前面文章已经对Spark Catalyset原理做了介绍,这边简单回顾下:
一条SQL的处理过程
Spark在执行SQL会经历如下过程: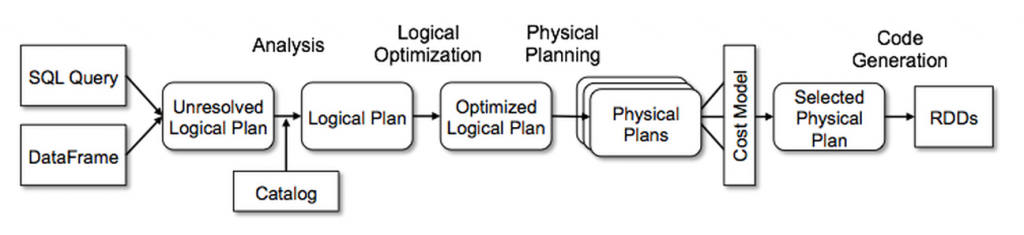
- 首先会通过解析器,将其解析成一个抽象的语法树(AST),这边叫做unresolvedRelation LogicalPlan
- 进入analysis阶段进行规则解析,分为下面几个子阶段:
Hints: 比如BoradcastJoinHints处理Simple Sanity Check: 简单check,比如检查sql中的Function是否存在Substitution: 对sql中的一些进行替换,比如如果union只有一个child则取消unionResolution:对sql中的一些信息进行绑定,变成 Resolved LogicalPlanPost-Hoc Resolution: resolition之后的操作,默认为空,用户可以自己注入- 其他阶段,如:
View、UDF、Subquery等等,所以analysis阶段,不止是resolition。
- 进行optimization阶段:使用Rule对LogicalPlan进行优化,得到Optimized LogicalPlan
- 通过使用
SparkStrategy和Rule将逻辑计划LogicalPlan转换为可执行的物理计划SparkPlan
我们先介绍一下上面提到的 Rule 和 Strategy 。
Rule
每个阶段都有一个执行计划,可以看成是一棵树,树上面的节点是一个 LogicalPlan 或者 SparkPlan 。而 Rule 就是对树上的节点进行transform操作。org.apache.spark.sql.catalyst.rules.Rule 类如下:
abstract class Rule[TreeType <: TreeNode[_]] extends Logging {/** Name for this rule, automatically inferred based on class name. */val ruleName: String = {val className = getClass.getNameif (className endsWith "$") className.dropRight(1) else className}def apply(plan: TreeType): TreeType}
我们看Rule的apply方法,是将一个TreeType转换为TreeType。也就是说,它可以将一个LogicalPlan转化为另一个LogicalPlan,或者将一个SparkPlan转化为另外一个SparkPlan。也就是说Rule不会涉及到质变。
Strategy
Strategy和Rule类似,同样是对树上的节点进行转化操作,但是Strategy是质的改变,它会将一个LogicalPlan转化为一系列SparkPlan。
abstract class GenericStrategy[PhysicalPlan <: TreeNode[PhysicalPlan]] extends Logging {/*** Returns a placeholder for a physical plan that executes `plan`. This placeholder will be* filled in automatically by the QueryPlanner using the other execution strategies that are* available.*/protected def planLater(plan: LogicalPlan): PhysicalPlandef apply(plan: LogicalPlan): Seq[PhysicalPlan]}
Spark Catalyst扩展点
Spark catalyst的扩展点在SPARK-18127中被引入,Spark用户可以在SQL处理的各个阶段扩展自定义实现,非常强大高效,下面我们具体看看其提供的接口和在Spark中的实现。
SparkSessionExtensions
SparkSessionExtensions保存了所有用户自定义的扩展规则,自定义规则保存在成员变量中,对于不同阶段的自定义规则,SparkSessionExtensions提供了不同的接口。
用户自己可以通过SparkSessionExtensions来让扩展Catalyst 中的Rule, Strategy,甚至自己定义解析规则等等。
里面定义了如下几种type:
// 注入一个Ruletype RuleBuilder = SparkSession => Rule[LogicalPlan]// 用于check而已,只是check LogicalPlan,如果不通过,会抛异常,通过则不做任何操作,所以返回类型为Unittype CheckRuleBuilder = SparkSession => LogicalPlan => Unit// 注入一个Strategytype StrategyBuilder = SparkSession => Strategy// 注入一个Parser, 用于语法解析type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
新增自定义规则
用户可以通过 SparkSessionExtensions 提供的inject开头的方法添加新的自定义规则,具体的inject接口如下:
在Analysis阶段的Resolution子阶段添加Rule
/*** Inject an analyzer resolution `Rule` builder into the [[SparkSession]]. These analyzer* rules will be executed as part of the resolution phase of analysis.*/def injectResolutionRule(builder: RuleBuilder): Unit = {resolutionRuleBuilders += builder}
添加Analyzer自定义规则到Resolution阶段,analyzer负责逻辑执行计划生成。这个方法是添加一个Rule用于resolve unResolvedLogicalPlan。只需要自己实现一个Rule,然后使用这个方法进行Rule注入。
在Analysis阶段的Post-Hoc Resolution子阶段添加Rule
/*** Inject an analyzer `Rule` builder into the [[SparkSession]]. These analyzer* rules will be executed after resolution.*/def injectPostHocResolutionRule(builder: RuleBuilder): Unit = {postHocResolutionRuleBuilders += builder
添加Analyzer自定义规则到Post Resolution阶段,会在ResolvedLogicalPlan之后,OptimizedLogicalPlan之前执行。
在Analysis阶段之后对LogicalPlan进行check
/*** Inject an check analysis `Rule` builder into the [[SparkSession]]. The injected rules will* be executed after the analysis phase. A check analysis rule is used to detect problems with a* LogicalPlan and should throw an exception when a problem is found.*/def injectCheckRule(builder: CheckRuleBuilder): Unit = {checkRuleBuilders += builder}
添加Analyzer自定义Check规则,在Analysis阶段之后对LogicalPlan进行check,如果有问题,则抛异常。没问题则检查通过。需要自己实现CheckRuleBuilder。
注入自己的Optimizer Rule
/*** Inject an optimizer `Rule` builder into the [[SparkSession]]. The injected rules will be* executed during the operator optimization batch. An optimizer rule is used to improve the* quality of an analyzed logical plan; these rules should never modify the result of the* LogicalPlan.*/def injectOptimizerRule(builder: RuleBuilder): Unit = {optimizerRules += builder}
添加optimizer自定义规则,optimizer负责逻辑执行计划的优化。
注入自己的Strategy
/*** Inject a planner `Strategy` builder into the [[SparkSession]]. The injected strategy will* be used to convert a `LogicalPlan` into a executable* [[org.apache.spark.sql.execution.SparkPlan]].*/def injectPlannerStrategy(builder: StrategyBuilder): Unit = {plannerStrategyBuilders += builder}
添加planner strategy自定义规则,planner负责物理执行计划的生成。
注入自己的解析器Parser
/*** Inject a custom parser into the [[SparkSession]]. Note that the builder is passed a session* and an initial parser. The latter allows for a user to create a partial parser and to delegate* to the underlying parser for completeness. If a user injects more parsers, then the parsers* are stacked on top of each other.*/def injectParser(builder: ParserBuilder): Unit = {parserBuilders += builder}
添加parser自定义规则,parser负责SQL解析。
SparkSessionExtensions对应每一种自定义规则也都有一个build开头的方法用于获取对应类型的自定义规则,Spark session在初始化的时候,通过这些方法获取自定义规则并传递给parser,analyzer,optimizer以及planner等对象。
Spark Catalyst的SQL处理分成parser,analyzer,optimizer以及planner等多个步骤,其中analyzer,optimizer等步骤内部也分为多个阶段,以Analyzer为例,analyse规则切分到不同的batch中,每个batch的执行策略可能不尽相同,有的只会执行一遍,有的会迭代执行直到满足一定条件。具体每个步骤的每个阶段的具体实现请参考Spark源码。
配置自定义规则
在Spark中,用户自定义的规则可以通过两种方式配置生效:
- SparkSession.Builder中的withExtenstion方法,withExtension方法是一个高阶函数,接收一个自定义函数作为参数,这个自定义函数以SparkSessionExtensions作为参数,用户可以实现这个函数,通过SparkSessionExtensions的inject开头的方法添加用户自定义规则。
- Spark配置参数,具体参数名为spark.sql.extensions。用户可以将1中的自定义函数实现定义为一个类,将完整类名作为参数值。
具体的用法用户可以参考 org.apache.spark.sql.SparkSessionExtensionSuite 测试用例中的Spark代码。
扩展Spark Catalyst实现SQL检查
有场景会使用Spark SQL构建数据分析查询平台,会有许多的业务用户使用这个平台进行数据分析处理,由于业务用户SQL开发能力参差不齐,作为平台方很难约束用户,一个不合理的SQL查询不仅可能导致容易出错,很难维护,可能还会直接搞垮整个平台。
其中SELECT 是一个非常常见的SQL查询方式,用于获取表的所有列数据,但是这种SQL的可维护性相对来说会比较差,表可能增加新列或者删除已有列,甚至列的展示顺序也可能发生变化,这些都会影响SQL执行的结果以及依赖此查询的后续查询。
本例实现简单的SQL检查,发现SELECT 请求就报错,不允许执行。
创建一个自定义Parser
通过集成ParserInterface,实现自定义Parser。
import org.apache.spark.sql.catalyst.{FunctionIdentifier, TableIdentifier}import org.apache.spark.sql.catalyst.analysis.UnresolvedStarimport org.apache.spark.sql.catalyst.expressions.Expressionimport org.apache.spark.sql.catalyst.parser.ParserInterfaceimport org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, Project}import org.apache.spark.sql.types.{DataType, StructType}class StrictParser(parser: ParserInterface) extends ParserInterface {/*** Parse a string to a [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]].*/override def parsePlan(sqlText: String): LogicalPlan = {val logicalPlan = parser.parsePlan(sqlText)logicalPlan transform {case project @ Project(projectList, _) =>projectList.foreach {name =>if (name.isInstanceOf[UnresolvedStar]) {throw new RuntimeException("You must specify your project column set," +" * is not allowed.")}}project}logicalPlan}/*** Parse a string to an [[org.apache.spark.sql.catalyst.expressions.Expression]].*/override def parseExpression(sqlText: String): Expression = parser.parseExpression(sqlText)/*** Parse a string to a [[org.apache.spark.sql.catalyst.TableIdentifier]].*/override def parseTableIdentifier(sqlText: String): TableIdentifier = parser.parseTableIdentifier(sqlText)/*** Parse a string to a [[org.apache.spark.sql.catalyst.FunctionIdentifier]].*/override def parseFunctionIdentifier(sqlText: String): FunctionIdentifier = parser.parseFunctionIdentifier(sqlText)/*** Parse a string to a [[org.apache.spark.sql.types.StructType]]. The passed SQL string should be a comma separated* list of field definitions which will preserve the correct Hive metadata.*/override def parseTableSchema(sqlText: String): StructType = parser.parseTableSchema(sqlText)/*** Parse a string to a [[org.apache.spark.sql.types.DataType]].*/override def parseDataType(sqlText: String): DataType = parser.parseDataType(sqlText)}
创建扩展点函数
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
type ExtensionsBuilder = SparkSessionExtensions => Unit
val parserBuilder: ParserBuilder = (_, parser) => new StrictParser(parser)
val extBuilder: ExtensionsBuilder = { e => e.injectParser(parserBuilder)}
这里面有两个函数,extBuilder函数用于SparkSession构建,SparkSessionExtensions.injectParser函数本身也是一个高阶函数,接收parserBuilder作为参数,将原生parser作为参数传递给自定义的StrictParser,并将StrictParser作为自定义parser插入SparkSessionExtensions中。
在SparkSession中启用自定义Parser
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.master", "local[2]")
.withExtensions(extBuilder)
.getOrCreate()
测试代码
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.master", "local[2]")
.withExtensions(extBuilder)
.getOrCreate()
import spark.implicits._
val df = Seq((1, "zs"), (2, "lisi")).toDF
df.createOrReplaceTempView("person")
spark.sql("select * from person limit 3").show
spark.stop()
执行的结果如下: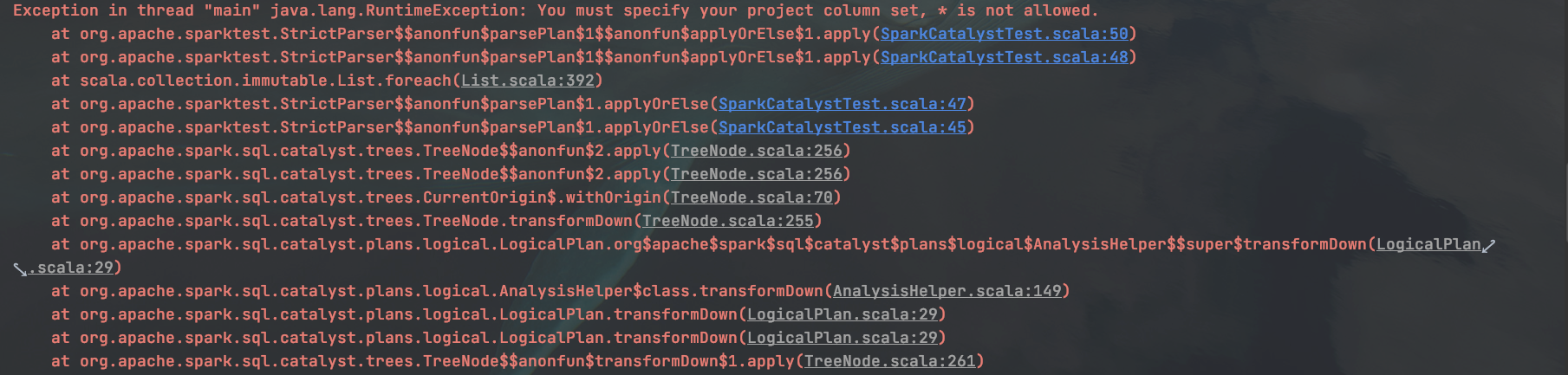

若有收获,就点个赞吧
0 人点赞
