Intro
Spark is designed to be highly accessible, offering imple APIs in: Python, Java, Scala, SQL.
It integrates closely with other Big Data tools.
Spark can run in Hadoop clusters and access any Haddop data source.
Spark performs rapid calculations on in-memory distributed datasets, referred to as RDDs.
RDDs are Resilient Distributed Datasets.
RDDs is a distributed collectionsof objects that can be cached in memory across cluster and can be manipulated in parallel;
Immutable –already defined RDDs canbe used asa basis togenerate derivative RDDs but are nevermutated;
Distributed – the dataset is often partitioned across multiple nodes for increased scalability and parallelism;
Key modules
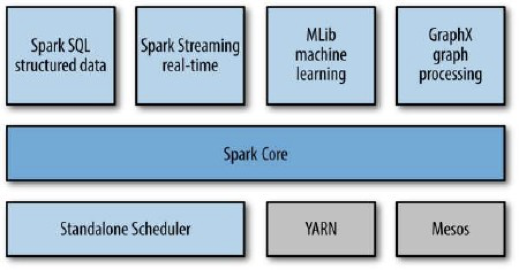
Spark Core contains the basic functionality of Spark, including components:
- Task scheduling;
- Memory management;
- Fault recovery;
- Interacting with storagesystems;
Spark SQL allows querying data viaSQL as well as the Apache Hive variant of SQL—Hive Query Language (HQL)
Spark Streaming is a Spark component that enables processing of live streams of data;
MLlib is a library containing common machine learning (ML) functionality;
GraphX is a library for manipulating graphs (e.g., a social network’s friend graph) and performing graph-parallel computations;
Spark vs Map Reduce
Map Reduce **places every result on a disk
Spark is much smarter, it keeps all results in** memory
**
load data in python
>>>lines = sc.textFile(“ulysis/4300.txt”)
>>> lines.count()
>>>blines= sc.textFile(“file:///home/cloudera/4300.txt”)
>>> blines.count()
33056
>>> blines.first**()

若有收获,就点个赞吧
0 人点赞
