
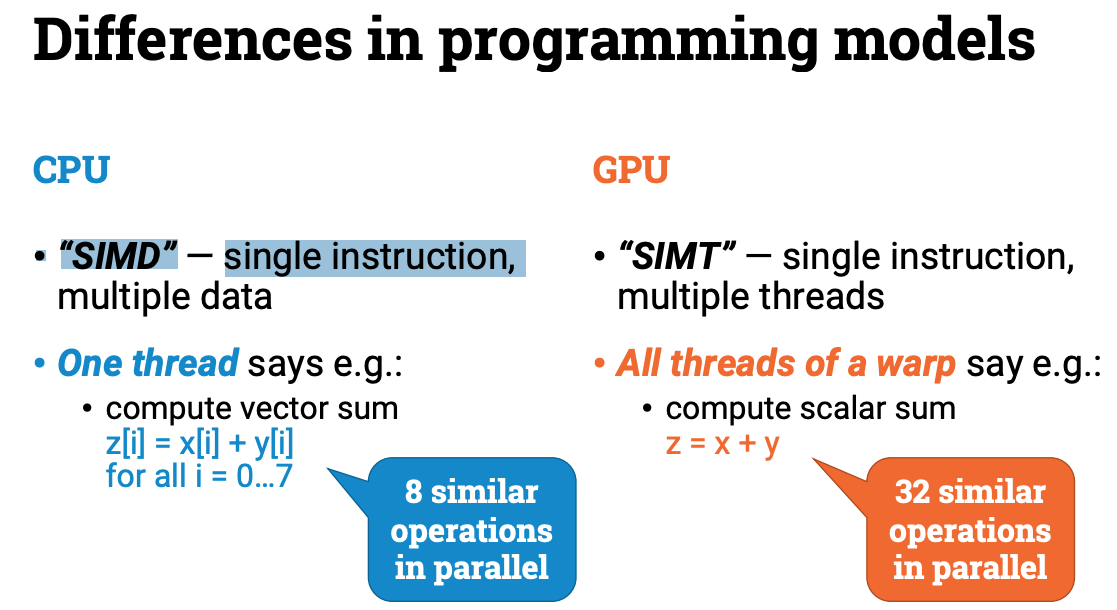



Why do we still need CPU?

GPU programming with CUDA

Practice: Sequential CPU one and parallel GPU one
Sequential CPU:

#include <iostream>#include <ctime>#include <stack>#include <limits>std::stack<clock_t> tictoc_stack;void tic(){tictoc_stack.push(clock());}void toc(){std::cout << "Time elapsed: "<< ((double)(clock() - tictoc_stack.top())) / CLOCKS_PER_SEC<< std::endl;tictoc_stack.pop();}inline int p5(int i) { return i * i * i * i * i; }inline int value(int x){int a = 0;for (int i = 0; i < 30; i++){// ALL the possibility is verified hereif (x & (1 << i)){a += p5(i + 1);}else{a -= p5(i + 1);}}return abs(a);}int main(){constexpr int total = 1 << 30;int best_x = 0;int best_v = value(best_x);tic();for (int x = 0; x < total; x++){int v = value(x);if (v < best_v){best_x = x;best_v = value(x);}}std::cout << "best_x:" << best_x << " best_v:" << best_v << std::endl;toc();}


#include <ctime>#include <stack>#include <limits>#include <vector>#include <stdio.h>constexpr int blocks = 1 << 10;constexpr int threads = 1 << 6;constexpr int iterations = 1 << 14;__host__ __device__ inline int p5(int i) { return i * i * i * i * i; }__host__ __device__ inline int value(int x){int a = 0;for (int i = 0; i < 30; i++){if (x & (1 << i)){a += p5(i + 1);}else{a -= p5(i + 1);}}return abs(a);}__global__ void mykernel(int* r){int x3 = blockIdx.x;int x2 = threadIdx.x;int best_x = 0;int best_v = value(best_x);for (int x1 = 0; x1 < iterations; x1++){int x = (x3 << 20) | (x2 << 14) | x1;int v = value(x);if (v < best_v){best_x = x;best_v = v;}}r[(x3 << 6) | x2] = best_x;}int main(){int* rGPU = NULL;Each block will calculate the limited number of records, which really speed upcudaMalloc((void**)&rGPU, blocks * threads * sizeof(int));mykernel<<<blocks, threads>>>(rGPU);cudaDeviceSynchronize();cudaGetLastError();std::vector<int> r(blocks * threads);cudaMemcpy(r.data(), rGPU, blocks * threads * sizeof(int), cudaMemcpyDeviceToHost);cudaFree(rGPU);}
Parallel GPU Reading:
Memory access pattern


若有收获,就点个赞吧
0 人点赞
