parallel regions
tells OpenMP that we would like to create multiple threads:
a();#pragma omp parallel{c(1);c(2);}z();--------------12does not make any differences

The number of threads is automatically chosen by OpenMP; it is typically equal to the number of hardware threads that the CPU supports, which in the case of a low-end CPU is usually the number of CPU cores. In the examples of this chapter we use a 4-core CPU with 4 threads.
Everything that is contained inside aparallelregion is executed by all threads. OpenMP will automatically wait for all threads to finish their work before continuing the part that comes after the loop.
Critical sections
A critical section ensures that at most one thread is executing code that is inside the critical section.
a();#pragma omp parallel{c(1);#pragma omp critical{c(2);}c(3);c(4);}z();
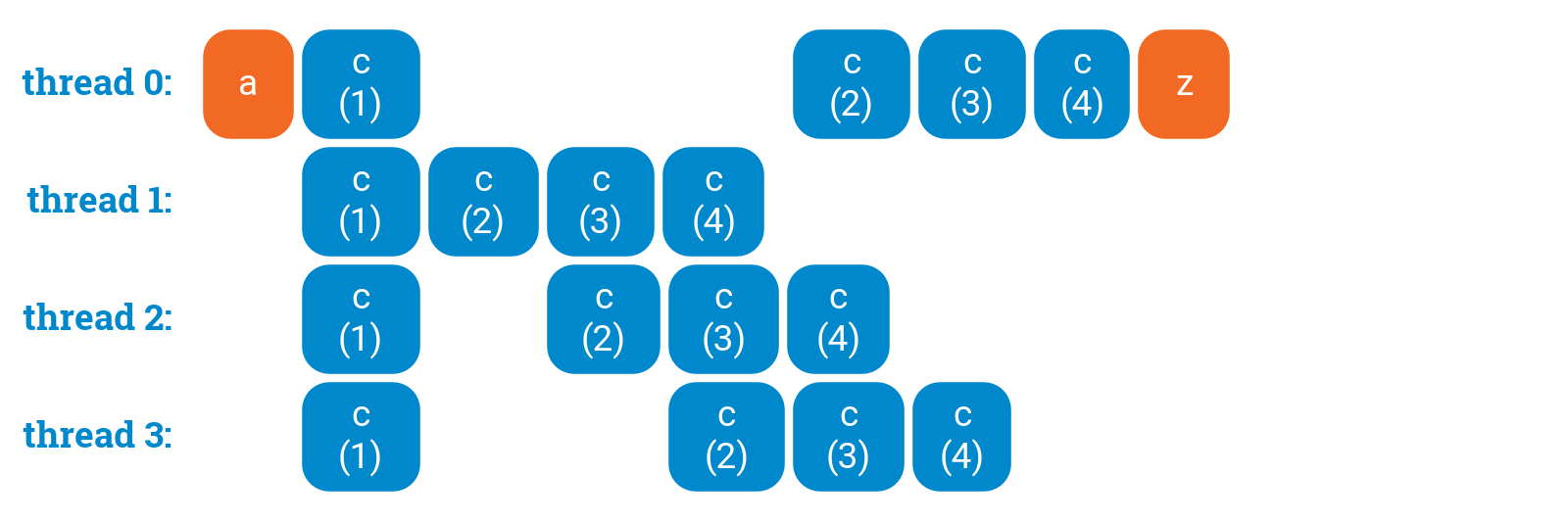
critical sections also ensure that modifications to shared data in one thread will be visible to the other threads, as long as all references to the shared data are kept inside critical sections.
Shared vs. private data
Any variable that is declared outside aparallelregion is shared: there is only one copy of the variable, and all threads refer to the same variable. Care is needed whenever you refer to such a variable.
Any variable that is declared inside aparallelregion is private: each thread has its own copy of the variable. Such variables are always safe to use.
If a shared variable is read-only, you can safely refer to it from multiple threads inside theparallelregion. However, if any thread ever writes to a shared variable, then proper coordination is needed to ensure that no other thread is simultaneously reading or writing to it.
static void critical_example(int v) {// Shared variablesint a = 0;int b = v;#pragma omp parallel{// Private variable - one for each threadint c;// Reading from "b" is safe: it is read-only// Writing to "c" is safe: it is privatec = b;// Reading from "c" is safe: it is private// Writing to "c" is safe: it is privatec = c * 10;#pragma omp critical{// Any modifications of "a" are safe:// we are inside a critical sectiona = a + c;}}// Reading from "a" is safe:// we are outside parallel regionstd::cout << a << std::endl;}
Other shared resources
Note that e.g. I/O streams are shared resources. Any piece of code that prints something to stdout has to be kept inside a critical section or outside a parallel region.
parallel for loops
a();for (int i = 0; i < 10; ++i) {c(i);}z();
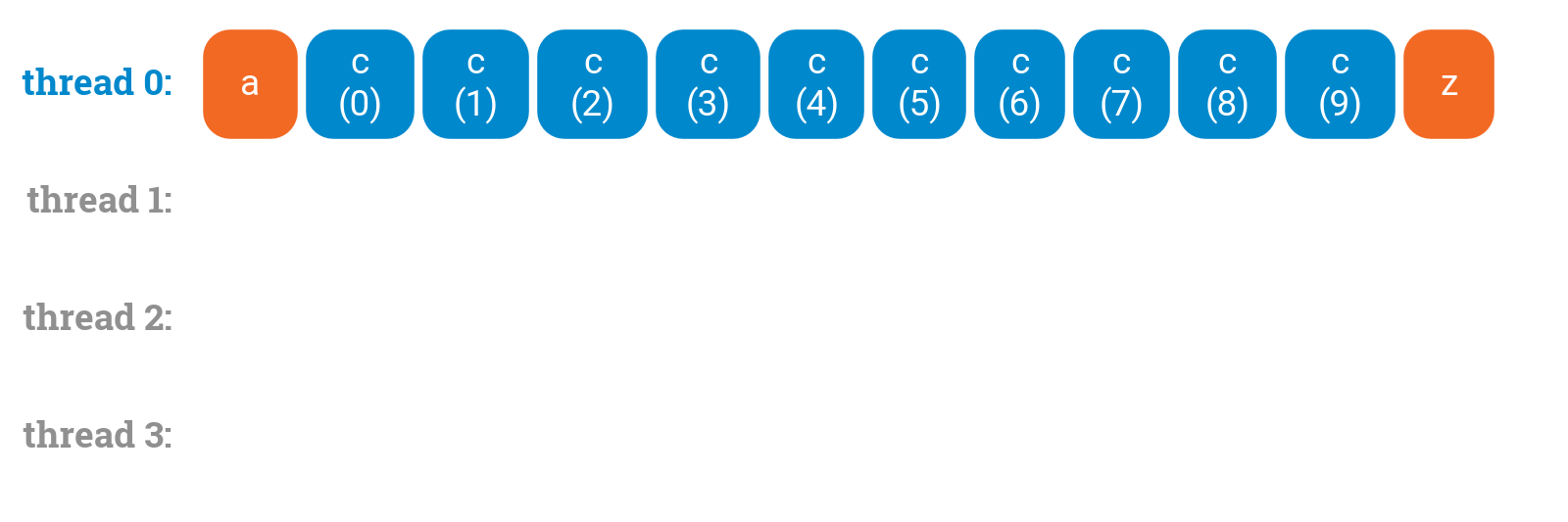
Note that OpenMP automatically waits for all threads to finish their calculations before continuing with the part that comes after the parallel for loop:
a();#pragma omp parallel forfor (int i = 0; i < 10; ++i) {c(i);}z();
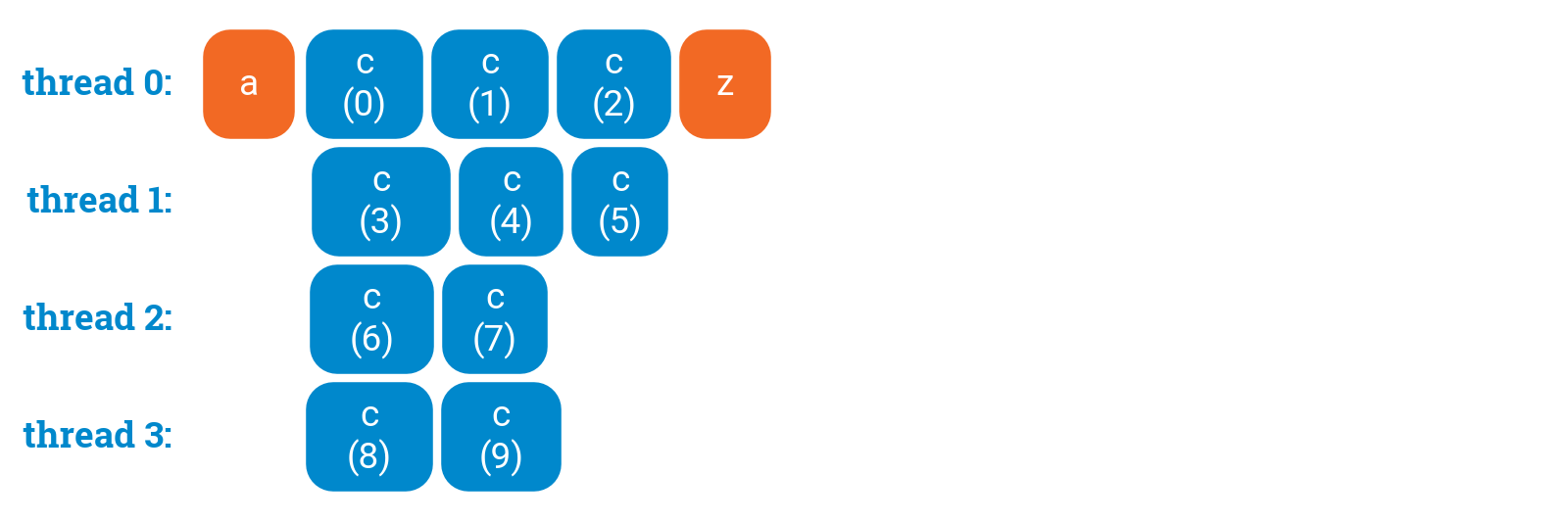
omp parallel, which declares that we would like to have multiple threads in this region, and omp for, which asks OpenMP to assign different iterations to different threads:
a();#pragma omp parallel{#pragma omp forfor (int i = 0; i < 10; ++i) {c(i);}}z();
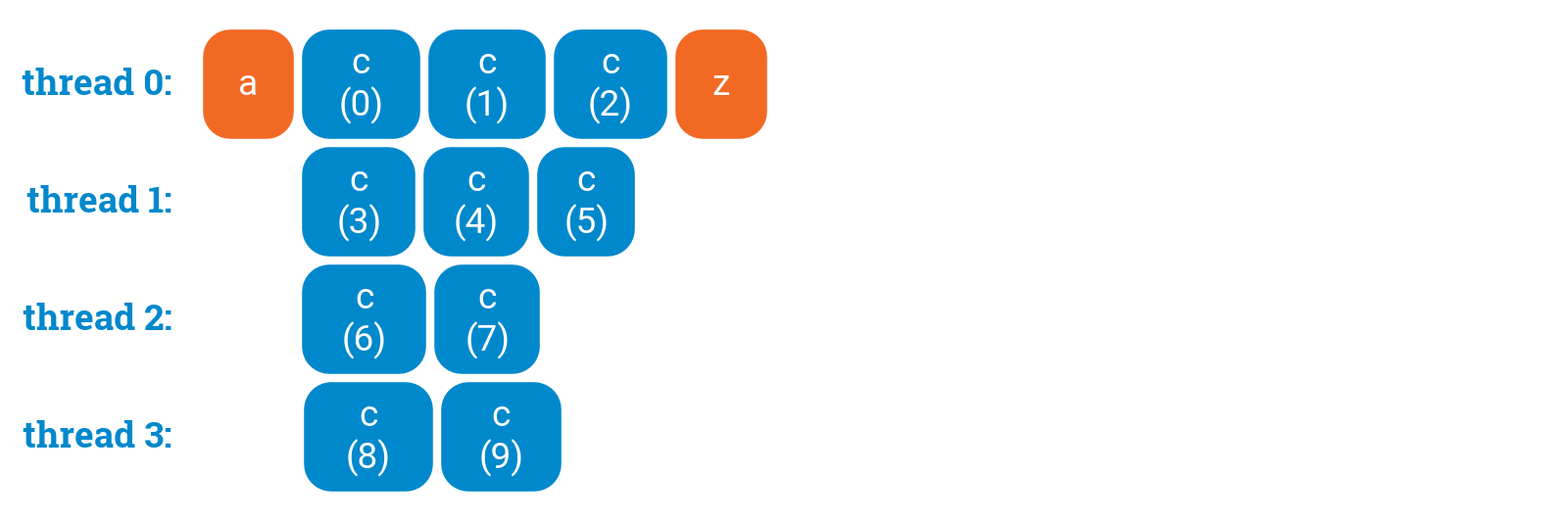
While in many cases it is convenient to combine omp parallel and omp for in one directive, please remember that you can always split them.
There is also a synchronization point _after _each omp for loop; here no thread will executed() until all threads are done with the loop:
a();#pragma omp parallel{b();#pragma omp forfor (int i = 0; i < 10; ++i) {c(i);}d();}z();
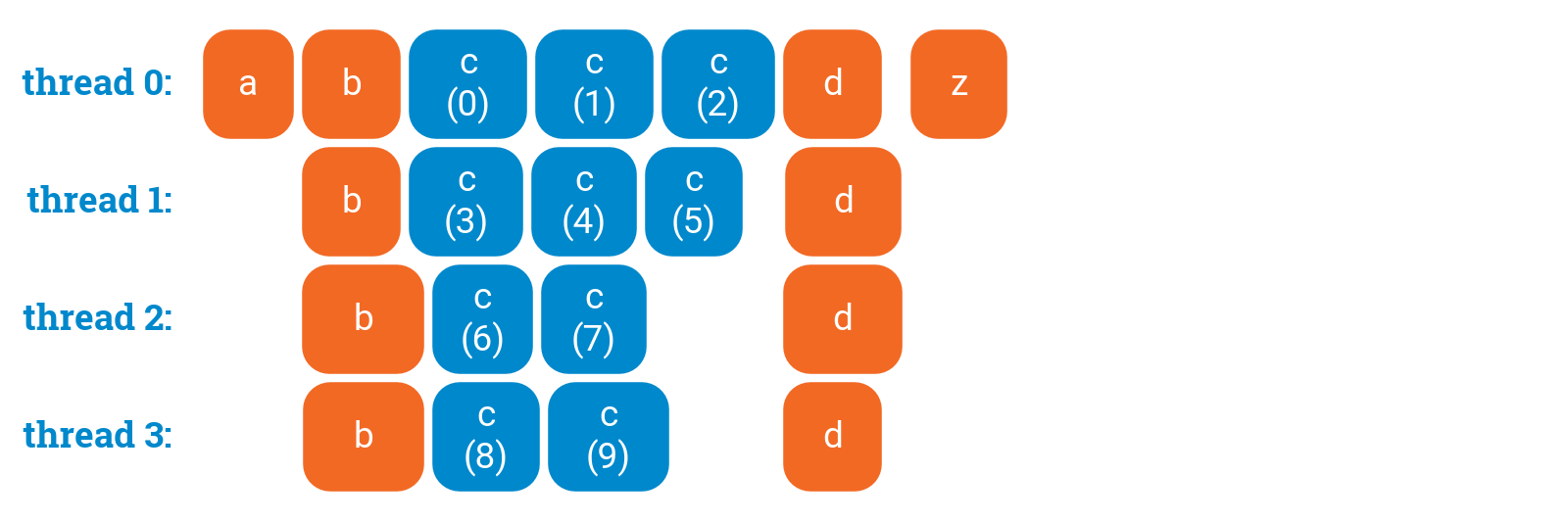
However, if you do not need synchronization after the loop, you can disable it with nowait:
a();#pragma omp parallel{b();#pragma omp for nowaitfor (int i = 0; i < 10; ++i) {c(i);}#pragma omp critical{d();}}z();
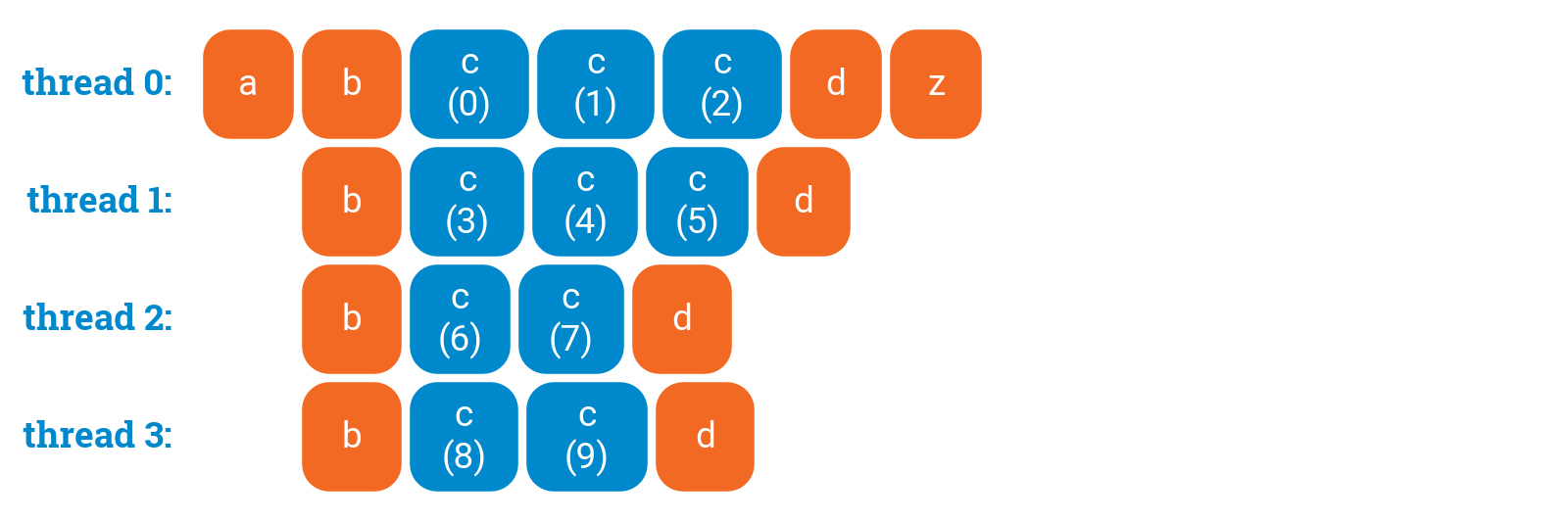
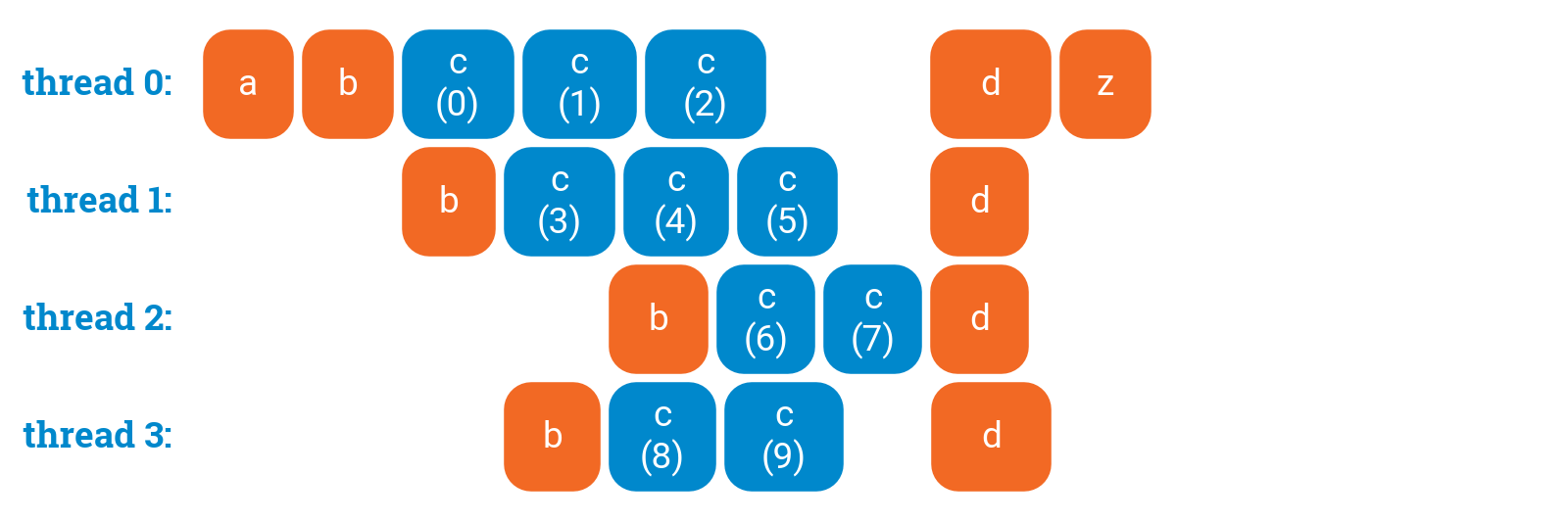
You can disable waiting, so that some threads can start doing postprocessing early. This would make sense if, e.g., d() updates some global data structure based on what the thread computed in its own part of the parallel for loop:
a();#pragma omp parallel{#pragma omp critical{b();}#pragma omp forfor (int i = 0; i < 10; ++i) {c(i);}d();}z();
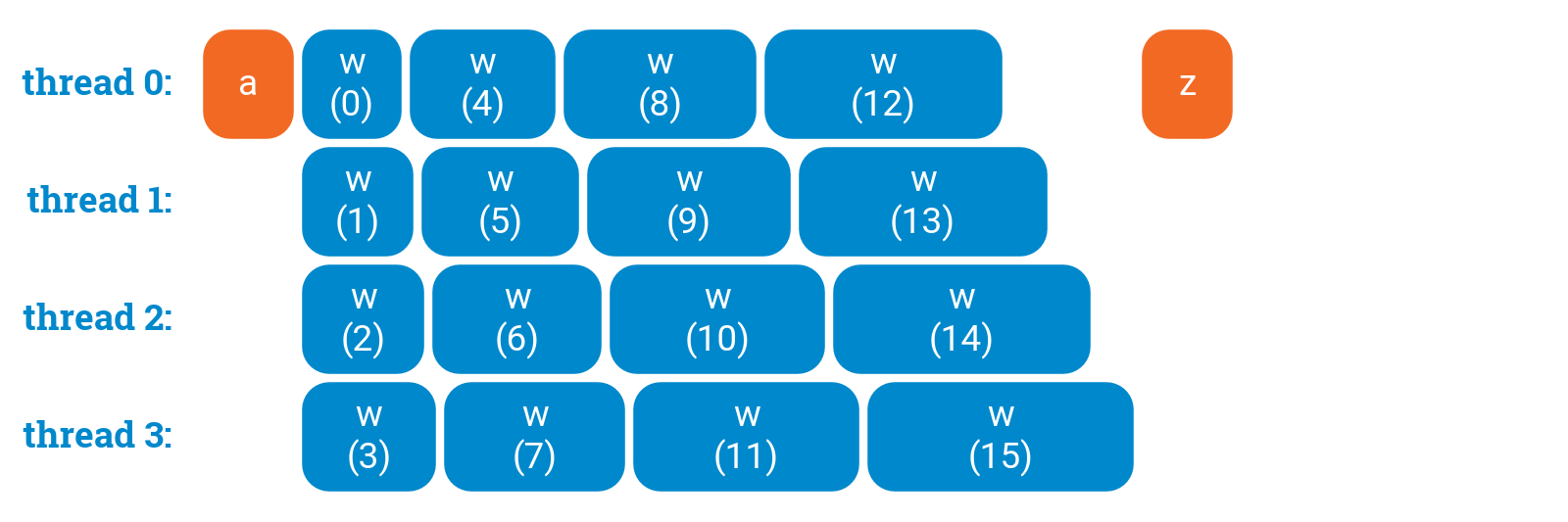
OpenMP parallel for loops: scheduling
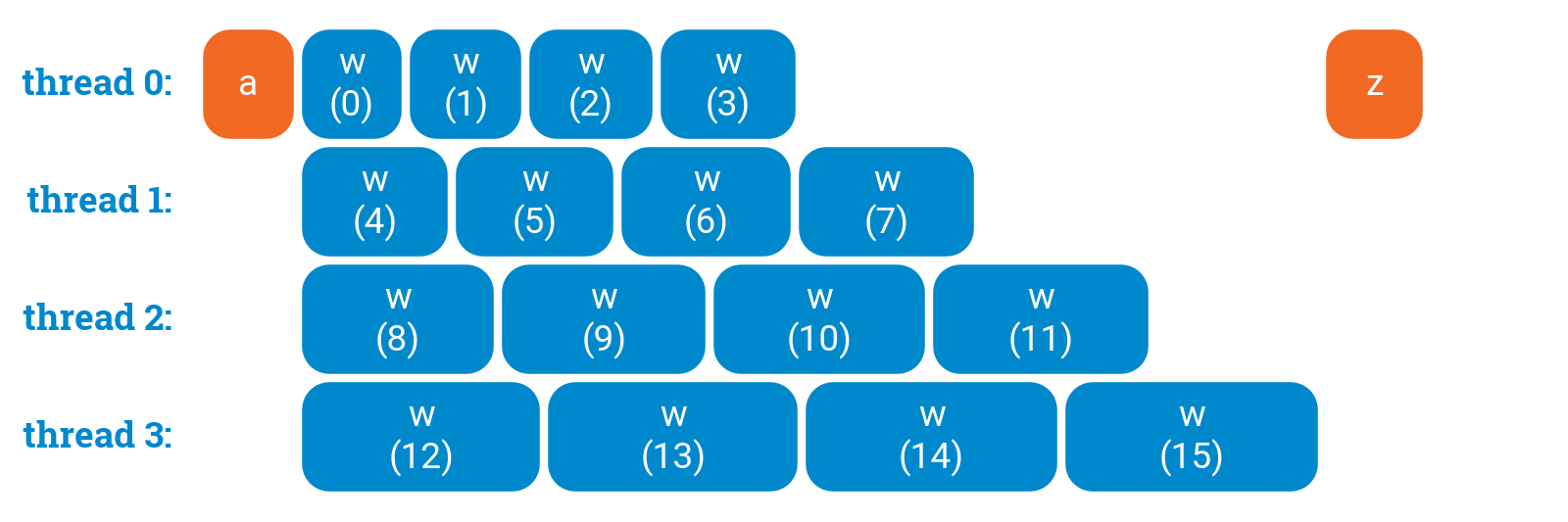
a();#pragma omp parallel for schedule(static,1)for (int i = 0; i < 16; ++i) {w(i);}z();
Dynamic loop scheduling
a();#pragma omp parallel for schedule(dynamic,1)for (int i = 0; i < 16; ++i) {v(i);}z();
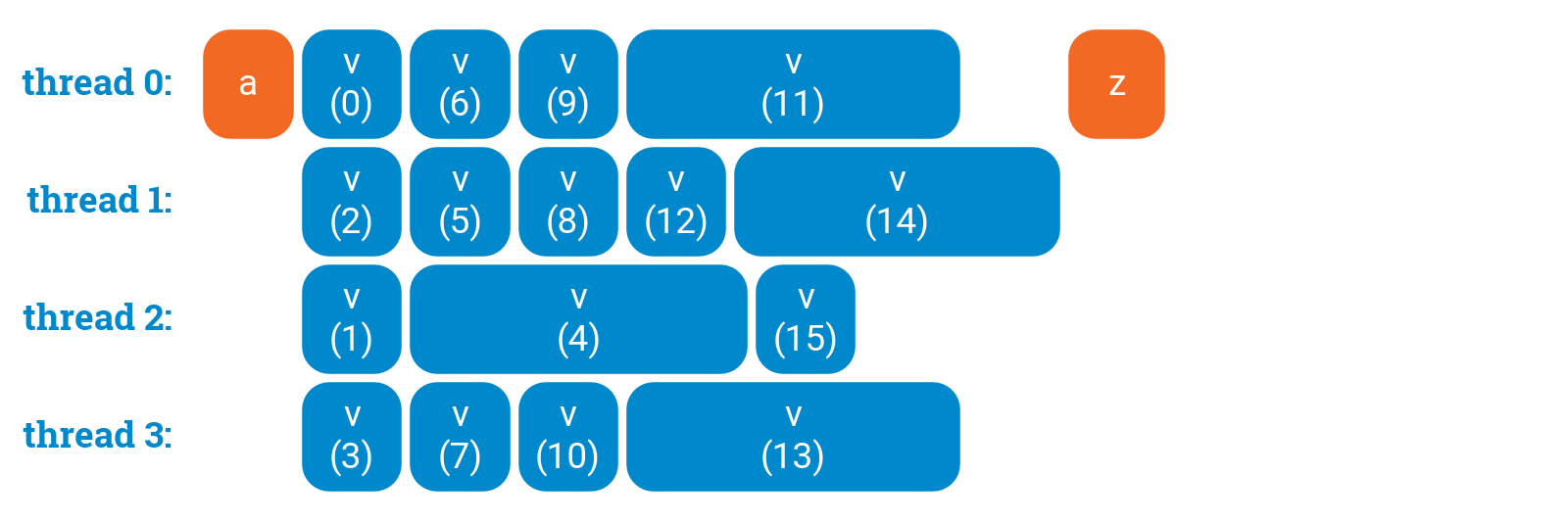
However, please note that dynamic scheduling is expensive: there is some communication between the threads after each iteration of the loop! Increasing the chunk size(number “1” in the schedule directive) may help here to find a better trade-off between balanced workload and coordination overhead.
Parallelizing nested loops
If we have nested for loops, it is often enough to simply parallelize the outermost loop:
a();#pragma omp parallel forfor (int i = 0; i < 4; ++i) {for (int j = 0; j < 4; ++j) {c(i, j);}}z();
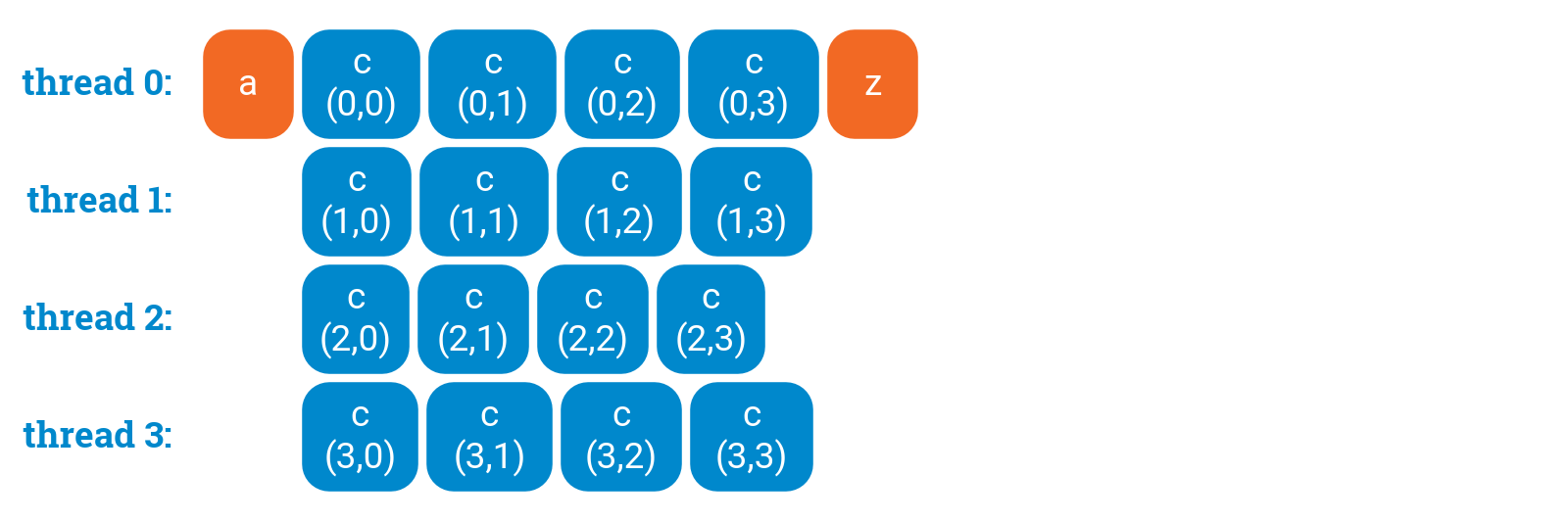
This is all that we need most of the time. You can safely stop reading this part now; in what follows we will just discuss what to do in some rare corner cases.
Challenges
Sometimes the outermost loop is so short that not all threads are utilized:
a();#pragma omp parallel forfor (int i = 0; i < 3; ++i) {for (int j = 0; j < 6; ++j) {c(i, j);}}z();
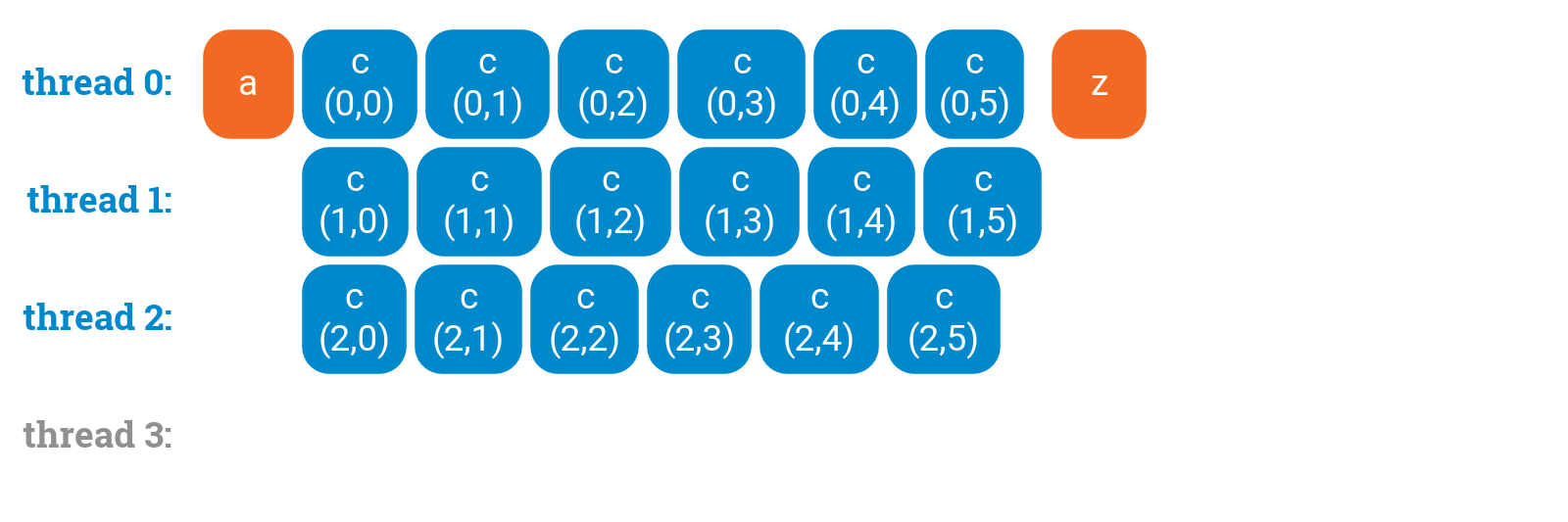
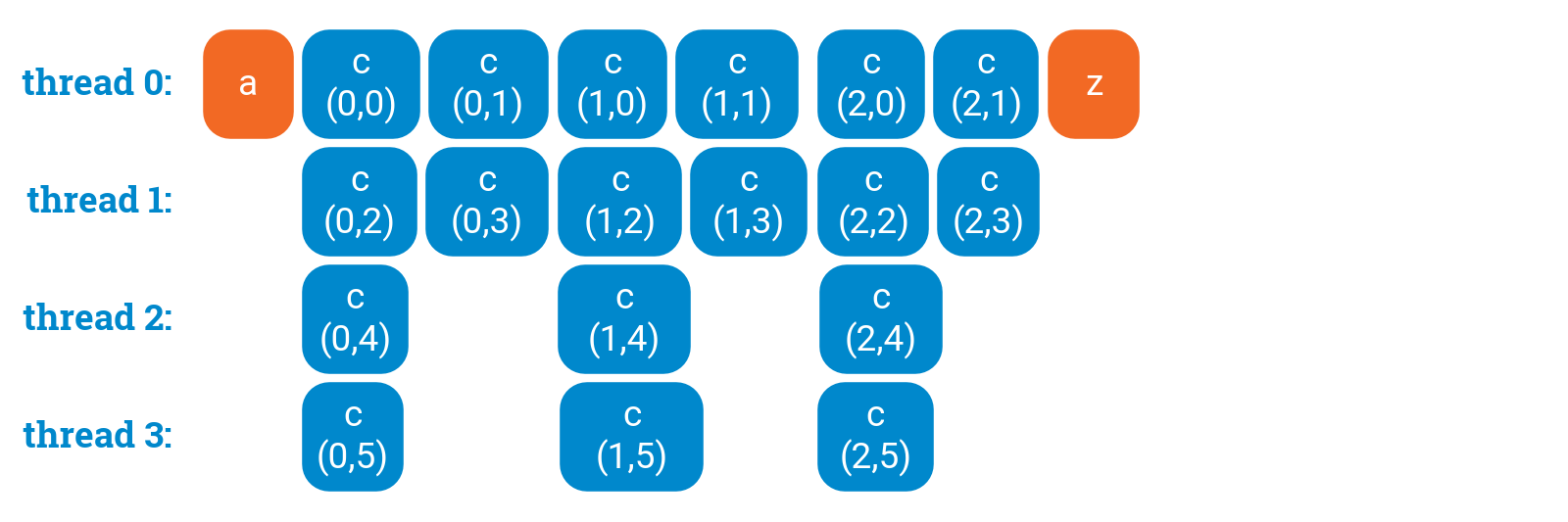
We could try to parallelize the _inner _loop. However, then we will have more overhead in the inner loop, which is more performance-critical, and there is no guarantee that the thread utilization is any better:
a();for (int i = 0; i < 3; ++i) {#pragma omp parallel forfor (int j = 0; j < 6; ++j) {c(i, j);}}z();
Good ways to do it
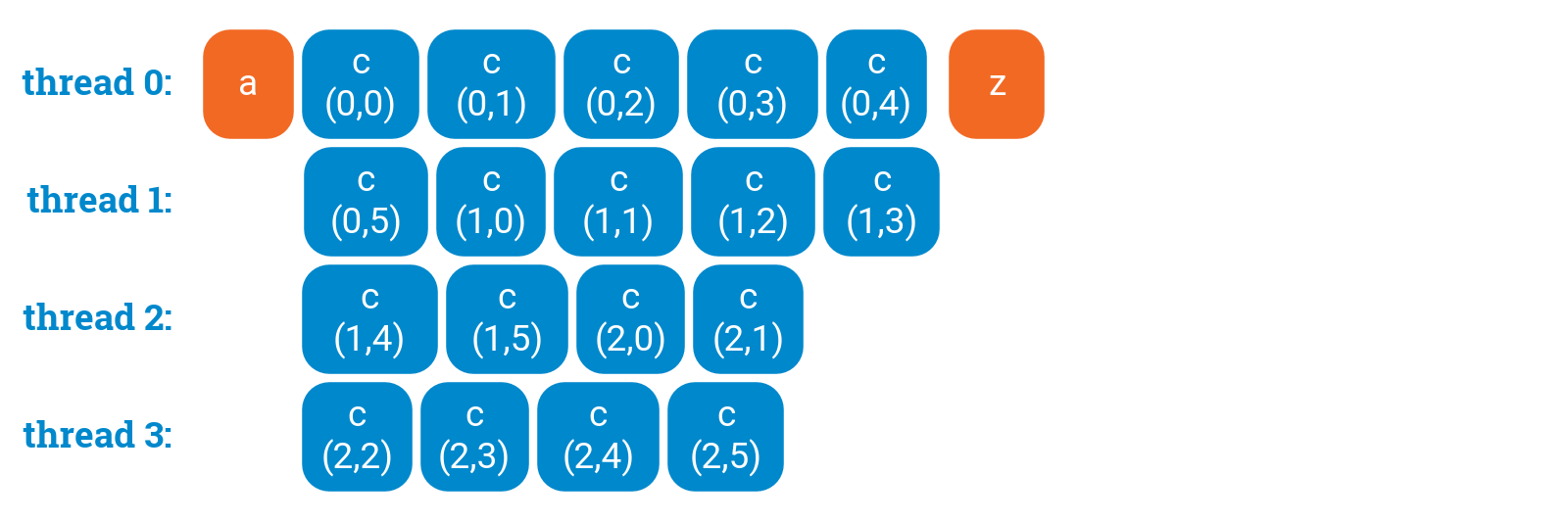
In essence, we have got here 3 × 6 = 18 units of work and we would like to spread it evenly among the threads. The correct solution is tocollapse it into one loopthat does 18 iterations. We can do it manually:
a();#pragma omp parallel forfor (int ij = 0; ij < 3 * 6; ++ij) {c(ij / 6, ij % 6);}z();
Or we can ask OpenMP to do it for us:
a();#pragma omp parallel for collapse(2)for (int i = 0; i < 3; ++i) {for (int j = 0; j < 6; ++j) {c(i, j);}}z();

Wrong way to do it, part 1
Unfortunately, one often sees failed attempts of parallelizing nested for loops. This is perhaps the most common version:
a();#pragma omp parallel forfor (int i = 0; i < 3; ++i) {#pragma omp parallel forfor (int j = 0; j < 6; ++j) {c(i, j);}}z();
This code does not do anything meaningful. “Nested parallelism” is disabled in OpenMP by default, and the second pragma is ignored at runtime: a thread enters the inner parallel region, a team of only one thread is created, and each inner loop is processed by a team of one thread.
The end result will look, in essence, identical to what we would get without the second pragma — but there is just more overhead in the inner loop: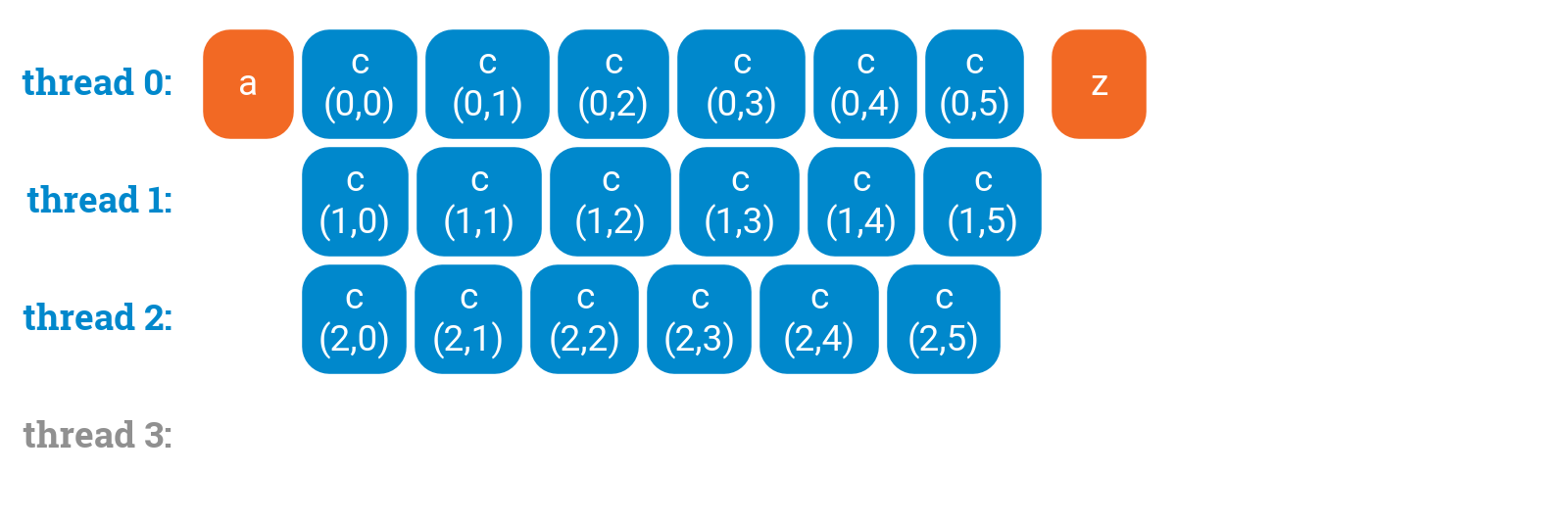
Wrong way to do it, part 2
One also occasionally sees attempts of using multiple nested omp for directives inside one parallel region. This is seriously broken; OpenMP specification does not define what this would mean but simply forbids it:
a();#pragma omp parallel forfor (int i = 0; i < 3; ++i) {#pragma omp forfor (int j = 0; j < 6; ++j) {c(i, j);}}z();
Hyper-threading
So far we have discussed the simple case of each CPU core running only one thread. However, some high-end CPUs are able to runmultiple threads per core. This is known as hyper-threading.
From the perspective of the operating system, a 4-core CPU with hyper-threading looks a lot like an 8-core CPU. The operating system can all the time keep 8 threads running on the CPU. However, from the perspective of the programmer, things get more complicated if we are interested in the performance.

OpenMP memory model: manipulating shared data
Any multithreaded programming environment has to define a memory model). This is acontract between programmer and the environment: the system will assume that the programmer is following the rules, and if this is indeed the case, the system will do what the programmer expects it to do.
Temporary view vs. memory
The OpenMP memory model consists of two components: there is a global memory _shared by all threads, and each thread has its own temporary view _of the memory.
OpenMP performs a flush automatically whenever you enter or leave aparallelregion. It also performs a flush whenever you enter or leave a critical section.
Each read and write operation refers to the temporary view. The temporary view may or may not be consistent with the global memory. Consistency is guaranteed only after a “flush” operation. Flush makes sure that whatever you have written to your own temporary view will be visible in the global memory, and whatever someone else has flushed to the global memory will be available for reading in your own temporary view.
Memory model is an abstraction
It is important to keep in mind that memory models are abstractions. “Temporary view” is just an abstract way to describe how the system is guaranteed to behave. This does not refer to any specific piece of hardware or software.
In practice, “temporary view” refers to the combination of the following elements (and many more):
- What kind of optimizations the compiler might do.
- How the cache memory system works in the CPU.

Atomic operations
Critical sections are slow. If you have a performance-critical part in which you would like to modify some shared variable, there are also faster alternatives: atomic operations.

Atomic operations are like tiny critical sections that only apply to one operation that refers to one data element. They do a flush, but only for this specific data element. Modern CPUs have direct hardware support for atomic operations, which makes them much faster than critical sections.

若有收获,就点个赞吧
0 人点赞
