本文将介绍常见的3种flink安装部署模式:
以flink-1.12.0版本为例
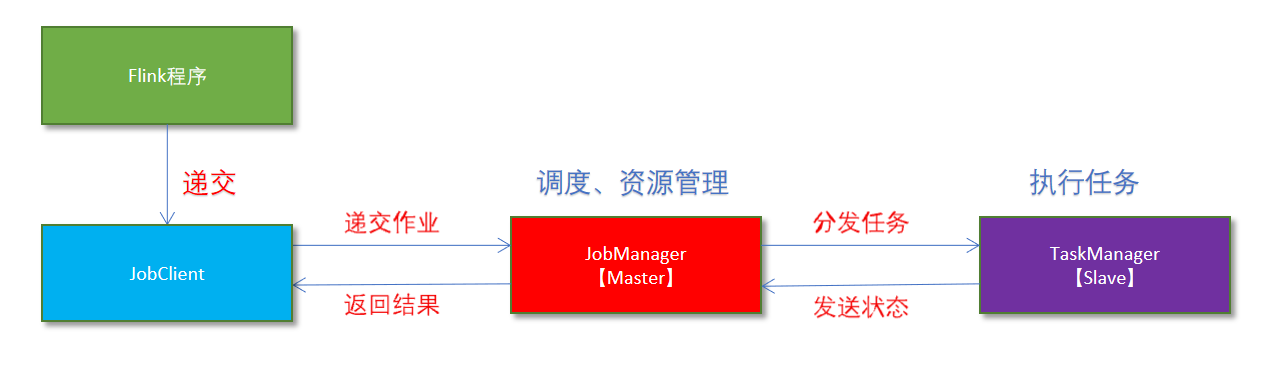
- Flink程序由JobClient进行提交给JobManager
- JobManager负责协调资源分配给作业执行。资源分配后,将任务提交给相应的TaskManager
- TaskManager启动一个线程开始执行,并会向JobManager报告状态如:开始执行、正在执行或已完成
- 作业执行完成后,结果将发送会客户短JobClient
部署步骤
- 下载安装包:https://archive.apache.org/dist/flink/
- 解压包 & 设置坏境变量 ```shell tar -zxvf flink-1.12.0-bin-scala_2.11.tgz
vim .bash_profile
FLINK_HOME=/Users/sgr/software/bigdata/flink-1.12.0 PATH=$PATH:$FLINK_HOME/bin export FLINK_HOME
source .bash_profile
<a name="o1P4U"></a>## 测试例子<a name="RkK8h"></a>### 通过flink脚本提交作业- 启动local集群:./bin/start-cluster.sh> 启动完会启动两个进程:> > 并会启动web UI,端口为8081> 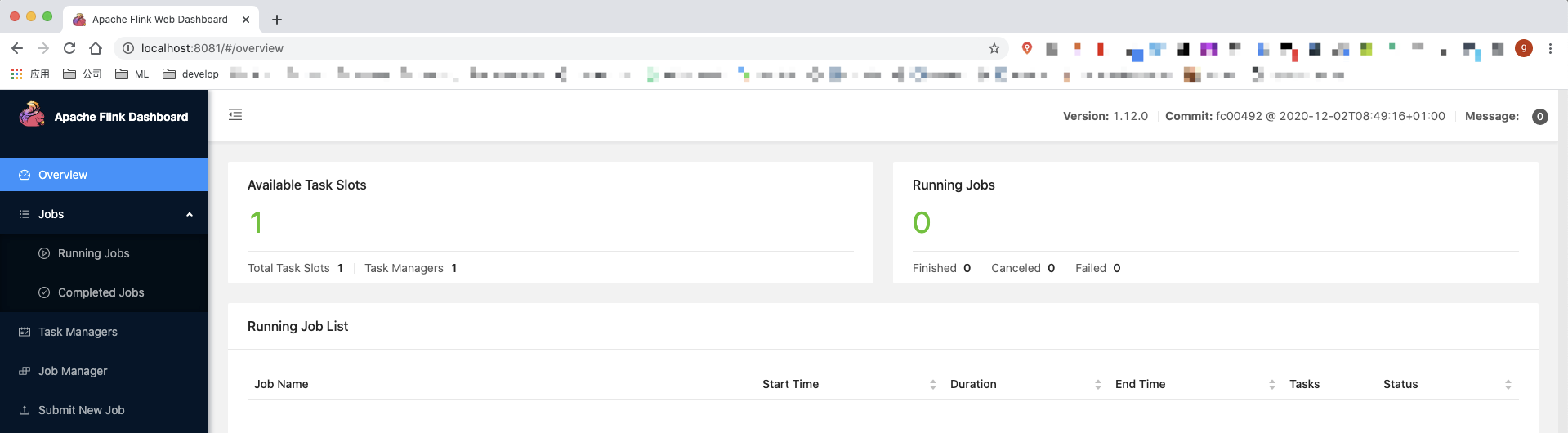> slot是flink的资源组,flink会将任务拆分成task分配给slot进行执行- 提交作业```shell./bin/flink run ./examples/batch/WordCount.jar --input ./README.txt --output ./out
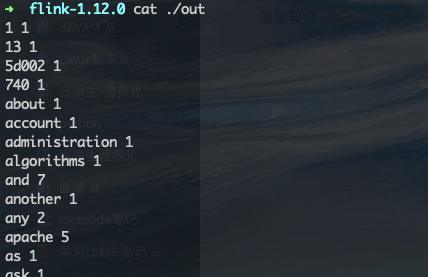
执行输出: cat ./out
-
启动shell交互
该方式类似与spark-shell,可以交互式的执行scala代码
启动client:./bin/start-scala-shell.sh local
启动完会启动进程

提交作业
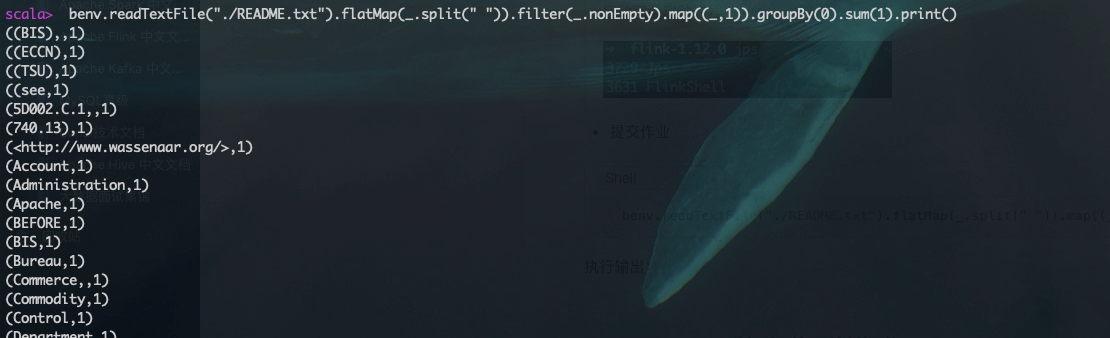
benv.readTextFile("./README.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()standalone独立集群模式
standalone独立集群的架构如下:

执行流程如下:
- client客户端提交作业给JobManager
- JobManager负责申请运行作业需要的资源,并管理资源和作业
- JobManager分发任务给TaskManager执行,TaskManager会定期向JobManager汇报状态
部署步骤
集群规划如下 | 机器列表 | JobManager | TaskManager | | :—-: | :—-: | :—-: | | node1 | ✅ | ✅ | | node2 | | ✅ | | node3 | | ✅ |
修改配置文件
解压flink包: tar zxvf flink-1.12.0-bin-scala_2.11.tgz -C /opt/
历史服务器
jobmanager.archive.fs.dir: hdfs://node1:9000/flink/completed-jobs/ historyserver.web.address: node1 historyserver.web.port: 8082 historyserver.archive.fs.dir: hdfs://node1:9000/flink/completed-jobs/
- 修改$FLINK_HOME/conf/masters
node1:8081
- 修改$FLINK_HOME/conf/workers
node1 node2 node3
- 分发配置文件
```shell
cd /opt
for i in {2..3};do scp -r flink-1.12.0 node$i:$PWD;done
或者可以单独启动jobmanager/taskmanager
在node1上执行
./bin/jobmanager.sh start && ./bin/taskmanager.sh start
剩余的node2、node3上执行
./bin/taskmanager.sh start
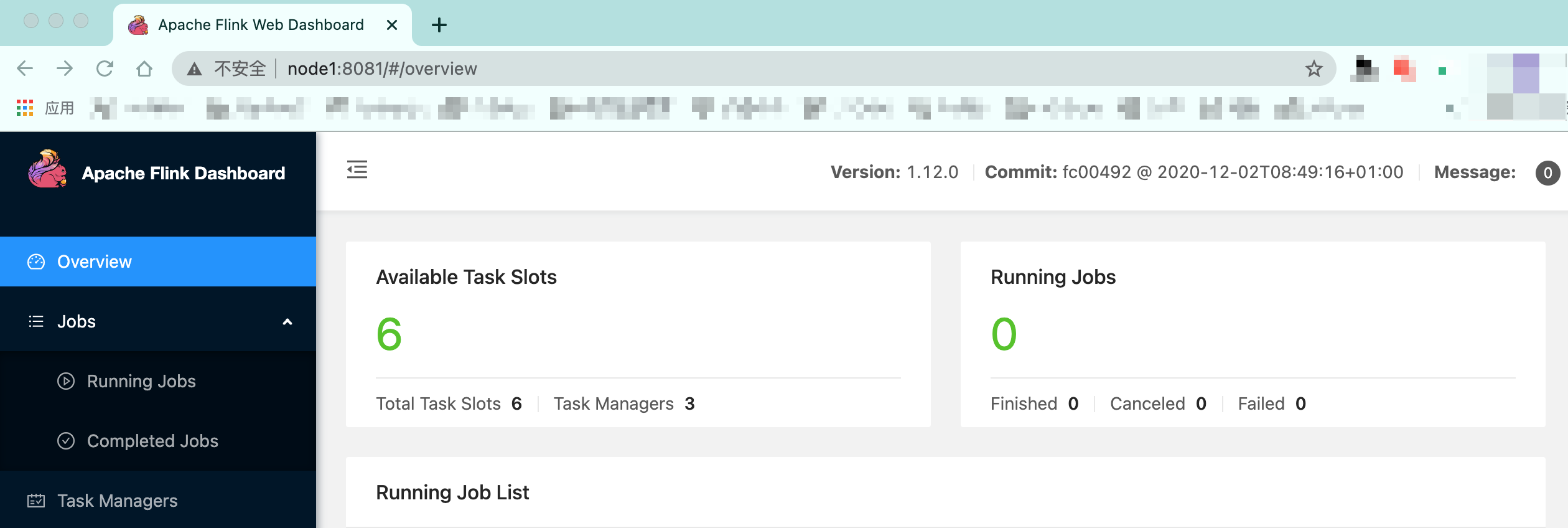
可以通过访问flink web UI:[http://node1:8081/](http://node1:8081/#/overview)
> 
- 启动历史服务器
```shell
# 在node1上执行
./bin/historyserver.sh start
启动会报如下错误: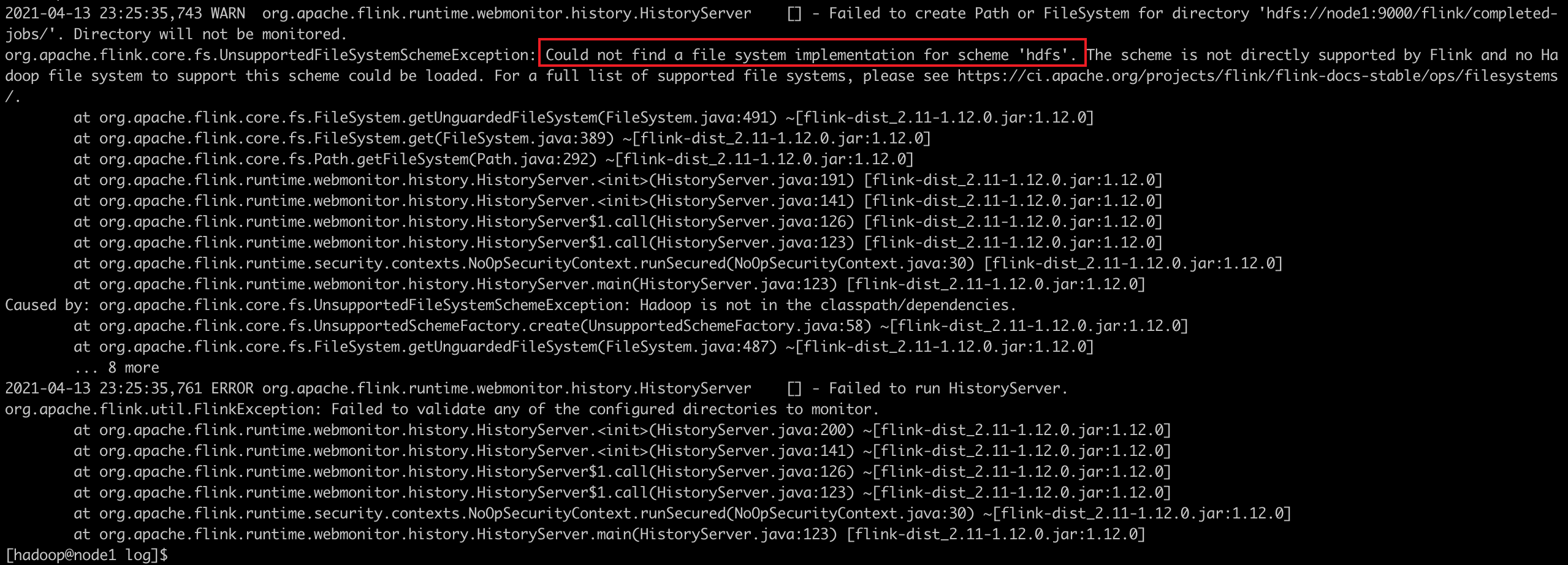
原因是flink采用Pluggable File Systems模式,如果要操作hdfs的话,必须要在flink安装目录的 lib 下加上额外的jar包。 Note: historyserver目录 hdfs://node1:9000/flink/completed-jobs 需要事先创建,不然会报错。
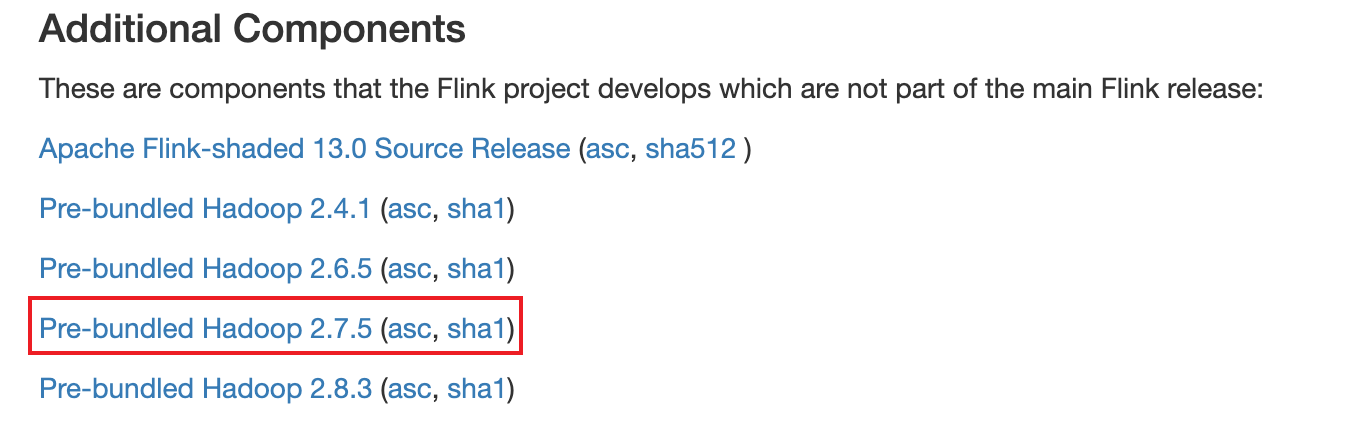
我这边hadoop集群版本为2.7.4jar,对应包的下载地址:https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-7.0/flink-shaded-hadoop-2-uber-2.7.5-7.0.jar
也可以通过flink官网下载:https://flink.apache.org/downloads.html
可以通过访问flink historyserver web UI:http://node1:8082/
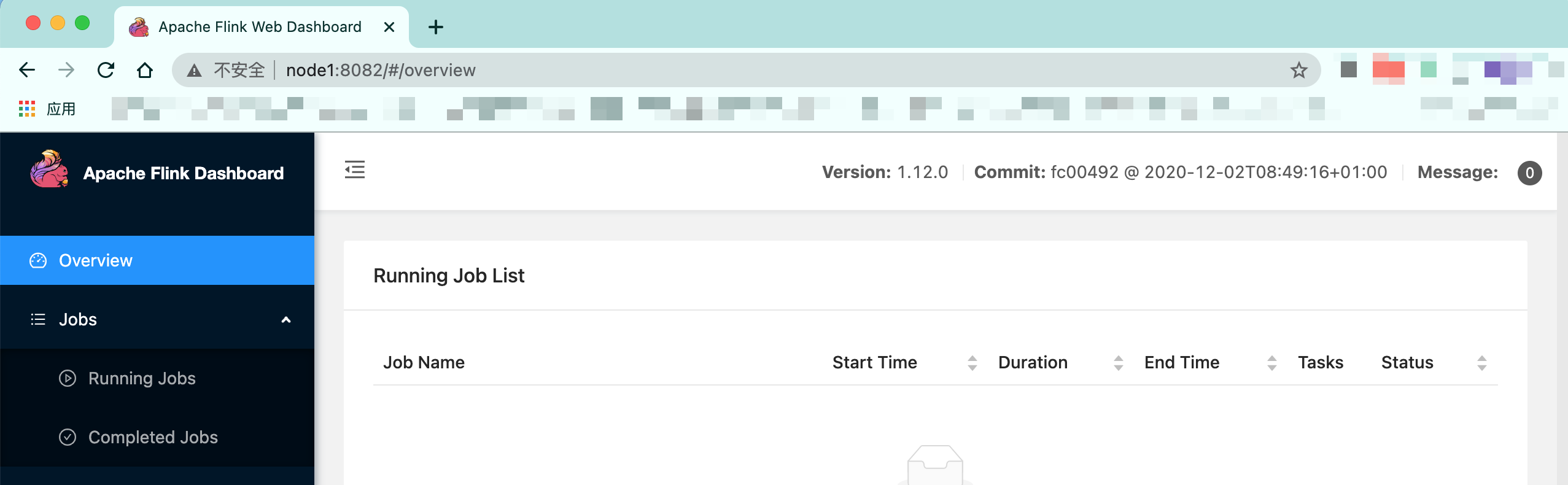
测试例子
提交作业
cd /opt/flink-1.12.0 ./bin/flink run ./examples/batch/WordCount.jar --input ./README.txt --output ./out查看历史
我们可以在hdfs看到作业信息:
web UI上也能查看到成功的job:
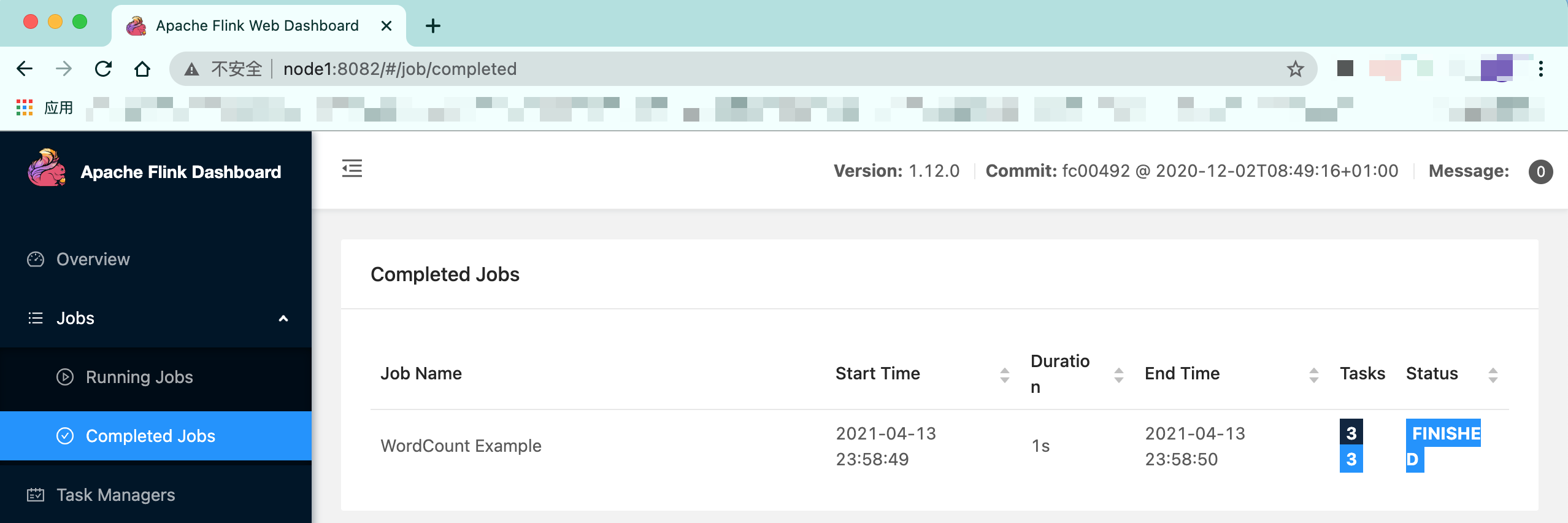
-
standalone HA搭建
之前的架构中,有一个很明显的问题就是JobManager存在单点问题,JobManager负责任务调度及资源分配,一旦JobManager出现问题,整个集群将不可用。
为了解决这个问题,我们引入Zookeeper,同时部署多个JobManager。在整个集群中只有一个active的JobManager,其余的将处于standby状态。当主JobManager出现问题,Zookeeper将会从剩余的standby状态中选取一个新的JobManager来管理Flink集群。基本架构如下: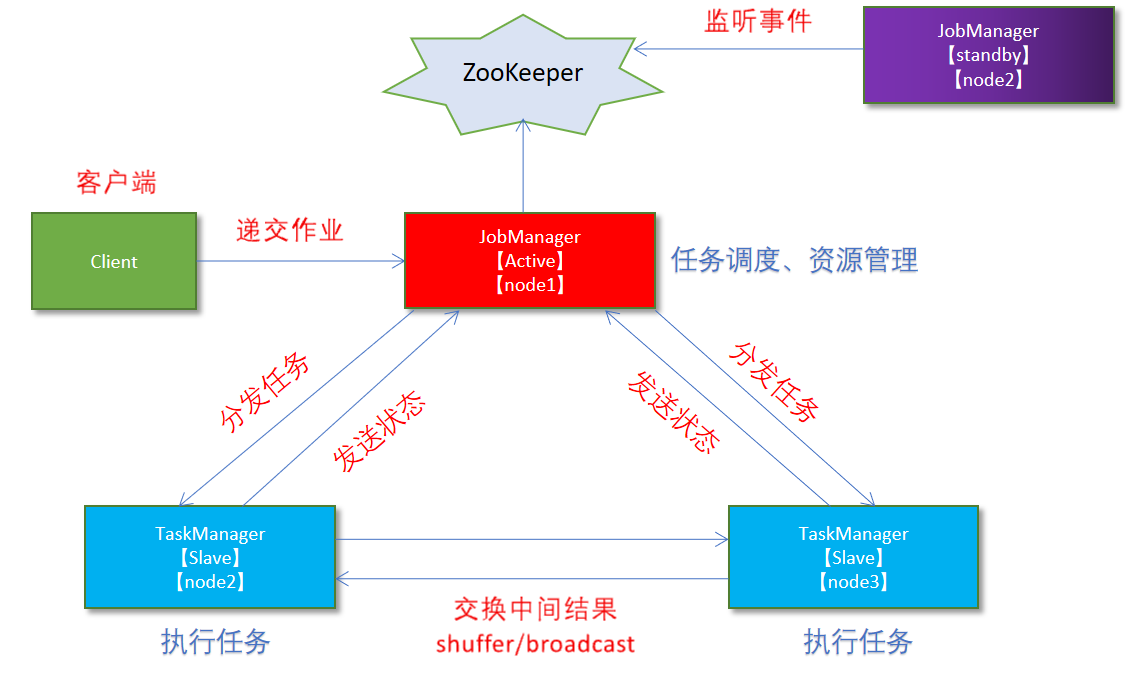
部署流程
集群规划 | 机器列表 | JobManager | TaskManager | | :—-: | :—-: | :—-: | | node1 | ✅ | ✅ | | node2 | ✅ | ✅ | | node3 | | ✅ |
启动Zookeeper集群:这边不详细展开
修改配置文件
修改$FLINK_HOME/conf/flink-conf.yaml,新增如下配置:
# 开启HA后,使用文件系统作为快照存储 state.backend: filesystem # 设置检查点,可以将快照信息保持到hdfs state.checkpoints.dir: hdfs://node1:9000/flink/flink-checkpoints # HA 设置 high-availability: zookeeper # 存储JobManager的元数据到hdfs high-availability.storageDir: hdfs://node1:9000/flink/ha/ high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181修改$FLINK_HOME/conf/masters
node1:8081 node2:8081
分配配置文件
cd /opt/flink-1.12.0 for i in {2..3};do scp -r conf node$i:$PWD;done注意:需要修改node2上的$FLINK_HOME/conf/flink-conf.yaml配置中jobmanager.rpc.address为node2
启动集群
# 在node1上执行如下命令: cd /opt/flink-1.12.0 ./bin/start-cluster.sh
可以分别访问两台flink web UI:
这样当某个JobManager出现问题时,另一个会进行接管,用户还是可以正常提交作业执行。
Flink on Yarn模式
我们使用yarn集群来管理Flink应用有如下好处:
- Yarn对资源可以按需使用,配合多种调度模式,能提高集群资源利用率
- Yarn对任务调度能设置优先级,保障重要任务
- 基于Yarn调度,能够自动处理各个角色的Failover(容错机制)
JobManager和TaskManager进程都由Yarn NodeManager进行监控,如果JobManager异常退出,Yarn的ResourceManager会重新调度JobManager到其他机器;如果TaskManager异常退出,JobManager会收到消息并重新向ResourceManager申请资源进行启动。
Flink与Yarn的交互基本如下所示: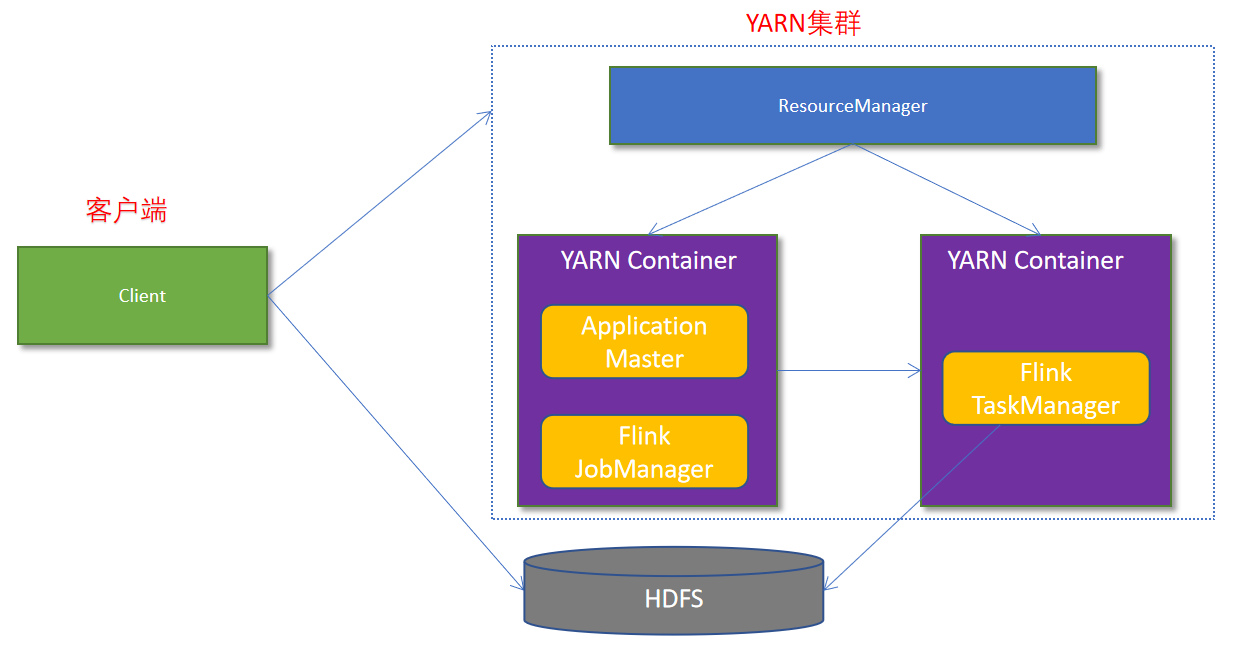
作业提交流程如下: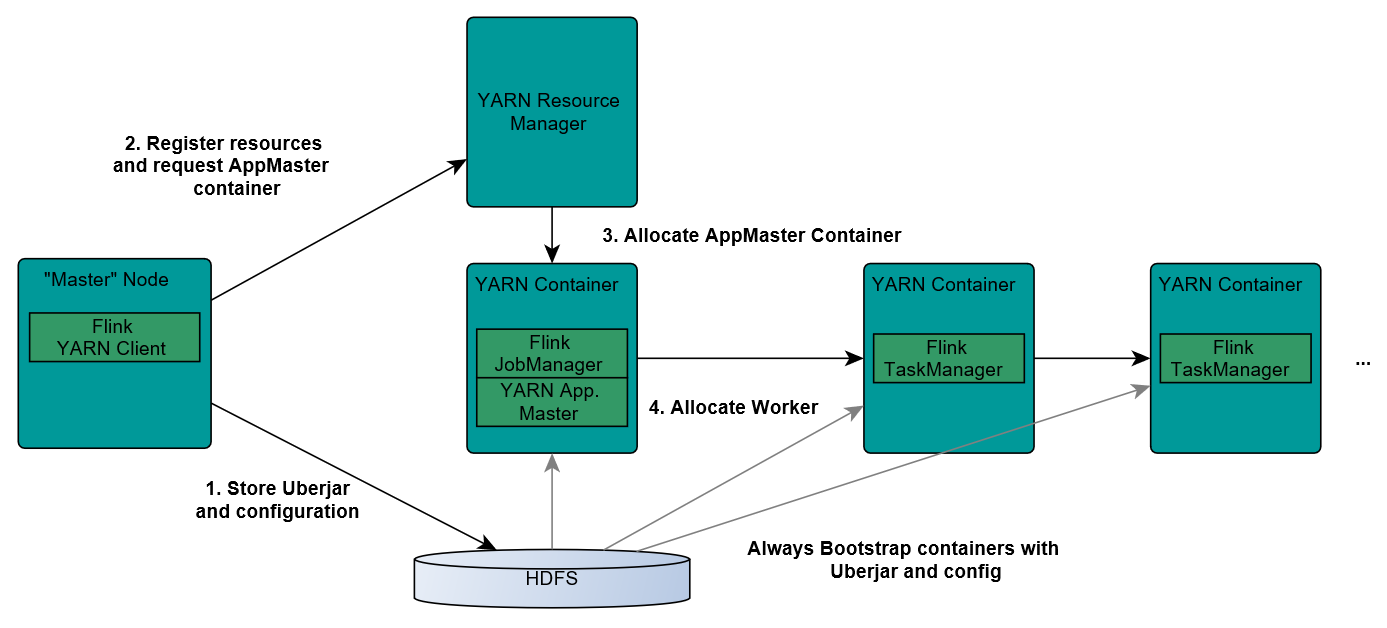
- 首先用户上次程序jar包和配置文件到hdfs集群上
- Client向Yarn ResourceManager提交作业并申请资源
Yarn ResourceManager分配Container资源并启动ApplicationMaster,然后AM加载Flink相关的jar包和配置文件构建好坏境,启动JobManager
JobManager和ApplicationMaster运行在同一个Container中。 他俩成功启动后,AM就获得了JobManager的地址,他会为TaskManager生成一个新的Flink配置(如何连接到JobManager的信息,这个配置会被上传到hdfs上)。 同时,AM容器会为Flink提供一个临时的web服务端口,用户允许并行执行多个Flink应用
ApplicationMaster向ResourceManager申请工作资源,NodeManager会加载Flink的jar包和配置构建坏境启动TaskManager
- TaskManager启动后,会向JobManager发送心跳,等待JobManager分配任务
Session模式
该模式会在Yarn集群中启动一个Flink集群,并进行重复使用,结构如下: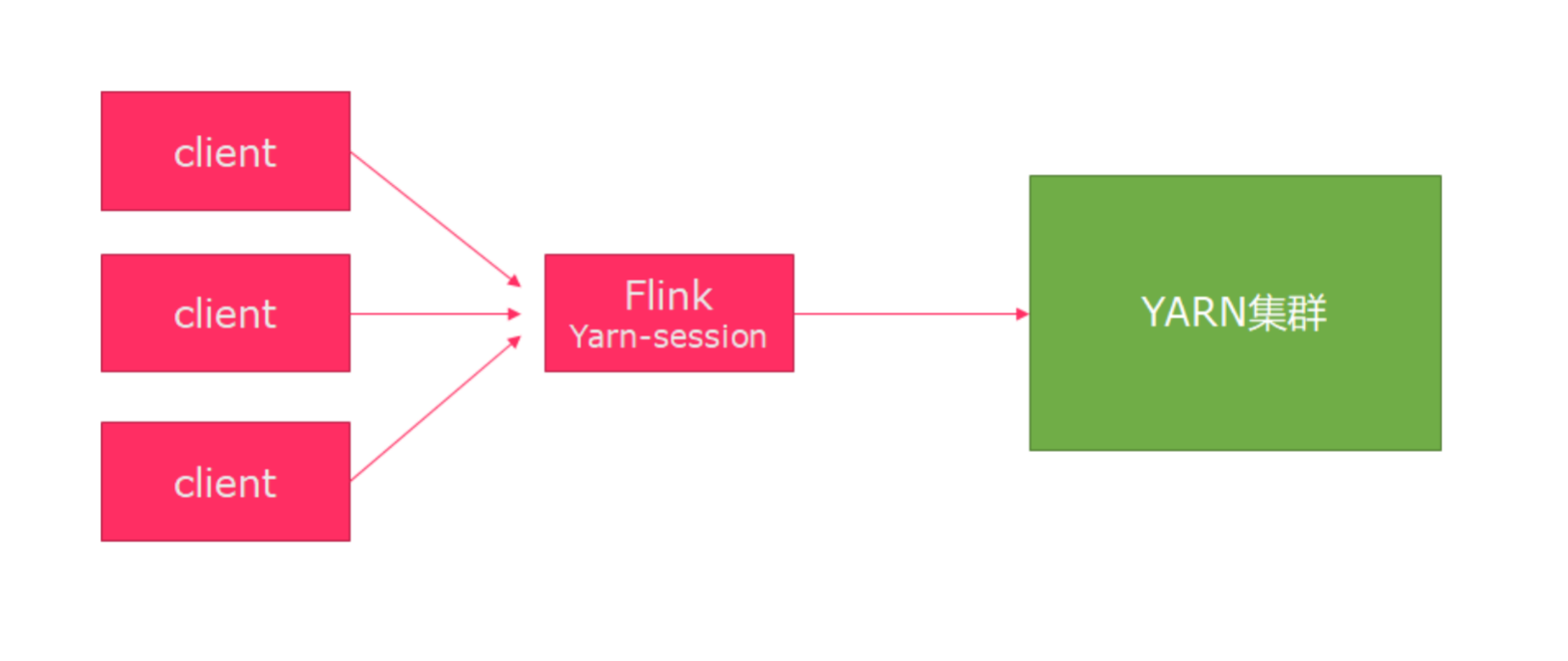
它有如下特点: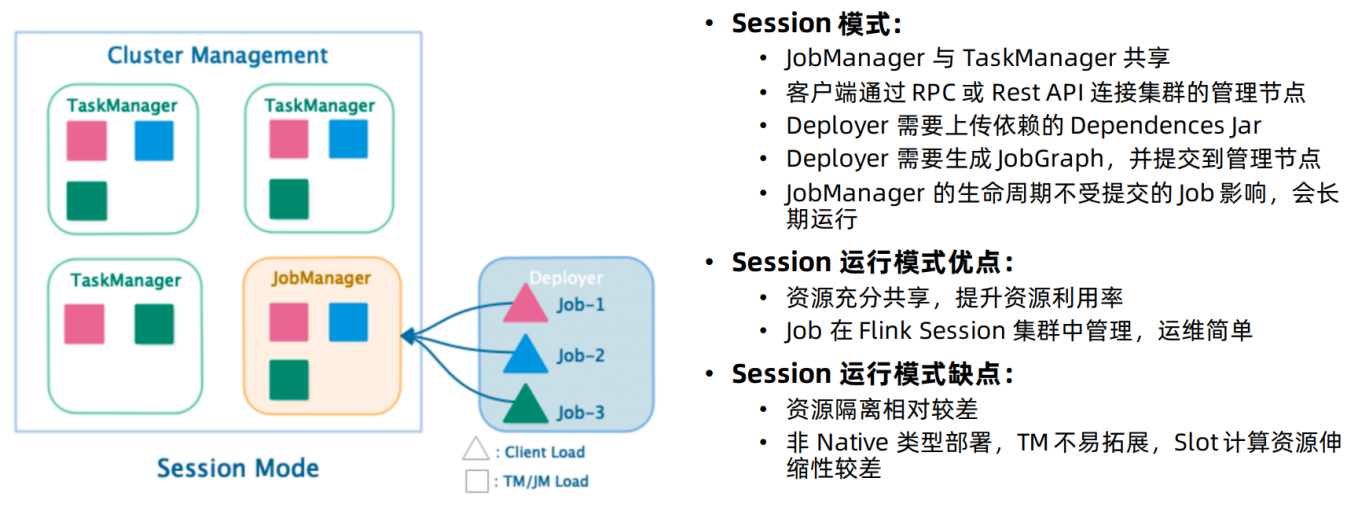 该模式事先申请好资源,并长期运行JobManager和TaskManager。这样的好处就是每次提交作业不需要重新申请资源,缺点也是资源将不会被释放,会一直占用系统资源。
该模式事先申请好资源,并长期运行JobManager和TaskManager。这样的好处就是每次提交作业不需要重新申请资源,缺点也是资源将不会被释放,会一直占用系统资源。
适用场景:作业频繁提交,小作业较多的场景。
PerJob模式
该模式会对每一个Flink任务单独启动一个Flink集群,运行完将会释放,不能被重复使用。结构如下: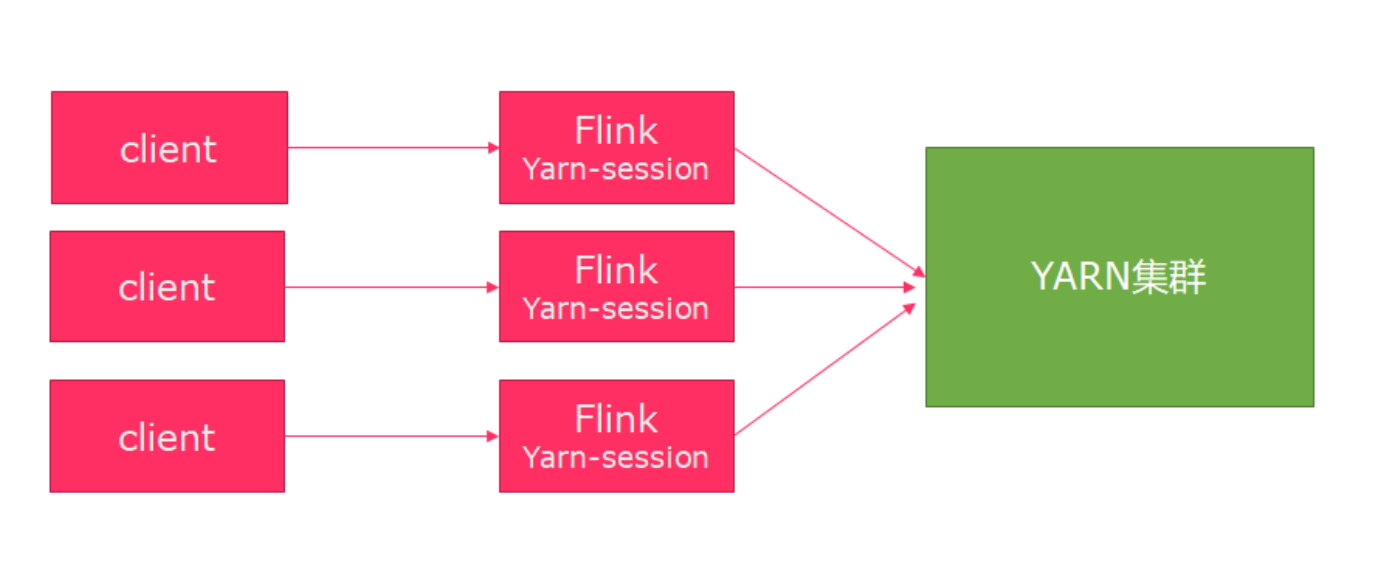
有如下特点: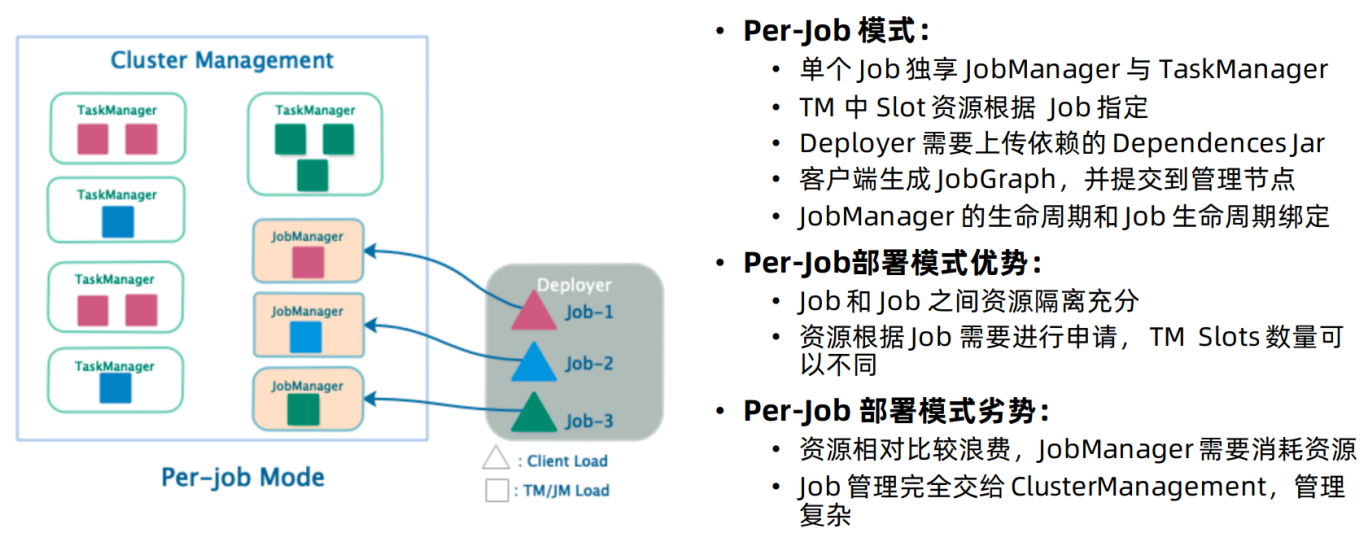
该模式每次提交作业都要重新申请资源,并作业运行完,资源会被释放,这会影响到执行效率,因为资源申请需要消耗时间,但带来的好处就是能够进行资源隔离,并且可以按需申请TM slots数量。
适用场景:作业数量小,大作业较多的场景。实际场景中该方式使用的最多。
部署测试
对于Yarn集群,我们关闭内存检查:
修改yarn-site.xml配置文件
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
上面参数确定是否启动线程来检查每个任务正在使用的虚拟内存量,如果任务超出分配值,会被直接杀掉,默认为true。我们需要关闭,因为flink任务本身会大量使用内存,在yarn模式下很容易超标。
Session会话模式
- 启动Flink session
cd /opt/flink-1.12.0 ./bin/yarn-session.sh -n 2 -tm 800 -s 1 -d上面命令会启动2个cpu,1600m内存的flink集群 -n 2表示申请2个容器启动taskmanager -tm 800 表示每个taskmanager内存为800m -s 1 表示每个taskmanager的slots数量为1 -d 表示后台程序运行
提交运行成功,可以在yarn web UI上看到一个常驻的application:
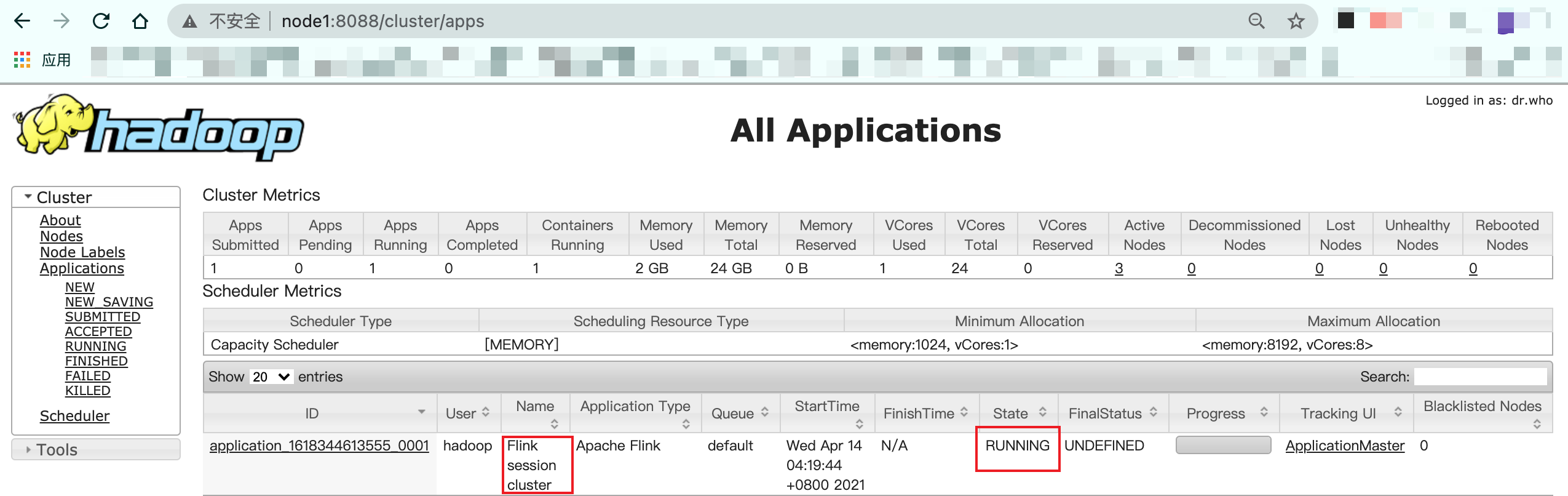
提交任务测试
./bin/flink run examples/batch/WordCount.jar
停止flink集群
yarn application -kill application_1618344613555_0002(appid)Job分离模式
提交Flink Job
./bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 examples/batch/WordCount.jar-m 设置JobManager地址为yarn-cluster,使用YARN执行模式 -yjm 设置jobmanager内存 -ytm 设置taskmanager内存
提交完在yarn UI上可以看到job信息:
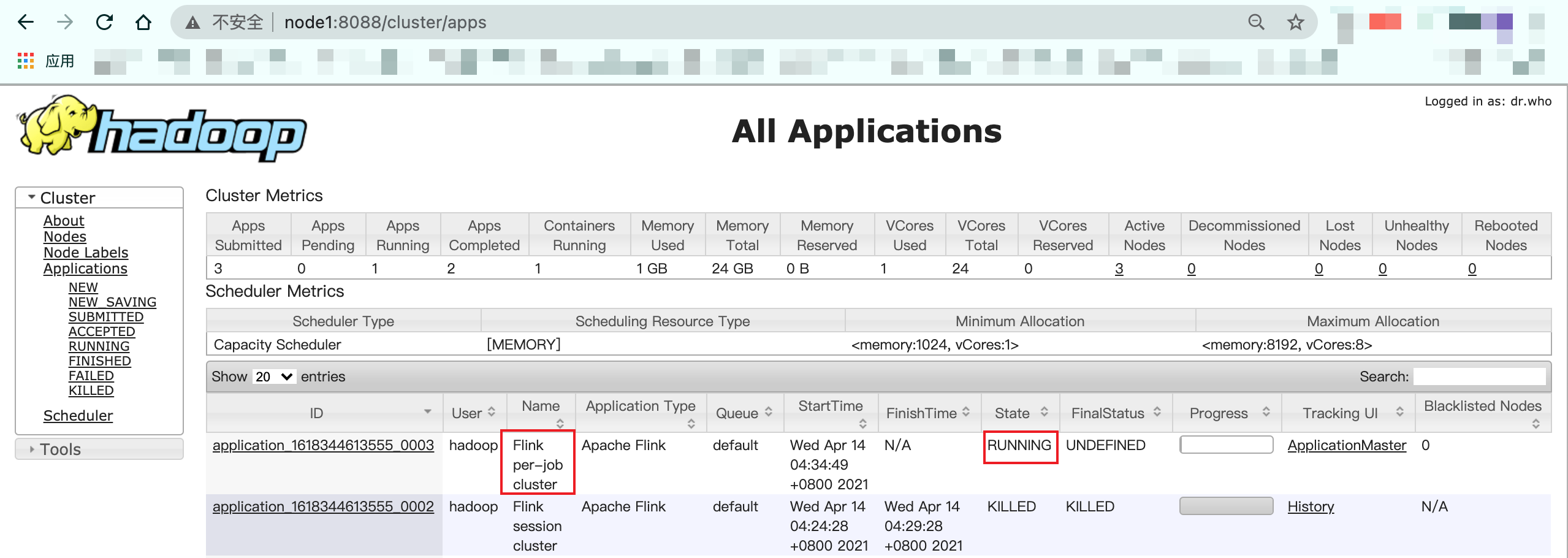

若有收获,就点个赞吧
0 人点赞
