摘要
摘要:In this paper,we introduce and compare different approaches for incorporating shape prior information into neural network-based image segmentation. Specifically, we introduce the concept of template transformer networks, where a shape template is deformed to match the underlying structure of interest through an end-to-end trained spatial transformer network. This has the advantage of explicitly enforcing shape priors, and this is free of discretization artifacts by providing a soft partial volume segmentation. We also introduce a simple yet effective way of incorporating priors in the state-of-the-art pixel-wise binary classification methods such as fully convolutional networks and U-net. Here, the template shape is given as an additional input channel, incorporating this information significantly reduces false positives. We report results on synthetic data and sub-voxel segmentation of coronary lumen structures in cardiac computed tomography showing the benefit of incorporating priors in neural network-based image segmentation.
本文提出了一种基于神经网络的模板变换网络TTN,TTN基本原理是通过变形一个形状模板通过STN网络来匹配感兴趣的底层结构,具有显式强制形状先验的优点,通过提供柔和部分体积分割【?】消除离散化伪影。
简介
介绍形状先验的意义:
引入形状先验可以极大地改善解剖结构的分类,对于数据不明确、损坏或信噪比低、稀缺等情况,引入形状先验具有重要意义。
分析以往分割工作的不足:
- 以往的一些采用deformable templates的方法将图像配准和shape templates结合进行分割,随后和解剖图谱结合实现不同器官的分割,然而这些方法需要image to image的似然函数来驱动变形模型的图谱配准,首先在构造形状模型上就存在困难,然后由于潜在流形学习方法(linear of non-linear PCA),形状模型的表达经常受到限制。
- 目前最先进的基于神经网络的模型通常优化像素级损失函数,例如MSE,CE和可微的Dice系数等,这些损失函数在训练中不考虑明确的先验。
- 通过在训练过程中学习先验来正则化神经网络的embedding可能会导致支持合理分割的网络,无法保证输出复合所需的形状约束,例如一些封闭的曲面。
贡献:
- 提出TTN网络:基于STN网络,本文的模型利用神经网络的表示能力,同时通过限制模型通过预先给定形状先验的变形执行分割,在分割中显式强制形状约束。
- 通过调整deformation field[?]来产生解剖学上合理的结果,因为不限制网络进行像素分类所以避免了离散化伪影。
- 不需要其他模板变形模型的图像分割配准测量。
- 在训练过程中提供形状模板作为额外输入,并证明state of the art分割算法可以很容易地扩展到包含隐式先验【描述见下图】。
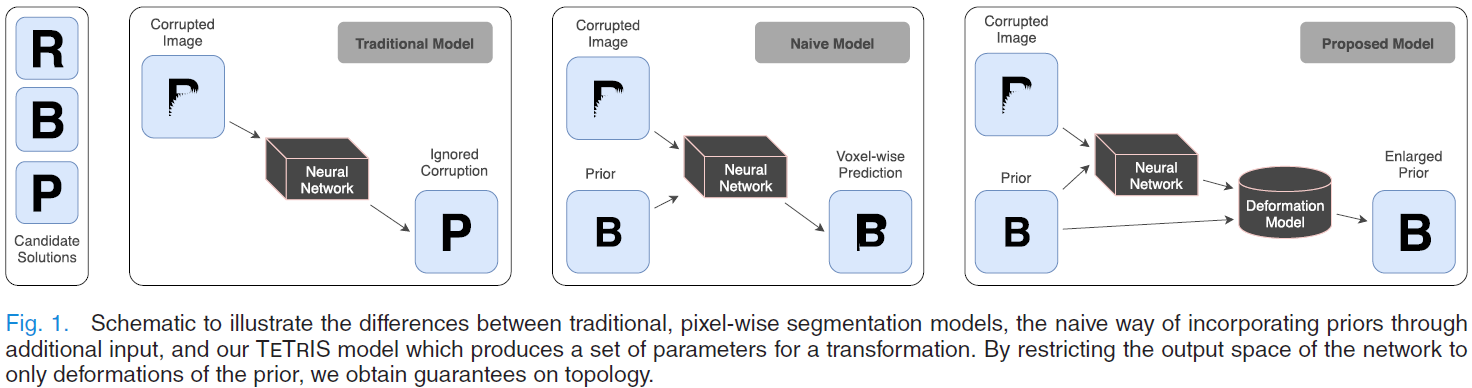
相关工作
① 基于地图集和配准的图像分割
基于地图集的分割算法通常依赖图像匹配项![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图2](/uploads/projects/siena0706@bhxtqf/3c916d2bdb8e05fa4bcaab683a59d95a.svg) 和一堆训练样本[即附有对应标签的地图集]。在测试过程中,可以使用将图像与图集数据集中的实例进行比较,并选择最相似的图集的标签掩码作为候选分割结果。然而,这种方法提供的分割结果是粗糙的,通过线性或非线性配准进行改进。
和一堆训练样本[即附有对应标签的地图集]。在测试过程中,可以使用将图像与图集数据集中的实例进行比较,并选择最相似的图集的标签掩码作为候选分割结果。然而,这种方法提供的分割结果是粗糙的,通过线性或非线性配准进行改进。
② 统计形状模型
③ 基于网络的图像配准
传统配准算法拍摄两张图像,移动的![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图4](/uploads/projects/siena0706@bhxtqf/dc40faf04c6a9864cbc65c9b379b85e1.svg) 和固定的
和固定的![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图5](/uploads/projects/siena0706@bhxtqf/63d9dfe475778bbf8c791d28d9441901.svg) ,通过迭代更新一些参数化变换
,通过迭代更新一些参数化变换![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图6](/uploads/projects/siena0706@bhxtqf/2a977fc320912eb9c44fda9f188be65d.svg) 【网格位置相互映射】来执行配准。从而使得某些损失参数
【网格位置相互映射】来执行配准。从而使得某些损失参数![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图7](/uploads/projects/siena0706@bhxtqf/b78eb09eba9b2a5c67eddeefd1424a0a.svg) 最小,在
最小,在![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图8](/uploads/projects/siena0706@bhxtqf/da500bd69c09f8269b120cfdf9ecc492.svg) 。优化这种算法可以看做是优化
。优化这种算法可以看做是优化![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图9](/uploads/projects/siena0706@bhxtqf/af556754c0b6bdc19b7e67699bf0d2ba.svg) 。基于神经网络的图像配准与传统的迭代配准算法的关键区别在于,只在神经网络的训练过程中计算损失函数。神经网络的参数隐式编码什么变换,条件下的输入,需要配准图像的最小代价,而不是重复计算损失迭代更新参数。
。基于神经网络的图像配准与传统的迭代配准算法的关键区别在于,只在神经网络的训练过程中计算损失函数。神经网络的参数隐式编码什么变换,条件下的输入,需要配准图像的最小代价,而不是重复计算损失迭代更新参数。
④ 神经网络中的形状先验
尽管条件随机场被认为是平滑先验,但是他们确实有助于在分割中提供形状一致性。
⑤ 空间转换网络STN
STN是一种神经网络模型,在给定输入 I 的条件下,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图11](/uploads/projects/siena0706@bhxtqf/49659eb9dec12cad3ed62cdcff76e9e9.svg) 的参数转换模型返回参数,也就是
的参数转换模型返回参数,也就是![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图13](/uploads/projects/siena0706@bhxtqf/1947a038b83398d406befa05cf4cad6a.svg) ,
,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图14](/uploads/projects/siena0706@bhxtqf/5f408f1db06b0e3ac6ff5babdbc1e823.svg) 是一个神经网络,
是一个神经网络,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图15](/uploads/projects/siena0706@bhxtqf/54f148e5a94a31da5f1b0cdd94f00f89.svg) 是其参数。一旦我们拥有参数,我们就可以使用对图像 I 到 V 做可区分的重采样。然后STN将重采样的图片 V 传递给另外一个网络,
是其参数。一旦我们拥有参数,我们就可以使用对图像 I 到 V 做可区分的重采样。然后STN将重采样的图片 V 传递给另外一个网络,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图18](/uploads/projects/siena0706@bhxtqf/58fd8b0d551face87afb9fc4138f8326.svg) 执行一些下游任务。在[15]中,他们使用这个有力的模型训练
执行一些下游任务。在[15]中,他们使用这个有力的模型训练![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图19](/uploads/projects/siena0706@bhxtqf/405d343f8ae1a5adf3e3fea78b0aa404.svg) ,该算法同时执行分类任务和训练变形模型,通过缩放、兴趣区域提取和旋转输入图像的组合使down stream task更容易。【what means down stream?】
,该算法同时执行分类任务和训练变形模型,通过缩放、兴趣区域提取和旋转输入图像的组合使down stream task更容易。【what means down stream?】
在训练过程中,loss只在down stream task中进行计算,对于分类来说,这可能是由产生的预测类和真实类之间的交叉熵损失。由于神经网络是一个可微函数,并且从 I 到 V 的采样也是可微的,因此我们可以把这两个任务进行端到端的训练。本质上,STN是进行变形来辅助down stream task,而不是在deforming task上直接计算损失。这可以认为是一个隐式的配准步骤,其中配准是由网络自主发现的optimal downstream performance。
在测试过程中,与迭代配准模型不同,不需要计算损失值。我们只需要通过网络进行一次向前传递,就可以得到变形和类预测。
网络结构
传统模板变形模型需要定义图像到分割匹配函数作为分割目标的近似或替代。然后使用迭代优化来增量更新转换参数,以最大限度地提高模板和待分割图像之间的一致性。相比之下,我们的方法使用了基于网络的配准,再训练的时候只需要计算相应的损失函数(相当于匹配函数),这一重要区别意味着我们不再需要通过基于强度的代理近似我们的实际分割函数,可以直接优化现有的任务。
我们引入了一种新的Template Transformer Network,利用了基于神经网络的配准能力。该端到端模型以部分体积图像(PVI)的形式进行形状先验,并将图像作为输入传给神经网络,神经网络学习变形输入先验,产生对输入图像的分割结果。这是通过隐式估计一个deformation field来实现的,从而使模板对齐达到最佳的分割精度。我们在下面提供了对主要步骤的详细描述。我们的方法概述如图2所示。在下面的小节(II-B, II-C和II-D)中,我们将详细描述如何执行变形,如何正则化变形场,以及如何处理大体积尺寸。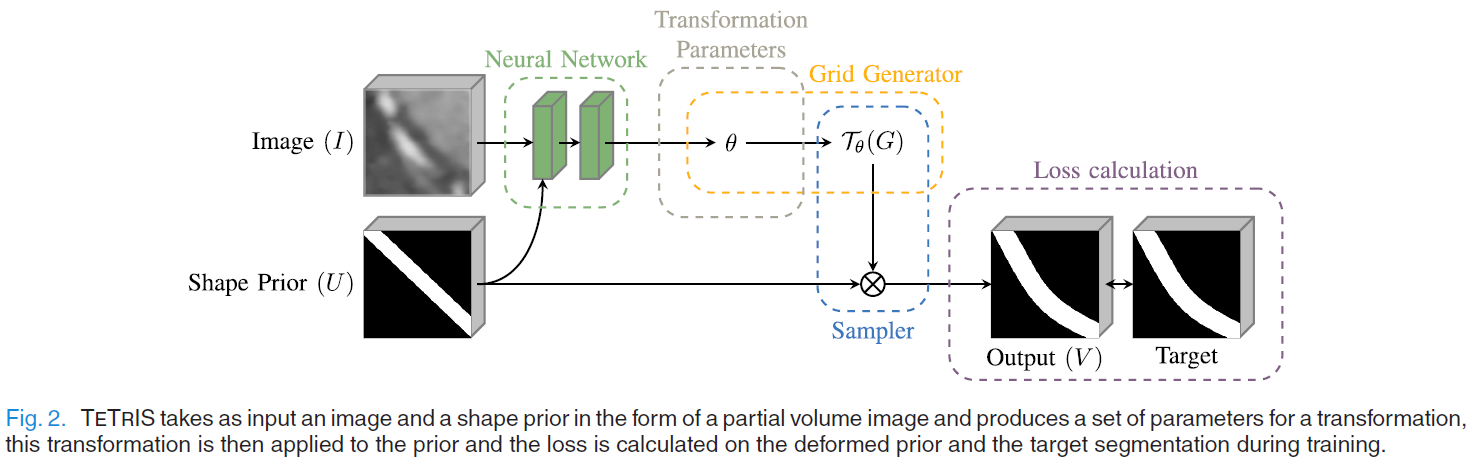
A. Obtaining Shape Templates
形状先验可以以各种形式应用于神经网络,如水平集、PVIs、二进制掩模或形状参数(如网格控制点)。在这项工作中,我们集中在使用变形模型,条件是一个形状之前,将一个PVI变形为另一个PVI。在这种特殊情况下,我们的形状先验本身也是一个PVI,但我们强调这不是必要的,更丰富的先验,如统计外观模型也可以使用。由于模板传输网络预测转换而不是点分割映射,它们自然能够使用其他几何表示先验的能力,如基于网格的模型。形状先验一般可以通过手动、半自动和自动三种方法来获得,具体的机理是根据具体应用而定的。稍后我们将讨论一种特殊的方法来获得形状先验的应用冠状动脉分割。
B. Deformation Model
为了变形一个模板,需要考虑一些输入图像![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图23](/uploads/projects/siena0706@bhxtqf/4476b1b0ee675591d743d08d1a739c15.svg) ,以及形状先验
,以及形状先验![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图24](/uploads/projects/siena0706@bhxtqf/86633d6af6400432ca7abd3e9a189f7e.svg) ,Ground Truth分割标签
,Ground Truth分割标签![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图25](/uploads/projects/siena0706@bhxtqf/b4abc8bb750958445f3fb4e6bbdb7148.svg) ,
,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图26](/uploads/projects/siena0706@bhxtqf/02ae70d9bc6b3b332dde7cf0167ace5e.svg) 均为
均为![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图27](/uploads/projects/siena0706@bhxtqf/fcb409582435bbe8bb7ff551f52042e7.svg) 的图像。
的图像。
采样方法(变形模型),![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图29](/uploads/projects/siena0706@bhxtqf/d41210b8a9f64bdab494ff76bb252e0d.svg) 是一个标准的坐标格网,损失函数为。
是一个标准的坐标格网,损失函数为。
是一个关于 ![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图32](/uploads/projects/siena0706@bhxtqf/142e22c9023e09d340351c79b3b28194.svg) [即目标空间的坐标格网]的函数,映射至源空间
[即目标空间的坐标格网]的函数,映射至源空间 ![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图33](/uploads/projects/siena0706@bhxtqf/5cb05e108b3e7eefc307eba2730b2e3b.svg) 。其中i∈[1,…,H’W’D’],给定这些,我们就可以定义V,基于 ,对先验U的重采样。
。其中i∈[1,…,H’W’D’],给定这些,我们就可以定义V,基于 ,对先验U的重采样。
STN:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图35](/uploads/projects/siena0706@bhxtqf/5b8d48388f6c3405ff38db4e4872ea65.svg)
TTN:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图36](/uploads/projects/siena0706@bhxtqf/1449dbd97f195531414fbb3dece3b599.svg)
k是带任意参数 ![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图37](/uploads/projects/siena0706@bhxtqf/d7f561cefa07d2b1653bdab7a83b0678.svg) 的采样核。对于图像插值,我们使用一个三线性核来防止重新采样的像素值被外推到原始强度域之外,
的采样核。对于图像插值,我们使用一个三线性核来防止重新采样的像素值被外推到原始强度域之外,
STN:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图38](/uploads/projects/siena0706@bhxtqf/ab1bd9a5206c530bc5aa0245ec6d2b0f.svg)
TTN:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图39](/uploads/projects/siena0706@bhxtqf/2a9490ed6b780b35869b0f35e4798a73.svg)
我们选择 作为一个自由变形形状, 是一个三维向量场。
为了简化符号,我们定义采样网格函数为:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图42](/uploads/projects/siena0706@bhxtqf/391d32b77d58f280d958907bb7daf1e0.svg)
如果 一个与目标图像分辨率不同的自由变形,我们就需要对变形场重新采样。
可能使用一组不同的采样内核k及其自己的参数 。为了确保平缓场,采用B-Spline 插值,使用Catmull-Rom方法解决插值问题。
我们的灵感来源于STNs,使用神经网络 ![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图45](/uploads/projects/siena0706@bhxtqf/8b0c66d5cd04092f8640b50ee4a37e46.svg) 去生成B-Spline变换模型 的参数 , 然后可以对先验U进行变形,计算分割损失之后更新网络的参数 。
去生成B-Spline变换模型 的参数 , 然后可以对先验U进行变形,计算分割损失之后更新网络的参数 。
通过将模板变形与神经网络相结合,解决了传统模板变形模型需要手工制作一幅好的图像来实现分割对齐的关键问题。与任何配准技术一样,这一问题的根源在于必须在测试期间进行损失计算,以更新变形场参数 。利用STNs在测试时产生 ,在训练时用神经网络来代替 的更新,我们可以训练一个带有真分割损失函数的配准模型(基于先验分割和参考分割之间的对齐),从而避免在测试时使用替代函数。
模板变形模型与网络无关,因此可以使用任何神经网络。 我们选择具有卷积和最大池的简单前馈网络体系结构,以产生变形场,该变形场在STN中用于使先验变形。 其全部细节在图3和12。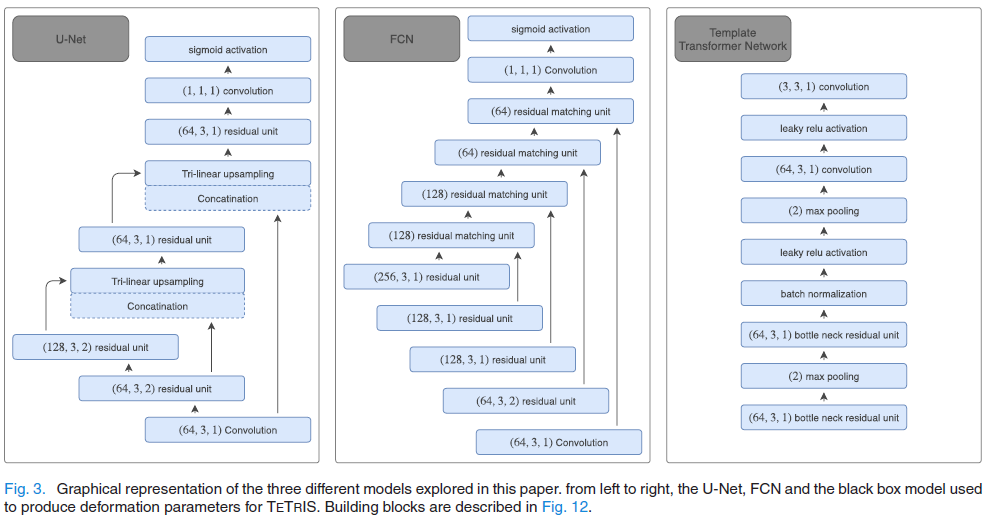
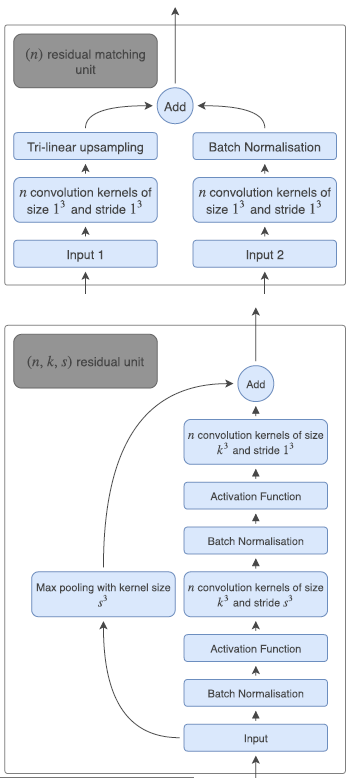
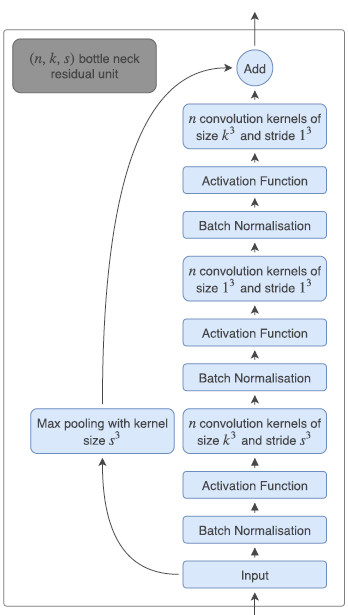
与其他基于神经网络的分割算法不同的是,我们的方法可以先采取任何形状,并以亚像素精度进行变形,而其他基于神经网络的分割算法通常将分割视为像素级分类。由于我们的模型平滑地提前变形,我们能够产生部分体积分割,减少最终分割地图中的离散工件。我们提供了部分体积数据和体素分类结果的实验。
C. Field Regularization
由于配准问题的不适定性质,通常通过在优化问题中添加正则化项来约束变形场,这有利于一些期望的性质,如局部光滑变形,或向量场本身的l2惩罚,以支持最小位移解。我们研究两个正规化项![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图55](/uploads/projects/siena0706@bhxtqf/efa8c150dba7f6161154a2d3c8a227df.svg)
和![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图56](/uploads/projects/siena0706@bhxtqf/fe7826e6bab47ca1d1d487600f1f8959.svg)
![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图57](/uploads/projects/siena0706@bhxtqf/6daa01ceb527bc528fdc7d85673f28a1.svg) 惩罚场的l2项,
惩罚场的l2项,![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图58](/uploads/projects/siena0706@bhxtqf/7a2dcacf3188eaa2ab6d600aa2eee5c6.svg) 惩罚二阶导数的平方和。
惩罚二阶导数的平方和。
D. Field Aggregation
为了处理数据的大小和现代图形处理单元的内存限制,我们以补丁为基础进行推断,我们收集了补丁之间的控制点,并在使用B样条插值进行重新采样之前对其进行汇总。 这与仅使用有效填充相结合,可防止在整个图像上出现不适定的边界条件。 这也使我们能够在不更改神经网络的情况下,以一致的控制点间距对可变大小的体积执行推理。
模型训练细节
我们使用两个基线模型来比较我们提出的三个模型:1)残差全卷积网络(FCN)和2)残差U-net架构,利用[45]的实现,使用[46]的残差块。架构的细节可以在图3中找到,在图12中描述了构建模块。
我们还展示了将形状先验简单地整合到这些最先进的模型中的结果。我们通过向网络输入两个通道来实现这一点,一个是要分割的图像,另一个是我们在那个位置的图像的先验信息。这种替代方法是现有最先进像素方法的简单扩展,计算成本低,易于实现。在这种情况下,先前的形状充当了网络输出的一种初始化。
对于所有模型,我们都是用了相同的patch提取参数,在训练期间,我们从每个卷中动态提取32个patch,并随机将他们放入一个512个不定的缓冲区中。如果patch靠近中心线则进行提取,使得围绕血管的采样进行偏移。我们对所有模型使用的batchsize都是8,并且使用Adam优化器,学习率以指数衰减。
第i步的学习率定义为:![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图59](/uploads/projects/siena0706@bhxtqf/db08ab41959562909b2dbc4deb45cdfe.svg)
我们的初始学习率设置为0.00001,衰减率 r 设置为0.99, 衰减step s = 500, 当使用正则化的时候,我们将其加权为5^10-6。
我们使用方程7中定义的加权交叉熵函数对baseline模型进行预训练,其中p是我们的目标分布,q是我们的候选分布,w是加权因子。 通过设置w> 1,我们使损失项偏向于惩罚false negative。 这是有益的,因为包含血管内部的体素在任何给定的patch中都是稀疏的。 惩罚false negative还可以防止网络在优化的初始阶段(一个很小的局部最优值)将所有体素预测为背景体素。 请注意,由于我们的正则化项倾向于平滑变形场,因此网络已经偏向于身份转换,因此我们的TETRIS模型不需要这样做。 对于我们的实验,我们设置w = 2并预训练非TETRIS模型进行1000次迭代。![TETRIS: Template Transformer Networks for Image Segmentation With Shape Priors[论文笔记] - 图60](/uploads/projects/siena0706@bhxtqf/83f084aa2fd03ca2ada31f5fa2efed81.svg)
我们使用正常的、未加权的交叉熵对模型进行微调,再进行5000次迭代。
网络复现
import torchimport torch.nn as nnclass ResBottleNeck(nn.Module):def __init__(self, in_channels, k_num, k_size, s_size):super(ResBottleNeck,self).__init__()self.bottle_res_unit = nn.Sequential(nn.BatchNorm2d(in_channels, affine=True),nn.ReLU(),nn.Conv2d(in_channels, k_num, kernel_size=k_size*k_size, stride=s_size*s_size),nn.BatchNorm2d(k_num, affine=True),nn.ReLU(),nn.Conv2d(k_num, k_num, kernel_size=1*1, stride=s_size*s_size),nn.BatchNorm2d(k_num, affine=True),nn.ReLU(),nn.Conv2d(k_num, k_num, kernel_size=k_size*k_size, stride=s_size*s_size))def forward(self, x):return torch.cat((self.bottle_res_unit(x), x), 1)# add ?# return torch.add([self.bottle_res_unit(x), x])class MaxPool(nn.Module):def __init__(self):super().__init__()self.maxpool = nn.Sequential(nn.MaxPool2d(2))def forward(self, x):return self.maxpool(x)class BatchNorm(nn.Module):def __init__(self):super().__init__()self.batchNorm = nn.Sequential(nn.BatchNorm2d(16))def forward(self, x):return self.batchNorm(x)class Activate(nn.Module):def __init__(self):super().__init__()self.activate = nn.Sequential(nn.LeakyReLU())def forward(self, x):return self.activate(x)class Conv(nn.Module):def __init__(self, in_channels, out_channels, k_size, s_size):super().__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size = k_size, stride = s_size))
class TTN(nn.Module):def __init__(self, in_channels, k_num, k_size, s_size):super(TTN, self).__init__()self.in_channels = in_channelsself.k_num = k_numself.k_size = k_sizeself.s_size = s_sizeself.bott1 = ResBottleNeck(3, 64, 3, 1)self.max1 = MaxPool()self.bott2 = ResBottleNeck(3, 64, 3, 1)self.bn1 = BatchNorm()self.at1 = Activate()self.max2 = MaxPool()self.conv1 = Conv(8, 64, 3, 1)self.at2 = Activate()self.conv2 = Conv(64, 3, 3, 1)def forward(self, x):x1 = self.bott1(x)x2 = self.max1(x1)x3 = self.bott2(x2)x4 = self.bn1(x3)atx = self.at1(x4)x5 = self.max2(atx)convx1 = self.conv1(x5)atx2 = self.at2(convx1)convx2 = self.conv2(atx2)return convx2

若有收获,就点个赞吧
0 人点赞
