赫夫曼编码是赫夫曼树在电讯通信中的经典应用之一。
广泛地用于数据文件压缩。其压缩率通常在20%~90%之间。
赫夫曼编码是可变长编码(VLC)的一种。
赫夫曼编码压缩数据,是无损压缩。
原理剖析
定长编码
比如下面的字符串:
i like like like java do you like a java
一共有40个字符(包括标点符号和空格)
计算机中的信息最终都会转换成01二进制,上面的字符串最终转换成二进制如下
01101001001000000110110001101001011010110110010100100000011011000110100101101011011001010010000001101100011010010110101101100101001000000110101001100001011101100110000100100000011001000110111100100000011110010110111101110101001000000110110001101001011010110110010100100000011000010010000001101010011000010111011001100001
上面的二进制可以参考下图,不足8位的在前面补0,8位一字节,就是上面字符串的一个字符。
转换成二进制后,二进制的长度是320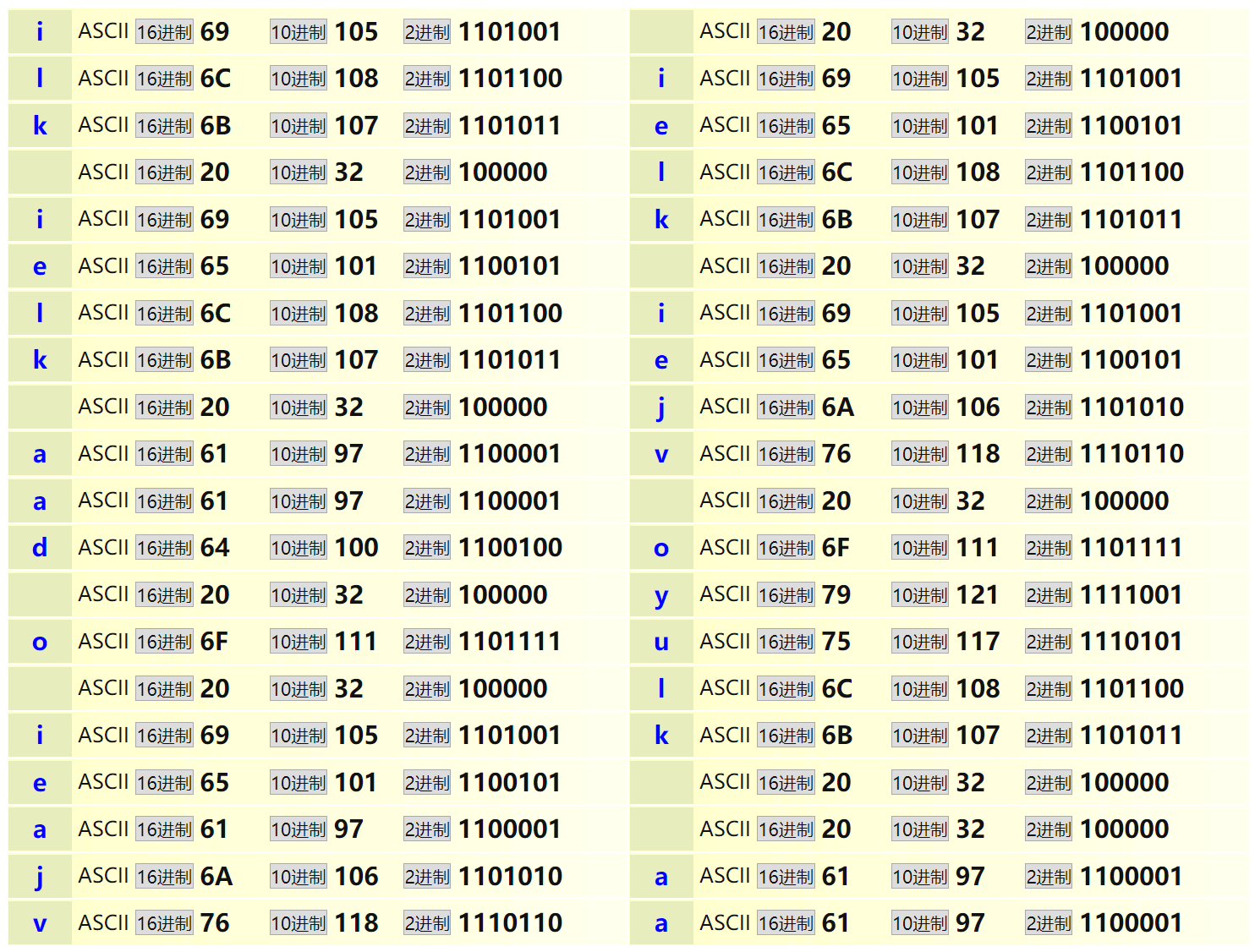
变长编码
i like like like java do you like a java
- 统计每个字符对应的个数
- d:1
- y:1
- u:1
- j:2
- v:2
- o:2
- l:4
- e:4
- i:5
- a:5
- :9
- 按各个字符出现的次数进行编码,原则是出现次数越多的,则编码越小,比如空格出现了9次,编码为0
- 0=
- 1=a
- 10=i
- 11=e
- 100=k
- 101=l
- 110=o
- 111=v
- 1000=j
- 1001=u
- 1010=y
- 1011=d
- 按照上面的各个字符编码规定,最终的编码是
10010110100……
根据颜色可以一一对应上面的编码规则,但是这种编码存在二义性。
比如前面三个字符100,这里是分成10,0,代表i,也可以划分成1,0,0,代表a。
解决这种二义性的办法,如下
前缀编码
字符的编码都不能是其他字符编码的前缀,符合此要求的编码叫做前缀编码,即不能匹配到重复的编码。
具体例子如下
赫夫曼编码
i like like like java do you like a java
- 统计每个字符对应的个数
- d:1
- y:1
- u:1
- j:2
- v:2
- o:2
- l:4
- e:4
- i:5
- a:5
- :9
- 按照上面字符出现的次数构建一颗赫夫曼树(看赫夫曼树的笔记),次数作为权值,字符也要记录在节点里面

- 根据赫夫曼树给各个字符规定编码,向左的路径为0,向右的路径为1,编码如下:
- o:1000
- u:10010
- d:100110
- y:100111
- i:101
- a:110
- k:1110
- e:1111
- j:0000
- v:0001
- l:001
- :01
赫夫曼编码是前缀编码,没有哪个编码是另一个编码的前缀,这样就不会出现多义性
- 按照赫夫曼编码,上面的字符对应的编码就是
101010011011110111101001101111011110100110111101111010000110000111001100111100011001111000100100100110111101111011100100001100001110
如上编码,匹配数据时,从左到右,1没有,10没有,101,发现能匹配到i,101后面的0没有,01发现能匹配空格……
赫夫曼编码长度变成了132,压缩了(320-132)/320=58.75%
注意:
赫夫曼编码根据排序方法的不同,也可能不太一样,这样对应的赫夫曼编码不完全一样,但是WPL是一样的,都是最小的。所以最终的结果都是一样的
赫夫曼编码与解码代码
using System;using System.Collections.Generic;using System.Globalization;using System.IO;using System.Runtime.Serialization.Formatters.Binary;using System.Text;namespace ConsoleApp1{class Program{//生成赫夫曼树对应的赫夫曼编码,用字典存,key是原始数据,value是编码值static Dictionary<byte, string> huffmanCodes = new Dictionary<byte, string>();static void Main(string[] args){string str = "i like like like java do you like a java";//得到字节数组byte[] bytes = Encoding.Default.GetBytes(str);Console.WriteLine("赫夫曼编码后的字节数组");byte[] hfcb = huffmanZip(bytes);foreach (var b in hfcb){Console.Write(b + " ");}Console.WriteLine();Console.WriteLine("解码");byte[] dbytes = decode(hfcb);Console.WriteLine(Encoding.Default.GetString(dbytes));}#region 编码//把数据字节数组做成节点集合public static List<HFNode> getNodes(byte[] bytes){List<HFNode> nodes = new List<HFNode>();//存储每个byte出现的次数,用字典,唯一键Dictionary<byte, int> weights = new Dictionary<byte, int>();foreach(var b in bytes){bool bo =weights.ContainsKey(b);if (bo)weights[b] += 1;elseweights.Add(b, 1);}//把每个键值对转换成nodes集合foreach(var w in weights){nodes.Add(new HFNode(w.Value, w.Key));}return nodes;}//创建赫夫曼树public static HFNode CreateHuffmanTree(List<HFNode> nodes){while (nodes.Count > 1){//排序从小到大nodes.Sort();//取出前两棵最小的二叉树HFNode leftnode = nodes[0];HFNode rightnode = nodes[1];//合并成一颗新的二叉树HFNode parent = new HFNode(leftnode.weight + rightnode.weight, 0);parent.left = leftnode;parent.right = rightnode;//去掉已经使用的两个节点,加入新的节点nodes.Remove(leftnode);nodes.Remove(rightnode);nodes.Add(parent);}//nodes最后的一个节点就是赫夫曼树的根节点return nodes[0];}//将传入的hfnode节点的所有叶子节点的赫夫曼编码得到//node是传入节点//code是路径:左子节点是0,又子节点是1//path是用于拼接路径public static void getCodes(HFNode node,string code,StringBuilder path){path.Append(code);if (node != null){//判断当前节点是叶子节点还是非叶子节点if (node.left!=null || node.right!=null)//左右子节点只要有一个不为null,就是非叶子节点{//递归getCodes(node.left, "0", path);getCodes(node.right, "1", path);}else//叶子节点{//表示找到了某个叶子节点的最后huffmanCodes.Add(node.data, path.ToString());}}}//将字符串对应的byte[]数组,通过生成赫夫曼编码表,返回一个赫夫曼编码压缩后的byte[]//bytes:原始数组public static byte[] Zip(byte[] bytes){//利用huffmanCodes将bytes转成赫夫曼编码对应的字符串string hfcstr = "";//赫夫曼编码对应的字符串StringBuilder strb = new StringBuilder();//用StringBuilder来拼接,速度快foreach( var b in bytes){//在赫夫曼编码字典里面查找strb.Append(huffmanCodes[b]);}hfcstr = strb.ToString();//Console.WriteLine(hfcstr);//将hfcstr字符串,8位一字节的转换成一个byte[]数组//先计算byte[]的长度,如果hfcstr%8有余数,始终都要+1,不如直接+7后/8,保留整数部分int len = (hfcstr.Length + 7) / 8;//创建存储压缩后的byte数组byte[] hfcb = new byte[len];int index = 0;//数组的计数器,记录第几个bytefor(int i = 0; i < hfcstr.Length; i += 8)//8位1字节所以步长+8{//从i开始截取8个字符string strbyte = "";if (i + 8 > hfcstr.Length)//最后一次,不够8位strbyte += hfcstr.Substring(i);elsestrbyte += hfcstr.Substring(i, 8);//将strbyte转换成byte放入到hfcb里面hfcb[index++] = Convert.ToByte(strbyte,2);}return hfcb;}/// <summary>/// 赫夫曼压缩总方法/// </summary>/// <param name="bytes">原始字节数组</param>/// <returns></returns>public static byte[] huffmanZip(byte[] bytes){//1.根据原始字节数据,得到赫夫曼节点集合List<HFNode> hfl = getNodes(bytes);//2.根据赫夫曼节点集合创建赫夫曼树,得到根节点HFNode root = CreateHuffmanTree(hfl);//3.得到赫夫曼编码字典getCodes(root, "", new StringBuilder());//4.得到一个赫夫曼编码压缩后的字节数组byte[] hfcb = Zip(bytes);return hfcb;}#endregion#region 解码//将一个byte转换成一个二进制的字符串,flag:最后一个字节不用补高位,这儿flag就是判断是否补高位的public static string byteTobitstring(byte b,bool flag){string bitstr = Convert.ToString(b,2);//转换成二进制字符串if (flag)//要补高位{int len = 8 - bitstr.Length;for (int t = 0; t < len; t++)bitstr = "0" + bitstr;}return bitstr;}/// <summary>/// 赫夫曼解码./// </summary>/// <param name="huffmanBytes">传入一个赫夫曼编码后的一个字节数组</param>/// <returns></returns>public static byte[] decode(byte[] huffmanBytes){//先得到huffmanBytes对应的二进制字符串string bitstr = "";StringBuilder sb = new StringBuilder();//用StringBuilder拼接速度快for(int i = 0; i < huffmanBytes.Length; i++){//判断是否是最后一个字节,如果是最后一个字节,不用补高位,是多少位就是多少位数bool b = !(i == huffmanBytes.Length - 1);sb.Append(byteTobitstring(huffmanBytes[i], b));}bitstr = sb.ToString();Console.WriteLine("得到对应的二进制字符串完成");//Console.WriteLine(bitstr);//把字符串按照指定的赫夫曼编码进行解码//原来的字典是通过字符ASCII码查询赫夫曼编码,现在重新建一个字典,反过来通过赫夫曼编码查询字符ASCII码Dictionary<string, byte> hfcodes = new Dictionary<string, byte>();foreach(var a in huffmanCodes)hfcodes.Add(a.Value, a.Key);//创建一个集合存放byteList<byte> list = new List<byte>();//扫描bitstr,i就是每个字符的指针for(int i = 0; i < bitstr.Length; i++){//长度,从i开始多少长度的字符串,是一个赫夫曼编码。这个长度区间在1——bitstr.Length - i之间,一定得是<=,能匹配到最后一个字符for (int t = 1; t <= bitstr.Length - i; t++){//判断从i开始,取t个字符的字符串是不是已经存在的赫夫曼编码,bool b = hfcodes.ContainsKey(bitstr.Substring(i, t));if(b){//如果是赫夫曼编码,就把数据字符的ASCII码加入到list中list.Add(hfcodes[bitstr.Substring(i, t)]);i += t-1;//从0开始到i+t之前的字符串已经扫描过了,现在从i+t开始,为什么要t-1,因为这里退出后,进入外层循环,i++,先-1,在++,就保持不变break;}}}//到这里list里面就已经存放了所有字符的ASCII码return list.ToArray();}#endregion/// <summary>/// 赫夫曼节点实现IComparable接口,作用是进行排序/// </summary>public class HFNode : IComparable<HFNode>{public int weight;//权值,表示字符出现的次数public byte data;//存放数据本身,比如'a'==97,' '==32,存放ASCII码public HFNode left;public HFNode right;public HFNode(int weight,byte data){this.weight = weight;this.data = data;}//实现接口方法public int CompareTo(HFNode hfnode){//从小到大排序return this.weight - hfnode.weight;}//前序遍历public void preOrder(){Console.WriteLine(this.weight);if (this.left != null)this.left.preOrder();if (this.right != null)this.right.preOrder();}}}}
赫夫曼编码压缩文件代码
using System;using System.Collections.Generic;using System.Globalization;using System.IO;using System.Runtime.Serialization.Formatters.Binary;using System.Text;namespace ConsoleApp1{class Program{//生成赫夫曼树对应的赫夫曼编码,用字典存,key是原始数据,value是编码值static Dictionary<byte, string> huffmanCodes = new Dictionary<byte, string>();static void Main(string[] args){//zipFile(@"D:\B\a.pdf", @"D:\B\a.dat");unzipFile(@"D:\B\a.dat", @"D:\B\Aa.pdf");}//省略部分和上面一样#region 编码public static List<HFNode> getNodes(byte[] bytes){}public static HFNode CreateHuffmanTree(List<HFNode> nodes){}public static void getCodes(HFNode node,string code,StringBuilder path){}public static byte[] Zip(byte[] bytes){}public static byte[] huffmanZip(byte[] bytes){}#endregion#region 解码public static string byteTobitstring(byte b,bool flag){}public static byte[] decode(byte[] huffmanBytes){}#endregion#region 文件压缩public static void zipFile(string srcFileName,string dstFileName){FileStream srcstream = new FileStream(srcFileName, FileMode.Open, FileAccess.Read);byte[] b = new byte[srcstream.Length];srcstream.Read(b, 0, b.Length);byte[] hfcb = huffmanZip(b);//序列化两个东西到文件里面,赫夫曼字节数组,和赫夫曼编码字典FileStream dststream = new FileStream(dstFileName, FileMode.OpenOrCreate, FileAccess.Write);BinaryFormatter formatter = new BinaryFormatter();formatter.Serialize(dststream, hfcb);formatter.Serialize(dststream, huffmanCodes);srcstream.Dispose();dststream.Dispose();Console.WriteLine("压缩成功");}public static void unzipFile(string zipFileName,string dstFileName){FileStream zipstream = new FileStream(zipFileName, FileMode.Open, FileAccess.Read);BinaryFormatter formatter = new BinaryFormatter();byte[] hfbs = (byte[])formatter.Deserialize(zipstream);huffmanCodes = (Dictionary<byte, string>)formatter.Deserialize(zipstream);Console.WriteLine("反序列化完成");//解压赫夫曼编码byte[] bytes = decode(hfbs);Console.WriteLine("解压赫夫曼编码完成");//输出文件FileStream dststream = new FileStream(dstFileName, FileMode.OpenOrCreate, FileAccess.Write);dststream.Write(bytes, 0, bytes.Length);zipstream.Dispose();dststream.Dispose();Console.WriteLine("解压成功");}#endregionpublic class HFNode : IComparable<HFNode>{}}}

若有收获,就点个赞吧
0 人点赞
