集群概述
集群是副本和分片的基础,它将 Clickhouse 的服务拓扑由单节点延伸到多个节点。
Clickhouse 集群配置很灵活,既可以将所有节点组成一个单一的大集群,也可以按照业务需求,把节点划分为多个小集群。在每个小集群区域之间,它们的节点、分区和副本数量可以各不相同。
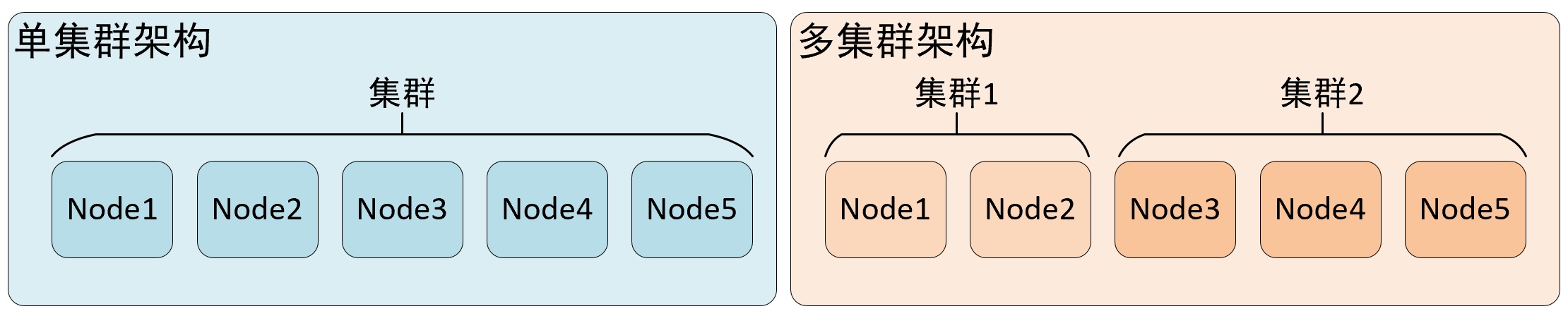
Clickhouse 集群的工作更多是针对逻辑层面,集群定义了多个节点的拓扑关系,这些节点在后续服务过程中很可能会协同工作,在执行层面的具体工作则交给了副本和分片来执行。
副本与分片的区别:
- 从数据层面上区分,假设 Clickhouse 有 N 个节点,在集群的各个节点上都有一张结构相同的数据表 Y , 如果 N1,N2 两个节点的数据完全相同,则互为副本,如果数据完全不同则互为分片。
- 从功能层面上看,副本的主要目的是为了防止数据丢失,而数据分片是为了实现数据的水平切分。

数据副本
如果在 MergeTree 表引擎前面加上 Replicated 前缀,就能够组合成一个新的引擎即 Replicated-mergeTree 复制表。如下从 1 分片 0 副本发展到多分片多副本:
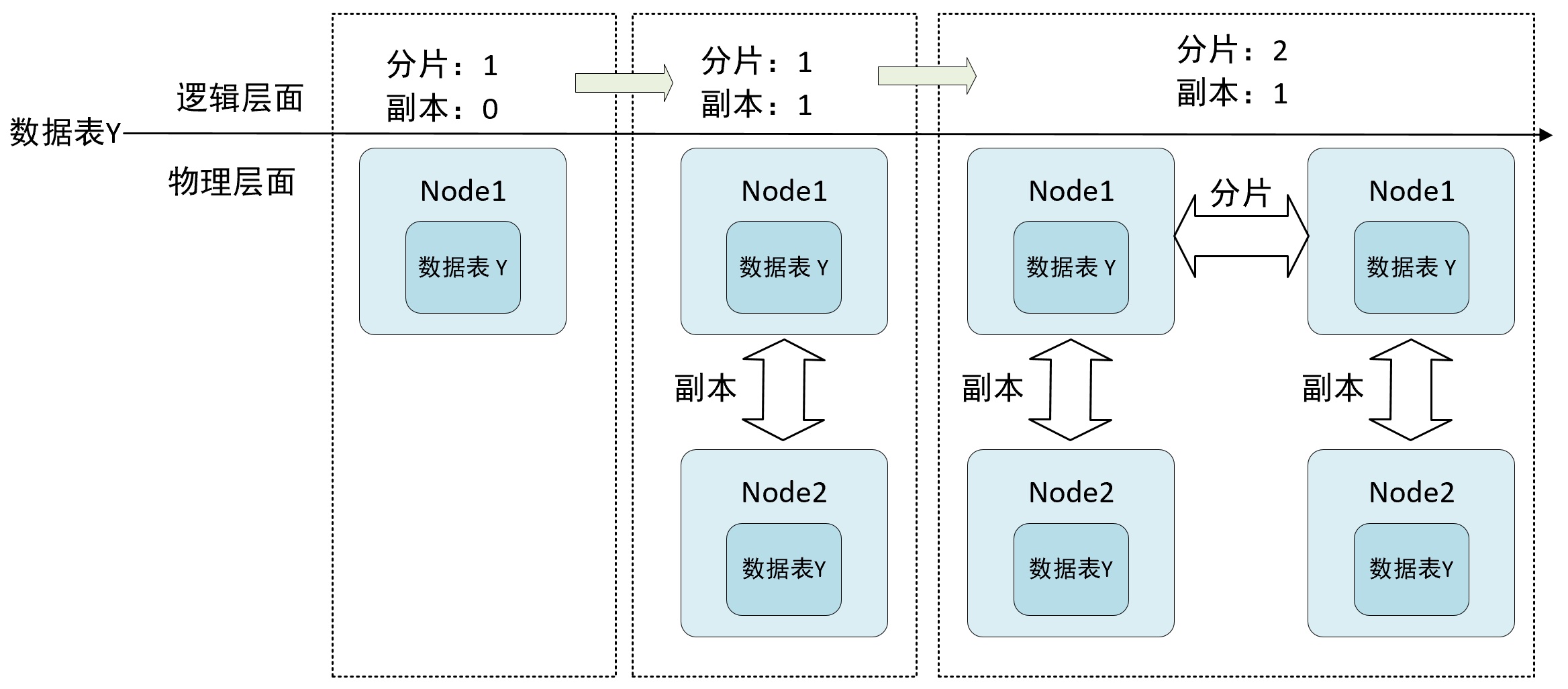
只有使用了 ReplicatedMergeTree 系列复制表引擎才能使用副本。ReplicatedMergeTree 是 MergeTree 的派生表引擎,在 MergeTree 的基础上加入了分布式协同能力。
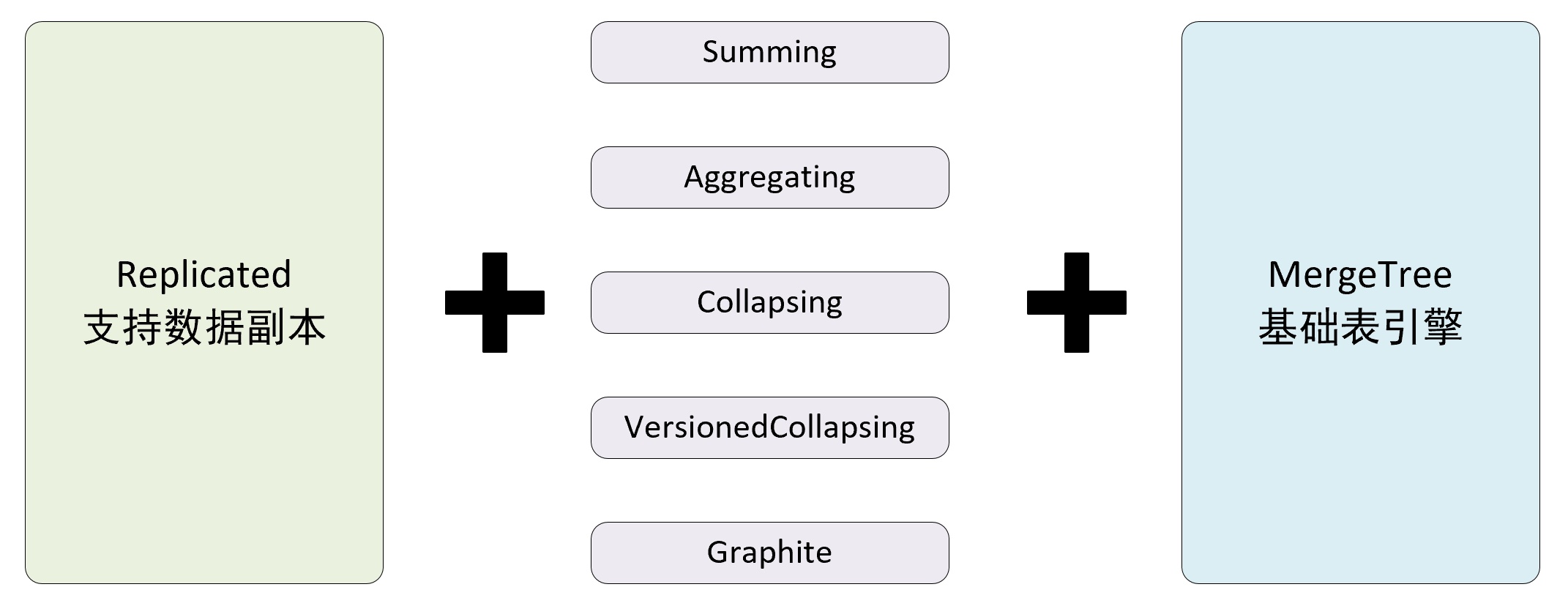
ReplicatedMergeTree 与 MergeTree 的关系如下:
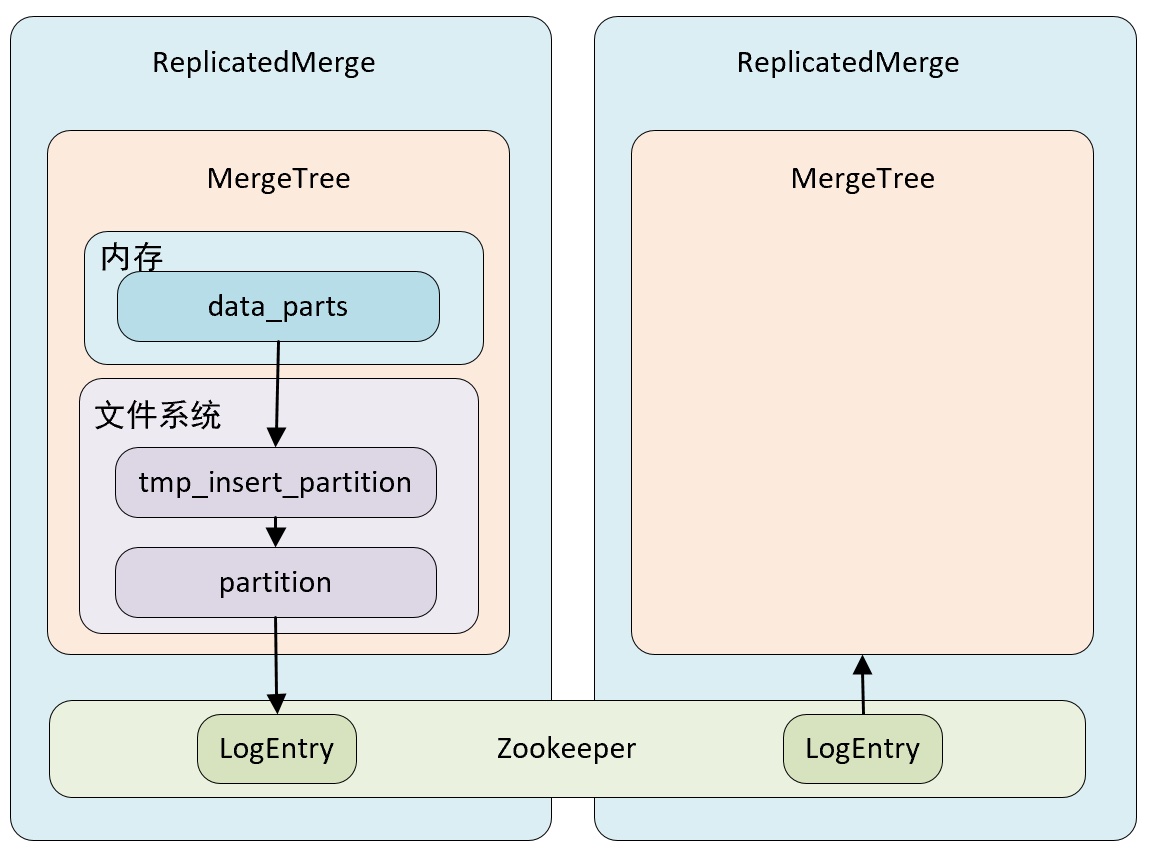
在 MergeTree 中,一个分区由开始创建到全部完成会经历两个存储区域:
- 内存:数据首先会被写入内存缓存区。
- 本地磁盘:数据接着会被写入到 tmp 临时目录分区,待全部完成后,再将临时目录重命名为正式分区。
ReplicatedMergeTree 在上述基础上增加了 zookeeper 的部分,它会进一步在 zookeeper 内部创建一系列的监听节点,并以此实现多个实例之间的通信,在整个通信过程中 zookeeper 并不会设计数据的传输。
数据副本的特点
依赖 zookeeper
在执行 insert 和 alert 查询的时候,ReplicatedMergeTree 需要借助 zookeeper 的分布式协调能力,以实现多个副本之间的数据同步,但是在查询的时候,并不需要使用 zookeeper。
表级别的副本
副本是在表级别定义的,所以每张表的副本配置都可以按照它的实际需求进行个性化,包括副本数量,以及副本在集群内的分布式位置等。
多主架构(Multi Master)
可以在任意一个副本上执行 insert 和 alter 查询,它们的效果是相同的,这些操作会借助 zookeeper 的协调能力被分发至每个副本以本地形式执行。
Block 数据块
在执行 insert 命令时,会依据 max_insert_block_size 的大小(默认 1048576 行)将数据切分成若干个 Block 数据块。所以数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。
原子性
在数据写入时,一个 Block 块内的数据要么全部写入成功,要么全部失败。
唯一性
在写入一个 Block 数据块的时候,会按照当前的 Block 数据块的数据顺序、数据行和数据大小等指标计算 Hash 信息摘要记录。在此之后,如果某个待写入的 Block 数据块与先前已被写入的 Block 数据块拥有相同的 Hash 摘要,则该 Block 数据块会被忽略,这个设计可以预防由于异常原因引起的 Block 数据块重复写入的问题。
zookeeper 的配置方式
在配置 zookeeper 之前需要先安装 zookeeper,zookeeper 的安装方式可以查看文档: zookeeper 安装
Clickhouse 使用量一组 zookeeper 标签定义了相关配置,在默认情况下,在全局配置 config.xml 中定义即可,但是为了方便在多个节点中复制,通常会把配置文件抽离出来,独立使用一个文件保存。
编写 zookeeper 配置文件(/etc/Clickhouse-server/config.xml):
<zookeeper><node><host>node2</host><port>2181</port></node></zookeeper>
Clickhouse 提供了一张名为 zookeeper 的代理表,可以使用 SQL 查询 zookeeper 中的数据。如下所示:
-- 查询 zookeeper 中的数据,必须指定 path 条件SELECTname,value,ctimeFROM system.zookeeperWHERE path = '/'-- ┌─name───────┬─value─┬───────────────ctime─┐-- │ zookeeper │ │ 1970-01-01 08:00:00 │-- │ clickhouse │ │ 2021-07-21 11:29:59 │-- └────────────┴───────┴─────────────────────┘
副本的定义形式
使用副本可以增加数据的冗余,降低数据的丢失风险。副本才用了多主架构,每个副本示例都可以作为数据读写的入口,分摊了节点的负载。
使用 ReplicatedMergeTree 定义副本:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],...) ENGINE = ReplicatedMergeTree('zk_path','replica_name')[PARTITION BY expr][ORDER BY expr][PRIMARY KEY expr][SAMPLE BY expr][SETTINGS name=value, ...]
参数说明:
- zk_path:用于指定 zookeeper 中创建的表的路径,值可自定义,但是 Clickhouse 建议设置的值为 /Clickhouse/tables/{shard}/table_name
- /Clickhouse/tables:固定路径前缀,表示存放表的根路径。
- {shard}:表示分片编号,通常使用数值代替,一张表可以有多个分片,每个分片拥有自己的副本。
- table_name:表名,为了方便维护,通常与表的物理名称相同。
- replica_name:定义在 zookeeper 中创建的副本名称,该名称是区分不同副本实例的唯一标识,约定的方式是使用服务器的域名 。
示例:
-- 1 个分片,1 个副本ReplicatedMergeTree('/clickhouse/tables/01/t_replicated','node3')ReplicatedMergeTree('/clickhouse/tables/01/t_replicated','node4')-- 多个分片,1 个副本ReplicatedMergeTree('/clickhouse/tables/01/t_replicated','node3')ReplicatedMergeTree('/clickhouse/tables/01/t_replicated','node4')ReplicatedMergeTree('/clickhouse/tables/02/t_replicated','node3')ReplicatedMergeTree('/clickhouse/tables/03/t_replicated','node4')
ReplicatedMergeTree 原理解析
数据结构
在 ReplicatedMergeTree 的核心逻辑大量使用量 zookeeper,以实现多个 ReplicatedMergeTree 副本实例之间的协同,包括副本选举、副本状态感知、操作分发日志、任务队列和 BlockID 去重判断等。
在执行 insert 、merge 和 mutation 操作的时候,都会涉及与 zookeeper 的通信。
在与 zookeeper 通信时并不会涉及任何数据的传输,在查询数据的时候也不会访问 zookeeper,因此不必担心 zookeeper 承担太多压力。
zookeeper 内的节点结构
ReplicatedMergeTree 需要依靠 zookeeper 的事件监听机制实现各个副本之间的协同,当 ReplicatedMergeTree 表创建过程中会以 zk_path 为根路径,在 zookeeper 中为这张表创建一组监听节点,按照作用不同,监听节点可以分为如下几类:
- 元数据:
- /metadata:保存元数据信息,包括主键、分区间、采样表达式等。
- /columns:保存列字段信息,包括列名称和数据类型。
- /replicas:保存副本名称,对应设置参数中的 replica_name。
- 判断标识:
- /leader_election:对于副本的选举工作,主副本会主导 Merge 和 mutation 操作(alter delete / 和 alter update),这些任务在主副本完成之后,借助 zookeeper 将消息时间分发至其他副本。
- /blocks:记录 Block 数据库的 Hash 摘要,以及对应的 partition id 。通过 Hash 摘要能够判断 Block 是否重复,通过 partition ID 能够找到需要同步的分区。
- /block_numbers:按照分区的写入顺序,以相同顺序记录 partition ID。各个副本在本地进行 Merge 时,都会依照相同的 block_numbers 顺序进行。
- /quorum:记录 quorum 的数量,当至少有 quorum 数量的副本写入成功后,整个写操作才算成功,quorum 的数量有 insert_quorum 参数控制,默认为 0。
- 日志操作:
- /log:常规日志节点(insert、Merge 和 drop table),它是整个工作机制中最为重要的一环,保存了副本需要执行的任务指令。log 使用了 zookeeper 的持久节点,每条指令以 log- 为前缀递增,每个副本实例都会监听 /log 节点,当有新的指令加入时,他们会把指令加入副本各自的任务队列,并执行任务。
- /mutatios:mutation 操作 (alter delete / 和 alter update) 日志节点,节点命名没有前缀,其余逻辑与 /log 相同。
- /replicas/{replica_name}/*:每个副本各自的节点下的一组监听节点,用于指导副本在本地执行具体的任务指令,比较重要的有下面几个:
- /queue:任务队列节点,用于执行具体的操作任务从 /log 或 /mutations 节点监听到操作指令时,会将执行任务添加到该节点下,并给基于列执行。
- /log_pointer:log 日志指针节点,记录了最后一次执行 log 日志下标信息。
- /mutation_pointer:mutation 日志指针节点,记录了最后一次执行 mutation 日志下标信息。
Entry 日志对象的数据结构
在 zookeeper 中的两个重要的节点 log 和 mutation 在 Clickhouse 中被抽象成了两个 Entry 对象。
LogEntry(封装 log 节点的信息)拥有以下核心属性:
- source replica:发送这条 log 指令的来源,对应 replica_name。
- type:操作指令类型,主要有 get、merge、mutate 三种,分别对应从远程副本下载分区,合并分区和 mutation 操作。
- block_id:当前分区的 BlockID,对应 / blocks 路径下的子节点名称。
- partition_name:当前分区目录的名称。
MutationEntry(封装 mutation 接节点信息):
- source replica:发送这条 mutation 指令的来源,对应 replica_name。
- commands:操作指令,alter delete / 和 alter update。
- mutation_id:mutation 操作的版本号。
- partition_id:当前分区目录 ID。
副本操作流程
副本操作一般有数据写入,分区合并,数据修改和元数据修改 4 部分。
数据写入和元数据修改时分布式执行的,借助 zookeeper 的事件监听机制,多个副本之间会自动进行同步,但是这些操作不会使用 zookeeper 存储任何数据。
其他操作不支持分布式执行,如 SELECT、CREATE、DROP、RENAME、ATTACH 等。
INSERT 的执行流程
(1)创建测试表,该表由一个分片 0 个副本构成
CREATE TABLE t_replicated(id UInt8,name STRING,date DateTime) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/t_replicated', 'node3')PARTITION by toYYYYMM(date)ORDER BY id
在创建过程中 ReplicatedMergeTree 会进行如下操作:
- 根据 zk_path 初始化所有的 ZooKeeper 节点;
- 在 /replicas/ 节点下注册自己的副本实例 node3;
- 启动监听任务,监听 /log 日志节点;
- 参与副本选举,选举出出副本,选举的方式是向 /leader_election 插入子节点,第一个插入成功的副本就是主副本 。
创建表之后 zookeeper 元数据情况如下:
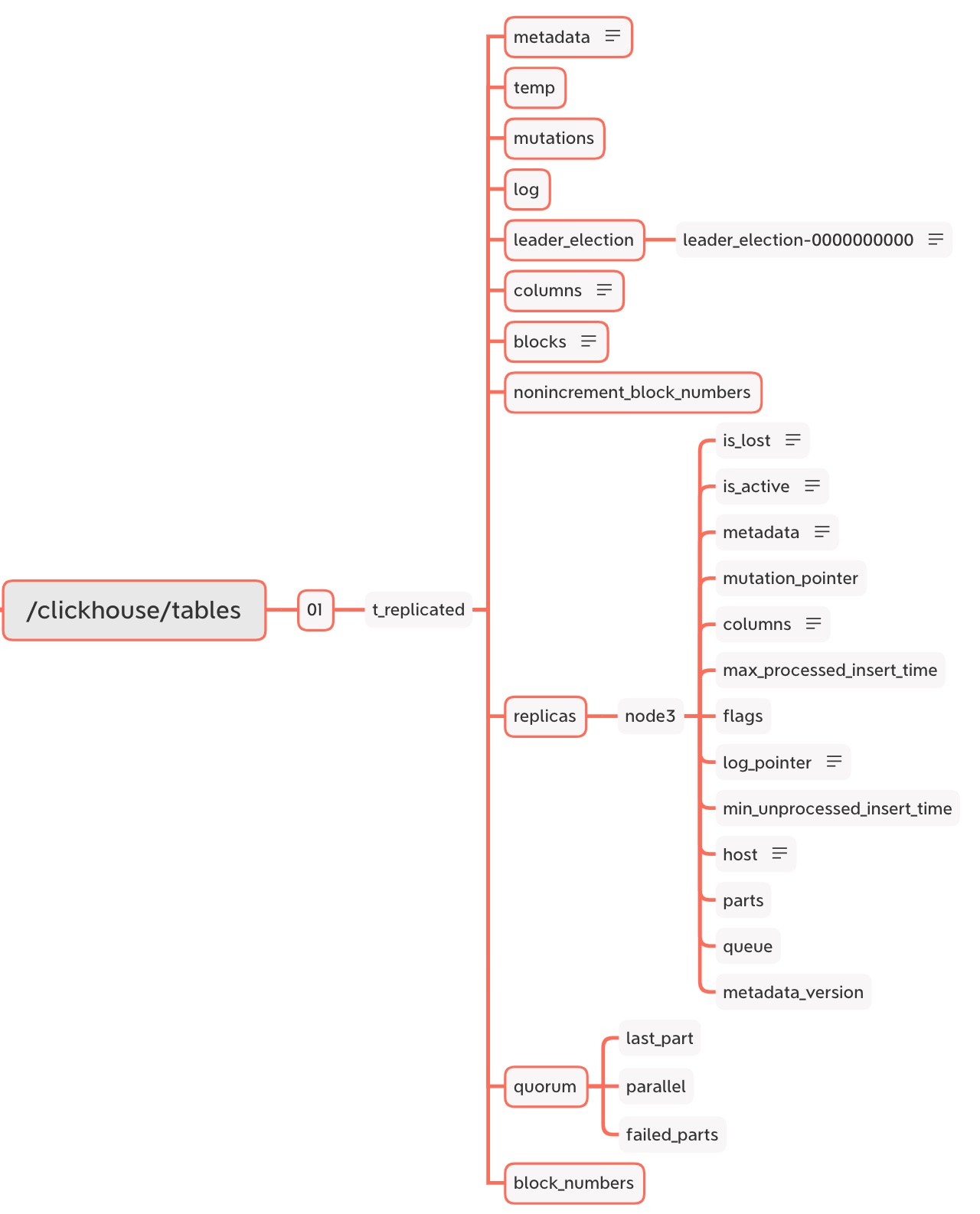
查看 zookeeper 中节点数据相关命令:
ls /clickhouseget /clickhousels /clickhouse/tablesget /clickhouse/tablesls /clickhouse/tables/01get /clickhouse/tables/01get /clickhouse/tables/01/t_replicatedls /clickhouse/tables/01/t_replicatedget /clickhouse/tables/01/t_replicated/metadatals /clickhouse/tables/01/t_replicated/metadataget /clickhouse/tables/01/t_replicated/templs /clickhouse/tables/01/t_replicated/tempget /clickhouse/tables/01/t_replicated/mutationsls /clickhouse/tables/01/t_replicated/mutationsget /clickhouse/tables/01/t_replicated/logls /clickhouse/tables/01/t_replicated/logget /clickhouse/tables/01/t_replicated/leader_electionls /clickhouse/tables/01/t_replicated/leader_electionls /clickhouse/tables/01/t_replicated/leader_election/leader_election-0000000001get /clickhouse/tables/01/t_replicated/leader_election/leader_election-0000000001get /clickhouse/tables/01/t_replicated/columnsls /clickhouse/tables/01/t_replicated/columnsget /clickhouse/tables/01/t_replicated/nonincrement_block_numbersls /clickhouse/tables/01/t_replicated/nonincrement_block_numbersget /clickhouse/tables/01/t_replicated/replicasls /clickhouse/tables/01/t_replicated/replicasget /clickhouse/tables/01/t_replicated/replicas/node3ls /clickhouse/tables/01/t_replicated/replicas/node3get /clickhouse/tables/01/t_replicated/replicas/node2/is_lostls /clickhouse/tables/01/t_replicated/replicas/node2/is_lostget /clickhouse/tables/01/t_replicated/replicas/node2/is_activels /clickhouse/tables/01/t_replicated/replicas/node2/is_activeget /clickhouse/tables/01/t_replicated/replicas/node2/metadatals /clickhouse/tables/01/t_replicated/replicas/node2/metadataget /clickhouse/tables/01/t_replicated/replicas/node2/mutation_pointerls /clickhouse/tables/01/t_replicated/replicas/node2/mutation_pointerget /clickhouse/tables/01/t_replicated/replicas/node2/columnsls /clickhouse/tables/01/t_replicated/replicas/node2/columnsget /clickhouse/tables/01/t_replicated/replicas/node2/max_processed_insert_timels /clickhouse/tables/01/t_replicated/replicas/node2/max_processed_insert_timeget /clickhouse/tables/01/t_replicated/replicas/node2/flagsls /clickhouse/tables/01/t_replicated/replicas/node2/flagsget /clickhouse/tables/01/t_replicated/replicas/node2/log_pointerls /clickhouse/tables/01/t_replicated/replicas/node2/log_pointerget /clickhouse/tables/01/t_replicated/replicas/node2/min_unprocessed_insert_timels /clickhouse/tables/01/t_replicated/replicas/node2/min_unprocessed_insert_timeget /clickhouse/tables/01/t_replicated/replicas/node2/hostls /clickhouse/tables/01/t_replicated/replicas/node2/hostget /clickhouse/tables/01/t_replicated/replicas/node2/partsls /clickhouse/tables/01/t_replicated/replicas/node2/partsget /clickhouse/tables/01/t_replicated/replicas/node2/queuels /clickhouse/tables/01/t_replicated/replicas/node2/queueget /clickhouse/tables/01/t_replicated/replicas/node2/metadata_versionls /clickhouse/tables/01/t_replicated/replicas/node2/metadata_versionget /clickhouse/tables/01/t_replicated/quorumls /clickhouse/tables/01/t_replicated/quorumls /clickhouse/tables/01/t_replicated/quorum/last_partget /clickhouse/tables/01/t_replicated/quorum/last_partls /clickhouse/tables/01/t_replicated/quorum/parallelget /clickhouse/tables/01/t_replicated/quorum/parallells /clickhouse/tables/01/t_replicated/quorum/failed_partsget /clickhouse/tables/01/t_replicated/quorum/failed_partsls /clickhouse/tables/01/t_replicated/block_numbersget /clickhouse/tables/01/t_replicated/block_numbers
(2)创建第二个副本实例
表的构成是 1 分片 1 副本:
CREATE TABLE t_replicated(id UInt8,name STRING,date DateTime) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/t_replicated', 'node2')PARTITION by toYYYYMM(date)ORDER BY id;
在创建第二个副本实例的时候流程如下:
- 会在 /Clickhouse/tables/01/t_replicated/replicas 节点下注册自己的副本 node2;
- 启动监听任务,监听 /log 日志节点;
- 参与主副本选举。
1 分片,1 副本时,zookeeper 元数据情况如下:
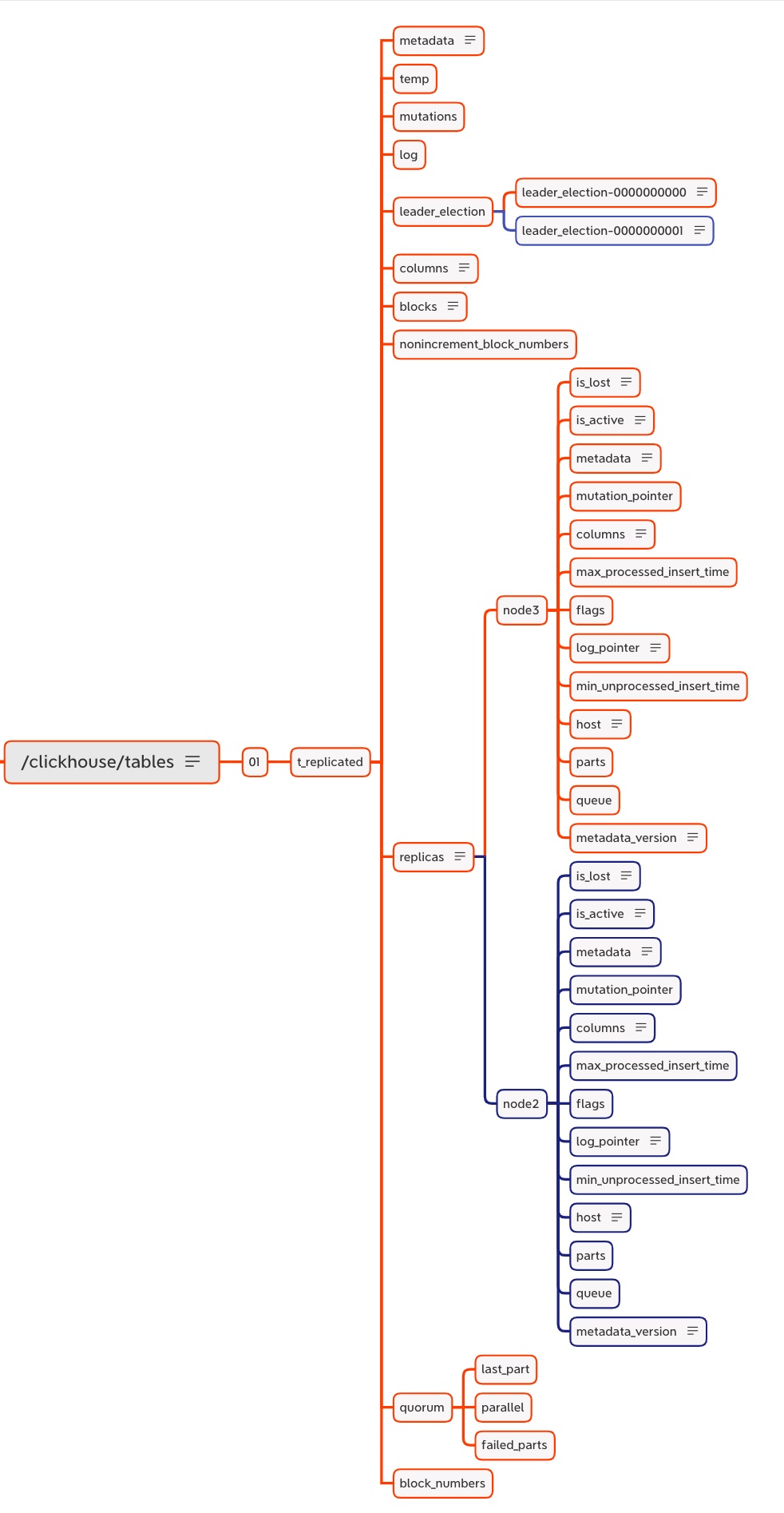
(3)向第一个副本写入数据
INSERT INTO t_replicated VALUES (1,'xiaoming','2021-07-21 18:01:49')
查看日志:
# 向 /blicks 节点写入该数据分区的 block_iddb_merge.t_replicated (f43ce61c-6253-473c-a54d-4d9d6da57613) (Replicated OutputStream): Wrote block with ID '202107_8139788293933794752_9955392769311530712', 1 rows# 向本地完成分区目录的写入<Trace> db_merge.t_replicated (f43ce61c-6253-473c-a54d-4d9d6da57613): Renaming temporary part tmp_insert_202107_1_1_0 to 202107_0_0_0.
查看 zookeeper 中 blocks 的元数据变化:
ls /clickhouse/tables/01/t_replicated/blocks# [202107_8139788293933794752_9955392769311530712] -- block_id 跟前面日志可以对应,该block_id 将作为后续去重操作的判断依据#get /clickhouse/tables/01/t_replicated/blocks/202107_8139788293933794752_9955392769311530712# 202107_0_0_0 -- 保存的值为数据所在分区
如果设置了 insert_quorum 参数,且 insert_quorum>=2 则 node3 会进一步监控已经写完操作的副本个数,只有写成功的副本数 大于等于 2 时,整个写操作才算成功。
(4)由第一个副本推送 log 日志
在上面执行完成之后,会继续由执行了 insert 的副本向 /log 节点推送操作日志。上面写入操作中,会由 node3 完成此操作。
查看 zookeeper 元数据:
ls /clickhouse/tables/01/t_replicated/log# [log-0000000000]get /clickhouse/tables/01/t_replicated/log/log-0000000000# format version: 4# create_time: 2021-07-21 12:29:59# source replica: node3# block_id: 202107_8139788293933794752_9955392769311530712# get -- 操作类型为 get# 202107_0_0_0# part_type: Compact
(5)第二个副本拉取 log 日志
node3 会一直监听 /log 节点的变化,当 node3 推送了 log-0000000000 之后,node3 会触发日志拉取任务并更新 log_pointer 将其指向最新日志下标。
查看 zookeeper 元数据:
get /clickhouse/tables/01/t_replicated/replicas/node2/log_pointer# 1
在拉取了 logEntry 之后,并不会直接执行,而是将其转为任务对象放到队列,因为在复杂情况下,同一时间内可能收到多个 logEntry 使用队列形式消化任务是一种更为合理的方式。
(6)第二个副本实例向其他副本发起下载请求
node3 基于 /queue 队列开始执行任务,当看到 type 为 get 的时候,就会知道远端的副本已经成功写入数据分区,而自己需要同步这些数据,node3 同步数据流程大概如下:
- 从 replicas 节点拿到所有的副本节点;
- 遍历副本,选取拥有最大的 log_pointer 且 /queue 子节点数量最少的副本,log_pointer 下标最大意味着该副本执行的日志最多,数据更加完整,/queue 最小意味着该副本目前的任务执行负担较小;
- 如果第一次请求失败,会再次请求,默认请求五次,由 max_fetch_partition_retries_count 参数控制。
(7)第一个副本响应数据下载
node3 的 DataPartsExchange 端口服务接收到调用请求,在得拉取数据请求后根据参数做出响应,将本地分区 202107_0_0_0 基于 DataPartsExchange 的服务响应发送会 node2。
(8)第二个副本实例下载数据并完成本地写入
node2 在收到分区数据后先将其写到临时目录,等到数据全部接收完之后,将目录重命名,至此整个写入数据流程结束。
在写入的整个过程中,zookeeper 不会进行实质性的数据传输。
MERGE 的执行流程
当 ReplicatedMergeTree 触发合并分区,即进入了这部分的流程。
无论 Merge 操作从哪个副本发起,其合并计划都会交给主副本来指定。整个流程从上至下按照时间顺序进行,大致分成 5 个步骤。
(1)创建远程连接,尝试与主副本通信
如果在非主副本节点执行 optimize 操作,强制触发 merge 合并,这时该节点会通过 /replicas 找到主副本,并与其建立连接。
(2)主副本接收通信
主副本接收并建立与远端副本的连接。
(3)主副本指定 merge 计划并推送 log
由主副本指定 merge 计划,并判断哪些分区需要被合并。选定之后将合并计划转为 log 日志对象推送到 log 日志,以通知所有副本开始合并,与此同时,主副本还会锁住执行线程,对日志的接收情况进行监听,监听行为由 replication_alter_partition_sync 参数控制,默认值为 1,当参数为 0 时,不做任何等待,当参数为 1 时,只等待主副本自身完成,当为 2 时,会等待所有副本拉取完成。
查看 zookeeper 元数据:
ls /clickhouse/tables/01/t_replicated/log# [log-0000000001, log-0000000000]get /clickhouse/tables/01/t_replicated/log/log-0000000001# format version: 4# create_time: 2021-08-12 17:18:32# source replica: node2# block_id:# merge -- 合并操作# 202107_0_0_0 -- 合并的分区# into# 202107_0_0_1 -- 合并后的分区# deduplicate: 0# part_type: Compact
(4)各个副本分别拉取 log 日志
当各个副本监听到 log-0000000001 的日志推送后,他们分别拉取本地日志,并推送到各自的 queue 任务队列。
(5)各个副本分别在本地执行 merge
各个副本基于各自的 /queue 队列开始执行任务,Merge 流程到此结束。
MUTATION 的执行流程
当对 ReplicatedMergeTree 执行 ALTER DELETE 和 ALTER UPDATE 操作时,就会进行 mutation 的执行流程。
与 merge 类似,无论从哪个节点发起 mutation 操作,都会由主副本进行相应。
(1)推送 mutation 日志
在某个节点尝试通过 delete 删除数据,命令如下:
ALTER TABLE t_replicated DELETE WHERE id = 1;
执行之后该副本会做两个操作:
- 创建 mutation id;
- 将 mutation 转换为 mutationEntry 日志并推送到 /Clickhouse/tables/01/t_replicated/mutations。
查看 zookeeper 元数据:
ls /clickhouse/tables/01/t_replicated/log# [log-0000000003, log-0000000001, log-0000000002, log-0000000000]get /clickhouse/tables/01/t_replicated/log/log-0000000003# format version: 4# create_time: 2021-08-12 17:56:32# source replica: node2# block_id:# drop# 202107_0_0_999999999_1
mutation 操作日志由 /Clickhouse/tables/01/t_replicated/mutations 分发至各个副本。
(2)所有副本实例各自监听 mutation 日志
所有副本都会监听 /Clickhouse/tables/01/t_replicated/mutations ,当有新的日志节点创建时他们都能监听到,但并不是每个副本都会响应,他们会先判断自己是否是主副本。
(3)由主副本实例响应 mutation 日志并推送 log 日志
主副本会响应 mutation 日志,将 mutation 日志转换为 logEntry 日志并推送到 /log 节点,以通知各个副本执行具体操作。
查看 zookeeper 元数据:
ls /clickhouse/tables/01/t_replicated/log# [log-0000000003, log-0000000001, log-0000000002, log-0000000000]get /clickhouse/tables/01/t_replicated/log/log-0000000003# format version: 4# create_time: 2021-08-12 17:56:32# source replica: node2# block_id:# drop# 202107_0_0_999999999_1
(4)各个副本分别拉取 log 日志
主副本推送 log 日志后,其余副本会监听到 log 日志节点的变化,根据日志内容将相关操作推送到各自的 /queue 队列。
(5)各个副本实例分别在本地执行 mutation
各个副本会基于自己的 /queue 队列开始执行任务,执行结束后,mutation 流程执行结束。
ALTER 执行流程
当 ReplicatedMergeTree 执行 ALTER 操作时进行元数据修改的时候,就会进入 ALTER 逻辑,例如增加,删除表字段等。
(1)修改共享元数据
在一个节点增加一个列字段,执行之后,该节点会修改 zookeeper 内的共享元数据节点,数据修改后,节点的版本号同时提升,与此同时,该节点还会监听所有副本的修改完成情况。
(2)监听共享元数据变更并各自执行本地修改
共享元数据元数据更改之后,其余副本会将自身的元数据版本号与共享元数据版本号进行对比,如果自身元数据版本号低于共享元数据版本号,则进行元数据更新。
(3)确认所有副本完成修改
当前确认所有副本均修改成功,则 ALTER 流程结束。

若有收获,就点个赞吧
0 人点赞
