前言
世界上并没有完美的程序,因为写程序本来就是一个不断追求完美的过程。同样没有一门语言在一诞生就是完美的,不变的唯有变化。Java诞生至今已经不仅仅是一门语言,背后所涵盖的是一个庞大的技术体系。
网上每隔一段时间就能见到几条“未来X语言将会取代Java”的新闻,此处“X”可以用Kotlin、Golang、Dart、JavaScript、Python等各种编程语言来代入。这大概就是长期占据编程语言榜单第一位的烦恼,天下第一总避免不了挑战者相伴。
在过去二十年Java的发展是孤独求败的,在未来,Java也在迎接着各种挑战,这种挑战来自云原生、容器化、也来自其他设计更完善的语言,相信身怀各种绝技的Java会焕发出更加夺目的光彩,重新攀登另一个高峰。
接下来的内容主要围绕Java、JavaWeb技术栈的发展之路。
Java发展史
Java是在1991年由SUN公司的James Gosling(Java之父)及其团队所研发的一种编程语言,第一个版本耗时18个月,最开始命名为Oak(一种橡树)。Java现在广泛应用于各种大型互联网应用,其设计的最初动机主要是平台独立(即体系结构中立)语言的需要,可以嵌入到各种消费类电子设备(家用电器等),但市场反应不佳。
随着1990年代互联网的发展,SUN公司看到了Oak在互联网上的应用场景,在1995年更名为Java(印度尼西亚爪哇岛的英文名称,因盛产咖啡而闻名),随着互联网的崛起,Java逐渐称为重要的Web应用开发语言。Java的发展可以主要看JavaWeb的发展,Java也见证了互联网的发展过程。
发展至今,Java不仅是一门编程语言,还是一个由一系列计算机软件和规范组成的技术体系,Java 是几乎所有类型的网络应用程序的基础,也是开发和提供嵌入式和移动应用程序、游戏、基于 Web 的内容和企业软件的全球标准。
从笔记本电脑到数据中心,从游戏控制台到科学超级计算机,从手机到互联网,Java 无处不在!
- 97% 的企业桌面运行 Java
- 美国有 89% 的桌面(或计算机)运行 Java
- 全球有 900 万 Java 开发人员
- 开发人员的头号选择
- 排名第一的部署平台
- 有 30 亿部移动电话运行 Java
- 100% 的蓝光盘播放器附带了 Java
- 有 50 亿张 Java 卡在使用
- 1.25 亿台 TV 设备运行 Java
- 前 5 个原始设备制造商均提供了 Java ME
数据来源:https://www.java.com/zh_CN/about/
说到Java自然离不开JDK、JVM、JRE,三者有什么关系。
- JDK(Java Development Kit)Java开发工具包,包含Java语言、Java虚拟机、Java类库,是支持Java程序开发的最小环境。
- JVM(Java Virtual Machine)Java虚拟机,运行于各种操作系统Linux,Windows,Solaris等之上,执行编译好的Java字节码class文件。
- JRE(Java Runtime Environment)Java运行时环境,包含JavaSE中核心类库API和Java虚拟机,简单理解为JVM+核心类库API。
接下来主要围绕JDK的发展,和JVM中常见的GC收集器及算法描述。
JDK发展史

文本及PDF附件:Java发展史-文本描述.md历史故事活动时间轴.pdf
更多JEP:JEPs
更多JDK版本变更信息:JDK Release Notes
JVM家族
- JDK 1.0,1996年引入Sun Classic VM,虚拟机鼻祖,世界上第一款商用Java虚拟机。
- JDK 1.2,Solaris平台发布Exact VM,已经初具现代高性能虚拟机雏形,出现热点探测、即时编译等。但是生命周期短暂,这一时期并存Sun Classic VM、Exact VM、HotSpot VM,可通过命令切换。
- JDK 1.3,HotSpot VM成为默认选择,Exact VM依然为备用选择。
- JDK 1.4,Classic VM才完全退出商用虚拟机的历史舞台,与Exact VM一起进入了Sun Labs Research VM之中。HotSpot继承了Sun公司两款虚拟机的优点,自此之后HotSpot VM也一直成为OracleJDK和OpenJDK中默认的虚拟机。得益于Sun和Oracle两大巨头在不同时期的影响力,HotSpot也成为了使用最为广泛的虚拟机。
- Mobile/Embedded VM,这是一款面向JavaME产品线的虚拟机。主打移动端和嵌入式设备市场。只留下了客户端编译器(C1),去掉了服务端编译器(C2);只保留Serial/Serial Old垃圾收集器,去掉了其他收集器等,是一款小家碧玉型产品。
- BEA JRockit,号称最快的虚拟机,天下武功唯快不破,当然也有可能每一家都这么宣传,后来BEA公司也被Oracle收购,由于其设计架构与HotSpot大相径庭,因此只有少部分监控相关的优势被吸纳进去,天下武功,九九归一。
- IBM J9,内部名称曾定义为IT4J(IBM Technology for Java Virtual Machine),太长的名字,因此也看出名字的重要性,至今仍然活跃,与之对应的是可以更好的兼容在IBM的小型机运行平台,模块化也是其显著的优势和特点,因此可以按需启用,消耗较小的资源,提供更大的优势。
- BEA LiquidVM/Azul VM 相比于大名鼎鼎的HotSpot、JRockit、J9等通用型的多平台兼容的JVM,还有一种与特定平台,硬件绑定的专有化虚拟机,BEA的Liquid VM不需要依托于其他操作系统,本身就已经系统化,直接运行在自家Hypervisor系统上。Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于自家专有硬件Vega上的虚拟机,可以管理大量的CPU和内存,使用的是有名的PGC和C4收集器。随着业务线的调整,2010年,Azul转型软件业务,把全部精力投入到Zing(以软件的方式达到接近Vega系统的虚拟机)的研发中,而HotSpot在JDK 11和JDK 12中的ZGC和Shenandoah也才达到同等目标,JVM的发展竞争也渐激烈。
除了上面提到的使用广泛或者名气比较大的商用虚拟机外,也存在一些对整个Java虚拟机产生深渊影响的产品。
- Apache Harmony,Harmony中的DRLVM,这是一个兼容JDK 5和JDK 6的平台,可以运行Eclipse、Tomcat、Maven等程序,一直没有获取TCK授权,在Oracle收购Sun之后,Apache一度退出JCP组织,这也是Java社区历史上最为割裂的一件事。直到OpenJDK的诞生,Harmony的优势被极大的抵消,项目的最大参与者IBM也宣布退出,虽然Harmony从诞生起就没有大规模商用,但是Harmony的代码被吸收进IBM的JDK 7和Google Android SDK,这也对Android的发展产生了深远影响,似乎某种程度圆了Java诞生之初Sun就设定的路线,主打移动端的嵌入式设备路线。
- Microsoft JVM,可曾想到微软当初也设计过自己的Java虚拟机,但被Sun以侵权告退,并且终止了Java虚拟机的研发,也许正因如此才诞生了.NET平台,能让你强大的永远是你的对手,微软也在一次证明了自己的强大。
Java虚拟机的发展也进入到一种百花齐放,百家争鸣的局面,除了大规模的服务器级别的虚拟机外,也存在一些小型的虚拟机平台。
- KVM,Android、IOS等智能手机操作系统出现前广泛使用的手机平台。
- JCVM,Java虚拟机的一个子集,如智能卡,SIM卡,信用卡等,通常用作加密模块。
- Squawk VM,由Sun开发曾用于Java Card的嵌入式虚拟机实现。
- JavaInJava,Sun公司开发的一个实验性质的虚拟机,通过元循环证明一门语言可以自举,通过Java来实现Java语言的运行环境,没有编译器,通过解释模式来运行。
- Maxine VM,一个类似于JavaInJava的产品,效率跟高,接近于HotSpot。
- Jikes RVM,由IBM研发的一个实验性质的项目,类似于JavaInJava。
- IKVM.NET,基于.NET平台实现的Java虚拟机,通过Mono实现了一定的跨平台能力。
Java经过了这么多年的发展,经历过公司更替,经历过组织割裂,沧海桑田,都使其走了过来,在互联网快速发展的今天,这是一个最好的时代,也是一个最坏的时代,挑战与机遇并存,Oracle公司推出的Graal VM也被官方称为Universal VM,这也是未来最有可能替代HotSpot VM的产品,也将承担起Java迎接更大的挑战。
GC算法
Java语言最大的优势就是垃圾自动回收,不需要开发者去关心内存管理的事情,可以专注于业务逻辑开发。内存自动回收的核心GC算法,每一种GC都是基于不同的算法理论来实现的,因此算法对GC的性能、回收等都起着至关重要的作用。GC算法之间没有好坏之分,只有适合或不适合,每一个GC算法也不是一蹴而就的,是经过无数的迭代改进诞生的。
- 引用计数算法,这个算法的原理很简单,在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。但是在主流的垃圾收集器中都没有使用过这种算法,当出现两个对象之间互相引用,但是这两个对象又没有实际被使用的场景,会导致引用计数都不能清零,成为无法回收的垃圾。
- 可达性分析算法,这是主流虚拟机都在使用的一种垃圾回收算法,通过一些GC Roots来向下搜索,形成一个个引用链,如果某个对象没有到达GC Roots的引用链,那么就判定这个对象可回收,也就解决了引用计数算法里面判定的问题。因此也定义了一些常见的GC Roots。
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 标记-清除算法,Mark-Sweep,算法分为标记清除两阶段,首先对需要回收的对象进行统一标记,在标记结束后,统一回收,也可以统一标记存活对象,统一回收未标记对象。这个算法是最基础的,但是也有很多问题,比如大量的标记和清除,会导致两个阶段的效率都不同程度的降低,其次是标记清除后空间的不连续性,不利于大对象的分布,并由此触发下一次GC。
- 标记-复制算法,Semispace-Copying,使用的是半区复制的思路,与清除所不一样的是,复制算法,将新生代既定内存区域按照1:1分为两部分,把存活对象迁移至其中一个半区,然后清理已使用过的空间,这种算法复制过程通过指针移动来实现,因此带来的开销是内存空间开销,会消耗大量的内存。从某种程度上标记-复制解决了标记-清理在处理大量可回收对象时遇到的效率问题,但是空间消耗是其要面对的另一个问题。因此对于这种情况,考虑到大部分场景的对象都是朝生夕灭,存活周期较短,将新生代按照比例1:8划分为Survivor:Eden区,Survivor又划分为From和To两个区域,每次分配内存只使用Eden和其中一块Survivor(From)。发生垃圾收集时,将Eden和Survivor(From)中仍然存活的对象一次性复制到另外一块Survivor(To)空间上,然后直接清理掉Eden和已用过的那块Survivor(From)空间,清空后存在一个From->To的转变,出现From和To的角色互换,总是保证在发生GC之前保证To区域是空闲的。当Survivor不足以承担一次MinorGC时就需要通过分配担保(Handle Promotion)机制来将一些对象迁移到老年代。
标记-整理算法,Mark-Compact,相当于是标记-清除,标记-复制算法的优势整合,标记阶段通标记-清除算法的标记阶段一致,但是在标记结束后不直接清理,而是让存活对象向内存空间另一端移动,这点类似于复制的处理。标记-整理算法是建立在是否移动回收后的存活对象这个风险点之上的,移动对象会加大延迟,STW现象更为显著,但是带来的好处是移动对象后整片的内存区域可以提高吞吐量,因此在HotSpot VM中关注吞吐量的Parallel Scavenge GC是基于标记-整理算法实现的,关注延迟的CMS是基于标记-清除算法实现的。
垃圾收集器
在《Java虚拟机规范》中并没有规定垃圾应该如何回收,只是提出了这样一种理论,因此不同的厂商也有不同的实现方式,在众多的JVM中也存在着形形色色的GC,在此主要说的也是HotSpot VM中出现过的垃圾收集器。在JDK 7之前也就是G1出现之前,垃圾收集器是分代收集的按照新生代和老年代有不同的GC来进行内存回收,在G1之后出现的GC基本都是面向全堆栈回收,因此也可以对GC做不同的分类。
新生代GC
- Serial GC,这是最基础也是历史最悠久的收集器,在JDK 1.3.1之前,HotSpot中新生代唯一的收集器选择,在进行收集的时候会暂停所有工作线程直到收集结束,由于其单线程模式,也导致了STW时间过长,用户应用处于长时间假死状态,非常影响用户体验。但也是所有收集器中内存资源消耗最少的,在单核或者核心较小的服务器环境,也能体现出其特有的优势。在客户端模式下是一个不错的选择。
- Parallel Scavenge GC,基于标记复制算法实现的收集器,其目标在于达到一个可控制的吞吐量(处理器用于运行用户代码时间与处理器总消耗时间的比值),良好的响应速度可以提高用户体验,高吞吐量可以最高效率的利用处理器资源,尽快完成运算任务,适合运算多而交互少的分析任务。
- ParNew GC,实质上是Serial的多线程版本,线程的数量一般为CPU的核数,除了在收集垃圾采用多线程并行收集外,其他地方与Serial并无较多差异,是不少在服务端模式下运行的虚拟机的首选新生代收集器。ParNew与Parallel Scavenge的区别在于,ParNew在Parallel Scavenge的基础上做了一个增强,使得它可以CMS配合使用,前者侧重于低延迟,后者侧重于高吞吐。
- 老年代GC
- Serial Old GC,相对于Serial收集器,Serial Old专用于处理老年代GC,使用标记整理算法,主要也是在客户端模式下使用,如果在服务端模式下,在JDK 1.5之前与Parallel Scavenge配合使用,或者作为CMS失败后的预案,在Concurrent Mode Failure时使用。
- Parallel Old GC,PArallel Old是Parallel Scavenge的老年代版本,基于标记整理算法,支持多线程并发收集,在JDK 6提供,在Parallel Old出现之前,Parallel Scvenge只能和Serial Old搭配使用,比较尴尬,CMS无法与之配合,而Serial Old又不适合服务端模式,因此在此之前使用较多的也是ParNew + CMS组合。在吞吐量优先的场景中,PS + PO的组合实至名归。
- CMS GC,JDK 5推出的一个划时代意义的收集器,首款真正做到了并发收集的垃圾收集器,实现了垃圾收集线程与用户线程同时运行。无法与Parallel Scavenge配合工作,因此CMS的出现也巩固了ParNew的地位。CMS使用了标记清除算法,一般分为四个阶段,初始标记->并发标记->重新标记->并发清除,由于初始标记和并发标记的存在,大大减小了STW的时间,但是CMS无法很好的处理浮动垃圾(并发清理阶段,用户线程产生的垃圾,无法被及时清除,保留在下一个GC阶段),为了处理浮动垃圾,CMS需要老年代预留一部分内存,通过设定的阈值来确定GC的时机。CMS也是在一次次不完美的过程中尝试完美。
- G1 GC,G1在JDK 7中进入Experimental状态,在JDK 8中日趋成熟,在JDK 9中开始正式成为HotSpot的默认GC,替代了服务端主打的PS + PO组合收集器,此后也在Oracle官方被称为全功能垃圾收集器(Full-Featured Garbage Collector),主要面向服务端。G1是垃圾收集器发展史上具有里程碑式的成果,开创了面向局部收集的设计,每一个Region都可以扮演新生代的Eden、Survivor或者老年代空间。
- 低延迟垃圾收集器(衡量指标:内存占用、吞吐量、延迟)
- Shenandoah GC,第一款不是Sun或者Oracle设计的GC,甚至在OracleJDK 12中被明确拒绝的GC,因此只能存在与OpenJDK中,开源比收费的功能反而更多。相比于G1更像是G1的继承者,多线程Full GC的支持、类似于Region的设计有着优于G1的更多设计,都是为了降低延迟。
- Z GC,JDK 11开始加入的GC,与Shenandoah目标类似,但设计思路又大有不同,Shenandoah更类似于G1的延伸,ZGC更像Azul公司PGC和C4的复刻。ZGC使用染色指针技术来作为其标志性的并发整理算法实现,支持更大的内存管理和更高效的垃圾收集。
- Epsilon GC,JDK 11中依然出现了一个实验性质的GC,不能够进行垃圾收集的垃圾收集器,相比于G1、Shenandoah、ZGC复杂的垃圾收集算法和设计实现,Epsilon有点反其道而行之的意味,事实上一个GC的功能不仅仅是回收这个动作,还要负责堆管理布局,对象分配以及与解释器的协同工作等,如果在某些不需要回收仍然可以正常运行的Java虚拟机系统中Epsilon似乎是一种更好的选择。解决问题的方式固然重要,处理问题的思路也很重要。
之所以存在这么多的垃圾收集器,也就说明了没有一个完美的GC来适应所有场景,因此面对不同的场景,分代收集和全堆栈收集也给JVM调优指明了思路,了解不同GC的设计特点,才能更好的选择。
常见GC搭配组合:
JDK 8之前,GC存在明确的分代模型,G1开始引入了Region的布局概念,每一个Region都可以按照需要扮演新生代的Eden或者Survivor空间以及老年代空间。由于在JDK 8中G1尚不成熟,因此没有成为默认收集器,JDK 8中默认使用的PS + PO的组合模式,因此在JDK8中也可以根据实际情况,对垃圾收集器进行适当调整。JDK 9中已经将G1设置为默认的垃圾收集器,从这个版本之后,JVM调优会越来越弱化,开发人员以更多的精力来关注上层应用开发。
使用命令查看当前版本JVM都默认GC
java -XX:+PrintCommandLineFlags -version
输出结果:
-XX:InitialHeapSize=257033280 -XX:MaxHeapSize=4112532480 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGCjava version "1.8.0_301"Java(TM) SE Runtime Environment (build 1.8.0_301-b09)Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
可以看到初始化堆内存和最大堆内存大小,默认开启指针压缩,以及默认GC信息。
无论是JDK、GC、GC算法哪一个时间线,都可以无限的延伸下去,不是三言两语可以解释清楚的。这里也仅仅介绍梳理了一下发展过程,在JVM不断的演变之中,一些传统的认知也在被更替,比如所谓的Java中对象是在堆内存分配,随着逃逸分析,栈上分配,标量替换等更先进的技术发展出以后,Java中对象的分配也不是一成不变的,是按照具体的情况来分配的。
JavaWeb发展
Java发展最为广泛的就是在互联网领域,这其中既包含了官方对于Web方向发展的一些规范及实现,也有非常出色的产品,如体系庞大且上手友好的Spring,也有小而美的JFinal、Vert.x等,未来将是云原生,提倡Serverless无服务模式的,Java无论是JDK层面还是GC、Web框架层面也涌现了一批优秀的框架,正在跃跃欲试,如Spring Native、Spring WebFlux、RedHat Quarkus、Eclipse MicroProfile、Oracle Helidon等反应式、云原生框架,去打造一个全新的轻量级微服务时代。
JavaEE
在Java的三条产品线中发展的最好的无疑是JavaSE,但是使用最为广泛的当属JavaEE(Java Platform, Enterprise Edition)。发展至今,JavaEE 提供了一个丰富的企业软件平台,拥有超过20 种符合 Java EE的实现。
Java EE 是利用 Java Community Process 开发的,业界专家、商业组织和开源组织、Java 用户组以及数不清的个人为此做出了巨大贡献。每个版本都集成了符合业界需求的新特性,提高了应用可移植性,提高了开发人员的工作效率。
JavaEE定义了十三种常用的核心技术规范。
- JDBC:Java Database Connectivity,定义了Java程序如何和数据库建立连接的接口规范。
- JNDI:Java Naming and Directory Interface,相当于一个目录服务,关联服务名称与服务对象,通过名称来直接访问与其关联的对象,譬如将数据源通过名称与数据源对象绑定。
- EJB:Enterprise JavaBean,构建企业级应用服务的一套体系,是一个体系庞大的规范,经历了1.0,2.0,3.0的阶段。
- RMI:Remote Method Invocation,RMI协议能够让在某个Java虚拟机上的对象,像调用本地对象一样调用另一个Java虚拟机中的对象上的方法。它使用了序列化方式在客户端和服务器端传送数据。
- Servlet:Server Applet,Servlet是一种小型的Java程序,它扩展了Web服务器的功能。作为一种服务器端的应用,当被请求时开始执行。如常用的Tomcat就是一种实现了Servlet的Web容器。
- JSP:Java Server Pages,其本质也是Servlet,相比于Servlet处理用户请求,JSP侧重于视图层的渲染,提高了通过Servlet输出HTML DOM的效率。
- XML:EXtensible Markup Language,XML是一种用于标记电子文件使其具有结构性的标记语言。它被用来共享数据。XML的发展和Java是相互独立的,但是它和Java有着相同的目标,即平台独立性。通过Java和XML的组合,可以得到一个完美的具有平台独立性的解决方案。
- JMS:Java Message Service,JMS是Java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。ActiveMQ就是完全实现了JMS规范的消息队列。
- Java IDL:Java Interface Description Language,IDL是用来描述软件组件接口的一种计算机语言。IDL通过一种中立的方式来描述接口,使得在不同平台上运行的对象和用不同语言编写的程序可以相互通信交流。
- JTS:Java Transaction Service,JTS是一个组件事务监视器。JTS是CORBA OTS事务监控的基本实现。JTS规定了事务管理器的实现方式。JTS事务管理器为应用服务器、资源管理器、独立的应用以及通信资源管理器提供了事务服务。。
- JTA:Java Transaction API,Java的事务API,原则上事务一般基于数据库来实现,但是JTA为JavaEE平台提供了分布式事务服务,它隔离了事务与底层的资源,实现了透明的事务管理方式,如Seat。
- JavaMail:JavaMail是用于存取邮件服务器的API,它提供了一套邮件服务器的抽象类。不仅支持SMTP服务器,也支持IMAP服务器和POP服务器。
- JAF:JavaBean Activation Framework,JavaMail利用JAF来处理MIME编码的邮件附件。MIME的字节流可以被转换成Java对象,或者转换自Java对象。大多数应用都可以不需要直接使用JAF。
更多的JavaEE规范:https://www.oracle.com/cn/java/technologies/java-ee-glance.html
- Java™ EE 平台文档
- API 文档
- 规范
基于JavaEE的框架由Sun公司发起的有EJB、JPA等,这些框架在设计初期,考虑到的规范众多,难于上手,因此没有很好的市场效应,EJB经历了1.0、2.0、3.0版本的大迭代,尤其是EJB3.0和之前的产品差异巨大,而JPA也被Hibernate一统持久化框架市场,做到了ORM领域的顶流产品。
Spring
Java诞生于1995年,赶上了互联网发展的浪潮,但Spring并不是伴随着Java产生的,因此在前近十年没有Spring的阶段,Java Web的开发也度过了一个黑暗漫长的阶段。Spring 由 Rod Johnson 创立,2004 年发布了 Spring 框架的第一版,其目的是用于简化企业级应用程序开发的难度和周期。
Spring使得Java开发变得更为简单,可以快速的构建出一个Java企业级应用,而且支撑对市面上大多数的Java框架的整合,正如其名,给Java程序员带来了春天,几乎人人都是Spring程序员。Spring特性可以概括为以下几点。
- Spring is everywhere
- Spring is flexible
- Spring is productive
- Spring is fast
- Spring is secure
- Spring is supportive
Spring是主打B/S架构的Java一站式企业级开发框架。每一个技术的出现不是一蹴而就的是经过一步步的演变而来的,Spring并不能见证Java Web的整个发展过程,但是重要的统一集大成者。这里主要介绍在Spring诞生前后以及目前Java Web开发过程中主要的技术栈体系发展过程。
- 远古时代(无Spring或者同类框架)
- 静态网页:代表技术包括XML、HTML、XSLT等。1994 年,网景公司发布了 Navigator 浏览器,早期的网站不能和用户交互,只能用来展示一些信息。
- Servlet:Servlet是Service Applet的简称,可以用来处理用户请求,并且输出返回结果到页面可以实现用户和网站的交互功能。Servlet也在不同时期的JavaEE规范中不断完善。
- JSP:全称为Java Server Pages,Sun公司借鉴微软的asp作为Java Web应用的视图层,其本质仍为Servlet,但是区别在于JSP更加专注于视图渲染。
- Model1:通过JSP、JavaBean来实现,已经对代码进行了简单的分层,JSP可以直接编写HTML DOM和JavaScript代码,并且借助el和jstl表达式直接获取到9大内置对象的值,使得前后端之间的交互更为灵活,但是大量的前后端代码耦合使得后期维护异常困难,需要开发人员同时熟悉前后端技术,对开发人员要求较高。
- Model2:通过JSP、JavaBean、Servlet来实现,已经具有MVC分层概念了JSP作为V,JavaBean作为M,Servlet作为C,实现了代码的解耦,更加易于扩展。这里要区分三层(业务逻辑层、数据持久化层和表现层)架构与MVC,不能混为一谈,表现层又分为模型、视图和控制器,对应MVC。
- Struts1/XWork/WebWork:这几个之所以放到一块,是因为有很多相似的地方,这是比较早期的控制层框架了,WebWork建立在xWork之上,Struts1与Servlet API耦合较深,表现层技术单一,WebWork已经支持更多的视图层技术,如FreeMarker和XSLT,并且可以通过OGNL表达式访问栈值。
- Struts2:Apache赞助的 一个开源项目,整合Struts1、WebWork优势,Struts2采用了WebWork的设计核心,使用拦截器来处理用户请求,从而允许用户的业务逻辑控制器与Servlet API分离,达到深层解耦的目的,Struts2控制器组件是Struts2框架的核心,所有MVC框架都是由控制器组件为核心的。Struts2的控制器由FilterDispatcher和业务控制器Action两部分组成,每一个用户拦截器通过继承实现。
- Hibernate诞生在2001年11月,一个基于JPA规范的ORM框架,让程序员只关心对象之间的关联关系,忽略SQL语句,自动生成相关的SQL,因其上手难度高,功能体系庞大,在发展过程中逐渐被半自动ORM框架Mybatis(早期名称ibatis)占据了一部分市场,至此Java的开发已经逐步进入框架时代,等待着Spring带来的大一统时代。
- Spring时代(进入人人都是Spring程序员时代)
- SSH:指的是以Spring、Struts2、Hibernate为核心技术栈的web应用技术框架,也可以继续借助Spring强大的整合能力来引入第三方依赖框架。
- SSM:指的是以Spring,SpringMVC,Mybatis为核心技术体系的Web应用技术栈。相比于SSH框架,无论是Struts2的设计,基于类的请求拦截,还是全ORM映射的Hibernate,这些元素都过于重量,不适合瞬息万变的互联网环境,需要更加建议轻量级的实现方式来替代,因此诞生了SSM,SpringMVC有着Spring的天然优越性,SpringMVC容器是Spring容器的子容器,子容器可以共享父容器的Bean,并且基于方法的SpringMVC缓存在处理大量并发请求的场景下更具有优势,Mybatis更加是和复杂查询场景,而实际业务场景中也是如此,这也降低了使用Hibernate的门槛成本。
- Spring Boot:即便SSM已经简化了在Struts2和Hibernate中复杂的配置关系,但是传统的Web项目依然存在大量的配置项,从web.xml到applicationContext.xml,再到SpringMVC等第三方xml,依然需要大量配置,仍有一定的学习成本,SpringBoot简化配置,根据常用的开发经验,简化maven依赖(即spring-boot-starter-和-spring-boot-starter),总结了一套体系化配置参数,约定大于配置(即application.properties和application.yml),并且内置Tomcat(SpringBoot2.x中已经切换到了undertow,拥有更高的并发处理能力)真正做到了一键启动。
- Spring Cloud NetFlix:基于Spring Boot强大的配置能力,传统项目在处理一个业务复杂的系统时候,体量巨大,不便于需求迭代和业务开发,牵一发而动全身,部署应用时也需要更大的内存、CPU等资源消耗,因此可以对一个复杂的项目进行拆分,在业务场景上做到服务分治,在技术方案中利用Spring Boot快速构建,相得益彰,Spring Cloud诞生了。Spring Cloud并不特指某个具体的技术,而是一系列现有成熟技术的整合,官方的解释就是SpringBoot构建一切,Spring Cloud协调一切。Spring Cloud NetFlix是由NetFlix公司开源的一套微服务组件库,包含常见的微服务组件。
- Eureka 基于AP的服务发现
- Zuul 网关组件
- Hystrix 熔断、限流组件
- Ribbon 负载均衡
- Feign 远程调用
- Zipkin 链路追踪
- Config 配置中心
随着微服务的发展,这些组件也许不是最好的解决方案,但是依然是一套完善的生态体系,可以应对大部分的业务场景。
- Spring Cloud AliBaba:同样提供了一站式的分布式应用解决方案,属于现在比较热门,先进的微服务解决方案,基于微服务的思想,提供了更好用的组件库,常见组件包含。
- Nacos 整合服务发现和配置中心,支持AP和CP场景
- Sentinel 哨兵,更为优越的限流解决方案
- 更多基于Spring Cloud的微服务解决方案,当然也有其他的微服务解决方案,比如k8s本身就可以作为微服务解决方案,还有Zero Ice,Apache ServiceComb等。
未来发展
- 展望未来(以容器化、云原生、反应式为关键特征)
- Quarkus
- Spring Native
- kubernetes
随着容器化技术Docker、Kubernetes,让云原生似乎成为了未来的发展方向,云原生(Cloud-Native)这个概念最早由Pivotal公司的Matt Stine于2013年首次提出,提到云原生首先想到的关键词可能就是容器化、微服务、Lambda,服务网格等,当然这些是必要元素,但是不代表拥有这些元素就是云原生应用,很多应用的部署只能说是基于云来完成,比如私有云、公有云,这也是未来的趋势。云原生本质上不是部署,而是以什么方式来构建应用,云原生的最终目的是为了提高开发效率,提升业务敏捷度、扩容性、可用性、资源利用率,降低成本。
个人认为,未来应用发展不应该像Spring Cloud时代过分关注于组件的功能,组件的本身是服务于业务场景的,而组件更应该依托于容器化部署方式来实现其功能,在这一点上来说Spring的脚步对比Quarkus确实略慢一筹,期待未来百花齐放的云原生时代。
架构发展
互联网如今也在深刻的影响着人们的生活,无处不在,不仅拉近了人们之间的距离,也在影响着人们的交流方式、生活方式等等。互联网快速发展的同时网站的技术架构也经历了无数次的迭代,从简单到复杂。按照演变过程来说可以大致分为三个阶段,这也是网站由小到大的一个过程。
- 单一架构
- 集群架构
-
单一架构
没有一个网站上线初期就会拥有庞大体量的用户,只不过在信息爆炸的今天这个过程可能会在不断缩短,比如抖音等短视频软件的快速扩展。就拿庞大的电商平台淘宝来说,也是经历了近十几年的发展,从一个功能单一的小网站,发展到今天巨无霸的体量,感兴趣的可以看一下《淘宝技术这十年》,带你认识一个巨型网站从小到大,从简单到复杂的过程。
在单一架构时代,不需要太多的服务器,也不需要过多的中间件来支持,往往依赖简单的技术栈体系就能支撑一个网站的运行,早期也诞生过不少优秀的组合,甚至今天依然也在沿用。 LNMP/WAMP LNMP一般指Linux、Nginx、MySQL、PHP,WAMP一般指Windows、Apache、MySQL、PHP,这种网站体系机构简单,单服务器可以部署所有资源(all in one),部署方便有很多现成的镜像包,一键启动建站的作用,区别的就是前者支持Linux环境,后者运行在Windows环境,Nginx和Apache都是静态服务器,处理一些简单嵌入式脚本语言,适用于业务简单、用户体量小的网站。
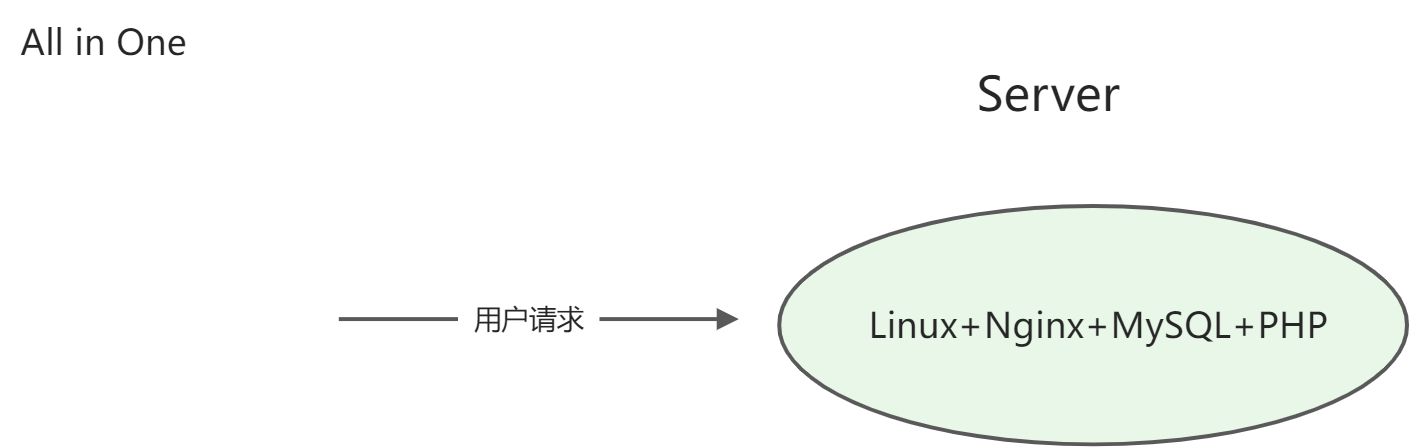
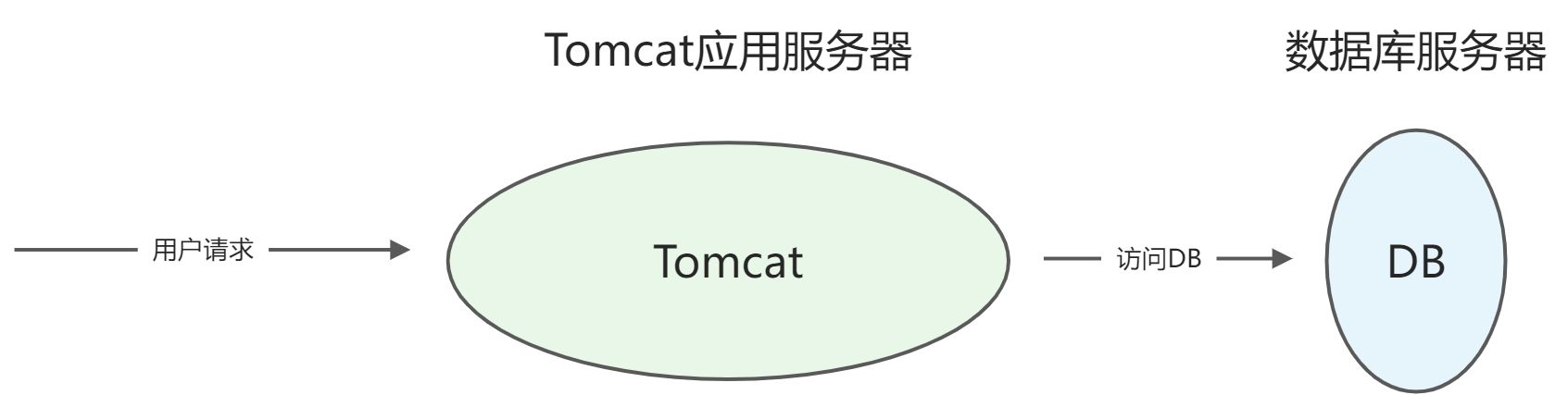
- Tomcat + DB,这种架构Tomcat作为动态服务器,不仅可以处理静态资源,也可以处理动态资源,适用于更复杂一些的业务场景,这里的DB指的是不限于MySQL如Oracle、DB2、SQLServer等常见关系型数据库。一般使用这种架构就有必要对部署服务器进行拆分,如把服务器资源分为应用服务器和DB服务器。
集群架构
当网站发展到一定规模,用户数量增多,相应的服务器也要进行扩增,如果业务流程相对不复杂的场景,不过多考虑业务代码的维护,只需要对服务器资源进行扩容,增加服务器数量即可,这个时候服务器的维护成本将会提高,对于一些经常访问的数据可以使用缓存服务器来降低关系型数据库的压力,对于关系西数据库可以采取读写分离达到高可用(HA)的目的,对于业务产生的文件可以增加共享文件服务器,降低应用服务器的磁盘压力。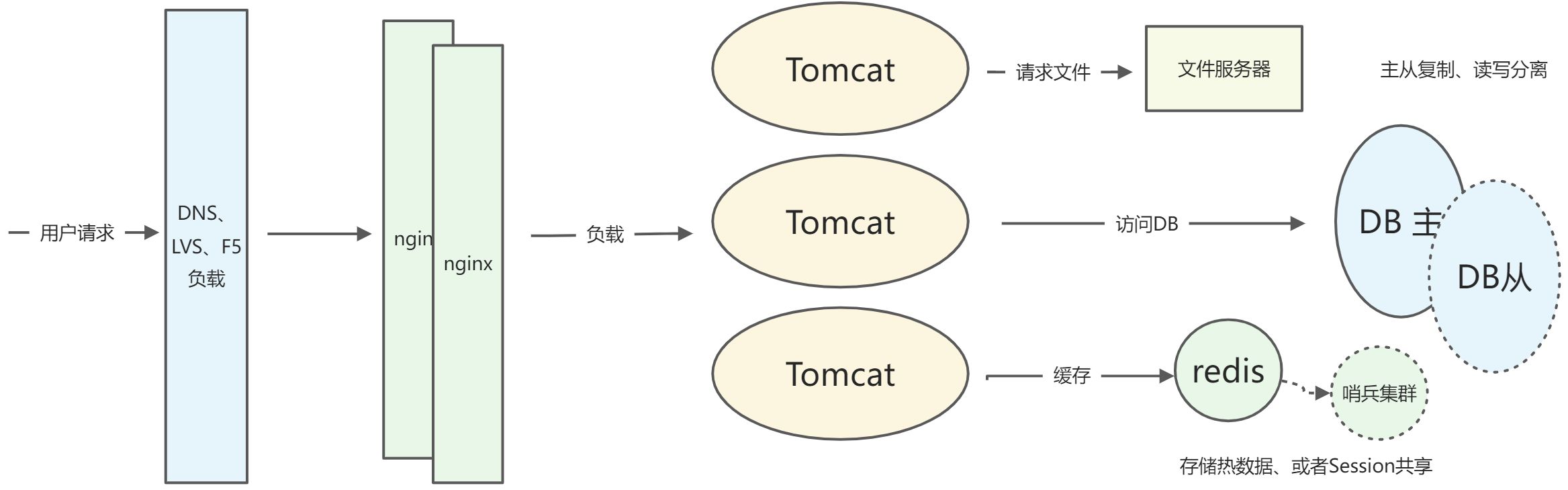
当然这里只是简单描绘了集群架构的一种模式,实际业务场景可能更为复杂,技术涉及到细节实现往往会有更多的问题需要处理,以上所描述的集群模式仅在传统单一架构模式对服务器横向扩容,所有的业务依然冗余在一块,很有可能存在牵一发而动全身的影响,比如某一个功能点的用户访问激增从而拖垮整个服务,而扩容只能进行整体扩容,浪费较多的服务器资源,不能进行有针对性的扩容,难以实现弹性伸缩。
分布式架构
分布式架构更侧重于部署形式,微服务架构更侧重于应用架构,在微服务出现之前还有一种传统SOA架构,面向服务架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来,发展至今这种传统的SOA架构似乎已经过时,微服务架构成为各企业热衷的潮流。相对于单体架构而言,微服务架构体现在微,如何拆分就成了关键。一般会对业务进行水平拆分和垂直拆分。
- 垂直拆分
对业务的不同进行分类,不同的业务划分到不同的应用和数据库中。这种拆分往往是根据系统的改造,将原来的功能模块按照更加细粒度的拆分成多个弱耦合的服务。
- 水平拆分
数据库层面的水平拆分,就是将一个数据表中的数据按照某种规则分化到不同的数据库中,也就是分库分表。应用层面的水平拆分,最经典的就是将整个应用分层。数据库访问层和业务逻辑层拆分、网关层和业务逻辑层拆分等等。
更为精细的可以参考AKF原则进行服务拆分,AKF 立方体也叫做scala cube,它在《The Art of Scalability》一书中被首次提出,旨在提供一个系统化的扩展思路,AKF 把系统扩展分为三个维度。
- X 轴:直接水平复制应用进程来扩展系统。
- Y 轴:将功能拆分出来扩展系统。
- Z 轴:基于用户信息扩展系统。
这里就不再展开描述,有兴趣的可以搜索相关资料。
微服务架构体系最明显的特征就是前后端分离,服务之间通过RPC调用,分工明确职责单一。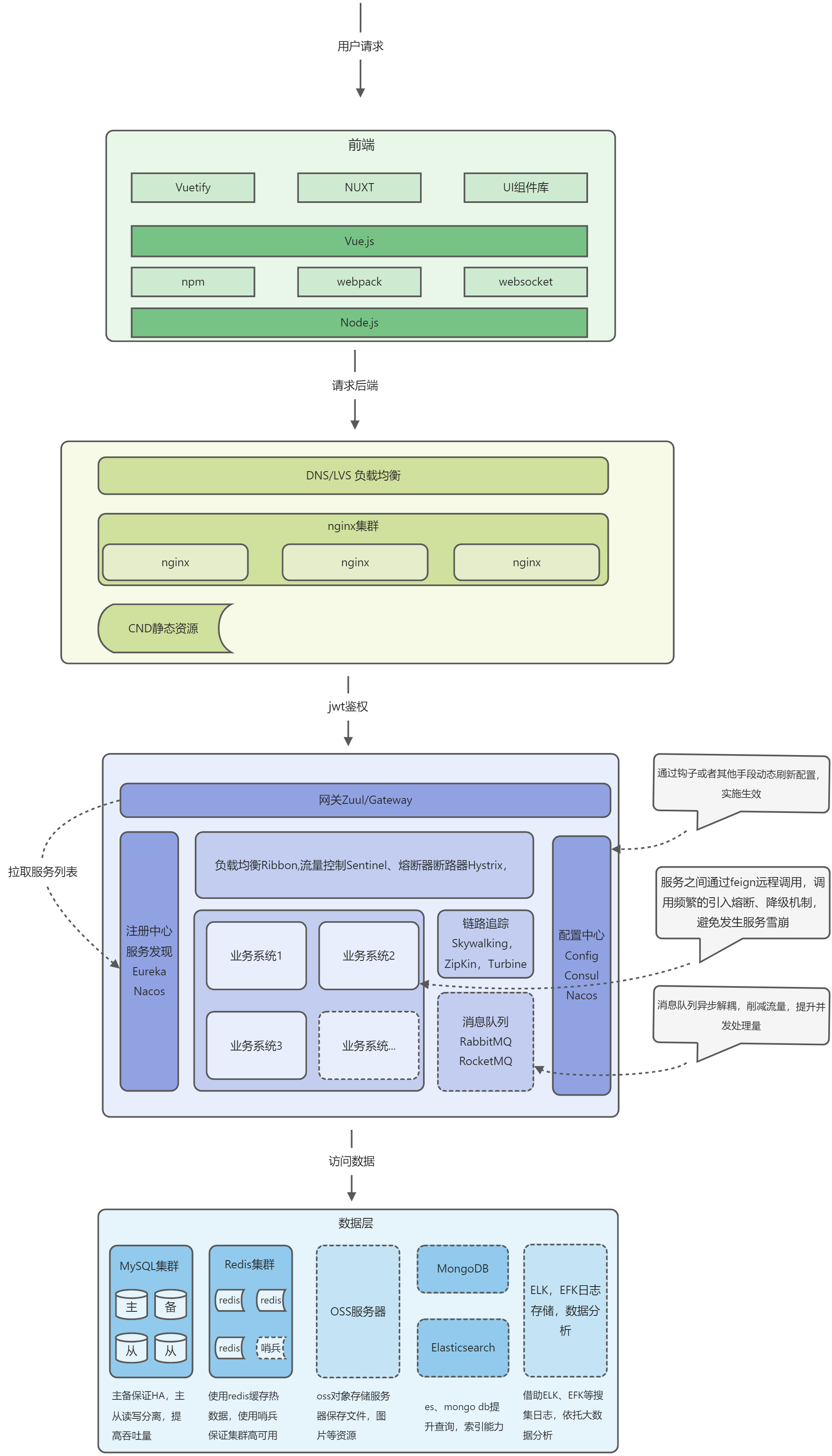
参考资料:

若有收获,就点个赞吧
0 人点赞
