前言
LinkedList位于java.util包,于JDK1.2引入,相比于ArrayList数组实现,LinkedList使用链表实现,便于数据的高效插入和删除。其类图关系如下所示: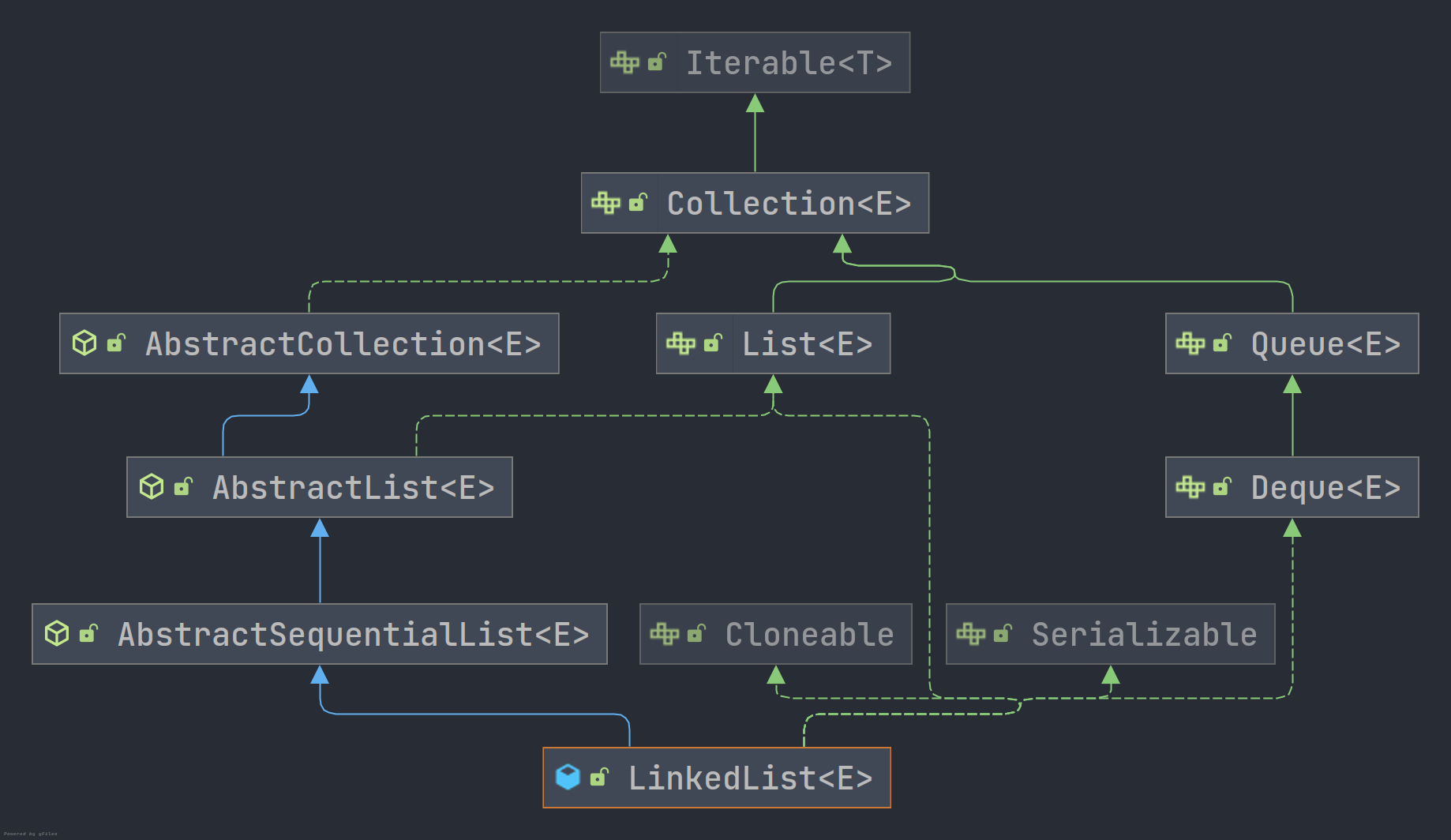
LinkedList是线程不安全的,如果需要线程安全,可以使用Collections.synchronizedList(new LinkedList())包装,也可以存储null元素。
实现原理
下面从LinkedList的数据结构和源码两个方面分析实现原理。
数据结构
如下图所示,LinkedList的数据结构使用的是双向链表,并且在每一个实例对象中记录了首尾指针的引用和结点的长度。
源码
下面对LinkedList源码常用API进行简单分析,加深其数据结构的实现理解,查看构造方法,LinkedList由于使用链表的实现结构,并没有进行初始化,当添加元素时直接在尾部追加,或者在指定index处插入元素,理论上链表的长度是无界的。
// 无参构造方法public LinkedList() {}// 有参方法,先调用无参方法,然后执行addAll添加元素public LinkedList(Collection<? extends E> c) {this();addAll(c);}
add
查看add方法,在LinkedList中,默认追加到链表尾部,主要实现在linkLast方法中
public boolean add(E e) {// 默认添加元素到队列尾部linkLast(e);return true;}
除了默认追加尾部外,还包含追加在指定索引位置后,查看你add(int index, E element)方法
public void add(int index, E element) {// 首先校验index位置,如果index超出界限会抛出越界异常checkPositionIndex(index);// 如果index == size,调用默认追加时的linkLast方法if (index == size)linkLast(element);else// 其他情况,通过linkBefore方法追加// 这里使用node方法去提取元素,LinkedList中关于set,get等操作也要多次使用该方法// 后面对node方法进行具体分析linkBefore(element, node(index));}
下面对add方法中的两种实现,linkLast、linkBefore进行源码分析
void linkLast(E e) {// 声明变量l指向链表的尾部,final意味着l的引用指向不可变// 此处如果不使用final修饰,l的指向会变化,后续操作会引起链表的混乱final Node<E> l = last;// 调用Node构造方法:Node(Node<E> prev, E element, Node<E> next)// 新添加元素的prev指向原来的last,元素存储在element,最后一个元素next指向为nullfinal Node<E> newNode = new Node<>(l, e, null);// LinkedList实例中last指向当前最新的引用last = newNode;if (l == null)// 如果LinkedList中不包含元素,那么其first、last将指向同一个结点first = newNode;else// 如果链表中l不为null,则其next引用指向最新添加的元素l.next = newNode;// 添加成功后,执行size++size++;// 记录LinkedList被修改的次数,使用迭代器时避免并发修改异常modCount++;}// linkBefor与linkLast处理思路一致,只不过其指向是逆向操作的// 其入参的succ通过node方法获取void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;}
在LinkedList中向指定位置添加元素时,使用linkBefore时会先调用node方法去提取对应index位置处的元素,接下来对node方法的实现进行分析
Node<E> node(int index) {// assert isElementIndex(index);// node方法在使用index进行遍历时的效率是相对比较低的,这里采用了二分查找的方式// 首先将链表的size >> 1也就是size / 2// 然后判断index是处于中间的左半部分,还是右半部分if (index < (size >> 1)) {// 由于LinkedList使用了双向链表,当index位于左半部分时,从头部开始查找Node<E> x = first;for (int i = 0; i < index; i++)// 这里巧妙的使用了链表的指向特性,从 0 -> index 为止,通过后驱指针通过循环遍历x = x.next;return x;} else {// 当index位于右半部分时,从尾部开始查找Node<E> x = last;// 同理使用双向链表特性,从 size-1 -> index 由尾部开始,使用前驱指针遍历for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
set
set方法可以设置指定位置(index)的元素值(element),查看set方法的源码
public E set(int index, E element) {// 首先校验index是否越界checkElementIndex(index);// 通过node方法查找到index位置对应的元素Node<E> x = node(index);// 获取原来链表中index位置处的元素值E oldVal = x.item;// 设置新的值到index处的结点中x.item = element;// 返回旧值return oldVal;}
remove
remove操作,包含了指定位置(index),默认的remove以及首尾的remove(可以看作指定位置的特殊场景),因此这里只对移除指定位置的remove(int index)方法进行分析,由于在LinkeList中记录了first和last的引用,因此移除首尾是一个比较快速的操作。
查看remove(int index)源码
public E remove(int index) {// 首先校验index是否越界checkElementIndex(index);// 通过node方法获取指定index的结点,remove的操作主要在unlink方法中return unlink(node(index));}
查看unlink方法的源码
// unlink移除不为null的结点,并且返回原来的值// 这里的入参x通过node(index)方法返回。E unlink(Node<E> x) {// assert x != null;// 定义final引用element指向x.item,用作返回,移除元素final E element = x.item;// 定义final引用next指向x的后驱结点,此处final作用同前final Node<E> next = x.next;// 定义final引用prev指向x的前驱结点final Node<E> prev = x.prev;// 如果prev指向为null,说明原来的x为链表的首结点,此时被移除后// 由first将指向x的next,也就是后一个结点if (prev == null) {first = next;} else {// 如果prev不为null,即不是首部结点// 那么将前一个结点的后驱引用指向当前结点的后驱引用// 并设置当前结点的前驱指向为nullprev.next = next;x.prev = null;}// 如果当前结点的后驱结点为null,说明当前结点为链表的尾结点// 那LinkedList中的last需要指向当前结点的前一个结点if (next == null) {last = prev;} else {// 如果next不为null,即不是尾部结点// 那么将下一个结点的前驱引用指向当前结点的前驱引用// 并设置当前结点的后驱指向为nullnext.prev = prev;x.next = null;}// 此时,当前结点x,即要移除结点的prev和next均指向null,而x的前一个结点和后一个结点// 已完成双向驱动,x从链表中移除,等待垃圾回收x.item = null; // x.item指向null,help GC// 链表size-1size--;// LinkedList的修改次数+1modCount++;// 返回移除结点中存储的元素值return element;}
在源码中根据不同场景,分别设置了x.next = null;x.item = null;x.prev = null;这也算是一些细节上的优化,根据垃圾回收算法的根可达分析,设置为null可以有助于垃圾回收。这一点在unlinkLast方法中有着更清晰的体现
private E unlinkLast(Node<E> l) {// assert l == last && l != null;final E element = l.item;final Node<E> prev = l.prev;l.item = null;l.prev = null; // help GC 此处的Help GClast = prev;if (prev == null)first = null;elseprev.next = null;size--;modCount++;return element;}
JDK源码中并不会每一处代码都进行注释,如果添加注释说明是比较重要的点,需要多注意一些注释,可以更好的帮助阅读源码。
总结
LinkedList的底层实现基于双向链表,可以高效的实现数据插入和移除,但是数据查询的效率则比较低,在实际情况中需要根据具体的场景选择使用LinkedList还是ArrayList。
LinkedList中巧妙的使用了双向链表的特性进行操作,阅读源码可以加深对数据结构的理解,也可以借鉴作者的思路。

若有收获,就点个赞吧
0 人点赞
