回顾之前所阅读的论文。
CNN低层卷积层特征图可视化之后,可以看出CNN学习的是一些粗浅的特征,例如纹理,颜色等等,高层卷积层特征图可视化之后,我们可以看到语义信息相对丰富的目标部分。
基于【论文 Interpretable Convolutional Neural Networks 】的思想,我们可以把baseline模型每一层的特征图画出来,观察每一层的语义特征。
具体地说,我想知道这四种特征的出现是在低层出现、还是高层出现。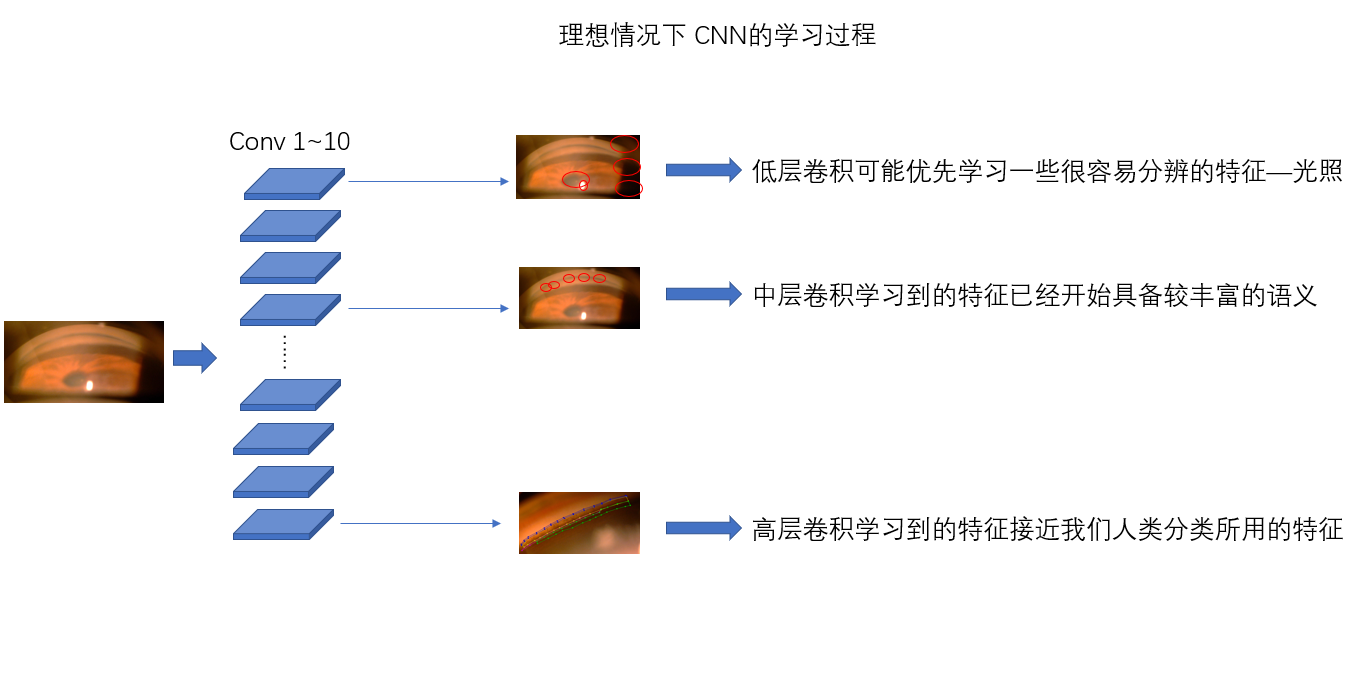
如果是在低层出现[base classification score≈50%],这种现象很好解释。这说明我们的特征跟纹理/光照的混合程度很高,模型无法区分干扰信息和四种特征。【这种现象可能是因为数据集本身的质量不够高,特征区域过于模糊】。我们需要做一些能够增强这四种特征语义信息的方法【例如通过观察图像的频谱信息,寻找特征区域和无关纹理/光线/颜色频率之间的关系,在一定的频带进行过滤处理】,使得这四种特征的语义跟纹理/光照有一个较大的区分度。从而提高分类的结果,并且使得我们的工作具有一定的可解释性。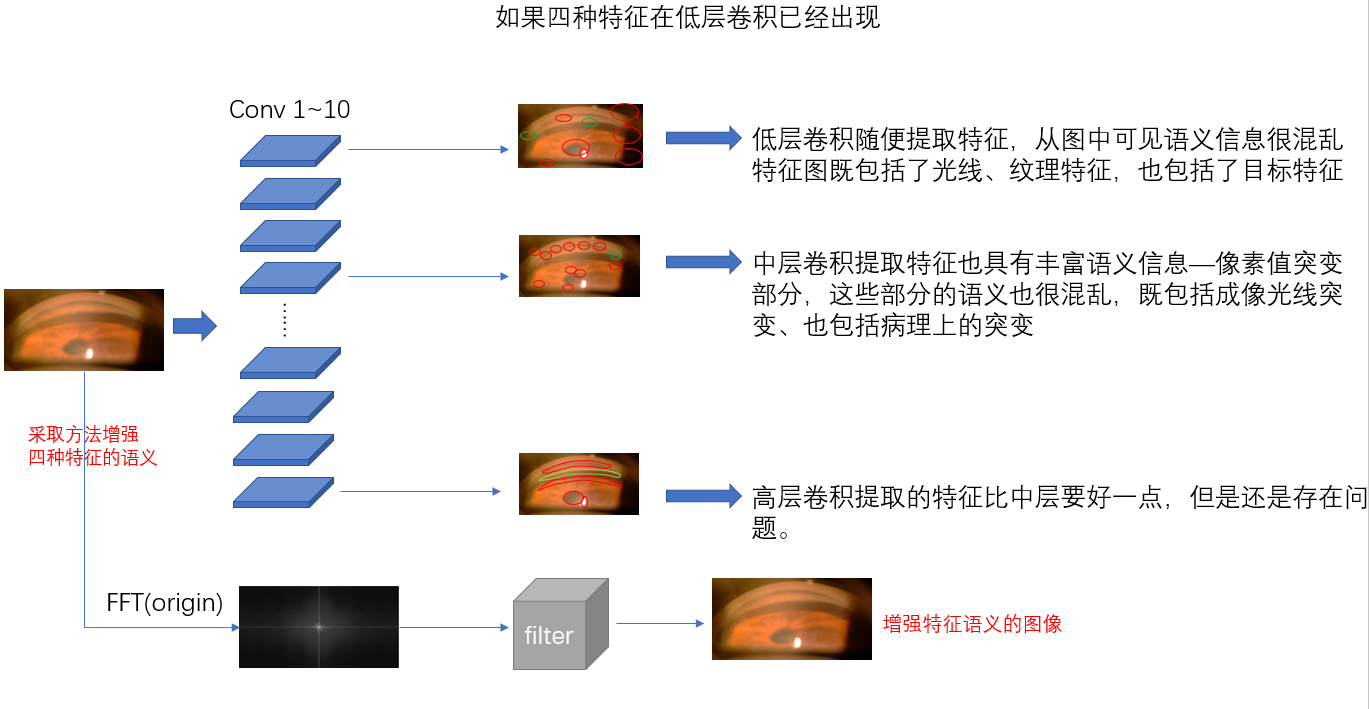
如果是在高层出现,这代表模型还是能够区分四种特征和纹理/光照的。但是同时我想知道这四种特征在同一层卷积层的特征图的位置关系是怎样的,如果这四种特征的空间关系符合现实空间关系,那么证明模型的学习没有很大问题,只不过到了一个通过传统训练方法无法突破的瓶颈期。我们可以参考论文提出的loss函数,对每一层卷积的卷积核加一个特定的loss,这个loss关注我们事先定义好的目标位置(例如四种特征之一睫状体带),在CNN学习过程中它的存在与否,以及整个特征图它的出现是否是唯一语义特征。通过这个loss函数,我们让卷积核产生的一张特征图只具有一个特征,而不是好几个特征糅合在一块,使得整个网络的解释性变得更强—> 第x个filter学的是小梁网,第x+1个filter学的是睫状体带……通过观察每个特征对结果的贡献程度,我们就可以回去修改某一层的filter达到提升分类效果的目的。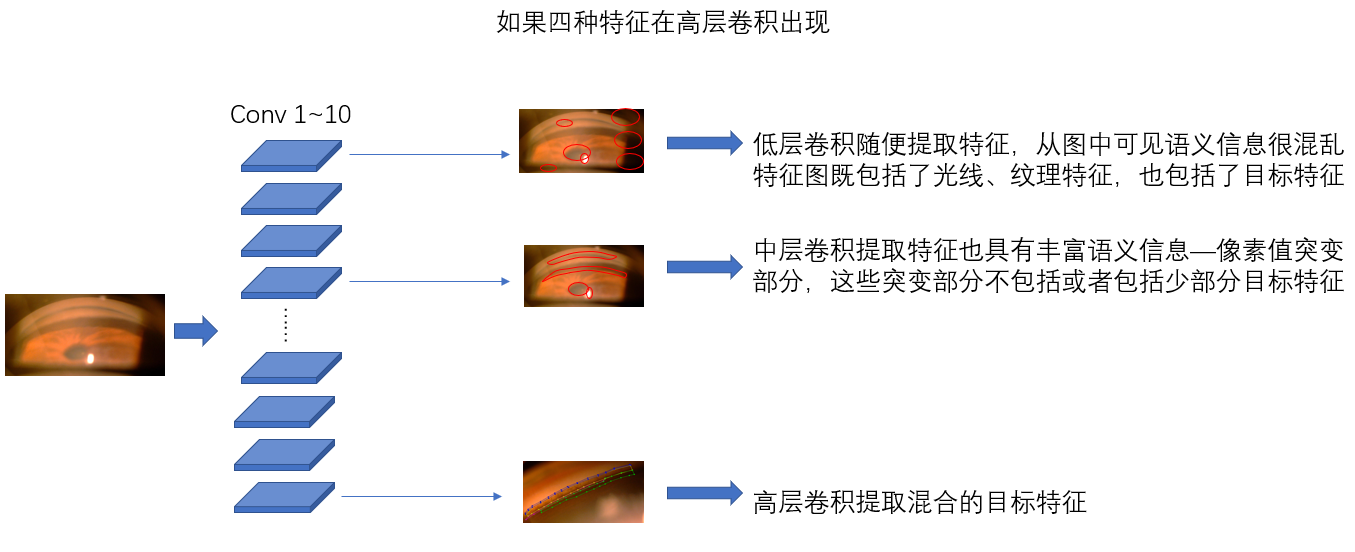


若有收获,就点个赞吧
0 人点赞
