MergeTree 原理解析
ClickHouse 拥有非常庞大的表引擎体系,而在这众多的表引擎中,又属合并树(MergeTree)表引擎及其家族系列(*MergeTree)最为强大,在生产环境的绝大部分场景中,都会使用此系列的表引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持 ALTER 相关操作。
特性:
- 索引:
- 一级索引
- 二级索引
- 跳数索引/稀疏索引分区
- 副本
- 采样 Sample
- update delete 删除和修改
合并树家族自身也拥有多种表引擎的变种。其中 MergeTree 作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在 MergeTree 的基础之上各有所长。例如 ReplacingMergeTree 表引擎具有删除重复数据的特性,而 SummingMergeTree 表引擎则会按照排序键自动聚合数据。如果给合并树系列的表引擎加上 Replicated 前缀,又会得到一组支持数据副本的表引擎,例如 ReplicatedMergeTree、ReplicatedReplacingMergeTree、ReplicatedSummingMergeTree 等。
合并树表引擎家族如表所示:正交
| 项目 | 类别 | 基础 |
|---|---|---|
| Replicated 支持数据副本 | ReplacingSumming Aggregating Collapsing VersionedCollapsing Graghite |
MergeTree 基础表引擎 |
虽然合并树的变种很多,但 MergeTree 表引擎才是根基。作为合并树家族系列中最基础的表引擎,MergeTree具备了该系列其他表引擎共有的基本特征,所以吃透了 MergeTree 表引擎的原理,就能够掌握该系列引擎的精髓。
MergeTree 创建方式
创建MergeTree数据表的方法,与普通的数据表的方法大致相同,但需要将 ENGINE 参数声明为 MergeTree(),其完整的语法如下所示:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],name2[type] [DEFAULT|MATERIALIZED|ALIAS expr],-- 省略...) ENGINE = MergeTree()[PARTITION BY expr][ORDER BY expr][PRIMARY KEY expr][SAMPLE BY expr][SETTINGS name=value,省略...]
MergeTree表引擎除了常规参数之外,还拥有一些独有的配置选项。接下来会着重介绍其中几个重要的参数,包括它们的使用方法和工作原理。但是在此之前,还是先介绍一遍它们的作用。
PARTITION BY [选填]
分区键,用于指定表数据以何种标准进行分区。分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。如果不声明分区键,则 ClickHouse 会生成一个名为 all 的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
CREATE TABLE table1 (id UInt8, name STRING) ENGINE = MergeTree()PARTITION by (id, name)ORDER BY id;
ORDER BY [必填]
排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序键既可以是单个列字段,例如 ORDER BY CounterID,也可以通过元组的形式使用多个列字段,例如ORDER BY(CounterID, EventDate)。当使用多个列字段排序时,以 ORDERBY(CounterID, EventDate)为例,在单个数据片段内,数据首先会以 CounterID 排序,相同 CounterID 的数据再按 EventDate 排序。
PRIMARY KEY [选填]
主键,顾名思义,声明后会依照主键字段生成一级索引,用于加速表查询。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用 ORDER BY 代为指定主键,无须刻意通过 PRIMARY KEY 声明。所以在一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree 主键允许存在重复数据(ReplacingMergeTree 可以去重)。
SAMPLE BY [选填]
抽样表达式,用于声明数据以何种标准进行采样。如果使用了此配置项,那么在主键的配置中也需要声明同样的表达式,抽样表达式需要配合 SAMPLE 子查询使用,这项功能对于选取抽样数据十分有用。例如:
CREATE TABLE table1 (id UInt8, name STRING) ENGINE= MergeTree(ORDER BY(CounterID,EventDate,intHash32(UserID)SAMPLE BY intHash32(UserID)
SETTINGS: index_granularity [选填]
index_granularity 对于 MergeTree 而言是一项非常重要的参数,它表示索引的粒度,默认值为 8192。也就是说,MergeTree 的索引在默认情况下,每间隔 8192 行数据才生成一条索引,其具体声明方式如下所示:
CREATE TABLE table1 (id UInt8, name STRING) ENGINE= MergeTree()ORDER BY(CounterID,EventDate,intHash32(UserID)SAMPLE BY intHash32(UserID)SETTINGS index_granularity = 8192;
8192 是一个神奇的数字,在 ClickHouse 中大量数值参数都有它的影子,可以被其整除(例如最小压缩块大小min_compress_block_size:65536)。通常情况下并不需要修改此参数,但理解它的工作原理有助于我们更好地使用 MergeTree。
SETTINGS: index_granularity_bytes [选填]
在 19.11 版本之前,ClickHouse 只支持固定大小的索引间隔,由 index_granularity 控制,默认为 8192。在新版本中,它增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,正是由 index_granularity_bytes 参数控制的,默认为 10M(10×1024×1024),设置为 0 表示不启动自适应功能。每条记录 1kb。
SETTINGS: enable_mixed_granularity_parts [选填]
设置是否开启自适应索引间隔的功能,默认开启。
SETTINGS: merge_with_ttl_timeout [选填]
从19.6 版本开始,MergeTree 提供了数据 TTL 的功能,可以选择性的让某个列,或者某个表设置自动过期时间。
SETTINGS: storage_policy [选填]
从 19.15 版本开始,MergeTree 提供了多路径的存储策略,为应对大数据量的存储提供了方案。
MergeTree 存储结构
创建一张 MergeTree 表数据:
CREATE TABLE test.table_merge1 (id UInt8,name STRING,date DateTime) ENGINE = MergeTree()PARTITION by toYYYYMM(date)ORDER BY id;INSERT INTO test.table_merge1 VALUES (4, 'aa', '2021-02-01 22:14:52');INSERT INTO test.table_merge1 VALUES (5, 'bb', '2021-02-02 22:14:52');
MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上,其完整的存储结构如下:
cd /var/lib/clickhouse/data/test/test.table_merge1
看到目录结构为:
drwxr-x--- 2 root root 221 Feb 11 18:59 202201_1_1_0drwxr-x--- 2 root root 221 Feb 11 18:59 202202_2_2_0drwxr-x--- 2 root root 6 Feb 11 18:59 detached-rw-r----- 1 root root 1 Feb 11 18:59 format_version.txt
前面两个文件夹是分区目录:进入其中任何一个。
-rw-r----- 1 root root 374 Feb 11 18:59 checksums.txt-rw-r----- 1 root root 78 Feb 11 18:59 columns.txt-rw-r----- 1 root root 1 Feb 11 18:59 count.txt-rw-r----- 1 root root 34 Feb 11 18:59 date.bin-rw-r----- 1 root root 48 Feb 11 18:59 date.mrk2-rw-r----- 1 root root 28 Feb 11 18:59 id.bin-rw-r----- 1 root root 48 Feb 11 18:59 id.mrk2-rw-r----- 1 root root 8 Feb 11 18:59 minmax_date.idx-rw-r----- 1 root root 32 Feb 11 18:59 name.bin-rw-r----- 1 root root 48 Feb 11 18:59 name.mrk2-rw-r----- 1 root root 4 Feb 11 18:59 partition.dat-rw-r----- 1 root root 2 Feb 11 18:59 primary.idx
一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件。接下来就逐一介绍它们的作用。
partition
分区目录,余下各类数据文件(primary.idx、[Column].mrk、[Column]. bin 等)都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分区的数据,永远不会被合并在一起。更多关于数据分区的细节会在后面节阐述。
checksums.txt
校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt 等)的 size 大小及 size 的哈希值,用于快速校验文件的完整性和正确性。
columns.txt
列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息,例如:
[root@bigdata05]# cat columns.txt# columns format version: 1# 3 columns:# `id` UInt8# `name` String# `date` DateTime
count.txt
计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数,例如:
[root@bigdata05]# cat count.txt# 2
primary.idx
一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张 MergeTree 表只能声明一次一级索引(通过 ORDER BY 或者 PRIMARY KEY)。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
[Column].bin
数据文件,使用压缩格式存储,默认为 LZ4 压缩格式,用于存储某一列的数据。由于 MergeTree 采用列式存储,所以每一个列字段都拥有独立的 .bin 数据文件,并以列字段名称命名(例如 CounterID.bin、EventDate.bin 等)。
[Column].mrk
列字段标记文件,使用二进制格式存储。标记文件中保存了 .bin 文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与 .bin 文件一一对应,所以 MergeTree 通过标记文件建立了primary.idx 稀疏索引与 .bin 数据文件之间的映射关系。即首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从 .bin 文件中读取数据。由于 .mrk 标记文件与 .bin 文件一一对应,所以 MergeTree 中的每个列字段都会拥有与其对应的 .mrk 标记文件(例如 CounterID.mrk、EventDate.mrk 等)。
[Column].mrk2
如果使用了自适应大小的索引间隔,则标记文件会以 .mrk2 命名。它的工作原理和作用与 .mrk 标记文件相同。
partition.dat 与 minmax_[Column].idx
如果使用了分区键,例如 PARTITION BYtoYYYYMM(date) ,则会额外生成 partition.dat 与 minmax 索引文件 minmax_date.idx,它们均使用二进制格式存储。partition.dat 用于保存当前分区下分区表达式最终生成的值;而 minmax_date.idx 用于记录当前分区下分区字段对应原始数据的最小和最大值。例如 date 字段对应的原始数据为 2019-05-01、2019-05-05,分区表达式为 PARTITION BY toYYYYMM(date)。partition.dat 中保存的值将会是 2019-05,而 minmax_date.idx 中保存的值将会是 2019-05-012019-05-05。在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围。
skpidx[Column].idx与skpidx[Column].mrk
如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。二级索引在 ClickHouse 中又称跳数索引,目前拥有 minmax、set、ngrambf_v1 和 tokenbf_v1 四种类型。这些索引的最终目标与一级稀疏索引相同,都是为了进一步减少所需扫描的数据范围,以加速整个查询过程。
MergeTree 数据分区
通过先前的介绍已经知晓在 MergeTree 中,数据是以分区目录的形式进行组织的,每个分区独立分开存储。借助这种形式,在对 MergeTree 进行数据查询时,可以有效跳过无用的数据文件,只使用最小的分区目录子集。
数据的分区规则
语法:
CREATE TABLE table1(id Int32,name STRING,date DateTime) ENGINE = MergeTree()PARTITION by toYYYYMM(date)ORDER BY date;
MergeTree 数据分区的规则由分区 ID 决定,而具体到每个数据分区所对应的 ID,则是由分区键的取值决定的。分区键支持使用任何一个或一组字段表达式声明,其业务语义可以是年、月、日或者组织单位等任何一种规则。针对取值数据类型的不同,分区ID的生成逻辑目前拥有四种规则:
- 不指定分区键:如果不使用分区键,即不使用 PARTITION BY 声明任何分区表达式,则分区 ID 默认取名为all,所有的数据都会被写入这个 all 分区。
- 使用整型:如果分区键取值属于整型(兼容 UInt64,包括有符号整型和无符号整型),且无法转换为日期类型 YYYYMMDD 格式,则直接按照该整型的字符形式输出,作为分区 ID 的取值。
- 使用日期类型:如果分区键取值属于日期类型,或者是能够转换为 YYYYMMDD 格式的整型,则使用按照 YYYYMMDD 进行格式化后的字符形式输出,并作为分区 ID 的取值。
- 使用其他类型:如果分区键取值既不属于整型,也不属于日期类型,例如 String、Float 等,则通过 128 位 Hash 算法取其 Hash 值作为分区 ID 的取值。数据在写入时,会对照分区 ID 落入相应的数据分区。
下图是一些分区的使用案例: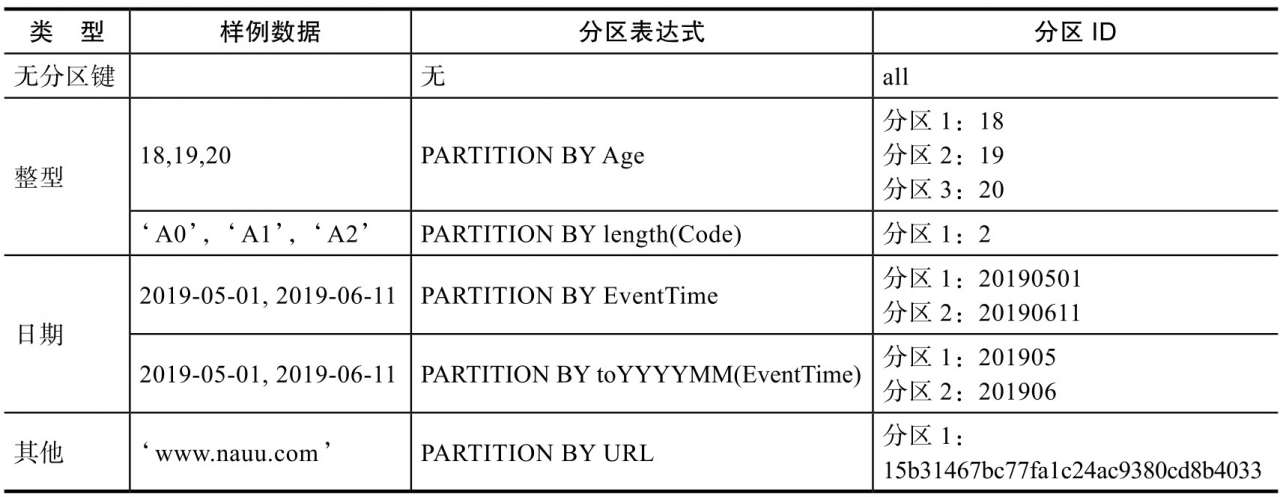
如果通过元组的方式使用多个分区字段,则分区 ID 依旧是根据上述规则生成的,只是多个 ID 之间通过“-”符号依次拼接。例如按照上述表格中的例子,使用两个字段分区:
PARTITION BY (length(Code),EventTime);
则最终的分区 ID 会是下面的模样:
2-201905012-20190611
分区目录的命名规则
通过上一小节的介绍,我们已经知道了分区 ID 的生成规则。但是如果进入数据表所在的磁盘目录后,会发现 MergeTree 分区目录的完整物理名称并不是只有 ID 而已,在 ID 之后还跟着一串奇怪的数字,例如 201905_1_1_0。那么这些数字又代表着什么呢?
众所周知,对于 MergeTree 而言,它最核心的特点是其分区目录的合并动作。但是我们可曾想过,从分区目录的命名中便能够解读出它的合并逻辑。在这一小节会着重对命名公式中各分项进行解读,而关于具体的目录合并过程将会留在后面讲解。一个完整分区目录的命名公式如下所示:
PartitionID_ MinBlockNum_MaxBlockNum_Level
如果对照着示例数据,那么数据与公式的对照关系会如同下图所示一般:
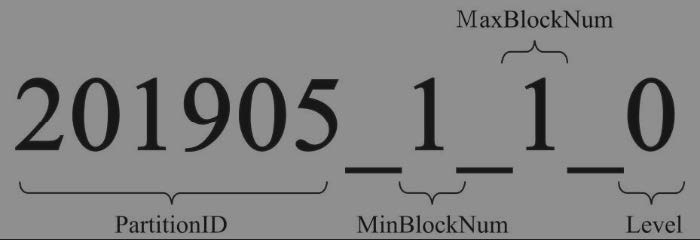
上图中,201905 表示分区目录的 ID; 1_1 分别表示最小的数据块编号与最大的数据块编号;而最后的 _0 则表示目前合并的层级。接下来开始分别解释它们的含义:
- PartitionID:分区 ID。
- MinBlockNum 和 MaxBlockNum:顾名思义,最小数据块编号与最大数据块编号。ClickHouse 在这里的命名似乎有些歧义,很容易让人与稍后会介绍到的数据压缩块混淆。但是本质上它们毫无关系,这里的 BlockNum 是一个整型的自增长编号。如果将其设为 n 的话,那么计数 n 在单张 MergeTree 数据表内全局累加,n 从 1 开始,每当新创建一个分区目录时,计数 n 就会累积加 1。对于一个新的分区目录而言,MinBlockNum 与 MaxBlockNum 取值一样,同等于 n,例如 201905_1_1_0、201906_2_2_0 以此类推。但是也有例外,当分区目录发生合并时,对于新产生的合并目录 MinBlockNum 与 MaxBlockNum 有着另外的取值规则。
- Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高表示年龄越大。Level 计数与 BlockNum 有所不同,它并不是全局累加的。对于每一个新创建的分区目录而言,其初始值均为 0。之后,以分区为单位,如果相同分区发生合并动作,则在相应分区内计数累积加 1。
分区目录的合并过程
MergeTree 的分区目录和传统意义上其他数据库有所不同。首先,MergeTree 的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。其次,它的分区目录在建立之后也并不是一成不变的。在其他某些数据库的设计中,追加数据后目录自身不会发生变化,只是在相同分区目录中追加新的数据文件。而 MergeTree 完全不同,伴随着每一批数据的写入(一次 INSERT 语句),MergeTree 都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15 分钟,也可以手动执行 optimize 查询语句), ClickHouse 会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认 8 分钟)。
属于同一个分区的多个目录,在合并之后会生成一个全新的目录,目录中的索引和数据文件也会相应地进行合并。新目录名称的合并方式遵循以下规则,其中:
- MinBlockNum:取同一分区内所有目录中最小的 MinBlockNum 值。
- MaxBlockNum:取同一分区内所有目录中最大的 MaxBlockNum 值。
- Level:取同一分区内最大 Level 值并加 1。
合并目录名称的变化过程如下图所示:
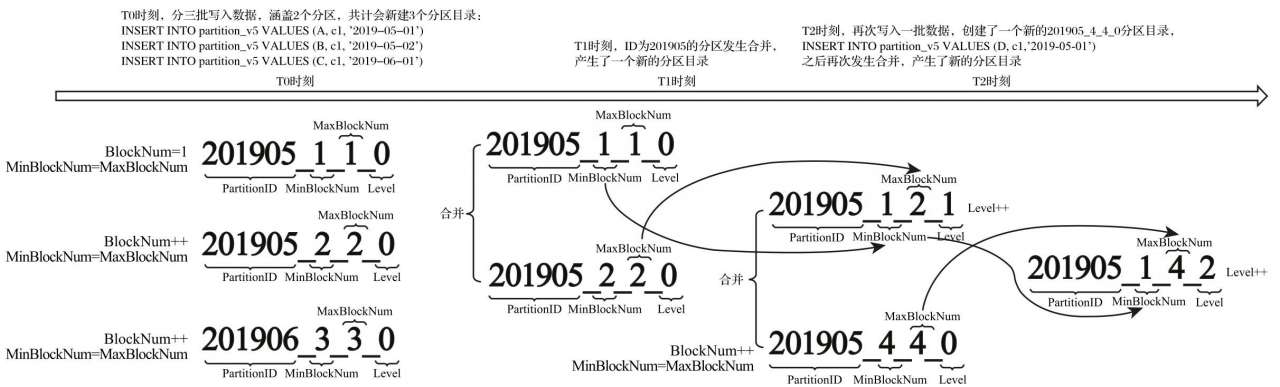
在上图中,partition_v5 测试表按日期字段格式分区,即 PARTITION BY toYYYYMM(EventTime), T 表示时间。假设在 T0 时刻,首先分 3 批(3 次 INSERT 语句)写入 3 条数据人:
INSERT INTO partition_v5 VALUES (A, c1, '2019-05-01')INSERT INTO partition_v5 VALUES (B, c1, '2019-05-02')INSERT INTO partition_v5 VALUES (c, c1, '2019-06-01')
按照目录规,上述代码会创建 3 个分区目录。分区目录的名称由 PartitionID、MinBlockNum、MaxBlockNum 和 Level 组成,其中 PartitionID 根据前面介绍的生成规则,3 个分区目录的 ID 依次为 201905、201905 和 201906。而对于每个新建的分区目录而言,它们的 MinBlockNum 与 MaxBlockNum 取值相同,均来源于表内全局自增的 BlockNum。BlockNum 初始为 1,每次新建目录后累计加 1。所以,3 个分区目录的 MinBlockNum 与 MaxBlockNum 依次为 0_0、1_1 和 2_2。最后是 Level 层级,每个新建的分区目录初始 Level 都是 0。所以 3 个分区目录的最终名称分别是 201905_1_1_0、201905_2_2_0 和 201906_3_3_0。
假设在 T1 时刻,MergeTree 的合并动作开始了,那么属于同一分区的 201905_1_1_0 与 201905_2_2_0 目录将发生合并。从上图所示过程中可以发现,合并动作完成后,生成了一个新的分区 201905_1_2_1。根据本节所述的合并规则,其中,MinBlockNum 取同一分区内所有目录中最小的 MinBlockNum 值,所以是 1; MaxBlockNum 取同一分区内所有目录中最大的 MaxBlockNum 值,所以是 2;而 Level 则取同一分区内,最大 Level 值加 1,所以是 1。而后续 T2 时刻的合并规则,只是在重复刚才所述的过程而已。
至此,大家已经知道了分区 ID、目录命名和目录合并的相关规则。最后,再用一张完整的示例图作为总结,描述 MergeTree 分区目录从创建、合并到删除的整个过程,如下图所示:
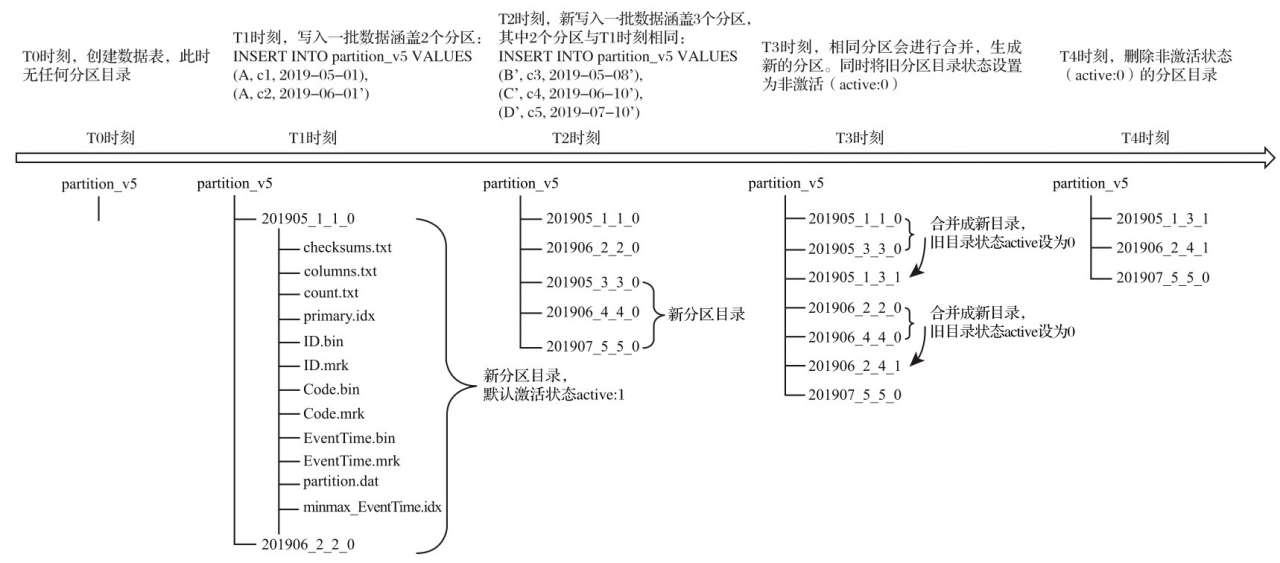
从上图中应当能够发现,分区目录在发生合并之后,旧的分区目录并没有被立即删除,而是会存留一段时间。但是旧的分区目录已不再是激活状态(active=0),所以在数据查询时,它们会被自动过滤掉。
说明:
- 压缩:到底用了好还不是还好呢? 网络密集型有用,计算密集型无用,ClickHouse 应该都是正向的效果,每个分区当中的, 每个列一个数据文件每隔 1M 进行一次压缩!
- OLAP : 列式存储 + 压缩 + 排序
- 数据排序了,查询效率就会高很多。
- 实际企业中,大量的查询分析,都是针对大宽表,列裁剪,把底层存储设计成列式存储。
- 正常情况来讲,压缩是能减少数据量的。列式存储中,每个文件存储的数据,都是相同的类型,而且这个列式存储文件还排序了;相同的数据是相邻的,数据的压缩率更高了。
MergeTree 系列表引擎
这个系列当中:
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- ……
目前在 ClickHouse 中,按照特点可以将表引擎大致分成 6 个系列,分别是合并树、外部存储、内存、文件、接口和其他,每一个系列的表引擎都有着独自的特点与使用场景。在它们之中,最为核心的当属 MergeTree 系列,因为它们拥有最为强大的性能和最广泛的使用场合。
MergeTree 有两层含义:其一,表示合并树表引擎家族;其二,表示合并树家族中最基础的 MergeTree 表引擎。而在整个家族中,除了基础表引擎 MergeTree 之外,常用的表引擎还有 ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree 和 VersionedCollapsingMergeTree。每一种合并树的变种,在继承了基础 MergeTree 的能力之后,又增加了独有的特性。其名称中的“合并”二字奠定了所有类型 MergeTree 的基因,它们的所有特殊逻辑,都是在触发合并的过程中被激活的。
MergeTree
MergeTree 作为家族系列最基础的表引擎,提供了很多丰富的功能。对于它们的运行机理,在上文中已经进行了详细介绍。本文档将再补充一个特性:数据 TTL。
TTL:time to live 生命周期。
- 针对单独的列指定 TTL : 如果超过了 TTL 之后,当前类的数据被清空,全部置为默认值。
- 针对表指定 TTL: 如果这个 TTL 到期了, 整个表清空。
数据 TTL
TTL 即 Time To Live,顾名思义,它表示数据的存活时间。在 MergeTree 中,可以为某个列字段或整张表设置 TTL。当时间到达时,如果是列字段级别的 TTL,则会删除这一列的数据(会被还原为数据类型的默认值);如果是表级别的 TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的 TTL,则会以先到期的那个为主。
无论是列级别还是表级别的 TTL,都需要依托某个 DateTime 或 Date 类型的字段,通过对这个时间字段的 INTERVAL 操作,来表述 TTL 的过期时间,例如:
TTL time_col + INTERVAL 3 DAY
上述语句表示数据的存活时间是 time_col 时间的 3 天之后。
INTERVAL 完整的操作包括 SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER 和 YEAR。
列级别 TTL
如果想要设置列级别的 TTL,则需要在定义表字段的时候,为它们声明 TTL 表达式,主键字段不能被声明 TTL。以下面的语句为例:
CREATE TABLE ttl_table_v1 (id String,create_time DateTime,code String TTL create_time + INTERVAL 10 SECOND,type UInt8 TTL create_time + INTERVAL 10 SECOND) ENGINE =MergeTreePARTITION BY toYYYYMM(create_time)ORDER BY id;
其中,create_time 是日期类型,列字段 code 与 type 均被设置了 TTL,它们的存活时间是在 create_time 的取值基础之上向后延续 10 秒。
optimize 命令可以强制触发TTL清理:
optimize TABLE ttl_table_v1 FINAL;
如果想要修改列字段的 TTL,或是为已有字段添加 TTL,则可以使用 ALTER 语句,示例如下:
ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY;
目前 ClickHouse 没有提供取消列级别 TTL 的方法。
表级别 TTL
如果想要为整张数据表设置 TTL,需要在 MergeTree 的表参数中增加 TTL 表达式,例如下面的语句:
CREATE TABLE ttl_table_v2 (id String,create_time DateTime,code String TTL create_time + INTERVAL 1 MINUTE,type UInt8) ENGINE = MergeTreePARTITION BY toYYYYMM(create_time)ORDER BY create_timeTTL create_time + INTERVAL 1 DAY;
ttl_table_v2 整张表被设置了 TTL,当触发 TTL 清理时,那些满足过期时间的数据行将会被整行删除。同样,表级别的TTL也支持修改,修改的方法如下:
ALTER TABLE ttl_table_v2 MODIFY TTL create_time + INTERVAL 3 DAY;
表级别 TTL 目前也没有取消的方法。
这里还有几条TTL使用的小知识
(1)TTL 默认的合并频率由 MergeTree 的 merge_with_ttl_timeout 参数控制
默认 86400 秒,即 1 天。它维护的是一个专有的 TTL 任务队列。有别于 MergeTree 的常规合并任务,如果这个值被设置的过小,可能会带来性能损耗
(2)除了被动触发TTL合并外,也可以使用 optimize 命令强制触发合并
例如触发一个分区合并:
optimize TABLE table_name;
触发所有分区合并:
optimize TABLE table_name FINAL;
(3)ClickHouse目前虽然没有提供删除 TTL 声明的方法,但是提供了控制全局 TTL 合并任务的启停方法
SYSTEM STOP/START TTL MERGES;
虽然还不能做到按每张 MergeTree 数据表启停,但聊胜于无吧。
多路径存储策略
在 ClickHouse 19.15 版本之前,MergeTree 只支持单路径存储,所有的数据都会被写入 config.xml 配置中 path 指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。为了解决这个痛点,从 19.15版本开始,MergeTree 实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
ReplacingMergeTree
作用:去重。
虽然 MergeTree 拥有主键,但是它的主键却没有唯一键的约束。这意味着即便多行数据的主键相同,它们还是能够被正常写入。在某些使用场合,用户并不希望数据表中含有重复的数据。
ReplacingMergeTree 就是在这种背景下为了数据去重而设计的,它能够在合并分区时删除重复的数据。它的出现,确实也在一定程度上解决了重复数据的问题。
创建一张 ReplacingMergeTree 表的方法与创建普通 MergeTree 表无异,只需要替换 Engine:
ENGINE = ReplacingMergeTree(ver);
其中,ver是选填参数,会指定一个 UInt*、Date 或者 DateTime 类型的字段作为版本号。这个参数决定了数据去重时所使用的算法。
接下来,用一个具体的示例说明它的用法。首先执行下面的语句创建数据表:
CREATE TABLE replace_table (id String,code String,create_time DateTime) ENGINE = ReplacingMergeTree()PARTITION BY toYYYYMM(create_time)ORDER BY (id, code)PRIMARY KEY id;
插入数据:
INSERT INTO nxdb9.replace_table VALUES ('A001', 'C1', '2019-05-10 17:00:00');INSERT INTO nxdb9.replace_table VALUES ('A001', 'C1', '2019-05-10 17:00:00');INSERT INTO nxdb9.replace_table VALUES ('A001', 'C2', '2019-05-10 17:00:00');
注意这里的 ORDER BY 是去除重复数据的关键,排序键 ORDER BY 所声明的表达式是后续作为判断数据是否重复的依据。在这个例子中,数据会基于 id 和 code 两个字段去重。假设此时表内的测试数据如下:
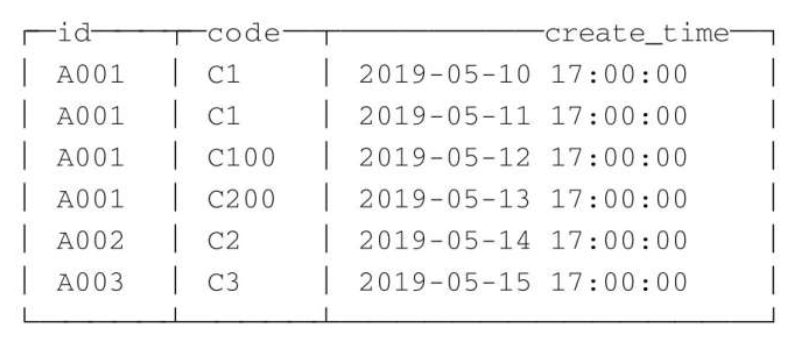
那么在执行 optimize 强制触发合并后,会按照 id 和 code 分组,保留分组内的最后一条(观察 create_time 日期字段):
optimize TABLE replace_table FINAL;
将其余重复的数据删除:
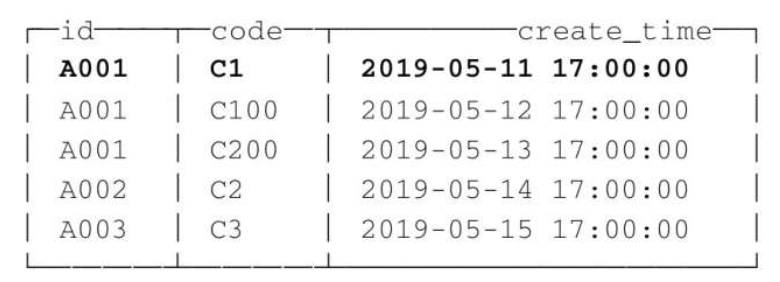
从执行的结果来看,ReplacingMergeTree 在去除重复数据时,确实是以 ORDER BY 排序键为基准的,而不是 PRIMARY KEY。因为在上面的例子中,ORDER BY 是(id, code),而 PRIMARY KEY 是 id,如果按照 id 值去除重复数据,则最终结果应该只剩下 A001、A002 和 A003 三行数据。
到目前为止,ReplacingMergeTree 看起来完美地解决了重复数据的问题。事实果真如此吗?现在尝试写入一批新数据:
INSERT INTO TABLE replace_table VALUES('A001', 'C1', '2019-08-10 17:00:00');INSERT INTO TABLE replace_table VALUES('A001', 'C1', '2019-08-11 17:00:00');INSERT INTO TABLE replace_table VALUES('A001', 'C1', '2019-08-12 17:00:00');
写入之后,执行optimize强制分区合并,并查询数据:
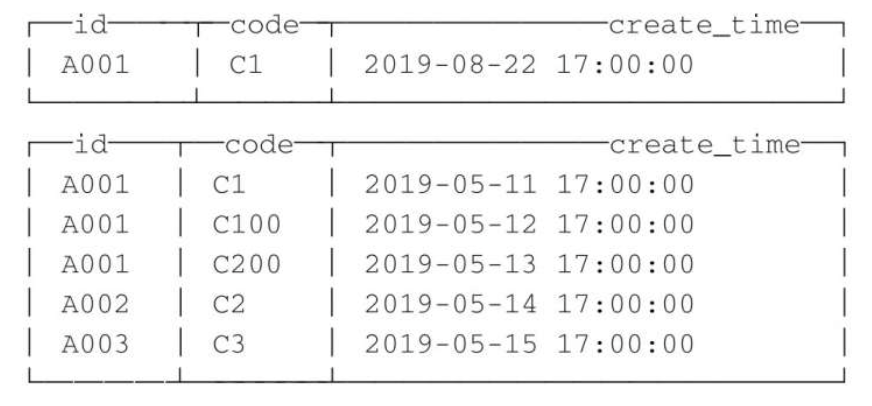
再次观察返回的数据,可以看到 A001:C1 依然出现了重复。这是怎么回事呢?这是因为 ReplacingMergeTree 是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。这就是上面说 ReplacingMergeTree 只是在一定程度上解决了重复数据问题的原因。
现在接着说明 ReplacingMergeTree 版本号的用法。以下面的语句为例:
CREATE TABLE replace_table_v (id String,code String,create_time DateTime) ENGINE = ReplacingMergeTree(create_time)PARTITION BY toYYYYMM(create_time)ORDER BY id
replace_table_v 基于 id 字段去重,并且使用 create_time 字段作为版本号,假设表内的数据如下所示:

那么在删除重复数据的时候,会保留同一组数据内 create_time 时间最长的那一行:

在知道了 ReplacingMergeTree 的使用方法后,现在简单梳理一下它的处理逻辑:
- 使用 ORBER BY 排序键作为判断重复数据的唯一键。
- 只有在合并分区的时候才会触发删除重复数据的逻辑。
- 以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
- 在进行数据去重时因为分区内的数据已经基于 ORBER BY 进行了排序,所以能够找到那些相邻的重复数据。
- 数据去重策略有两种:
- 如果没有设置 ver 版本号,则保留同一组重复数据中的最后一行。
- 如果设置了 ver 版本号,则保留同一组重复数据中 ver 字段取值最大的那一行。
SummingMergeTree
假设有这样一种查询需求:终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY 条件明确,且不会随意改变)。
对于这样的查询场景,在 ClickHouse 中如何解决呢?最直接的方案就是使用 MergeTree 存储数据,然后通过 GROUP BY 聚合查询,并利用 SUM 聚合函数汇总结果。这种方案存在两个问题:
- 存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据。
- 存在额外的查询开销:终端用户只关心汇总结果,虽然 MergeTree 性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗。
SummingMergeTree 就是为了应对这类查询场景而生的。顾名思义,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
在先前介绍 MergeTree 原理时曾提及,在 MergeTree 的每个数据分区内,数据会按照 ORDER BY 表达式排序。主键索引也会按照 PRIMARY KEY 表达式取值并排序。而 ORDER BY 可以指代主键,所以在一般情形下,只单独声明 ORDER BY 即可。此时,ORDER BY 与 PRIMARY KEY 定义相同,数据排序与主键索引相同。
如果需要同时定义 ORDER BY 与 PRIMARY KEY,通常只有一种可能,那便是明确希望 ORDER BY 与 PRIMARY KEY 不同。这种情况通常只会在使用 SummingMergeTree 或 AggregatingMergeTree 时才会出现。这是为何呢?这是因为 SummingMergeTree 与 AggregatingMergeTree 的聚合都是根据 ORDER BY 进行的。由此可以引出两点原因:主键与聚合的条件定义分离,为修改聚合条件留下空间。
现在用一个示例说明。假设一张 SummingMergeTree 数据表有 A、B、C、D、E、F 六个字段,如果需要按照 A、B、C、D 汇总,则有:
ORDER BY (A, B, C, D)
但是如此一来,此表的主键也被定义成了 A、B、C、D。而在业务层面,其实只需要对字段 A 进行查询过滤,应该只使用 A 字段创建主键。所以,一种更加优雅的定义形式应该是:
ORDER BY (A, B, C, D)PRIMARY KEY A
如果同时声明了 ORDER BY 与 PRIMARY KEY, MergeTree 会强制要求 PRIMARY KEY 列字段必须是 ORDER BY 的前缀。例如下面的定义是错误的:
ORDER BY (B, C, D)PRIMARY KEY A
PRIMARY KEY 必须是 ORDER BY 的前缀:
ORDER BY (B, C, D)PRIMARY KEY B
这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。
假设现在业务发生了细微的变化,需要减少字段,将先前的 A、B、C、D 改为按照 A、B 聚合汇总,则可以按如下方式修改排序键:
ALTER TABLE table_name MODIFY ORDER BY (A, B);
在修改 ORDER BY 时会有一些限制,只能在现有的基础上减少字段。如果是新增排序字段,则只能添加通过 ALTER ADD COLUMN 新增的字段。但是 ALTER 是一种元数据的操作,修改成本很低,相比不能被修改的主键,这已经非常便利了。
现在开始正式介绍 SummingMergeTree 的使用方法。表引擎的声明方式如下所示:
ENGINE=SummingMergeTree((col1, col2, …))
其中,col1、col2 为 columns 参数值,这是一个选填参数,用于设置除主键外的其他数值类型字段,以指定被 SUM 汇总的列字段。如若不填写此参数,则会将所有非主键的数值类型字段进行 SUM 汇总。接来下用一组示例说明它的使用方法:
CREATE TABLE summing_table (id String,city String,v1 UInt32,v2 Float64,create_time DateTime) ENGINE=SummingMergeTree()PARTITION BY toYYYYMM(create_time)ORDER BY (id,city)PRIMARY KEY id;
插入数据:
INSERT INTO summing_table VALUES('A001', 'wuhan', 10, 20, '2019-08-10 17:00:00');INSERT INTO summing_table VALUES('A001', 'wuhan', 20, 30, '2019-08-20 17:00:00');INSERT INTO summing_table VALUES('A001', 'zhuhai', 20, 30, '2019-08-10 17:00:00');INSERT INTO summing_table VALUES('A001', 'wuhan', 10, 20, '2019-02-10 09:00:00');INSERT INTO summing_table VALUES('A002', 'wuhan', 60, 50, '2019-10-10 17:00:00');
查询数据:
SELECT * FROM summing_table;
注意,这里的 ORDER BY 是一项关键配置,SummingMergeTree 在进行数据汇总时,会根据 ORDER BY 表达式的取值进行聚合操作。假设此时表内的数据如下所示: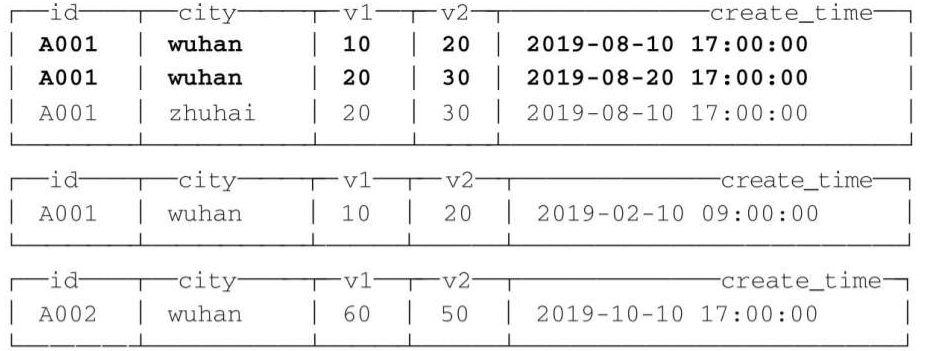
执行 optimize 强制进行触发和合并操作:
optimize TABLE summing_table FINAL;
再次查询,表内数据会变成下面的样子: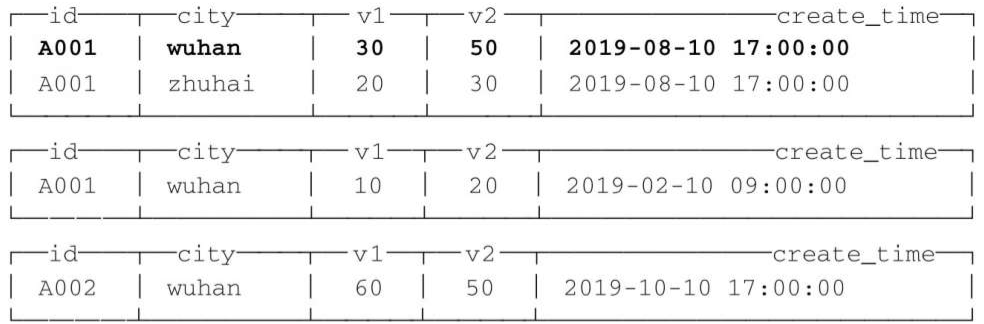
至此能够看到,在第一个分区内,同为 A001:wuhan 的两条数据汇总成了一行。其中,v1 和 v2 被 SUM 汇总,不在汇总字段之列的 create_time 则选取了同组内第一行数据的取值。而不同分区之间,数据没有被汇总合并。
SummingMergeTree 也支持嵌套类型的字段,在使用嵌套类型字段时,需要被SUM汇总的字段名称必须以Map后缀结尾,例如:
CREATE TABLE summing_table_nested (id String,nestMap Nested(id UInt32,key UInt32,val UInt64),create_time DateTime) ENGINE =SummingMergeTree()PARTITION BY toYYYYMM(create_time)ORDER BY id;
在使用嵌套数据类型的时候,默认情况下,会以嵌套类型中第一个字段作为聚合条件Key。假设表内的数据如下所示:
上述示例中数据会按照第一个字段id聚合,汇总后的数据会变成下面的样子:
数据汇总的逻辑示意如下所示:
[(1,10,40)] + [(1,20,50)]->[(1,30,90)][(2,30,60)]->[(2,30,60)]
在使用嵌套数据类型的时候,也支持使用复合 Key 作为数据聚合的条件。为了使用复合 Key,在嵌套类型的字段中,除第一个字段以外,任何名称是以 Key、Id 或 Type 为后缀结尾的字段,都将和第一个字段一起组成复合Key。
例如将上面的例子中小写 key 改为 Key:
nestMap Nested (id UInt32,Key UInt32,val UInt64)
上述例子中数据会以 id 和 Key 作为聚合条件。在知道了 SummingMergeTree 的使用方法后,现在简单梳理一下它的处理逻辑:
- 用 ORBER BY 排序键作为聚合数据的条件 Key。
- 只有在合并分区的时候才会触发汇总的逻辑。
- 以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合 Key 相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
- 如果在定义引擎时指定了 columns 汇总列(非主键的数值类型字段),则 SUM 汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段。
- 在进行数据汇总时,因为分区内的数据已经基于 ORBER BY 排序,所以能够找到相邻且拥有相同聚合 Key 的数据。
- 在汇总数据时,同一分区内,相同聚合 Key 的多行数据会合并成一行。其中,汇总字段会进行 SUM 计算;对于那些非汇总字段,则会使用第一行数据的取值。
- 支持嵌套结构,但列字段名称必须以 Map 后缀结尾。嵌套类型中,默认以第一个字段作为聚合 Key。除第一个字段以外,任何名称以 Key、Id 或 Type 为后缀结尾的字段,都将和第一个字段一起组成复合 Key。
AggregatingMergeTree
有过数据仓库建设经验的读者一定知道“数据立方体”的概念,这是一个在数据仓库领域十分常见的模型。它通过以空间换时间的方法提升查询性能,将需要聚合的数据预先计算出来,并将结果保存起来。在后续进行聚合查询的时候,直接使用结果数据。
AggregatingMergeTree 就有些许数据立方体的意思,它能够在合并分区的时候,按照预先定义的条件聚合数据。同时,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内。将同一分组下的多行数据聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。可以说,AggregatingMergeTree 是 SummingMergeTree 的升级版,它们的许多设计思路是一致的,例如同时定义 ORDER BY 与 PRIMARY KEY 的原因和目的。但是在使用方法上,两者存在明显差异,应该说 AggregatingMergeTree 的定义方式是 MergeTree 家族中最为特殊的一个。
声明使用 AggregatingMergeTree 的方式如下:
ENGINE = AggregatingMergeTree()
AggregatingMergeTree 没有任何额外的设置参数,在分区合并时,在每个数据分区内,会按照 ORDER BY 聚合。而使用何种聚合函数,以及针对哪些列字段计算,则是通过定义 AggregateFunction 数据类型实现的。以下面的语句为例:
CREATE TABLE agg_table (id String,city String,code AggregateFunction(uniq, String),value AggregateFunction(sum, UInt32),create_time DateTime) ENGINE= AggregatingMergeTree()PARTITION BY toYYYYMM(create_time)ORDER BY (id,city)PRIMARY KEY id;
上例中列字段 id 和 city 是聚合条件,等同于下面的语义:
GROUP BY id,city
而 code 和 value 是聚合字段,其语义等同于:
UNIQ(code),SUM(value);
AggregateFunction 是 ClickHouse 提供的一种特殊的数据类型,它能够以二进制的形式存储中间状态结果。其使用方法也十分特殊,对于 AggregateFunction 类型的列字段,数据的写入和查询都与寻常不同。在写入数据时,需要调用 *State 函数;而在查询数据时,则需要调用相应的 Merge 函数。其中,表示定义时使用的聚合函数。例如示例中定义的 code 和 value,使用了 uniq 和 sum 函数:
code AggregateFunction(uniq,String),value AggregateFunction(sum,UInt32),
那么,在写入数据时需要调用与 uniq、sum 对应的 uniqState 和 sumState 函数,并使用 INSERT SELECT 语法:
INSERT INTO TABLE agg_tableSELECT 'A000', 'wuhan', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
在查询数据时,如果直接使用列名访问 code 和 value,将会是无法显示的二进制形式。此时,需要调用与 uniq、sum 对应的 uniqMerge、sumMerge 函数:
SELECT id,city,uniqMerge(code),sumMerge(value) FROM agg_table GROUP BY id,city;
讲到这里,你是否会认为 AggregatingMergeTree 使用起来过于烦琐了?连正常进行数据写入都需要借助 INSERT…SELECT 的句式并调用特殊函数。如果直接像刚才示例中那样使用 AggregatingMergeTree,确实会非常麻烦。不过各位读者并不需要忧虑,因为目前介绍的这种使用方法,并不是它的主流用法。
AggregatingMergeTree 更为常见的应用方式是结合物化视图使用,将它作为物化视图的表引擎。而这里的物化视图是作为其他数据表上层的一种查询视图,如下图所示: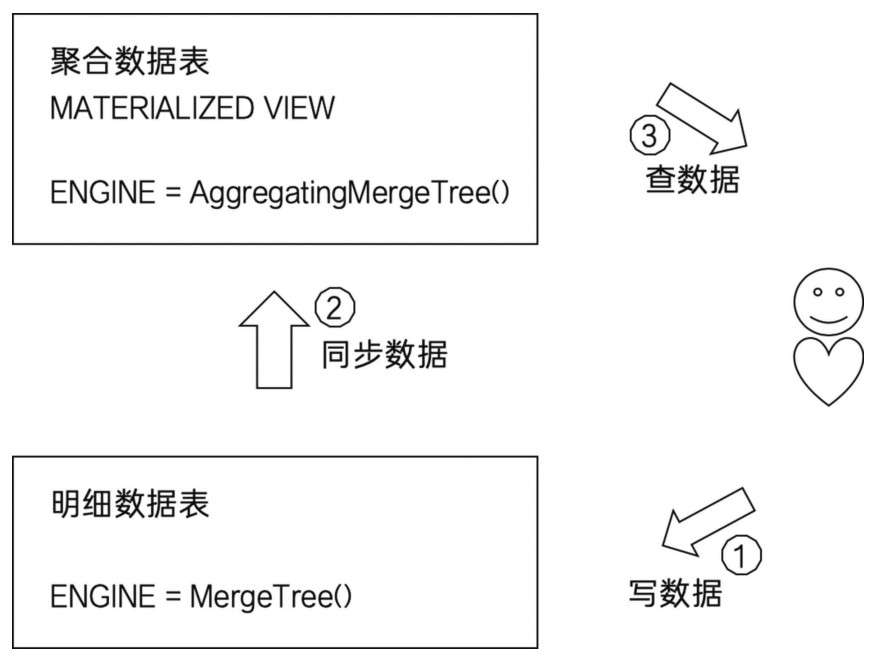
现在用一组示例说明。首先,建立明细数据表,也就是俗称的底表:
CREATE TABLE agg_table_basic (id String,city String,code String,value UInt32) ENGINE=MergeTree()PARTITION BY cityORDER BY (id,city);
通常会使用 MergeTree 作为底表,用于存储全量的明细数据,并以此对外提供实时查询。接着,新建一张物化视图:
CREATE MATERIALIZED VIEW agg_viewENGINE=AggregatingMergeTree()PARTITION BY cityORDER BY (id,city)AS SELECTid,city,uniqState(code) AS code,sumState(value) AS valueFROMagg_table_basicGROUP BYid, city;
物化视图使用 AggregatingMergeTree 表引擎,用于特定场景的数据查询,相比 MergeTree,它拥有更高的性能。在新增数据时,面向的对象是底表 MergeTree:
INSERT INTO TABLE agg_table_basic VALUES('A000', 'wuhan', 'code1', 100), ('A000', 'wuhan', 'code2', 200), ('AO00', 'zhuhai', 'code1', 200);
数据会自动同步到物化视图,并按照 AggregatingMergeTree 引擎的规则处理:
SELECT shop_code, uniqMerge(name), sumMerge(out_count) FROM agg_view GROUP BY shop_code,product_code;
结果如下:
接下来,简单梳理一下 AggregatingMergeTree 的处理逻辑:
- 用 ORBER BY 排序键作为聚合数据的条件 Key。
- 使用 AggregateFunction 字段类型定义聚合函数的类型以及聚合的字段。
- 只有在合并分区的时候才会触发聚合计算的逻辑。
- 以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合 Key 相同的数据会被合并计算,而不同分区之间的数据则不会被计算。
- 在进行数据计算时,因为分区内的数据已经基于 ORBER BY 排序,所以能够找到那些相邻且拥有相同聚合 Key 的数据。
- 在聚合数据时,同一分区内,相同聚合 Key 的多行数据会合并成一行。对于那些非主键、非 AggregateFunction 类型字段,则会使用第一行数据的取值。
- AggregateFunction 类型的字段使用二进制存储,在写入数据时,需要调用
*State函数;而在查询数据时,则需要调用相应的*Merge函数。其中,*表示定义时使用的聚合函数。 - AggregatingMergeTree 通常作为物化视图的表引擎,与普通 MergeTree 搭配使用。
CollapsingMergeTree
假设现在需要设计一款数据库,该数据库支持对已经存在的数据实现行级粒度的修改或删除,你会怎么设计?一种最符合常理的思维可能是:首先找到保存数据的文件,接着修改这个文件,删除或者修改那些需要变化的数据行。然而在大数据领域,对于 ClickHouse 这类高性能分析型数据库而言,对数据源文件修改是一件非常奢侈且代价高昂的操作。相较于直接修改源文件,它们会将修改和删除操作转换成新增操作,即以增代删。
CollapsingMergeTree 就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个 sign 标记位字段,记录数据行的状态。如果 sign 标记为 1,则表示这是一行有效的数据;如果 sign 标记为 -1,则表示这行数据需要被删除。当 CollapsingMergeTree 分区合并时,同一数据分区内,sign 标记为 1 和 -1 的一组数据会被抵消删除。这种 1 和 -1 相互抵消的操作,犹如将一张瓦楞纸折叠了一般。
这种直观的比喻,想必也正是折叠合并树(CollapsingMergeTree)名称的由来,其折叠的过程如如下所示:
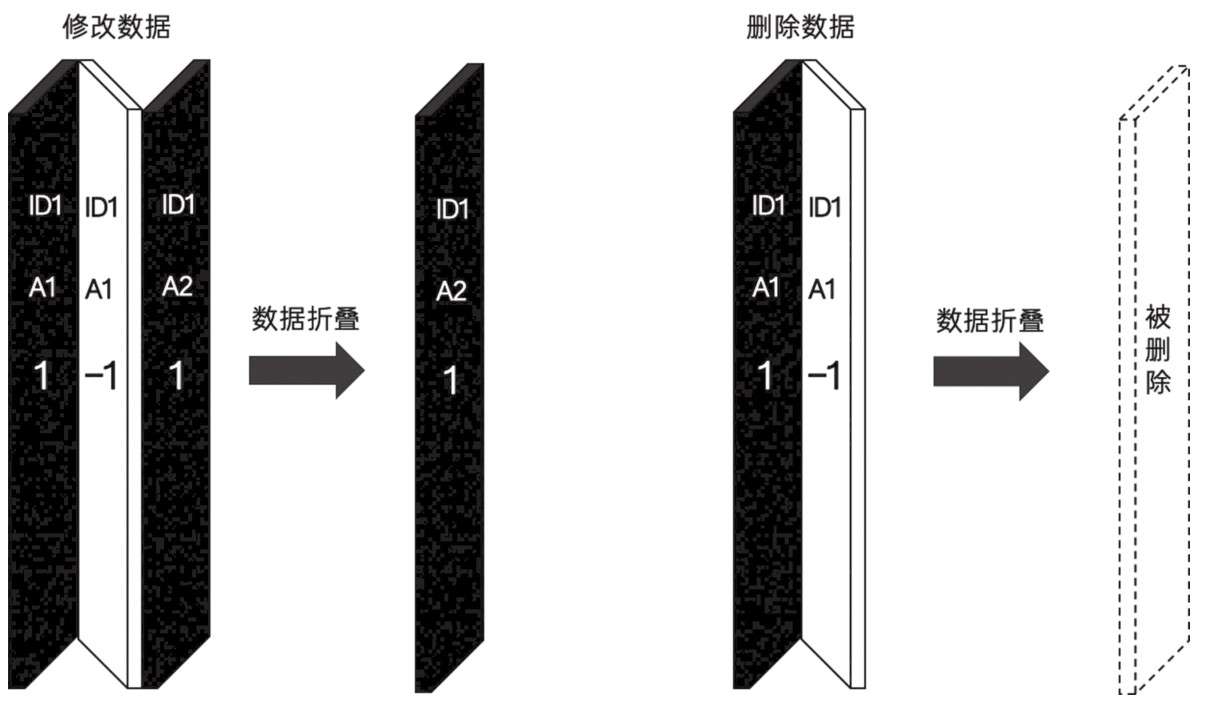
声明 CollapsingMergeTree 的方式如下:
ENGINE = CollapsingMergeTree(sign);
其中,sign 用于指定一个 Int8 类型的标志位字段。一个完整的使用示例如下所示:
CREATE TABLE collpase_table (id String,code Int32,create_time DateTime,sign Int8) ENGINE= CollapsingMergeTree(sign)PARTITION BY toYYYYMM(create_time)ORDER BY id;
与其他的 MergeTree 变种引擎一样,CollapsingMergeTree 同样是以 ORDER BY 排序键作为后续判断数据唯一性的依据。按照之前的介绍,对于上述 collpase_table 数据表而言,除了常规的新增数据操作之外,还能够支持两种操作。
其一,修改一行数据:
-- 修改前的源数据,它需要被修改INSERT INTO TABLE collpase_table VALUES('A000', 100, '2019-02-20 00:00:00', 1);-- 镜像数据,ORDER BY 字段与源数据相同(其他字段可以不同),sign 取反为 -1,它会和源数据折叠INSERT INTO TABLE collpase_table VALUES('A000', 100, '2019-02-20 00:00:00', -1);-- 修改后的数据,sign 为 1INSERT INTO TABLE collpase_table VALUES('A000', 120, '2019-02-20 00:00:00', 1);
其二,删除一行数据:
-- 修改前的源数据,它需要被删除INSERT INTO TABLE collpase_table VALUES('A000', 100, '2019-02-20 00:00:00', 1);-- 镜像数据,ORDER BY字段与源数据相同,sign取反为-1,它会和源数据折叠INSERT INTO TABLE collpase_table VALUES('A000', 100, '2019-02-20 00:00:00', -1);
CollapsingMergeTree 在折叠数据时,遵循以下规则:
- 如果 sign=1 比 sign=-1 的数据多一行,则保留最后一行 sign=1 的数据。
- 如果 sign=-1 比 sign=1 的数据多一行,则保留第一行 sign=-1 的数据。
- 如果 sign=1 和 sign=-1 的数据行一样多,并且最后一行是 sign=1,则保留第一行 sign=-1 和最后一行 sign=1 的数据。
- 如果 sign=1 和 sign=-1 的数据行一样多,并且最后一行是 sign=-1,则什么也不保留。
- 其余情况,ClickHouse 会打印警告日志,但不会报错,在这种情形下,查询结果不可预知。
在使用 CollapsingMergeTree 的时候,还有几点需要注意:
(1)折叠数据并不是实时触发
和所有其他的 MergeTree 变种表引擎一样,这项特性也只有在分区合并的时候才会体现。所以在分区合并之前,用户还是会看到旧的数据。解决这个问题的方式有两种。
方法一:在查询数据之前,使用 optimize TABLE table_name FINAL 命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
方法二:需要改变我们的查询方式。
以 collpase_table 举例,如果原始的 SQL 如下所示:
SELECT id, SUM(code), COUNT(code), AVG(code), uniq(code) FROM collpase_table GROUP BY id;
则需要改写成如下形式:
SELECT id, SUM(code*sign),COUNT(code*sign),AVG(code*sign),uniq(code*sign)FROM collpase_tableGROUP BY idHAVING SUM(sign)>0;
(2)只有相同分区内的数据才有可能被折叠
不过这项限制对于 CollapsingMergeTree 来说通常不是问题,因为修改或者删除数据的时候,这些数据的分区规则通常都是一致的,并不会改变。
(3)CollapsingMergeTree 对于写入数据的顺序有着严格要求
最后这项限制可能是 CollapsingMergeTree 最大的命门所在。现在用一个示例说明。如果按照正常顺序写入,先写 入sign=1,再写入 sign=-1,则能够正常折叠。如下:
-- 先写入 sign=1INSERT INTO TABLE collpase_table VALUES('A000’,102,'2019-02-20 00:00:00’,1);-- 再写入 sign=-1INSERT INTO TABLE collpase_table VALUES('A000’,101,'2019-02-20 00:00:00',-1);
现在将写入的顺序置换,先写入 sign=-1,再写入 sign=1,则不能够折叠:
-- 先写入 sign=-1INSERT INTO TABLE collpase_table VALUES('A000', 101, '2019-02-20 00:00:00', -1);-- 再写入 sign=1INSERT INTO TABLE collpase_table VALUES('A000', 102, '2019-02-20 00:00:00’, 1);
这种现象是 CollapsingMergeTree 的处理机制引起的,因为它要求 sign=1 和 sign=-1 的数据相邻。而分区内的数据基于 ORBER BY 排序,要实现 sign=1 和 sign=-1 的数据相邻,则只能依靠严格按照顺序写入。
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree 的工作机制就会出现问题。为了解决这个问题,ClickHouse 另外提供了一个名为 VersionedCollapsingMergeTree 的表引擎,下面我们来学习它。
VersionedCollapsingMergeTree
VersionedCollapsingMergeTree 表引擎的作用与 CollapsingMergeTree 完全相同,它们的不同之处在于,VersionedCollapsingMergeTree 对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。VersionedCollapsingMergeTree 是如何做到这一点的呢?其实从它的命名各位就应该能够猜出来,是版本号。
在定义 VersionedCollapsingMergeTree 的时候,除了需要指定 sign 标记字段以外,还需要指定一个 UInt8 类型的 ver 版本号字段:
ENGINE= VersionedCollapsingMergeTree(sign,ver);
一个完整的例子如下:
CREATE TABLE ver_collpase_table (id String,code Int32,create_time DateTime,sign Int8,ver UInt8) ENGINE = VersionedCollapsingMergeTree(sign,ver)PARTITION BY toYYYYMM(create_time)ORDER BY id;
VersionedCollapsingMergeTree 是如何使用版本号字段的呢?其实很简单,在定义 ver 字段之后,VersionedCollapsingMergeTree 会自动将 ver 作为排序条件并增加到 ORDER BY 的末端。以上面的 ver_collpase_table 表为例,在每个数据分区内,数据会按照 ORDER BY id , ver DESC 排序。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
可以用一组示例证明,首先是删除数据:
-- 删除INSERT INTO TABLE ver_collpase_table VALUES('A000', 101, '2019-02-2000:00:00',-1, 1)INSERT INTO TABLE ver_collpase_table VALUES('A000', 102, '2019-02-20 00:00:00', 1, 1)
接着是修改数据:
-- 修改INSERT INTO TABLE ver_collpase_table VALUES('A000', 101,'2019-02-20 00:00:00', -1, 1)INSERT INTO TABLE ver_collpase_table VALUES('A000', 102, '2019-02-20 00:00:00', 1, 1)INSERT INTO TABLE ver_collpase_table VALUES('A000', 103, '2019-02-20 00:00:00', 1, 2)
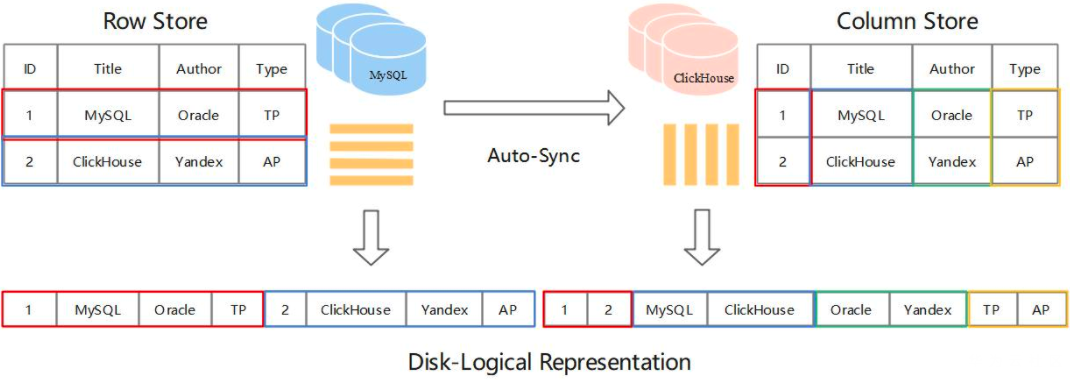
MaterializeMySQL 引擎
MaterializeMySQL 引擎是 ClickHouse 官方 2020 年主推的特性。支持从 MySQL 全量及增量实时数据同步。MaterializeMySQL 引擎目前支持 MySQL 5.6/5.7/8.0 版本,兼容 Delete/Update 语句,及大部分常用的 DDL 操作。
这样我们就可以很方便地基于 ClickHouse 实现对 MySQL数据的分析了。
使用方法
MySQL my.cnf 关键配置配置如下:
# 开启 GTID 模式以解决位点同步时 MySQL 主从切换问题(BinLog reset 导致位点失效)gtid_mode=ONenforce_gtid_consistency=1# 开启BinLog功能 ROW 模式binlog_format=ROW
创建 Slave-ClickHouse 中 MaterializeMySQL database:
-- 开启 materialize 同步功能SET allow_experimental_database_materialize_mysql=1;-- 创建 slave 库,参数分别是("mysqld服务地址", "待同步库名", "授权账户", "密码")CREATE DATABASE slave_db ENGINE = MaterializeMySQL('192.168.6.39:3306', 'master_db', 'root', '3306123456');
此时可以看到ClickHouse中已经有从MySQL中同步的数据了:
SELECT *FROM runoob_tbl-- Query id: 6e2b5f3b-0910-4d29-9192-1b985484d7e3---- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┐-- │ 1 │ MySQL-learning │ Bob │ 2021-01-06 │-- └───────────┴────────────────┴───────────────┴─────────────────┘-- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┐-- │ 2 │ MySQL-learning │ Tim │ 2021-01-06 │-- └───────────┴────────────────┴───────────────┴─────────────────┘-- 2 rows in set. Elapsed: 0.056 sec.
工作原理
BinLog Event
MySQL中BinLog Event主要包含以下几类:
MYSQL_QUERY_EVENT — DDL
MYSQL_WRITE_ROWS_EVENT — insert
MYSQL_UPDATE_ROWS_EVENT — update
MYSQL_DELETE_ROWS_EVENT — delete
事务提交后,MySQL 将执行过的 SQL 处理 BinLog Event,并持久化到 BinLog 文件,ClickHouse 通过消费 BinLog 达到数据同步,过程中主要考虑3个方面问题:
- DDL 兼容:由于 ClickHouse 和 MySQL 的数据类型定义有区别,DDL 语句需要做相应转换。
- Delete/Update 支持:引入 _version 字段,控制版本信息。
- Query 过滤:引入 _sign 字段,标记数据有效性。
DDL 操作
对比一下 MySQL 的 DDL 语句以及在 ClickHouse 端执行的 DDL 语句。
MySQL:
SHOW CREATE TABLE runoob_tbl\G;-- *************************** 1. row ***************************-- Table: runoob_tbl-- Create Table: CREATE TABLE `runoob_tbl` (-- `runoob_id` int unsigned NOT NULL AUTO_INCREMENT,-- `runoob_` varchar(100) NOT NULL,-- `runoob_author` varchar(40) NOT NULL,-- `submission_date` date DEFAULT NULL,-- PRIMARY KEY (`runoob_id`)-- ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8-- 1 row in set (0.00 sec)
ClickHouse:
cat /metadata/slave_db/runoob_tbl.sql# ATTACH TABLE _ UUID '14dbff59-930e-4aa8-9f20-ccfddaf78077'# (# `runoob_id` UInt32,# `runoob_` String,# `runoob_author` String,# `submission_date` Nullable(Date),# `_sign` Int8 MATERIALIZED 1,# `_version` UInt64 MATERIALIZED 1# )# ENGINE = ReplacingMergeTree(_version)# PARTITION BY intDiv(runoob_id, 4294967)# ORDER BY tuple(runoob_id)# SETTINGS index_granularity = 8192
可以看到:
- 在 DDL 转化时默认增加了2 个隐藏字段:_sign(-1 删除, 1 写入) 和 _version(数据版本)。
- 默认将表引擎设置为 ReplacingMergeTree,以 _version 作为 column version
- 原 DDL 主键字段 runoob_id 作为 ClickHouse 排序键和分区键。
此外还有许多 DDL 处理,比如增加列、索引等,相应代码在 Parsers/MySQL 目录下。
Delete/Update 操作
MySQL:
UPDATE runoob_tbl SET runoob_author='Mike' WHERE runoob_id=2;SELECT * FROM runoob_tbl;-- +-----------+----------------+---------------+-----------------+-- | runoob_id | runoob_title | runoob_author | submission_date |-- +-----------+----------------+---------------+-----------------+-- | 1 | MySQL-learning | Bob | 2021-01-06 |-- | 2 | MySQL-learning | Mike | 2021-01-06 |-- +-----------+----------------+---------------+-----------------+-- 2 rows in set (0.00 sec)
ClickHouse:
SELECT*,_sign,_versionFROM runoob_tblORDER BY runoob_id ASC-- Query id: c5f4db0a-eff6-4b49-a429-b55230c26301---- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐-- │ 1 │ MySQL-learning │ Bob │ 2021-01-06 │ 1 │ 2 │-- │ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ 1 │ 4 │-- │ 2 │ MySQL-learning │ Tim │ 2021-01-06 │ 1 │ 3 │-- └───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘-- 3 rows in set. Elapsed: 0.003 sec.
可以看到,ClickHouse 数据也实时同步了更新操作。
Delete
MySQL:
DELETE FROM runoob_tbl WHERE runoob_id=2;SELECT * FROM runoob_tbl;-- +-----------+----------------+---------------+-----------------+-- | runoob_id | runoob_title | runoob_author | submission_date |-- +-----------+----------------+---------------+-----------------+-- | 1 | MySQL-learning | Bob | 2021-01-06 |-- +-----------+----------------+---------------+-----------------+-- 1 row in set (0.00 sec)
ClickHouse:
SELECT*,_sign,_versionFROM runoob_tblORDER BY runoob_id ASC-- Query id: e9cb0574-fcd5-4336-afa3-05f0eb035d97---- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐-- │ 1 │ MySQL-learning │ Bob │ 2021-01-06 │ 1 │ 2 │-- └───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘-- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐-- │ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ -1 │ 5 │-- └───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘-- ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐-- │ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ 1 │ 4 │-- │ 2 │ MySQL-learning │ Tim │ 2021-01-06 │ 1 │ 3 │-- └───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘-- 4 rows in set. Elapsed: 0.002 sec.
可以看到,删除 id 为 2 的行只是额外插入了 _sign = -1 的一行记录,并没有真正删掉。
日志回放
MySQL 主从间数据同步时 Slave 节点将 BinLog Event 转换成相应的 SQL 语句,Slave 模拟 Master 写入。类似地,传统第三方插件沿用了 MySQL 主从模式的 BinLog 消费方案,即将 Event 解析后转换成 ClickHouse 兼容的 SQL 语句,然后在 ClickHouse 上执行(回放),但整个执行链路较长,通常性能损耗较大。不同的是,MaterializeMySQL 引擎提供的内部数据解析以及回写方案隐去了三方插件的复杂链路。回放时将 BinLog Event 转换成底层 Block 结构,然后直接写入底层存储引擎,接近于物理复制。此方案可以类比于将 BinLog Event 直接回放到 InnoDB 的 Page 中。
流程:
- ClickHouse 发送 GTID:0857c24e-4755-11eb-888c-00155dfbdec7:1-783 给 MySQL;
- MySQL 根据 GTID 找到本地位点,读取下一个 Event 发送给 ClickHouse;
- ClickHouse 接收 BinLog Event 并完成同步操作;
- ClickHouse 更新 .metadata GTID 信息。

若有收获,就点个赞吧
0 人点赞
