高斯分布在机器学习中占有举足轻重的位置。
假设数据 ,其中
,其中 ,
, ,令参数
,令参数
一维高斯分布
高斯分布的极大似然估计
极大似然估计是频率派常用的参数估计的方法
同时我们已知一元和多元的高斯分布分别为:

为了便于说明,简化一下,只考虑一元的高斯分布,也就是 ,可得:
,可得:
针对 ,
,
令 可得:
可得:
同理针对 ,
,
令 可得:
可得:
这样就求得了两个参数的极大似然估计,其中 分别是无偏估计和有偏估计。
分别是无偏估计和有偏估计。
那如何判断参数的估计是有偏估计还是无偏估计呢?
如果一个变量的期望等于他的理想值,那么就称该变量无偏;否则称为有偏。 即
下面分别来验证一下:
针对 ,
, ,因此
,因此 是无偏的。
是无偏的。
针对 ,
,


已知 ,需要求一下
,需要求一下

将 代入
代入 中得,
中得,
所以是有偏估计。
思考一下这是为什么?
因为样本的均值并不等于期望,除非样本量无穷大时可以近似看作相等,即 ,而样本均值
,而样本均值 本身就是一个随机变量,
本身就是一个随机变量, ,根据
,根据 式计算的有偏估计为
式计算的有偏估计为 而真正的无偏估计为:
而真正的无偏估计为:
为什么分母是 就变成无偏估计了?
就变成无偏估计了?
真正的无偏估计
可以明显发现, ,另外
,另外 ,为了逼近真正的无偏估计的方差,所以在前面乘以
,为了逼近真正的无偏估计的方差,所以在前面乘以 ,最后分母就变成了。
,最后分母就变成了。
多维高斯分布
正如式 所示,高维的高斯分布为
所示,高维的高斯分布为  ,
,
假设  ,
, 为协方差矩阵。
为协方差矩阵。
不妨令 , 它是一个二次型,其实
, 它是一个二次型,其实 是向量
是向量 与向量
与向量 之间的马氏距离
之间的马氏距离
关于马氏距离简单提一下:
马氏距离是印度统计学家提出来的,表示数据的协方差距离,一种有效计算两个未知样本相似度的方法。与欧式距离不同的是,马氏距离考虑到各种特性之间的联系。 两个向量之间的马氏距离为:

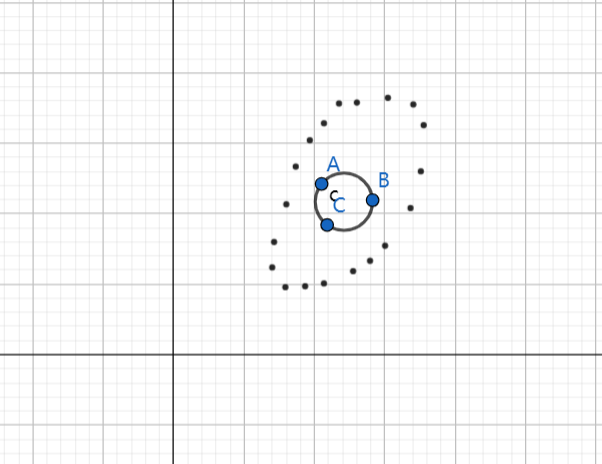
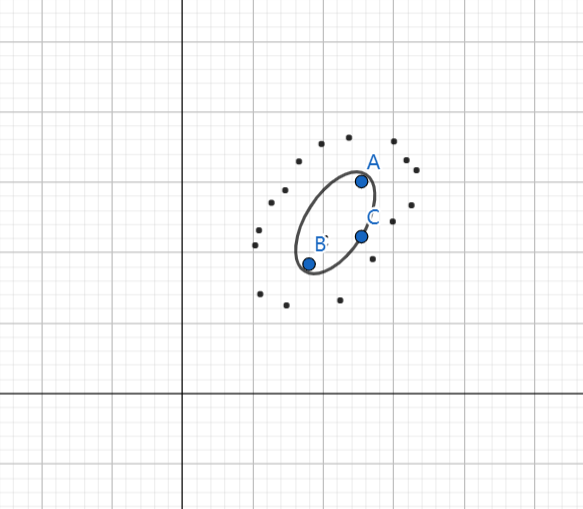
A和B有相同的欧式距离 A和B有相同的马氏距离
在中,如果 ,
, 就是欧氏距离了。
就是欧氏距离了。
注:此处的协方差矩阵一般而言是半正定矩阵,此处只考虑正定矩阵。是对称矩阵,对其进行特征值分解: ,其中
,其中

则进一步可以得到 :
:
将其带入 得:
得:
为了便于解释,不妨设 ,则
,则  ,其中
,其中
假如此时令 ,可以发现这是一个圆锥曲线,
,可以发现这是一个圆锥曲线, 就是向量
就是向量 在特征向量
在特征向量 上的投影,对于不同的
上的投影,对于不同的 ,就会对应不同的同心椭圆,假如特征值
,就会对应不同的同心椭圆,假如特征值 都是常数的话,就会变成同心圆。
都是常数的话,就会变成同心圆。
高斯分布的一个重要特性:如果两组随机变量的联合分布是高斯的,那么已知一组随机变量的条件下,另一组随机变量也是高斯分布;同样,任意一组随机变量的边缘分布也是高斯的。用数学语言表示就是如果 是两组随机变量,如果
是两组随机变量,如果 服从联合高斯分布,则
服从联合高斯分布,则 也服从高斯分布,
也服从高斯分布, 也服从高斯分布。
也服从高斯分布。
多维高斯分布为: ,对于指数项,可以进一步化简为:
,对于指数项,可以进一步化简为: ,其中
,其中 为常量。
为常量。
这就意味着如果能找到一个高斯分布指数项的二次部分和一次部分就能求得这个分布的期望和方差,进而求得这个高斯分布。
已知联合高斯分布求条件分布和边缘概率分布
假设 ,将
,将 拆成两部分即
拆成两部分即 ,那么
,那么 ,其中
,其中 。
。
为了保持简洁,常常使用精度矩阵(Precision matrix),其定义为协方差矩阵的逆。 ,其中
,其中
求条件分布
如果已知 ,求
,求 的分布,也就是求
的分布,也就是求 。
。
由于联合分布是高斯分布,所以两个边缘分布和条件分布也都是高斯分布,因此也就是求期望 和协方差矩阵
和协方差矩阵 。
。
经过复杂的计算推导可得:

 的分布,也就是求
的分布,也就是求 。
。

求边缘概率分布
已知 的联合概率分布,求边缘概率分布
的联合概率分布,求边缘概率分布 。
。
经过复杂的计算推导可得:

同理已知的联合概率分布,求边缘概率分布 。
。
经过复杂的计算推导可得:

计算过程中用到了分块矩阵的逆矩阵:
其中
 ,便可以得到一一对应的关系。
,便可以得到一一对应的关系。
高斯分布的贝叶斯定理
已知一个多维随机变量 ,另外一个多维随机变量
,另外一个多维随机变量 在
在 已知的条件也服从高斯分布,且均值为的线性变换,即
已知的条件也服从高斯分布,且均值为的线性变换,即 ,其中
,其中 为精度矩阵。
为精度矩阵。
这是一个线性高斯的一个例子,该问题所求为边缘分布 和的后验分布
和的后验分布 。
。
思路先定义 求求联合分布
求求联合分布 ,根据前面已知联合高斯分布求条件分布和边缘概率分布,进而求解。
,根据前面已知联合高斯分布求条件分布和边缘概率分布,进而求解。
最后求得:





以上推导十分复杂,需要具备良好的线性代数基础,若需完成的数学推导过程,请看下面这篇博客:
由于这篇博客推导十分详细清楚,故此此处也就不再做重复工作了。
高斯分布的局限性
- 参数太多。
协方差矩阵是 的,由于其实对称矩阵,那么实际上参数有
的,由于其实对称矩阵,那么实际上参数有 个,为了降低参数量,假设为对角矩阵
个,为了降低参数量,假设为对角矩阵 ,相关的算法有因子分析(factor analysis)等,甚至令特征值
,相关的算法有因子分析(factor analysis)等,甚至令特征值 都相等,这种情况称为各同向性,相关算法有概率PCA(p-PCA)。
都相等,这种情况称为各同向性,相关算法有概率PCA(p-PCA)。
- 其本身的局限性。它本质上单峰的,一个高斯分布难以很好的刻画数据的分布,此时需要用到多个高斯分布,即混合高斯分布GMM。
参考


若有收获,就点个赞吧
0 人点赞
