转载请注明出处~~~
方差(Variance):Variance的对象是多个模型,是相同分布的不同数据集训练出模型的输出值之间的差异。它刻画的是数据扰动对模型的影响。方差描述的是训练数据在不同迭代阶段的训练模型中,预测值变化的波动情况(或称为离散情况)。在数学的角度上,表示为:每个预测值与预测均值之差的平方和再求平均数。
偏差(Bias):Bias的对象是单个模型,是期望输出与真实标记的差别。它描述了模型对本训练集的拟合程度。偏差衡量模型的预测值与实际值之间的偏离关系。预测值与实际值的匹配度越强,偏差越小,反之偏差越大。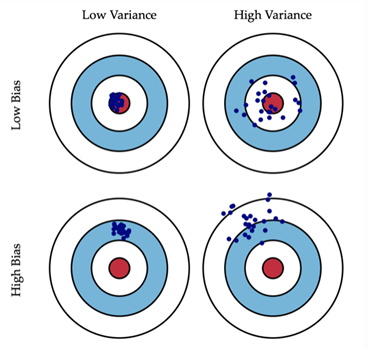
低偏差,低方差:这是训练的理想模型,蓝色点集基本落在靶心区域,数据离散程度小。
低偏差,高方差:深度学习面临的最大问题,也就是过拟合问题。模型太贴合训练数据,泛化能力弱,若遇到测试集,准确度下降地厉害。
高偏差,低方差:训练的初始阶段。
高偏差,高方差:训练最糟糕的情况。
数学定义:
我们从简单的回归模型来入手,对于训练数据集S = {(x , y)},令y = f(x) + ε,假设为实际方程,其中ε是满足正态分布均值为0,标准差为σ的值。
我们再假设预测方程为h(x) = wx + b,这时我们希望总误差
E (x) = ∑ [y - h(x)]
能达到最小值。给定某集合样本(x, y),我们可以展开误差公式,以生成用方差、偏差和噪音组合的方式。
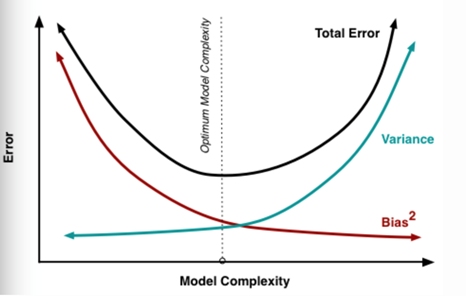
由上图可知,函数模型越来越复杂,会造成方差的变大,偏差会减少。
?为何训练初始阶段是低方差,训练后期易是高方差?
从方差的数学公式出发。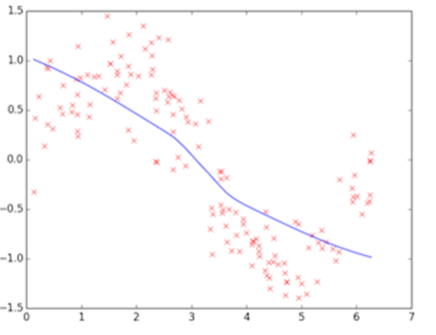
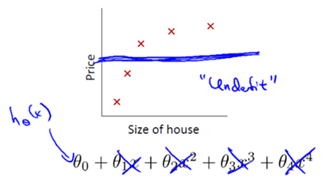
上图为训练初始阶段,我们的模型(蓝线)对训练数据(红点)拟合度很差,是高偏差,但蓝线近似线性组合,其波动变化小,套用数学公式也可知数值较小,故为低方差,这个阶段也称之为欠拟合(underfitting),需要加大训练迭代数。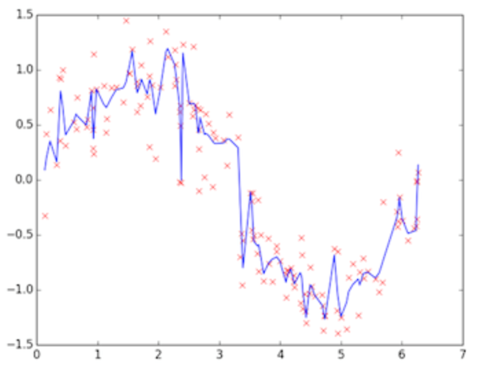
上图为训练的后期阶段,可明显看出模型的拟合度很好,是低偏差,但蓝线的波动性非常大,为高方差,这个阶段称之为过拟合(overfitting),问题很明显,蓝线模型很适合这套训练数据,但如果用测试数据来检验模型,就会发现泛化能力差,准确度下降。
再来看一个例子: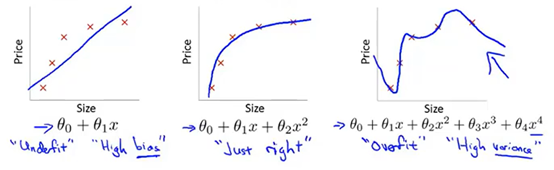
由以上可得:
过拟合将会在变量过多的时候出现,这个时候的训练出来的假设函数虽然能够很好地拟合训练集,但得到的曲线波动非常明显,由于它千方百计地拟合训练集,导致它无法很好地泛化在新的样本数据中。
解决过拟合问题的一些方法:
数据集扩增:
由于过拟合时往往是针对非常少量的Training Data进行训练的,得到的函数模型虽然能够很好的拟合,但是泛化能力非常差,增大训练数据集,能够适当的提高函数模型的泛化能力。
但是在扩增数据集的时候,我们需要得到符合要求的数据,即和已有的训练集数据时同分布的,或者是近似独立同分布,这样一来,就可以采用以下方法扩增数据集。
1.从数据源头采集更多数据。
2.复制原有数据并加上随机噪声。
3.重采样。
4.根据当前数据集估计数据分布,使用该分布产生更多数据。
Early Stopping(早停法)
所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。使用Early Stopping的方法,就可以通过在模型训练的整个过程中截取保存结果最优的参数模型,防止过拟合。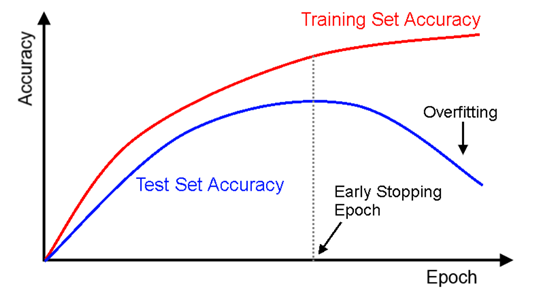
Epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被完整遍历的次数。
Earlystopping的工作原理:
·将数据分为训练集和验证集
·每个epoch结束后,在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练。
·将停止之后的权重作为网络的最终参数。
怎样才能认为验证集精度不能再提高呢?
—>并不是说验证集的精度一下降就认为精度不能再提高了,而是通过一定的epoch之后,验证集精度连续降低,在这个时候我们才能认为验证集的精度不能在提高。一般在训练过程中,10次epoch后没有达到最佳精度,就实施截取。
正则化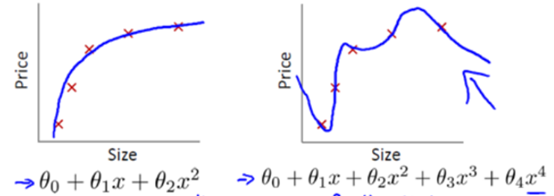
//正则化就是在损失函数后加上一个正则化项(惩罚项),其实就是常说的结构风险最小化策略,即经验风险(损失函数)加上正则化。一般模型越复杂,正则化值越大。正则化其实就是带约束条件的优化问题,正则化项是用来对模型中某些参数进行约束的。
从上图中我们可以得知,右图的函数实际上是过拟合的,泛化能力不好。但是如果在函数中加入惩罚项,使得参数θ3和θ4的值非常小(接近0),得到的函数其实是类似于二次函数的。
参数值小意味着这个函数模型的复杂程度越小,得到的函数就越平滑越简单,越不容易出现过拟合问题。
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。采用正则化方法会自动削弱不重要的特征变量,自动从许多的特征变量中‘提取’重要的特征变量,减小特征变量的数量级。
但在实际中,我们不知道哪些参数对整个函数模型的作用最小。
因此我们修改了代价函数。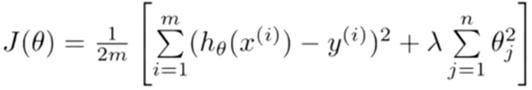
λ这个正则化参数需要控制的是这两者之间的平衡,即平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
//我们没有去惩罚 θ0,因此 θ0 的值是大的。这就是一个约定从 1 到 n 的求和,而不是从 0 到 n 的求和。无论你是否包括这 θ0 这项,在实践中这只会有非常小的差异。但是按照惯例,通常情况下我们还是只从 θ1 到 θn 进行正则化。
那么如何使得θ3和θ4尽可能地接近0呢?那就是对参数施加惩罚项。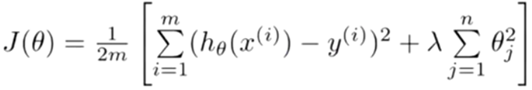
梯度下降的式子就变为: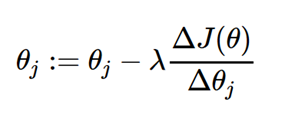
如果λ设置得太大,对θn的惩罚程度会太大,会导致θ1、θ2……都接近0,那么整个lossfunction = θ0,等于用一条直线去拟合数据,变成欠拟合。
l的选择:
①广义交叉验证法
②L-曲线法
最常用的两种正则化方法:
L1正则化: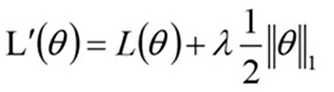
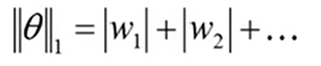

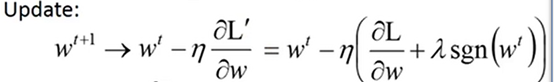
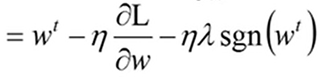
x>0, sgnx = 1
x=0, sgnx = 0
x<0, sgnx = -1
那么在w小于0的时候,加1,w大于0的时候,减1,这个加一或者减一是固定不变的,不管这个|w|有多大,每次都是加1或减1,实现将权值降低。
如果w等于0,怎么办?
—-当w=0的时候,|w|是不可导的,这个时候要进行特别处理,按照没有正则化的方法去更新w,即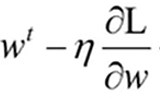
L2正则化: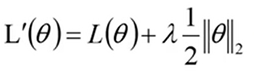
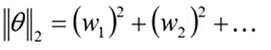
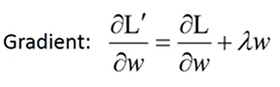
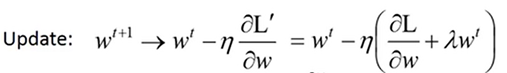
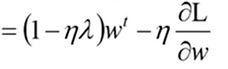
由上可见,在每次进行权值更新的时候,我们都在原来的参数上乘上一个小于1的数,那么久而久之,这个参数就会非常接近0,但是不会等于0,这就实现了权值的衰减。
L1正则化和L2正则化的区别:
在w非常大的时候,使用L2正则化能够快速降低权值,L1每次只是固定增1或减1,所以降低权值存在非常慢的情况,可能经过L1正则化后,仍存在比较大的权值。但是在w很小的时候,L2正则化却不能很快地衰减权值,L1却可以快速将w向0靠拢。
Dropout
Dropout也是避免过拟合的一种方法。
L1和L2正则化通过在损失函数上增加参数的惩罚项,通过对参数大小的约束,起到类似降维的作用(若高阶项参数接近0,相当于降阶)。进而简化模型,提高模型泛化力,避免过拟合。
L1和L2正则化是通过修改代价函数来避免过拟合,而Dropout修改神经网络本身。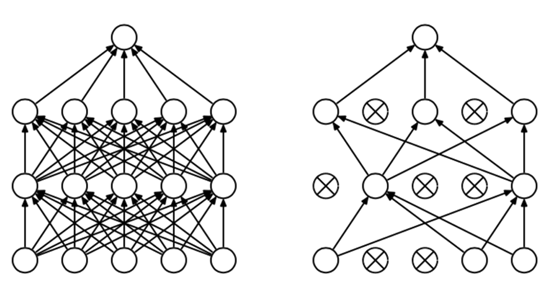
Dropout简单理解:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
工作流程:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)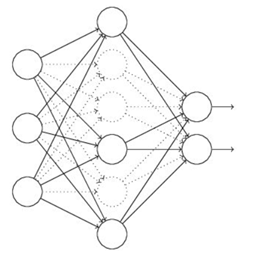
(2)然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)继续重复这一过程:恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b)(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
那么怎么让某些神经元以一定的概率停止工作(即被删除掉)?
在训练网络的每个单元都要添加一道概率流程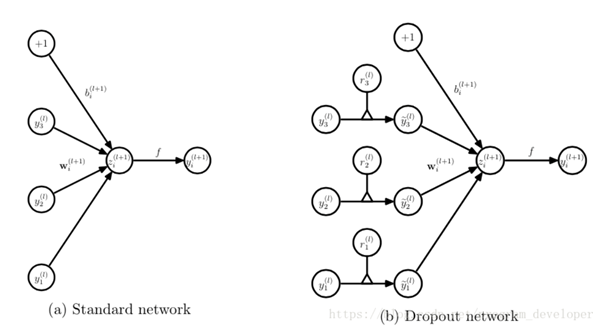
标准神经网络: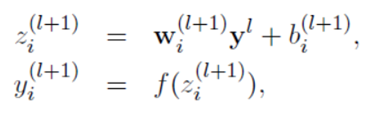
采用Dropout的神经网络:
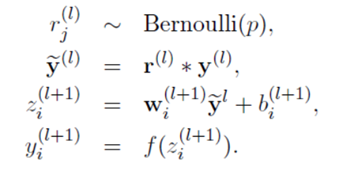
上述的Bernoulli函数是为了随机生成一个0、1向量
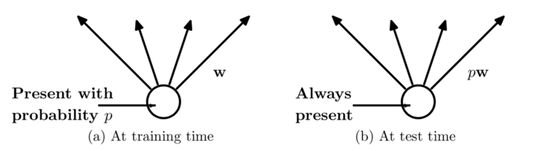
在训练时我们随机丢弃神经元,但是在测试时我们要用到全部的神经元,这两种情况下直接的到的结果显然是不能等同的,那么我们应该怎么处理?
在训练的时候,我们以p为概率保存神经元,以1-p为概率丢弃神经元,那么输出就变为pxw.
在测试的时候,所有神经元都保留,而权值进行缩放,乘上概率p,那么输出变为xpw
这样一来,在测试时的网络输出的结果就可以和在训练时的网络输出的结果保持一致。

若有收获,就点个赞吧
0 人点赞
