Node中的模块机制

1.2 请介绍一下require的模块加载机制
这道题基本上就可以了解到面试者对Node模块机制的了解程度 基本上面试提到
- 1、先计算模块路径
- 2、如果模块在缓存里面,取出缓存
- 3、加载模块
4、输出模块的exports属性即可 ```javascript // require 其实内部调用 Module._load 方法 Module._load = function(request, parent, isMain) { // 计算绝对路径 var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存 var cachedModule = Module._cache[filename]; if (cachedModule) { return cachedModule.exports;
// 第二步:是否为内置模块 if (NativeModule.exists(filename)) { return NativeModule.require(filename); }
/**这里注意了**/ // 第三步:生成模块实例,存入缓存 // 这里的Module就是我们上面的1.1定义的Module var module = new Module(filename, parent); Module._cache[filename] = module;
/**这里注意了**/ // 第四步:加载模块 // 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load try { module.load(filename); hadException = false; } finally { if (hadException) {
delete Module._cache[filename];
} }
// 第五步:输出模块的exports属性 return module.exports; };
<a name="ulUX4"></a># module.exports与exports,export与export default之间的关系和区别首先我们要明白一个前提,CommonJS模块规范和ES6模块规范完全是两种不同的概念。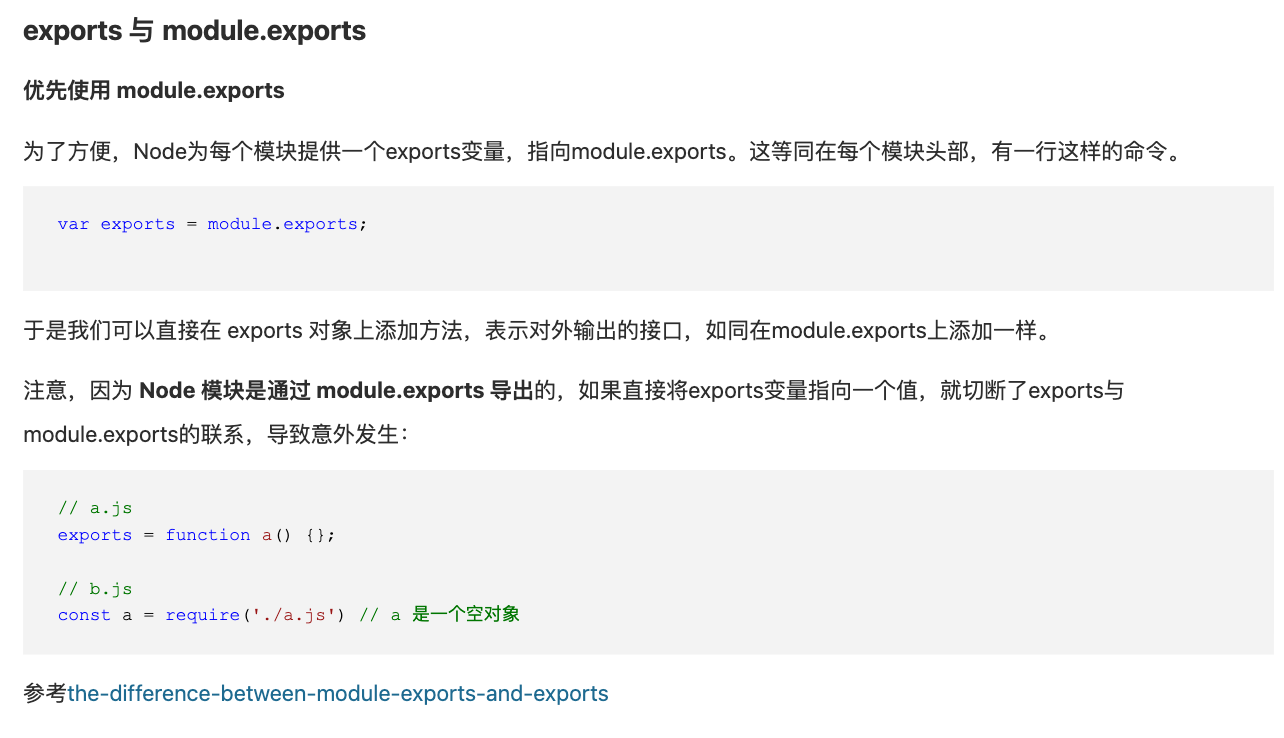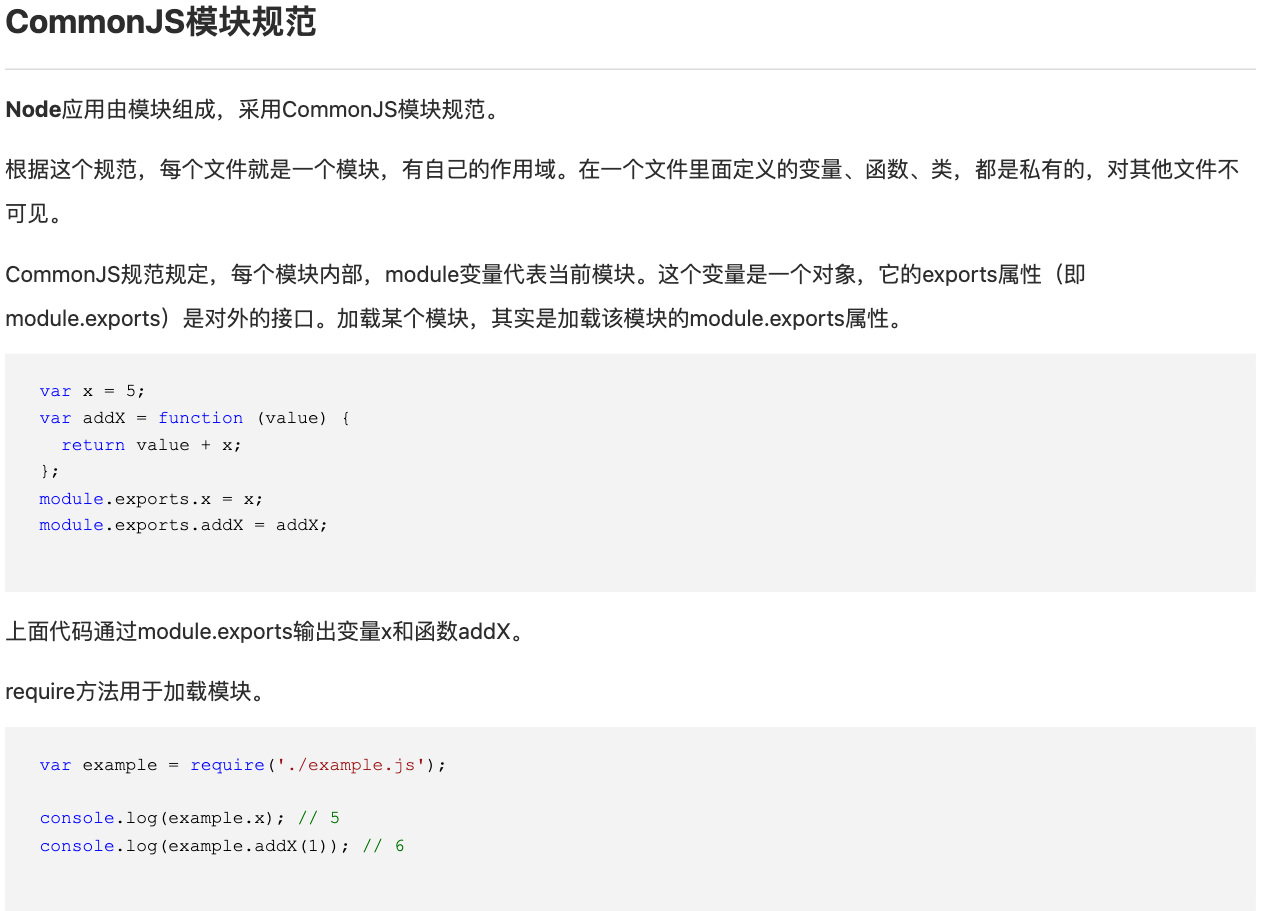```javascriptmodule.exports vs exports很多时候,你会看到,在Node环境中,有两种方法可以在一个模块中输出变量:方法一:对module.exports赋值:// hello.jsfunction hello() {console.log('Hello, world!');}function greet(name) {console.log('Hello, ' + name + '!');}module.exports = {hello: hello,greet: greet};方法二:直接使用exports:// hello.jsfunction hello() {console.log('Hello, world!');}function greet(name) {console.log('Hello, ' + name + '!');}function hello() {console.log('Hello, world!');}exports.hello = hello;exports.greet = greet;但是你不可以直接对exports赋值:// 代码可以执行,但是模块并没有输出任何变量:exports = {hello: hello,greet: greet};如果你对上面的写法感到十分困惑,不要着急,我们来分析Node的加载机制:首先,Node会把整个待加载的hello.js文件放入一个包装函数load中执行。在执行这个load()函数前,Node准备好了module变量:var module = {id: 'hello',exports: {}};load()函数最终返回module.exports:var load = function (exports, module) {// hello.js的文件内容...// load函数返回:return module.exports;};var exportes = load(module.exports, module);也就是说,默认情况下,Node准备的exports变量和module.exports变量实际上是同一个变量,并且初始化为空对象{},于是,我们可以写:exports.foo = function () { return 'foo'; };exports.bar = function () { return 'bar'; };也可以写:module.exports.foo = function () { return 'foo'; };module.exports.bar = function () { return 'bar'; };换句话说,Node默认给你准备了一个空对象{},这样你可以直接往里面加东西。但是,如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:module.exports = function () { return 'foo'; };给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。结论如果要输出一个键值对象{},可以利用exports这个已存在的空对象{},并继续在上面添加新的键值;如果要输出一个函数或数组,必须直接对module.exports对象赋值。所以我们可以得出结论:直接对module.exports赋值,可以应对任何情况:module.exports = {foo: function () { return 'foo'; }};或者:module.exports = function () { return 'foo'; };最终,我们强烈建议使用module.exports = xxx的方式来输出模块变量,这样,你只需要记忆一种方法。

垃圾回收
计算机的动态内存不再需要的时候就应该释放,让出内存。
- 引用计数
let user={name:"simple"}//现在user就引用了{name:"simple"}这个对象user=null;//现在{name:"simple"}变成不可到达的了,不能访问,JS就会回收他//若是let user={name:"simple"}let admin=usr;//现在{name:"simple"}就被两个对象引用user=null;//即使执行这个,{name:"simple"}还可以通过admin获取,故未被回收//循环引用问题function func() {let obj1 = {};let obj2 = {};obj1.a = obj2; // obj1 引用 obj2obj2.a = obj1; // obj2 引用 obj1}// 当函数 func 执行结束后,返回值为 undefined,所以整个函数以及内部的变量都应该被回收,但根据引用计数方法,obj1 和 obj2 的引用次数都不为 0,所以他们不会被回收。// 要解决循环引用的问题,最好是在不使用它们的时候手工将它们设为空。上面的例子可以这么做:obj1 = null;obj2 = null;
- 标记清除
解决引用计数解决不了的问题的,就是无法清除循环引用,标记清除分为标记与清除两个阶段,首先遍历所有数据,将能可达或者间接可达的数据标记存活,然后再清理没有标记的数据,这样就完成一次清理,一般都是引用计数为主,标记清除为辅,来清除垃圾
- 新老生代 新生代(scavenge算法) 老生代(标记清除)
各种实例对象存放在堆中,然后堆又划分成了两个不同的区域 年轻代(新生代区、from区、to区)和年老代新建的对象总是在新生代存放在新生代区中,当新生代区已经满了,就会触发一次垃圾回收(Garbage Collection)。将新生代中还未被使用的对象(存活的对象)复制到From区,当新生代区空间再次满,会触发一次GC,就会将新生代区和from区的未使用对象复制到To区下一次垃圾回收会将to区和新生代区的未使用对象复制到from区,这样某些对象就会在from和to区多次复制,如果超过某个阈值对象还没有被释放的话,就将改对象复制到老年代区当一个对象经过多次复制依然存活的时候,他会被认为是生命周期比较长的对象,会被移动到老生代中. 从新生代移动到老生代的过程称为晋升
scavenge只复制存活的对象,而标记清除只清除死亡的对象,活对象在新生代中占比较小,死对象在老生代中占比较小。
- node内存限制
由于V8内存限制,无法通过fs.readFile和fs.writeFile进行大文件的操作,从而改用fs.createReadStream和fs.createWriteStream通过流的方式实现对大文件的操作1.加载和执行
浏览器在执行JavaScript代码的时候,不能做其他任何事情.JavaScript 执行过程耗时越久,浏览器等待响应用户输入的时间就越长。
这意味着 script 标签每次出现都霸道地让页面等待脚本的解析和执行。无论当前的JavaScript代码是内嵌的还是包含在外链文件中,页面的下载和渲染都必须停下来等待脚本执行完成
- 性能问题
将script标签放在head中,或者放到body的前面,会导致脚本阻塞页面的渲染
- 浏览器厂商的解决
允许并行下载JavaScript,但是JavaScript的下载过程任然会阻塞其他资源的下载,比如图片尽管脚本下载过程不会互相影响,但是页面仍然要等待所有JavaScript代码下载完成之后才能继续
- 解决方案
1. 将script标签放在body的后面2. 将多个脚本合并成一个脚本.考虑到HTTP请求会带来额外的性能开销,因此下载单个100KB的文件将比下载4个25KB的文件更快。也就是说,减少页面中外链脚本文件的数量将会改善性能3. 减小JavaScript文件大小 压缩 uglyify 不必要的空格注释等等4. defer属性,在解析到JavaScript标签的时候开始下载,但是不会执行,直到DOM加载完成才执行

若有收获,就点个赞吧
0 人点赞
