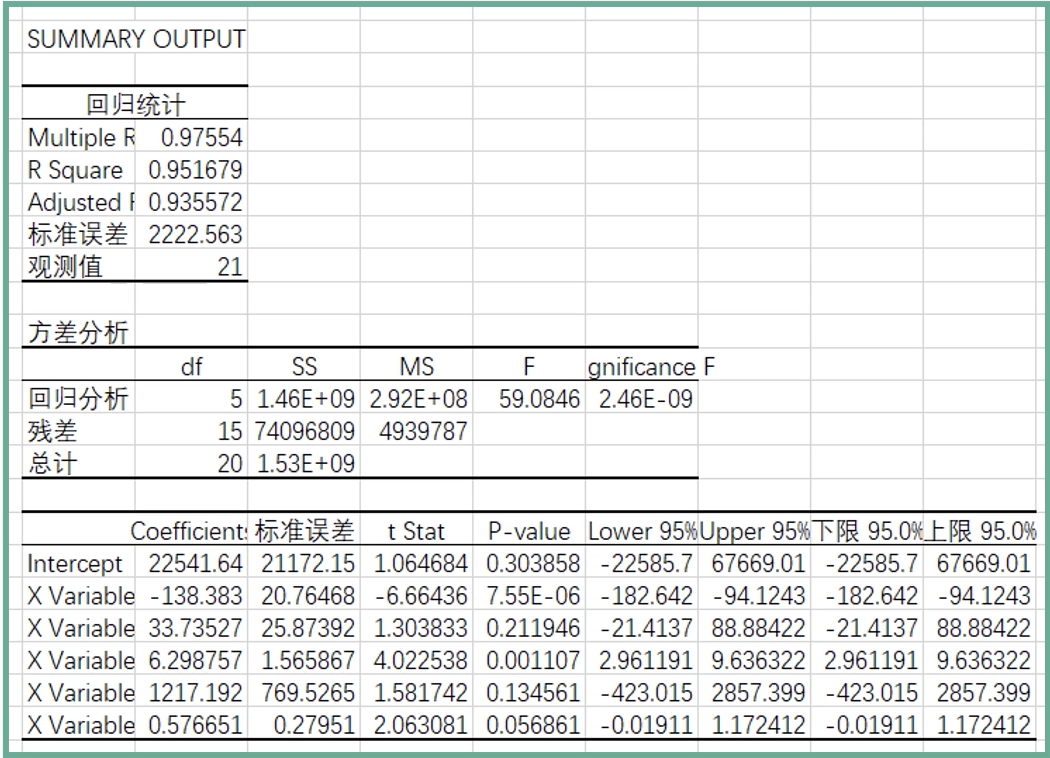
回归方程的检验
- Mutiple R:表明自变量和因变量之间相关性大小的值,呈正相关,>=0.8即代表较强的相关性
- R Square: R的平方值是指拟合系数,是自变量解释因变量差距的大小,数据越大则代表回归拟合得越好
- Adjusted R Square: 代表自变量解释因变量差距得百分比,一元回归的看R Square项多,多元回归看 Adjusted R Square项多
- 标准误差: 衡量拟合程度的大小,也用于计算与回归相关的其他统计量,值越小,说明拟合程度越好。
- 观察值:用于训练回归方程的样本数据有多少个
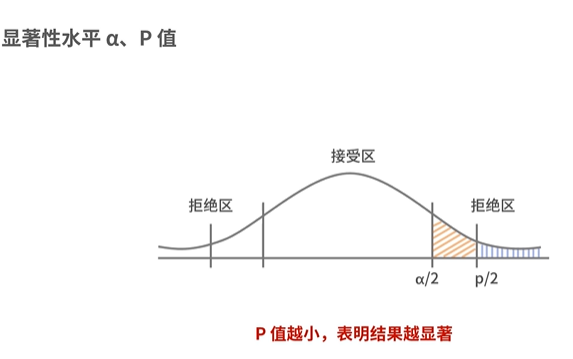
- Significance F: 指显著性检验度,值越小代表因变量和自变量之间的关联性越显著
- Coefficient: 回归系数,表示某个因子对最终值得影响系数,注意:这个值仅表示数值系数。
- T Stat: 回归系数与其标准误差得比值,表示因子的显著性,T的绝对值越大,影响因子也就越大,一般大于2说明影响显著
- P-value:指系数的显著性检验度,一般小于0.05说明具有统计学意义
综上可以看出,对销量影响最大的因素是X1,也就是客单价
回归模型的思想本质:研究变量的相关性,需要先定性,再定量
- 定性分析的核心在于利用假设检验,避免伪相关
定量分析的核心在于回归方程的检验,拟合判断的各种指标是快速掌握和利用回归模型的关键。
上节思考:推理性统计和描述性统计两种方法哪个更有说服力呢?
- 推理性统计更具有说服力的,推理性统计通过逻辑和概率对整体性数据做出推断,如假设检验。
本节思考:
- T参数存在的意义是什么?
- 线性回归里的相关性需不需要参考coefficient呢?
- coefficient会不会和变量的值有关?
- P值不具有统计学意义的含义是什么?
04 最好用的产品、商品、用户的分类方法你知道吗?
03讲主要学习了数据分析模型基础中的回归模型和相关性模型,为了解决原因分析类问题
本讲 介绍的聚类分析模型主要解决的是产品、用户的分类问题
什么是聚类


聚类 — 在不知道数据特征的前提下,对所有数据的内在特征进行推理
聚类的本质 — 近朱者赤近墨者黑
聚类:不断推测数据之间的联系规则,从而将数据进行族类划分。常被用到数据分析、数据挖掘、大数据计算等领域。
聚类算法之一: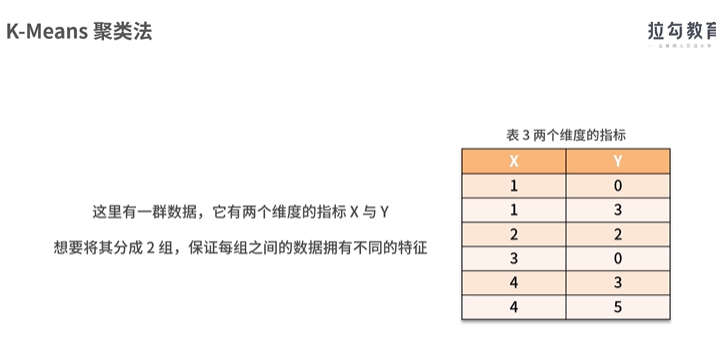
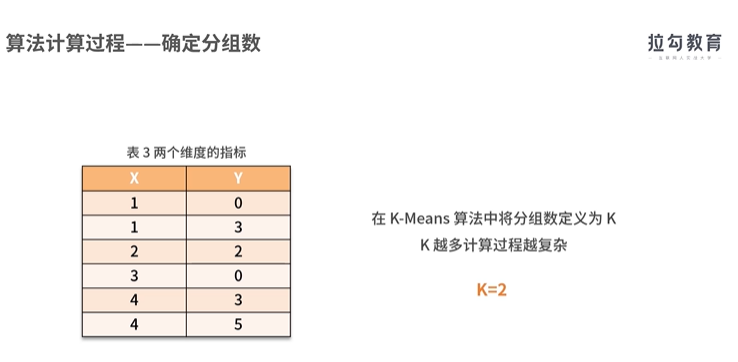
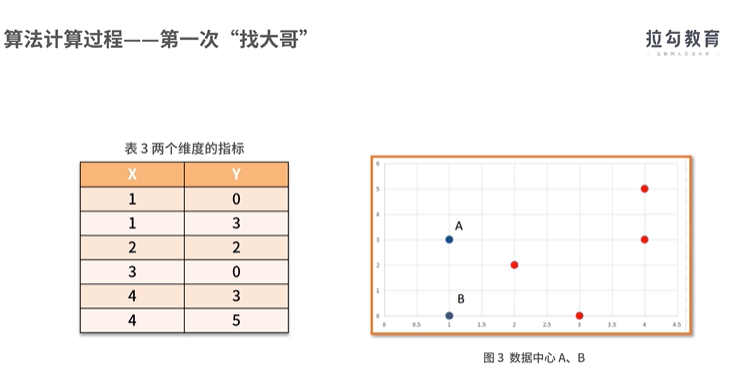
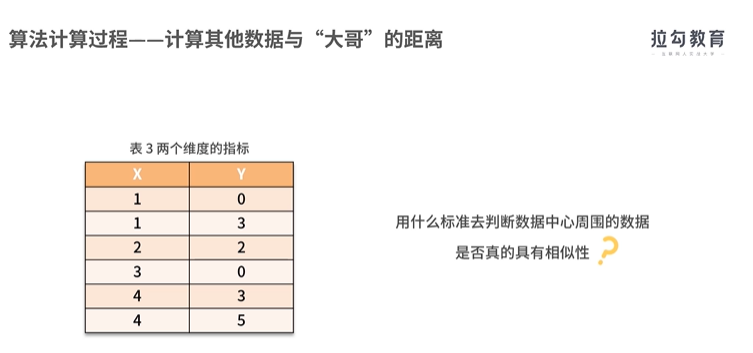
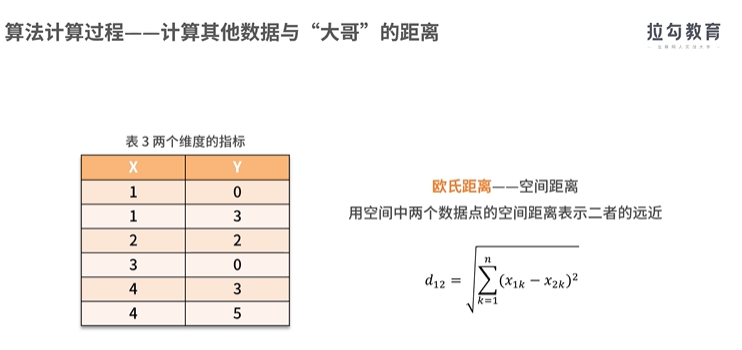
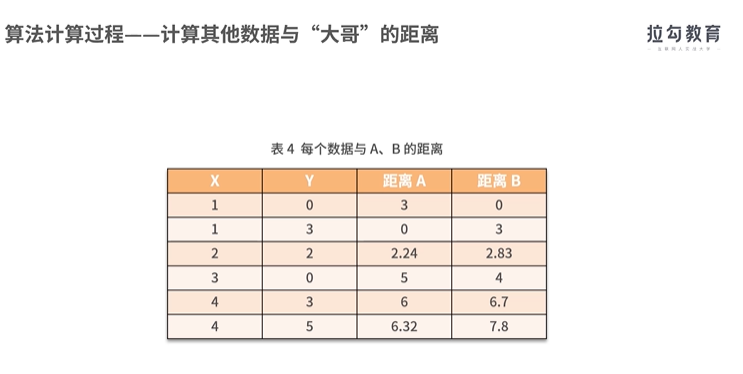
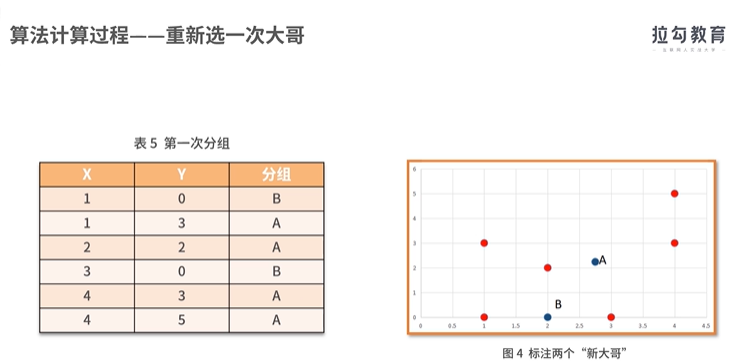
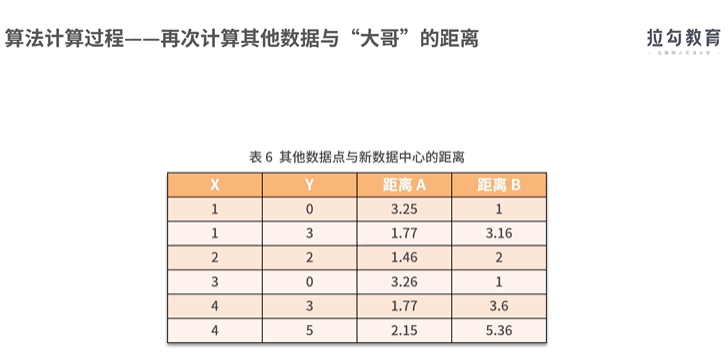
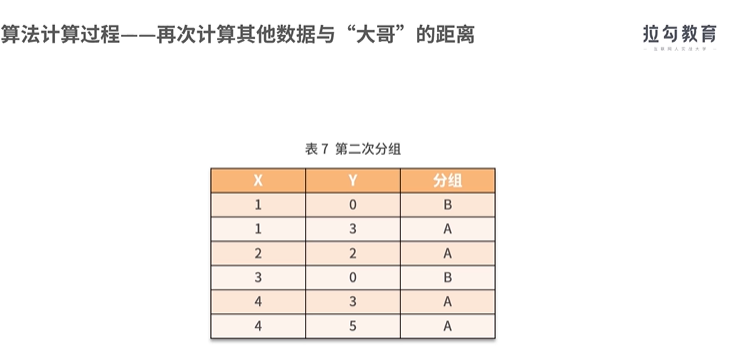

实现聚类操作的软件SPSS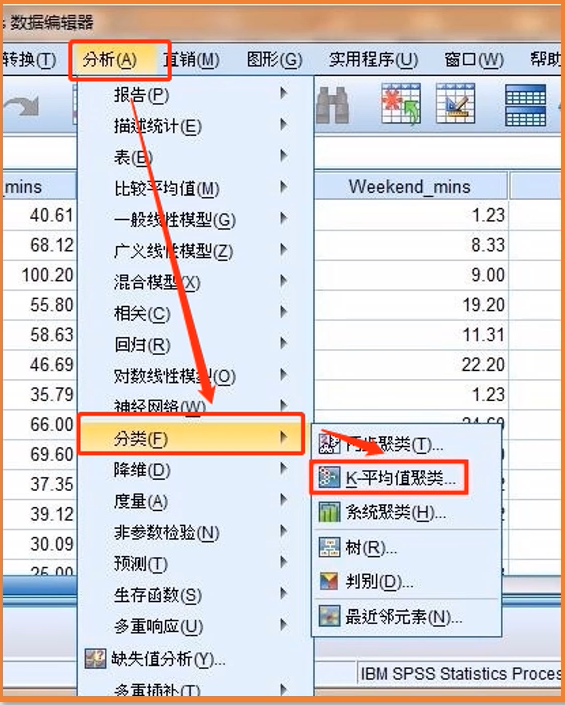
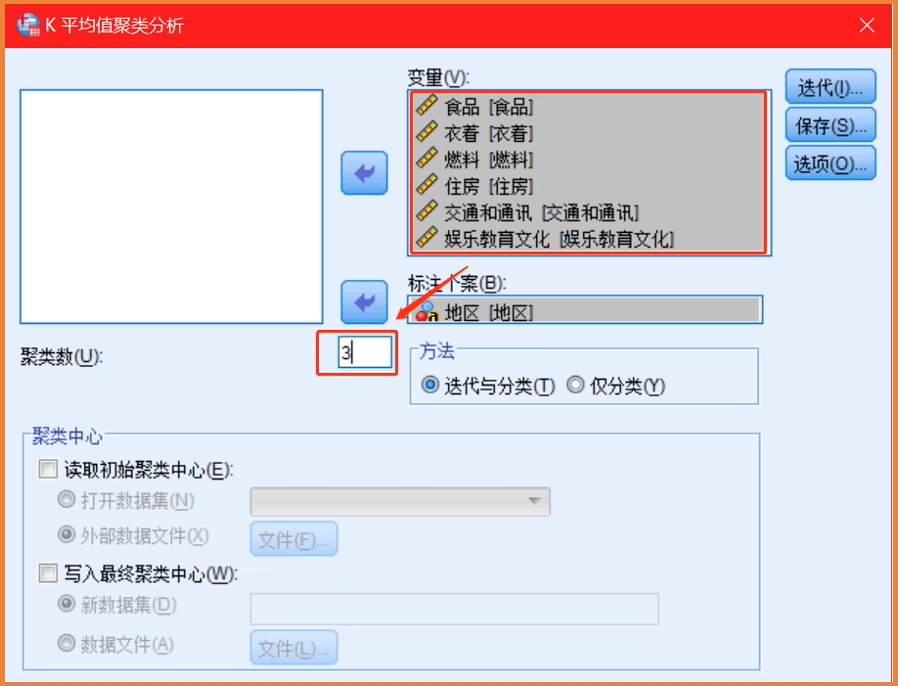

上节思考:
T参数存在的意义 — 表示因子的显著性比较因变量与自变量之间变化的差异程度
- 相关性要看T参数,T检验是体现对最终值变化程度大小的影响程度
- P值不具有统计学的含义,以偶然性造成最终值变化的概率很小
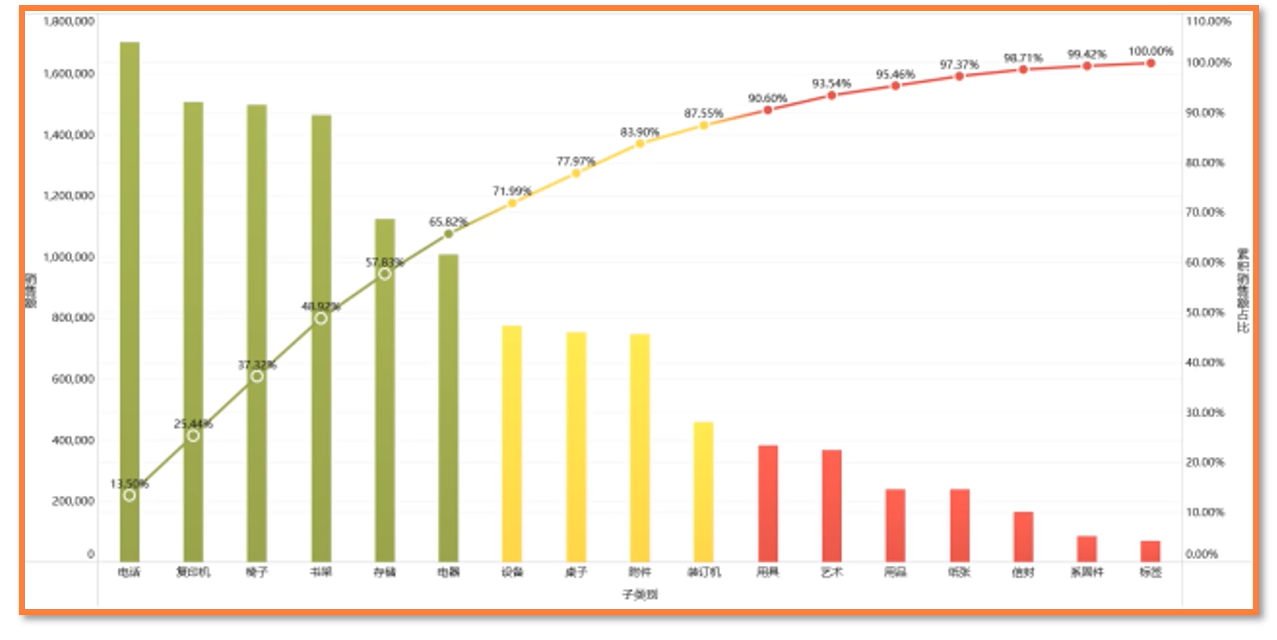
05 帕累托模型:如何用20%的成本产生80%的利润?
如果从实际业务出发,有没有一些实用的数据分析模型呢?
业务分析模型的建立
业务分析的对象:
- 商品/服务/产品
- 用户/客户
- 渠道/市场
分析模型:基于指标、维度与分析方法(思维)三者的关联组合
三要素关系图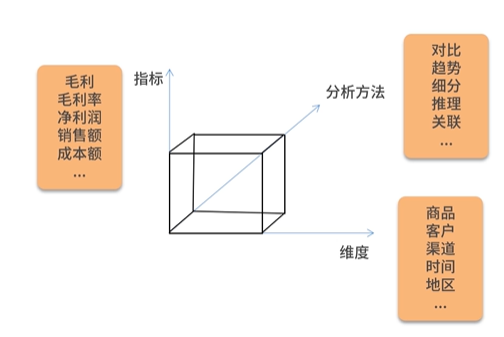
电商商品分析,怎么去分析产品或者商品、建立分析模型呢?
- 首先要确定要分析的维度有哪些?
- 比如销售维度、用户、地区、时间等维度
- 然后确定指标,不同维度的指标是不同的
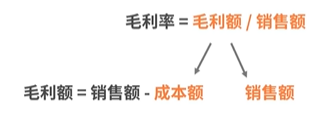
- 销售维度有销售额、毛利、净利、毛利率、周转率、促销次数、交易次数、客单价
- 地区维度里的指标有门店类别、门店课流量、门店销量等
- 最后确定分析方法是什么?


什么是帕累托模型呢?
没有什么模型是放之四海而皆准的,只有最适合的才是最好的
- 二八法则:在任何群体当中,较少的重要因子带来了绝大多数的影响,较多的不重要因子带来了很小的影响。
- 帕累托模型就是以二八法则为基础构建出来的商品分析模型

- https://www.bilibili.com/video/BV14F411p764?p=7&spm_id_from=pageDriver
06
07
08
09
10
11
12
13
结束语

若有收获,就点个赞吧
0 人点赞
