ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
官方文档:https://clickhouse.com/docs/zh/
ClickHouse 的特点
列式存储
以下面的表为例:
| Id | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
采用行式存储时,数据在磁盘上的组织结构为:
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
采用列式存储时,数据在磁盘上的组织结构为:
这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
列式储存的好处:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储。
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
DBMS 的功能
几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
多样化引擎
ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。
高吞吐写入能力
ClickHouse 采用类 LSM Tree 的结构,数据写入后定期在后台 Compaction。通过类 LSM tree 的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台 compaction 时也是多个段 merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行 100Byte 估算,大约相当于 50W-200W 条/s 的写入速度。
数据分区与线程级并行
ClickHouse 将数据划分为多个 partition , 每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个 CPU 核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条 Query 就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务, ClickHouse 并不是强项。
性能对比
参考:https://www.cnblogs.com/Sunnynanbing/p/14707317.html
结论:单表性能强悍,多表 join 性能欠佳。ClickHouse 作为目前所有开源 MPP 计算框架中计算速度最快的,它在做多列的表,同时行数很多的表的查询时,性能是很让人兴奋的,但是在做多表的 join 时,它的性能是不如单宽表查询的。性能测试结果表明ClickHouse 在单表查询方面表现出很大的性能优势,但是在多表查询中性能却比较差,不如 presto 和 impala、hawq 的效果好。
数据类型
基本数据类型
整型
固定长度的整型,包括有符号整型或无符号整型。
整型范围(-2n-1~2n-1-1):
- Int8 - [-128 : 127]
- Int16 - [-32768 : 32767]
- Int32 - [-2147483648 : 2147483647]
- Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围(0~2n-1):
- UInt8 - [0 : 255]
- UInt16 - [0 : 65535]
- UInt32 - [0 : 4294967295]
- UInt64 - [0 : 18446744073709551615]
使用场景: 个数、数量、也可以存储型 id。
浮点型
Float32 - float
Float64 – double
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
使用场景:一般数据值比较小,不涉及大量的统计计算,精度要求不高的时候。比如保存商品的重量。
布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
Decimal 型
有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
有三种声明(s 标识小数位):
- Decimal32(s),相当于 Decimal(9-s,s),有效位数为 1~9
- Decimal64(s),相当于 Decimal(18-s,s),有效位数为 1~18
- Decimal128(s),相当于 Decimal(38-s,s),有效位数为 1~38
使用场景: 一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal 进行存储。
字符串
String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
FixedString(N)
固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。与 String 相比,极少会使用 FixedString,因为使用起来不是很方便。
使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。
时间类型
目前 ClickHouse 有三种时间类型
- Date 接受
年-月-日的字符串比如 2019-12-16 - Datetime 接受
年-月-日 时:分:秒的字符串比如 2019-12-16 20:50:10 - Datetime64 接受
年-月-日 时:分:秒.亚秒的字符串比如2019-12-16 20:50:10.66
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。 还有很多数据结构,可以参考官方文档:https://clickhouse.yandex/docs/zh/data_types/。
时间间隔类型INTERVAL:
- Interval 是间隔的类型,表示时间和日期间隔的数据类型
- Interval 数据类型值不能存储在表中
- Interval 指定时间间隔的值应为无符号整数值
基本类型对应关系
ClickHouse 的数据类型和常见的其他存储系统的数据类型对比:
| MySQL | Hive | CLickHouse(区分大小写) |
|---|---|---|
| byte | tinyint | Int8 |
| short | smallint | Int16 |
| int | int | Int32 |
| long | bigint | Int64 |
| varchar | string | String |
| timestamp | timestamp | DateTime |
| float | float | Float32 |
| double | double | Float64 |
| boolean | boolean | 无 |
复合类型
除了基础数据类型之外,ClickHouse 还提供了数组、元组、枚举和嵌套等复合类型。这些类型通常
是其他数据库原生不具备的特性。拥有了复合类型之后,ClickHouse 的数据模型有了更强的表达能力。
枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 'string'= integer 的对应关系。其中:
- Enum8 用
'String'= Int8对描述。 - Enum16 用
'String'= Int16对描述。
例如:
CREATE TABLE t_enum(x Enum8('hello' = 1, 'world' = 2))ENGINE = TinyLog;
这个 x 列只能存储类型定义中列出的值:’hello’ 或 ‘world’,如果尝试保存任何其他值,ClickHouse 抛出异常。如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型(CAST(x, 'Int8') ):
-- 查询对应行的数值,则必须将 Enum 值转换为整数类型SELECTCAST(x, 'Int8')FROM enum_test;-- ┌─CAST(x, 'Int8')─┐-- │ 1 │-- │ 2 │-- └─────────────────┘
使用场景:对一些状态、类型的字段算是一种空间优化,也算是一种数据约束。但是实际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨慎使用。
数组
Array(T) 由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在 MergeTree 表中存储多维数组。
创建数组方式 1:使用 array 函数
SELECT array(1, 2) AS x, toTypeName(x) ;
创建数组方式 2:使用方括号
SELECT [1, 2] AS x, toTypeName(x);
类型检测机制:
- ClickHouse 会自动检测数组元素,并根据元素计算出存储这些元素最小的数据类型。
- 如果在元素中存在 Null 或存在 Nullable 类型元素,那么数组的元素类型将会变成 Nullable 。
- 如果 ClickHouse 无法确定数据类型,它将产生异常。
元组
元组类型由 1~n 个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。元组同样支持类型推断,其推断依据仍然以最小存储代价为原则。
元组也可以使用两种方式定义,常规方式 tuple(T):
- 方式一:tuple(T1,T2,…),常规方式
- 方式二:(T1,T2,…)
元素类型和泛型的作用类似,可以进一步保障数据质量。在数据写入的过程中会进行类型检查。
使用示例:
-- 创建一张带tuple字段的表并插入数据CREATE TABLE tuple_table(`t` Tuple(Int8, String, Array(String), Array(Int8)))ENGINE = TinyLog;INSERT INTO tuple_table VALUES ((1, 'a', ['a', 'b', 'c'], [1, 2, 3]));-- 定义元组类型数据SELECT tuple(1,'a') AS x, toTypeName(x) as type;-- ┌─x───────┬─type─────────────────┐-- │ (1,'a') │ Tuple(UInt8, String) │-- └─────────┴──────────────────────┘-- 获取元组内的数据SELECT tuple(1,'a') AS x, toTypeName(x) as type, x.1 as v1, x.2 as v2;-- ┌─x───────┬─type─────────────────┬─v1─┬─v2─┐-- │ (1,'a') │ Tuple(UInt8, String) │ 1 │ a │-- └─────────┴──────────────────────┴────┴────┘
嵌套类型
嵌套类型,顾名思义是一种嵌套表结构。数据表,可以定义任意多个嵌套类型字段,每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。
简单场景的层级关系或关联关系,使用嵌套类型能够非常方便的存储对应的数据。
嵌套的数据定义方式为:Nested(Name1 Type1,Name2 Type2,…)就像一个嵌套的表。嵌套数据结构的参数、列名和类型与在CREATE查询中的指定方式相同。
使用示例:
-- 创建带有嵌套结构字段的表CREATE TABLE nest_table(`name` String,`age` Int8,`dept` Nested(id UInt8, name String))ENGINE = TinyLog-- 插入数据INSERT INTO nest_table values('xiaohong', 18, [1], ['财务部']),('codes', 18, [1,2,3],['hadoop','spark','flink']);-- 查询数据SELECT * FROM nest_table;-- ┌─name─────┬─age─┬─dept.id─┬─dept.name──────────────────┐-- │ xiaohong │ 18 │ [1] │ ['财务部'] │-- │ codes │ 18 │ [1,2,3] │ ['hadoop','spark','flink'] │-- └──────────┴─────┴─────────┴────────────────────────────┘
可以看出嵌套类型本质是一个多维数组的结构。嵌套类型的一个字段对应一个数组。字段对应的数组内的数量没有限制,但是字段之间需要数组内的数量对齐。在Hive中,有一种复杂类型叫做 Struct,跟当前这种情况很类似,但是根据经验,推荐尽量少使用 Nested 类型
Nullable(TypeName)
Nullable 并不能算是一种独立的数据类型,更像是一种修饰符,需要与基础数据类型一起搭配使用。
Nullable 类型与 Java8 的 Optional 对象有些相似,它表示某个基础数据类型可以是Null 值。特殊标记 (NULL) 表示 “缺失值”,可以与 TypeName 的正常值存放一起。例如,Nullable(Int8) 类型的列可以存储 Int8 类型值,而没有值的行将存储 NULL。
Nullable 只能和基本类型搭配使用,不能使用在 Array/Tuple 这种复合类型上,不能作为索引字段 Order by。
慎用 Nullable ,写入写出性能不好。在正常情况下,每个列字段的数据会被存储在对应的 [Column].bin文件中。当列字段被Nullable 类型修饰后,会额外生成一个 [Column].null.bin 文件专门保存它的 Null 值。这意味着在读取和写入数据时,需要一倍的额外文件操作。
使用示例:
-- 建表CREATE TABLE null_test(`c1` String,`c2` Nullable(UInt8))ENGINE = TinyLog-- 插入数据insert into null_test values ('aa', null),('bb', 99);-- 查询数据select c1, c2 from null_test;-- ┌─c1─┬───c2─┐-- │ aa │ ᴺᵁᴸᴸ │-- │ bb │ 99 │-- └────┴──────┘
Nothing
此数据类型的唯一目的是表示不是期望值的情况。 所以不能创建一个 Nothing 类型的值。例如,文本 NULL 的类型为 Nullable(Nothing)。详情请见 Nullable。
Nothing 类型也可以用来表示空数组:
SELECT toTypeName(array()) as type;-- ┌─type───────────┐-- │ Array(Nothing) │-- └────────────────┘
Domain
Domain 类型是特定实现的类型,它总是与某个现存的基础类型保持二进制兼容的同时添加一些额外的特性,以能够在维持磁盘数据不变的情况下使用这些额外的特性。
目前 ClickHouse 暂不支持自定义domain类型。
域名类型分为 IPv4 和 IPv6 两类,本质上它们是对整型和字符串的进一步封装:
- IPv4 类型是基于UInt32 封装的
- IPv6 类型是基于FixedString(16) 封装的
使用示例:
-- 建表CREATE TABLE ip4_test(`url` String,`ip` IPv4)ENGINE = Memory-- 查看表结构describe ip4_test;-- ┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment─┬─codec_expression─┬─ttl_expression─┐-- │ url │ String │ │ │ │ │ │-- │ ip │ IPv4 │ │ │ │ │ │-- └──────┴────────┴──────────────┴────────────────────┴─────────┴──────────────────┴────────────────┘-- 插入数据INSERT INTO ip4_test VALUES ('www.baidu.com', '192.168.22.55');-- 查询数据SELECT url, ip, toTypeName(ip) FROM ip4_test;-- ┌─url───────────┬─ip────────────┬─toTypeName(ip)─┐-- │ www.baidu.com │ 192.168.22.55 │ IPv4 │-- └───────────────┴───────────────┴────────────────┘-- 转为更紧凑的二进制存储格式SELECT url,toTypeName(ip) AS type, hex(ip) FROM ip4_test;-- ┌─url───────────┬─type─┬─hex(ip)──┐-- │ www.baidu.com │ IPv4 │ C0A81637 │-- └───────────────┴──────┴──────────┘-- 将 IP 转换为 UInt32 类型SELECT toTypeName(ip) AS type, CAST(ip AS UInt32) AS i FROM ip4_test;-- ┌─type─┬──────────i─┐-- │ IPv4 │ 3232241207 │-- └──────┴────────────┘-- 将 IP 转换为 String 类型SELECT IPv4NumToString(ip) AS s, toTypeName(s) AS type FROM ip4_test;-- ┌─s─────────────┬─type───┐-- │ 192.168.22.55 │ String │-- └───────────────┴────────┘
LowCardinality
LowCardinality 是一种改变数据存储和数据处理方法的概念。
ClickHouse会把 LowCardinality 所在的列转为字典编码类型,在大多数情况下处理字典编码的数据可以显著的增加 SELECT 查询速度。
如果一个字典包含少于 10000 个不同的值,那么 ClickHouse 可以进行更高效的数据存储和处理。反之如果字典多于 10000,效率会表现的更差。
当使用字符类型的时候,可以考虑使用 LowCardinality 代替 Enum。
用法:LowCardinality(data_type)
- data_type — String, FixedString, Date, DateTime,包括数字类型,但是 Decimal 除外。
- 对一些数据类型来说,LowCardinality 并不高效,详查 allow_suspicious_low_cardinality_types 设置描述。
聚合函数类型
AggregateFunction
AggregateFunction — 参数化的数据类型。
定义方式:AggregateFunction(name, types_of_arguments…)
定义参数:
- 聚合函数名,可用函数列表
- 聚合函数参数的类型
说明:
- 写入数据时,需要调用相应的 State 函数,可以通过聚合函数名称加-State后缀的形式得到它。
- 查询数据时,需要调用相应的 Merge 函数,相同的聚合函数名加-Merge后缀的形式来得到。不使用 Merge 函数查询数据时将会是无法显示的二进制。
使用示例:
-- 建表语句CREATE TABLE aggregate_function_test(id String,code AggregateFunction(uniq,String),value AggregateFunction(sum,UInt32))ENGINE = Memory;-- 写入数据使用uniqState,sumState 函数-- 写入测试数据id = 001, code相同INSERT INTO TABLE aggregate_function_test SELECT '001', uniqState('code1'), sumState(toUInt32(100));INSERT INTO TABLE aggregate_function_test SELECT '001', uniqState('code1'), sumState(toUInt32(150));-- 写入测试数据id = 002, code不同INSERT INTO TABLE aggregate_function_test SELECT '002', uniqState('code1'), sumState(toUInt32(100));INSERT INTO TABLE aggregate_function_test SELECT '002', uniqState('code2'), sumState(toUInt32(50));-- 查询数据使用uniqMerge,sumMerge 函数SELECT id, uniqMerge(code), sumMerge(value) FROM aggregate_function_test GROUP BY id;-- ┌─id──┬─uniqMerge(code)─┬─sumMerge(value)─┐-- │ 002 │ 2 │ 150 │-- │ 001 │ 1 │ 250 │-- └─────┴─────────────────┴─────────────────┘-- 查询数据时,不使用Merge 函数SELECTid,code,valueFROM aggregate_function_test;-- ┌─id──┬─code─┬─value─┐-- │ 001 │ n� │ d │-- └─────┴──────┴───────┘
SimpleAggregateFunction
SimpleAggregateFunction(name, types_of_arguments…) 数据类型存储聚合函数的当前值,并不像 AggregateFunction 那样存储其全部状态。
这种优化可以应用于具有以下属性函数:将函数 f 应用于行集合 S1 UNION ALL S2 的结果,可以通过将 f 分别应用于行集合的部分, 然后再将 f 应用于结果来获得: f(S1 UNION ALL S2) = f(f(S1) UNION ALL f(S2))。 这个属性保证了部分聚合结果足以计算出合并的结果,所以我们不必存储和处理任何额外的数据。
SimpleAggregateFunction(func, Type) 的值外观和存储方式于 Type 相同, 所以你不需要应用带有 -Merge/-State 后缀的函数。SimpleAggregateFunction 的性能优于具有相同聚合函数的 AggregateFunction 。
参数
- 聚合函数的名称
- 聚合函数参数的类型
使用示例:
CREATE TABLE simpleAggregate_function_test(id String,code SimpleAggregateFunction(max,String),value SimpleAggregateFunction(sum,UInt64)) ENGINE = Memory;-- 写入测试数据id = 001, code相同INSERT INTO TABLE simpleAggregate_function_test values('001','code1',100),('001','code1',150);-- 写入测试数据id = 002, code不同INSERT INTO TABLE simpleAggregate_function_test values('002','code1',100),('002','code2',50);-- 查询数据SELECT id,max(code),sum(value) FROM simpleAggregate_function_test GROUP BY id;-- ┌─id──┬─uniqMerge(code)─┬─sumMerge(value)─┐-- │ 002 │ 2 │ 150 │-- │ 001 │ 1 │ 250 │-- └─────┴─────────────────┴─────────────────┘-- 不使用聚合函数查询数据SELECTid,code,valueFROM simpleAggregate_function_test-- ┌─id──┬─code──┬─value─┐-- │ 002 │ code1 │ 100 │-- │ 002 │ code2 │ 50 │-- └─────┴───────┴───────┘-- ┌─id──┬─code──┬─value─┐-- │ 001 │ code1 │ 100 │-- │ 001 │ code1 │ 150 │-- └─────┴───────┴───────┘
支持的聚合函数:
| any | anyLast | min | max | sum | sumWithOverflow |
|---|---|---|---|---|---|
| groupBitAnd | groupBitOr | groupBitXor | groupArrayArray | groupUniqArrayArray | sumMap |
| minMap | maxMap | argMin | argMax |
Map
Map(key, value) 数据类型存储 key: value 对。Map 数据类型仍在开发阶段版本时,要使用它,必须进行设置 allow_experimental_map_type = 1。你可以投 Tuple() 作为 Map() 使用CAST功能。
参数
- key对中的关键部分。字符串或整数
- value对的值部分。字符串,整数或数组
使用示例:
-- 开启 mapSET allow_experimental_map_type = 1;-- 创建包含 map 类型字段的表CREATE TABLE map_test (a Map(String, UInt64)) ENGINE=Memory;-- 插入数据INSERT INTO map_test VALUES ({'key1':1, 'key2':10}), ({'key1':2,'key2':20}), ({'key1':3,'key2':30});-- 查询数据SELECT * FROM map_test;-- ┌─a────────────────────┐-- │ {'key1':1,'key2':10} │-- │ {'key1':2,'key2':20} │-- │ {'key1':3,'key2':30} │-- └──────────────────────┘-- 选择所有 key2 值:SELECT a['key2'] AS value FROM map_test;-- ┌─value─┐-- │ 10 │-- │ 20 │-- │ 30 │-- └───────┘
表引擎
表引擎概述
表引擎在 ClickHouse 中的作用十分关键,直接决定了数据如何存储和读取、是否支持并发读写、是否支持 index、支持的 query 种类、是否支持主备复制等。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。引擎的名称大小写敏感。

ClickHouse表引擎一共分为四个系列,分别是 Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎 Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用。最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。对于大多数正式的任务,推荐使用 MergeTree 族中的引擎。
Log、Special、Integration 主要用于特殊用途,场景相对有限。MergeTree 系列才是官方主推的存储引擎,支持几乎所有 ClickHouse 核心功能。
官方文档:https://c lickhouse.yandex/docs/zh/operations/table_engines/
Log 系列
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
Log 系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。当你需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
几种 Log 表引擎的共性是:
- 数据被顺序 append 写到磁盘上。
- 不支持 delete、update。
- 不支持 index。
- 不支持原子性写。
- insert 会阻塞 select 操作。
该类型的引擎有:
- TinyLog
- StripeLog
- Log
主要特点:
- 数据存储在磁盘上。
- 写入时将数据追加在文件末尾。
- 不支持突变操作。
- 不支持索引,意味着 SELECT 在范围查询时效率不高。
- 非原子地写入数据,如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表。
它们彼此之间的区别是: 是否支持并发读写,性能问题,列存储问题
- TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据。
- StripLog:支持并发读取数据文件,查询性能比 TinyLog 好;将所有列存储在同一个大文件中,减少了文件个数。
- Log:支持并发读取数据文件,查询性能比 TinyLog 好;每个列会单独存储在一个独立文件中。
TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时数据将附加到文件末尾。
该引擎没有并发控制:
- 如果同时从表中读取和写入数据,则读取操作将抛出异常。
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比 Log 引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则你可能会发现切换使用 TinyLog 类型的表更容易。不支持索引。
示例:
CREATE DATABASE IF NOT EXISTS test;USE test;DROP TABLE IF EXISTS test.table_tinylog;CREATE TABLE table_tinylog (a UInt16, b STRING) ENGINE = TinyLog;INSERT INTO table_tinylog (a, b) VALUES (1, 'abc');SELECT * FROM table_tinylog;
Log
Log 与 TinyLog 的不同之处在于,”标记” 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
示例:
CREATE TABLE table_log (a UInt16, b String) ENGINE=Log;
StripeLog
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。不支持 alter update 和 alter delete 操作。
示例:
CREATE TABLE test.table_stripelog (id Int8, name STRING) ENGINE = StripeLog;
Integration 系列
该系统表引擎主要用于将外部数据导入到 ClickHouse 中,或者在 ClickHouse 中直接操作外部数据源。
外部数据:
- Kafka:将 Kafka Topic 中的数据直接导入到 ClickHouse。
- MySQL:将 Mysql 作为存储引擎,直接在 ClickHouse 中对 MySQL 表进行 select 等操作。
- JDBC/ODBC:通过指定 jdbc、odbc 连接串读取数据源。
- HDFS:直接读取 HDFS 上的特定格式的数据文件。
用于与其他的数据存储与处理系统集成的引擎。该类型的引擎有:
- Kafka
- MySQL
- ODBC
- JDBC
- HDFS
Kafka
参考:
clickhouse支持kafka的表双向同步,其中提供的为Kafka引擎。
Kafka 主题中存在对应的数据格式,Clickhouse 创建一个 Kafka 引擎表(即相当于一个消费者),当主题有消息进入时,获取该消息,将其进行消费,然后物化视图同步插入到 MergeTree 表中。
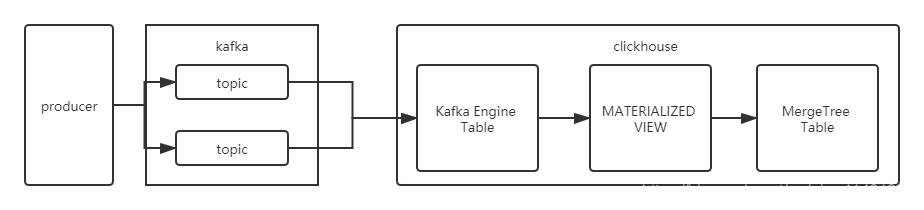
该引擎还支持反向写入到 Kafka 中,即往 Kafka 引擎表中插入数据,可以同步到 Kafka 中(同样可以使用物化视图将不同引擎需要的表数据同步插入到 Kafka 引擎表中)。
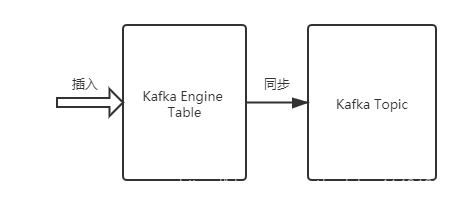
该引擎还支持反向写入到 Kafka 中,即往 Kafka 引擎表中插入数据,可以同步到 Kafka 中(同样可以使用物化视图将不同引擎需要的表数据同步插入到 Kafka 引擎表中)。
下面为 Kafka Engine 的一些配置:
-- 老版本格式Kafka(kafka_broker_list, kafka_topic_list, kafka_group_name, kafka_format[, kafka_row_delimiter, kafka_schema, kafka_num_consumers])-- 新版本格式Kafka SETTINGSkafka_broker_list = 'localhost:9092',kafka_topic_list = 'topic1,topic2',kafka_group_name = 'group1',kafka_format = 'JSONEachRow',kafka_row_delimiter = '\n',kafka_schema = '',kafka_num_consumers = 2
必填参数(例如 topic、kafka 集群、消费者组等):
- kafka_broker_list – 以逗号分隔的 brokers 列表 (例如 kafka1:9092,kafka2:9092,kafka3:9092)。
- kafka_topic_list – topic 列表 (你的 topic 名字,也可以多个)。
- kafka_group_name – Kafka 消费组名称 (group1)。如果不希望消息在集群中重复,请在每个分片中使用相同的组名。
- kafka_format – 消息体格式。使用与 SQL 部分的 FORMAT 函数相同表示方法,例如 JSONEachRow、CSV、XML等。
非必填的参数:
- kafka_row_delimiter - 每个消息体(记录)之间的分隔符。
- kafka_schema – 如果解析格式需要一个 schema 时,此参数必填。
- kafka_num_consumers – 单个表的消费者数量。默认值是 1,如果一个消费者的吞吐量不足,则指定更多的消费者。众所周知消费者的总数不应该超过 topic 中分区的数量,因为每个分区只能分配一个消费者。
示例:
-- 创建存储消费数据表CREATE DATABASE cppla ON cluster company_cluster;CREATE TABLE cppla.kafka_readings (dd_by_cppla String,msg String,platform String,data String,dt DateTime) Engine = MergeTree PARTITION BY toYYYYMMDD(dt) ORDER BY (dt);-- 创建消费Kafka数据表CREATE TABLE cppla.kafka_readings_queue (dd_by_cppla String,msg String,platform String,data String,dt DateTime)ENGINE = Kafka SETTINGSkafka_broker_list = 'localhost:9092',kafka_topic_list = 'test_2',kafka_group_name = 'consumer_group2',kafka_format = 'JSONEachRow',kafka_skip_broken_messages = 100,kafka_num_consumers = 3;-- 创建物化视图合并表传输数据,导入到 ClickHouseCREATE MATERIALIZED VIEW cppla.kafka_readings_view TO cppla.kafka_readingsAS SELECT dd_by_cppla, msg, platform, data, dtFROM cppla.kafka_readings_queue;-- 往 kafka 写入消息,数据被即时存储-- docker exec -ti kafka-docker_kafka_1 /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_2-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"111-111-111","dt":"2021-08-20 14:22:58"}-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"222-222-222","dt":"2021-08-20 14:23:04"}-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"333-333-333","dt":"2021-08-20 14:22:51"}-- 维护:停止接收 kafka 消息,卸载物化视图-- 注意:最好先停止 kafka 消息的写入,避免大批量消息写入过多堆积,来不及消费DETACH TABLE cppla.kafka_readings_view;-- 维护:恢复接收 kafka 消息,继续作业ATTACH TABLE cppla.kafka_readings_view;-- 创建复制表 + 分布式表 + 视图数据落地-- 创建复制表保证数据安全-- 注意一:这里 ReplicatedReplacingMergeTree 做合并时,重复数据会被去重删除。所以这里务必注意创建合理的 order by-- 注意二:Clickhouse-kafka 引擎极端情况无法保证不重复,所以最好利用 ReplicatedReplacingMergeTree 表引擎依据业务分区去重处理CREATE TABLE cppla.kafka_readings_replicated ON CLUSTER company_cluster(_offset UInt64,_partition UInt64,_timestamp Nullable(DateTime),dd_by_cppla String,msg String,platform String,data String,dt DateTime)ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicated/{shard}/kafka_readings_replicated_cppla', '{replica}')PARTITION BY toYYYYMMDD(dt)ORDER BY (_offset, _partition)TTL dt + toIntervalDay(365)SETTINGS index_granularity = 8192,use_minimalistic_part_header_in_zookeeper = 1;-- 创建视图落地到 ClickHouseCREATE MATERIALIZED VIEW cppla.kafka_readings_replicated_view TO cppla.kafka_readings_replicatedAS SELECT _offset, _partition, _timestamp, dd_by_cppla, msg, platform, data, dtFROM cppla.kafka_readings_queue;-- 创建分布式表加速查询CREATE TABLE cppla.kafka_readings_distributed ON CLUSTER company_clusterAS cppla.kafka_readings_replicated ENGINE = Distributed('company_cluster', cppla, kafka_readings_replicated, rand());-- 往 Kafka 写入新消息,查询数据-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"aaa-aaa-aaa","dt":"2021-08-23 12:32:17"}-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"bbb-bbb-bbb","dt":"2021-08-23 12:32:23"}-- {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"ccc-ccc-ccc","dt":"2021-08-23 12:32:29"}-- 多视图可以消费同一个 Kafka 数据表并加以落地存储:cppla.kafka_readings_queue
MySQL
MySQL 引擎用于将远程的 MySQL 服务器中的表映射到 ClickHouse 中,并允许对表进行 INSERT 和 SELECT 查询,以便在 ClickHouse 与 MySQL 之间进行数据交换。ClickHouse 的 MySQL 引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。这个模式类似于 Hive 的外部表。
官方文档
- https://clickhouse.com/docs/zh/engines/table-engines/integrations/mysql/
- https://clickhouse.com/docs/zh/engines/database-engines/mysql/
语法:
-- 库映射CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')-- 表映射CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] (name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
HDFS
从 ClickHouse 18.16.0 版本开始支持从 HDFS 读文件,在 19.1.6 版本对 HDFS 访问功能进行了增强,支持读和写,在 19.4 版本以后开始支持 Parquet 格式。
官方文档:https://clickhouse.com/docs/zh/sql-reference/table-functions/hdfs/
示例:
-- 读取数据CREATE TABLE IF NOT EXISTS test.table_csv (id Int8,name String,sex String,age Int8,department String) Engine = HDFS('hdfs://bigdata03:9000/clickhouse_data/student/stu*.csv', 'CSV');-- 导入数据INSERT INTO test.table_csvSELECT * FROM hdfs( 'hdfs://bigdata03:9000/clickhouse_data/student/student.csv', 'CSV', 'id Int8, name String, sex String, age Int8, department String' );
Special 系列
Special 系列的表引擎,大多是为了特定场景而定制的。例如:
- Memory:将数据存储在内存中,重启后会导致数据丢失。查询性能极好,适合于对于数据持久性没有要求的 1 亿一下的小表。在 ClickHouse 中,通常用来做临时表。
- Buffer:为目标表设置一个内存 buffer,当 buffer 达到了一定条件之后会 flush 到磁盘。
- File:直接将本地文件作为数据存储。
- Null:写入数据被丢弃、读取数据为空。
该类型的引擎有:
- Distributed
- MaterializedView
- Dictionary
- Merge
- File
- Null
- Set
- Join
- URL
- View
- Memory
- Buffer
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。读写操作不会相互阻塞,也不支持索引。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景。
Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据。 读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
ENGINE=Merge(db, 'regex')
示例:
CREATE TABLE test.tb_merge1 (id UInt16, name STRING) ENGINE = TinyLog;CREATE TABLE test.tb_merge2 (id UInt16, name STRING) ENGINE = TinyLog;CREATE TABLE test.tb_merge3 (id UInt16, name STRING) ENGINE = TinyLog;INSERT INTO test.tb_merge1(id, name) VALUES (1, 'first');INSERT INTO test.tb_merge2(id, name) VALUES (2, 'second');INSERT INTO test.tb_merge3(id, name) VALUES (3, 'three');DROP TABLE IF EXISTS test.table_merge;CREATE TABLE table_merge (id UInt16,name String) ENGINE=Merge(currentDatabase(), '^tb_merge');SELECT * FROM test.table_merge;
Distributed
分布式引擎,本身不存储数据,但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时远程服务器表的索引(如果有的话)会被使用。
示例:
-- 语法Distributed(cluster_name, database, table [, sharding_key])-- 在 bigdata02,bigdata03,bigdata04,bigdata05 上分别创建一个表 tb_distributedCREATE TABLE tb_distributed(id UInt16, name STRING) ENGINE = TinyLog;-- 在 bigdata02 上创建分布式表DROP TABLE IF EXISTS test.table_distributed;CREATE TABLE test.table_distributed(id UInt16,name STRING) ENGINE = Distributed(cluster_name, test, tb_distributed, id);
MergeTree 系列
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
MergeTree 表引擎比较重要,将在下文 【Clickhouse】核心表引擎 进行单独介绍~

若有收获,就点个赞吧
0 人点赞
