hive基本架构图
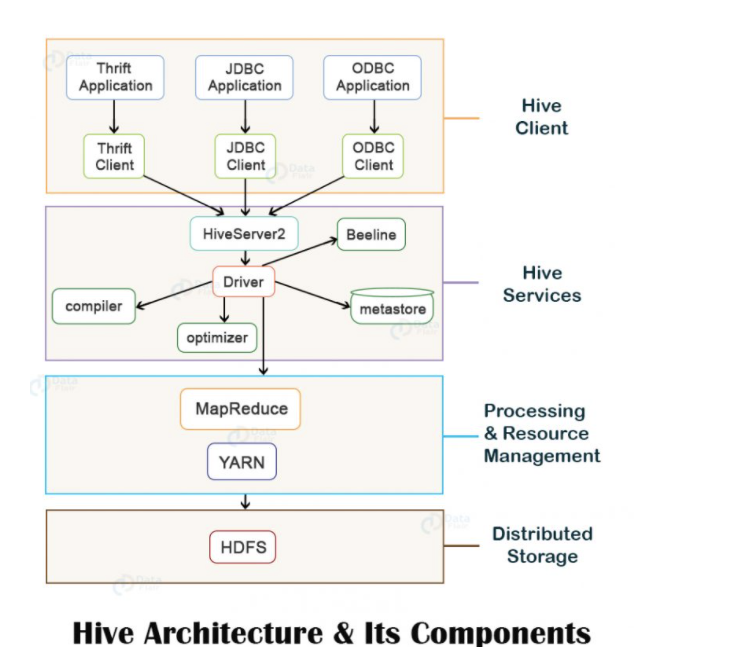
上图显示了Hive的基本体系结构及其主要组件。
Hive的主要组件如下:
- Hive Client
- Hive Services
- Processing and Resource Management
-
hive客户端
Hive支持使用JDBC, ODBC和Thrift驱动程序以任何语言(如Python, Java, C++,RuDy等)编写的应用程序,以在Hive上执行查询。因此,可以轻松地以自已选择的任何语言编写hive客户端应用程序。
Hive Services
为了执行所有查询,Hive提供了各种服务,例如Hive server2, Beeline等。
Hive Driver
Hive Driver接收用户通过shell提交的hql语句,为查询创建session handles,并将查询结果发送到编译器。
Hive Compiler
Hive编译器解析查询语句,使用存储在metastore中的元数据对不同的查询块和查询表达式进行语义分析和类型检查,并生成执行计划。
编译器创建的执行计划是DAG,其中每个阶段都是map/reduce任务、对hdfs的橾作、元数据橾作。Optimizer
优化器,Optimizer对执行计划进行转换操作,并拆分map/reduce任务来提高效率和可伸缩性。
Execution Engine
执行引起在编译和优化步骤完成之后,使用haooop按照赖关系的顺序执行由编译器创建的执行计划。
Metastore
Metastore是一个中央存储库,用于存储有关表和分区结构的元数据信息,包括列和列类型信息。
它还存储读/写操作所需的串行器和解串器信息,以及存储数据的HDFS文件。该元数据存储库通常是一 个关系数据库。
Metastore提供了一个Thrift接口,用于查询和橾作Hive元数据。HCatalog
HCatalog是Hadoop的表和存储管理层,它使用不同数据处理工具(例如Pig, MapReduce等)用户可以轻松地在网格上读取和写入数据。
它建立在Hive Metastore的顶部,并将Hive Metastore的表格数据公开给其他数据处理工具。WebHCat
WebHCat是用于HCatalog的REST API。它是执行Hive元数据操作的HTTP接口。它为用户提供了运行Hadoop MapReouce (或YARN), Pig, Hive作业的服务。
hql执行流程和执行计划
hql执行流程:
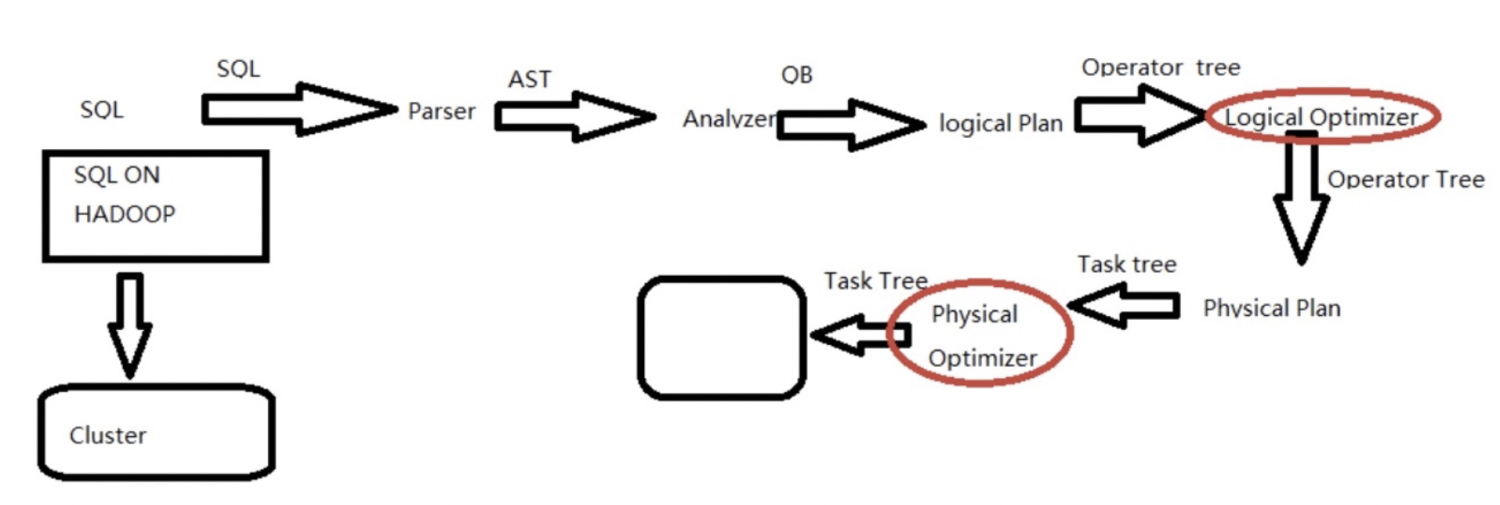
Parser:将sql解析为AST (抽象语法树),会进行语法校验,AST本质还是字符串。
- Analyzer:语法解析,生成QB(query block)
- LogiclPlan:逻辑执行计划解析,生成一堆Opertator Tree
- Logical optimizer:迸行逻辑执行计划优化,生成一堆优化后的Opertator Tree
- Phsical plan:物理执行计划解析,生成task tree
- Phsical Optimizer:进行物理执行计划优化,生成优化后的task tree,该任务即是集群上的执行的作业
hql执行计划:
通过explain参开头执行hql查看计划结果,执行计划输出有三个部分:
- 查询的抽象语法树
- 计划不同阶段之间的依赖关系
- 每个阶段的描述

若有收获,就点个赞吧
0 人点赞
