一、架构
1、数仓架构介绍
神策数据:
云上数仓:https://www.aliyun.com/solution/datavexpo/datawarehouse
2、数仓的输入输出
输入系统:用户埋点行为数据、后台产生的业务数据、爬虫数据。
输出系统(BI):报表系统、大屏展示、用户画像系统、推荐系统
3、系统流程
4、框架选型
1)Apache:运维麻烦,需要对组件兼容性进行维护
2)CDH:国内使用最多,不开源,对中、小公司没有影响(建议使用)
3)HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用较少
5、版本选择
Apache、CDH
6、集群规模(实习项目也可)
每条消息1K,压缩后不0.1K
Kafka所用的空间计算
7、数仓分层架构
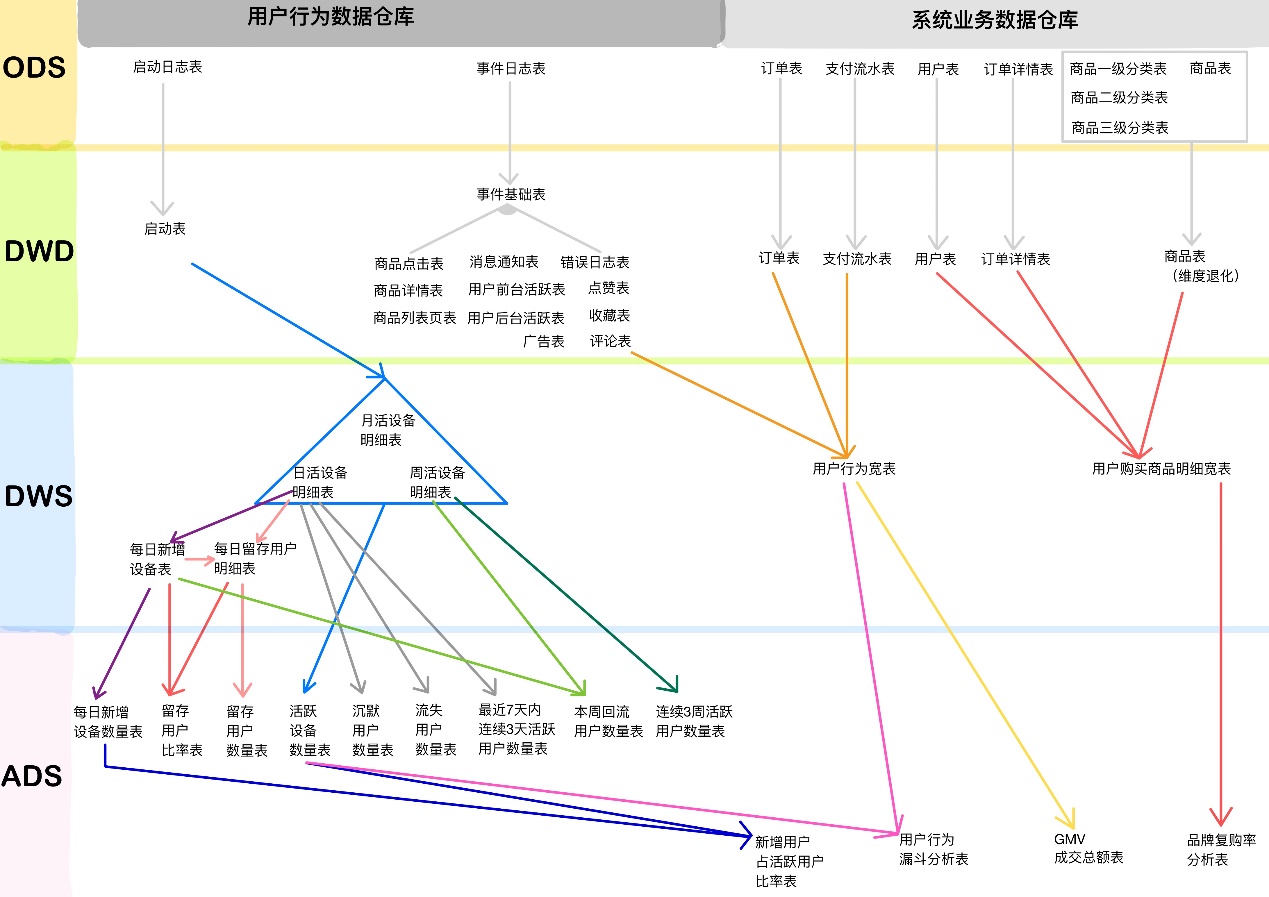
ods 原始数据层 存放原始数据,保持原貌不做处理
dwd 明细数据层 对ods层数据清洗(去除空值,脏数据,超过极限范围的数据)
dws 服务数据层 轻度聚合 形成宽表
ads 应用数据层 具体需求
8、为什么对数仓分层
分层优点:复杂问题简单化、清晰数据结构(方便管理)、增加数据的复用性、隔离原始数据(解耦)
二、行为日志
1、数据格式
(1)组成
公共字段:基本所有安卓手机都包含的字段
业务字段:埋点上报的字段,有具体的业务类型
(2)示例
{
“ap”:”xxxxx”,//项目数据来源 app pc
“cm”: { //公共字段common
“mid”: “”, // (String) 设备唯一标识
“uid”: “”, // (String) 用户标识
“vc”: “1”, // (String) versionCode,程序版本号
“vn”: “1.0”, // (String) versionName,程序版本名
“l”: “zh”, // (String) 系统语言
“sr”: “”, // (String) 渠道号,应用从哪个渠道来的。
“os”: “7.1.1”, // (String) Android系统版本
“ar”: “CN”, // (String) 区域
“md”: “BBB100-1”, // (String) 手机型号
“ba”: “blackberry”, // (String) 手机品牌
“sv”: “V2.2.1”, // (String) sdkVersion
“g”: “”, // (String) gmail
“hw”: “1620x1080”, // (String) heightXwidth,屏幕宽高
“t”: “1506047606608”, // (String) 客户端日志产生时的时间
“nw”: “WIFI”, // (String) 网络模式
“ln”: 0, // (double) lng经度
“la”: 0 // (double) lat 纬度
},
“et”: [ //事件系统 EventSystem
{
“ett”: “1506047605364”, //客户端事件产生时间
“en”: “display”, //事件名称 启动start和事件根据名称的不同
“kv”: { //事件结果,以key-value形式自行定义
“goodsid”: “236”,
“action”: “1”,
“extend1”: “1”,
“place”: “2”,
“category”: “75”
}
}
]
}
2、常见需求逻辑
(1)用户活跃
启动日志中统计不同设备id出现次数(group by)
(2)用户新增
活跃用户表 left join 用户新增表,用户新增表中mid为空的即为用户新增
(3)用户单日留存
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
(4)沉默用户
含义:登录时间为7天前,且只出现过一次
对日活表分组,登录次数为1,且是在一周前登录
(5)本周回流用户
本周活跃left join本周新增 left join上周活跃,且本周新增id和上周活跃id都为null
(6)流失用户
含义:7天前登录用户
按照设备id对日活表分组【登录过】,且七天内没有登录过
(7)最近连续3周活跃用户数
按照设备id对周活进行分组,统计次数大于3次
(8)最近七天内连续三天活跃用户数
1)查询出最近7天的活跃用户,并对用户活跃日期进行排名
2)计算用户活跃日期及排名之间的差值
3)对同用户及差值分组,统计差值个数
4)将差值相同个数大于等于3的数据取出,然后去重(去的是什么重???),即为连续3天及以上活跃的用户
(9)其他
7天连续收藏、点赞、购买、加购、付款、浏览、商品点击、退货
1个月连续7天
连续两周:
三、电商业务交互
1、表和字段
(1)表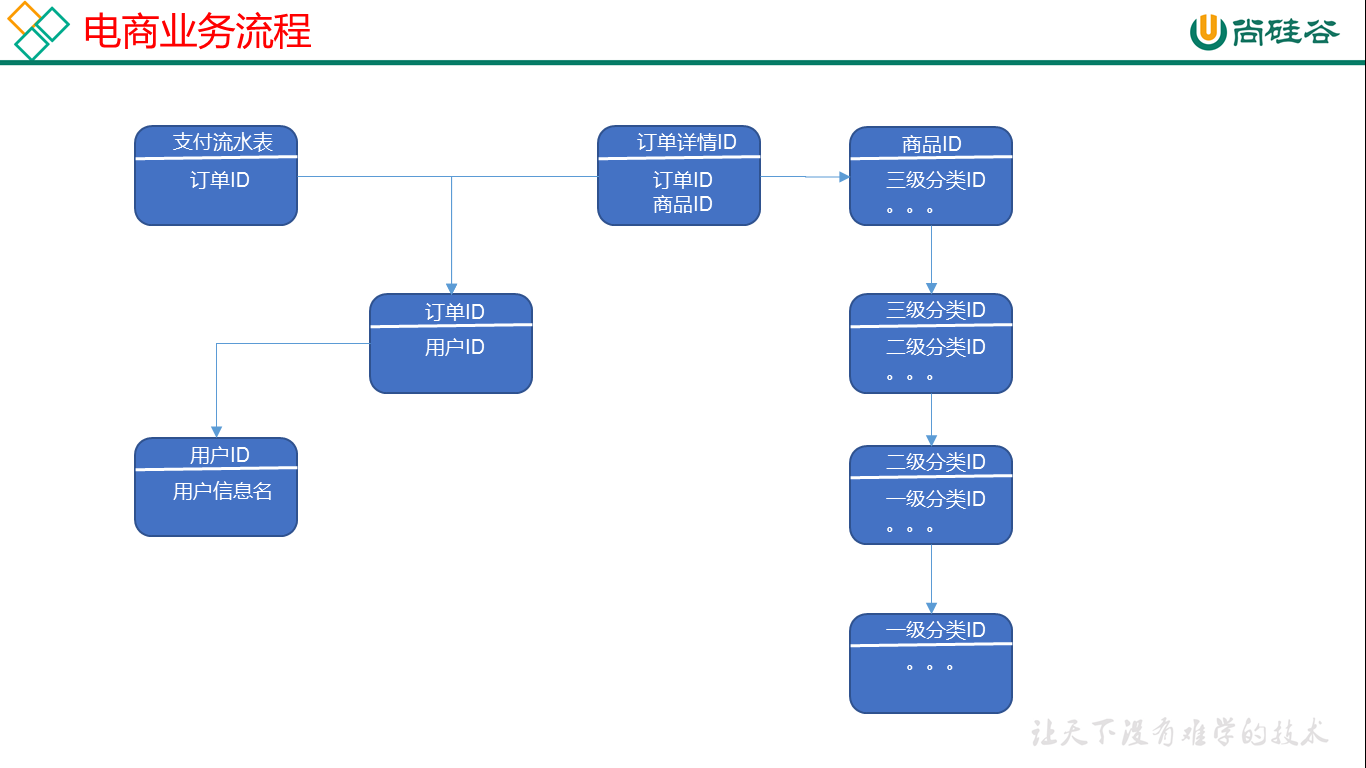
(2)字段
SKU:【库存】一台银色、128G内存的、支持联通网络的iPhoneX
SPU:【商品】iPhoneX
Tm_id:【品牌标志trademark】品牌Id苹果,包括IPHONE,耳机,mac等
2、业务表的组成
(1)组成
订单表(order_info):订单状态、流水id
订单详情表(order_detail):商品id
商品表
用户表
商品一/二/三级分类表:包含上级品类id
支付流水表:交易流水、支付时间
(2)订单表跟订单详情表有什么区别
订单表的订单状态会变化,订单详情表不会,因为没有订单状态
订单表记录支付相关信息+总金额
订单详情表记录商品相关信息+商品金额
3、表分类及同步策略
(1)表的分类
实体表,维度表,事务型事实表,周期型事实表、累积型事实表
订单表(order_info)(周期型事实表,拉链表?)
订单详情表(order_detail)(事务型事实表)
商品表(实体表)
用户表(实体表)
商品一级分类表(维度表)
商品二级分类表(维度表)
商品三级分类表(维度表)
支付流水表(事务型事实表)
(2)同步策略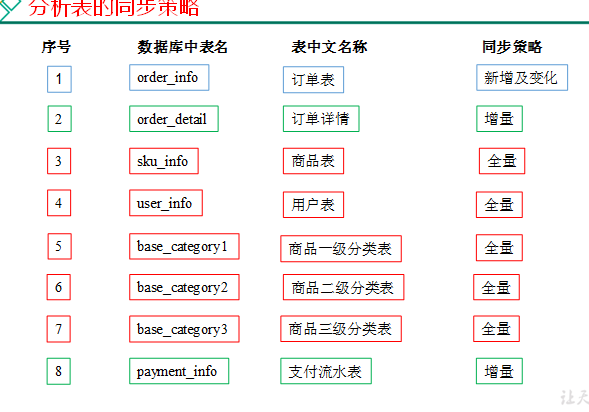
总结:
实体表,维度表,每日全量或者每月(更长时间)全量
事务型事实表:每日增量
周期性事实表:拉链表
4、数据模型
(1)关系建模与维度建模
Mysql关系建模:应用于OLTP系统中,为了保证一致性,遵循第三范式
Hive 维度建模:应用于OLAP系统中,避免多表关联影响执行效率,分为事实表和维度表。所有维度表围绕着事实表进行解释。
(2)维度建模的分类
雪花模型、星型模型和星座模型
(在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。)
星型模型(一级维度表),雪花(多级维度),星座模型(星型模型+多个事实表)
5、拉链表
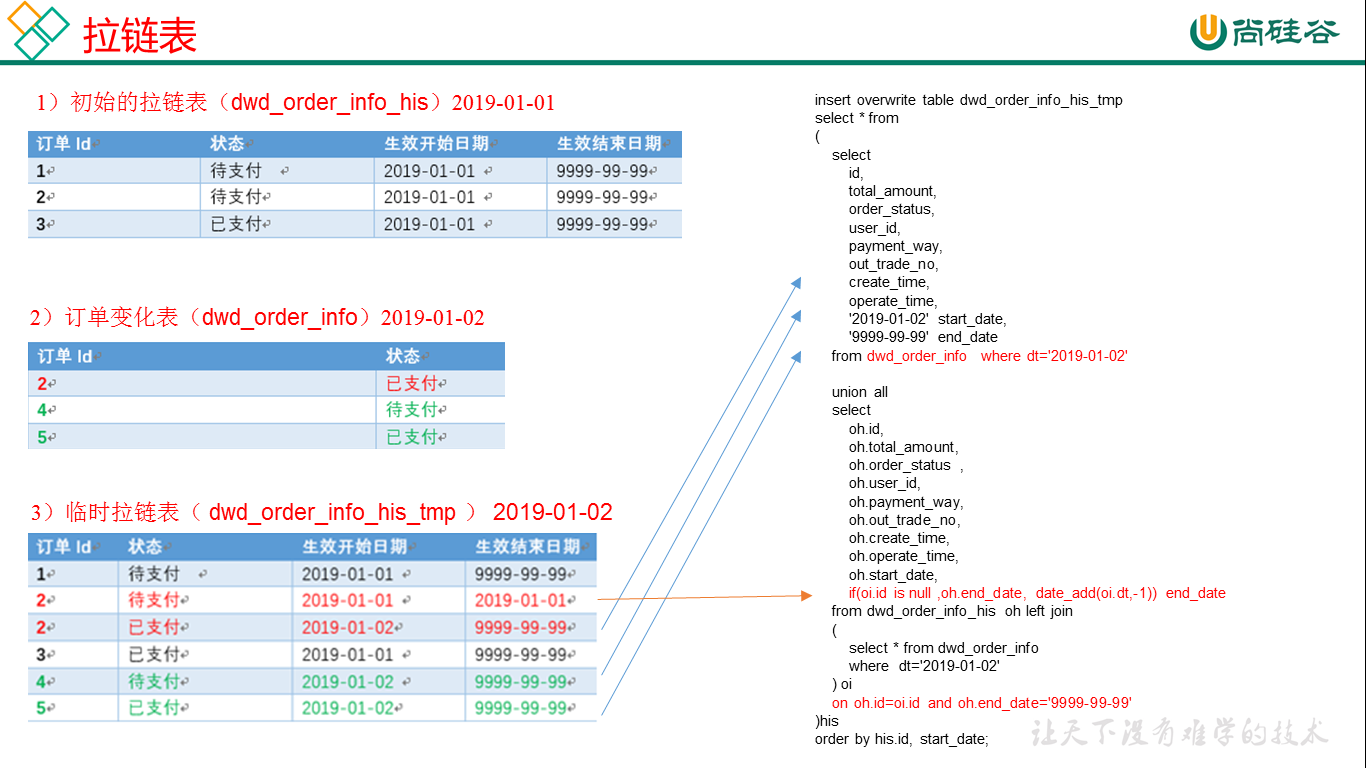
拉链表处理的业务场景:主要处理缓慢变化维的业务场景。(用户表、订单表)
订单表拉链表 dwd_order_info_his
id string COMMENT ‘订单编号’,
total_amount decimal(10,2) COMMENT ‘订单金额’,
order_status string COMMENT ‘订单状态’,
user_id string COMMENT ‘用户id’ ,
payment_way string COMMENT ‘支付方式’,
out_trade_no string COMMENT ‘支付流水号’,
create_time string COMMENT ‘创建时间’,
operate_time string COMMENT ‘操作时间’ ,
start_date string COMMENT ‘有效开始日期’,
end_date string COMMENT ‘有效结束日期’
1)创建订单表拉链表,字段跟拉链表一样,只增加了有效开始日期和有效结束日期
初始日期,从订单变化表ods_order_info导入数据,且让有效开始时间=当前日期,有效结束日期=9999-99-99
(从mysql导入数仓时只导新增和变化数据ods_order_info)
2)建一张拉链临时表dwd_order_info_his_tmp,字段跟拉链表完全一致
3)新的拉链表中应该有这几部分数据,
(1)增加订单变化表dwd_order_info的全部数据
(2)更新旧的拉链表左关联订单变化表dwd_order_info,关联字段:订单id, where 过滤出end_date只等于9999-99-99的数据,如果旧的拉链表中的end_date不等于9999-99-99,说明已经是终态了,不需要再更新
如果dwd_order_info.id is null , 没关联上,说明数据状态没变,让end_date还等于旧的end_date
如果dwd_order_info.id is not null , 关联上了,说明数据状态变了,让end_date等于当前日期-1
把查询结果插入到拉链临时表中
4)把拉链临时表覆盖到旧的拉链表中
四、CDH数仓
五、新数仓

若有收获,就点个赞吧
0 人点赞
