一、Spark概念及内核
1、部署方式
1)Local:本地模式,用于单机测试环境。
2)Standalone:自带脱机模式,Spark自身的基于Mster+Slaves的资源调度集群,任务提交给Master管理。【master+slave+历史服务器+Master的HA】【多台机器安装spark】
3)Yarn:客户端直连Yarn,无需额外构建Spark集群。有yarn-client和yarn-cluster两种模式,区别:Driver程序的运行节点。【安装一台spark】
4)Mesos:国内大环境比较少用。
2、架构-不同数据操作**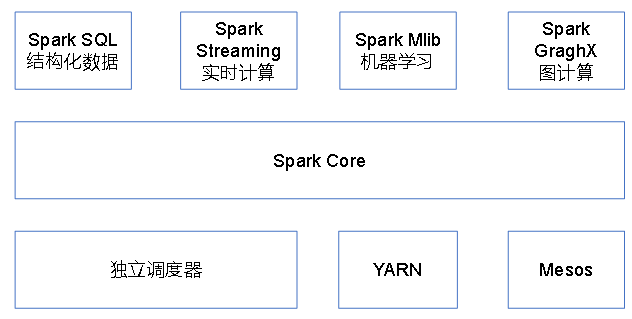
Spark Core:基本功能(任务调度、内存管理、错误恢复、与存储系统交互)、弹性Resilient 分布式数据集RDD的API【弹性数据】
Spark SQl:操作结构化数据的程序包,数据查询,并支持多种数据源(Hive 表、Parquet 以及 JSON 等)【结构化数据】
Spark Streaming:流式计算,提供用来操作数据流的 API,与Core中的RDD API高度对应【流式数据】
Spark MLlib:机器学习库,以及模型评估、数据导入等功能
Spark GraphX :图计算和挖掘
3、内核
(1)概念
核心组件的运行机制、任务调度、内存管理、运行原理
(2)核心组件
Driver驱动器节点:执行main方法进行作业提交,将程序转化为作业job,并将作业转化为计算任务task,在executor中调度任务task
Executor:运行具体任务task,并负责对RDD进行持久化
(3)运行流程
提交任务、启动Driver进程、注册程序、分配Executor、执行main函数、懒执行到action算子时按照宽依赖对stage进行划分
一个stage对应一个taskset,将task分发到指定的Executor执行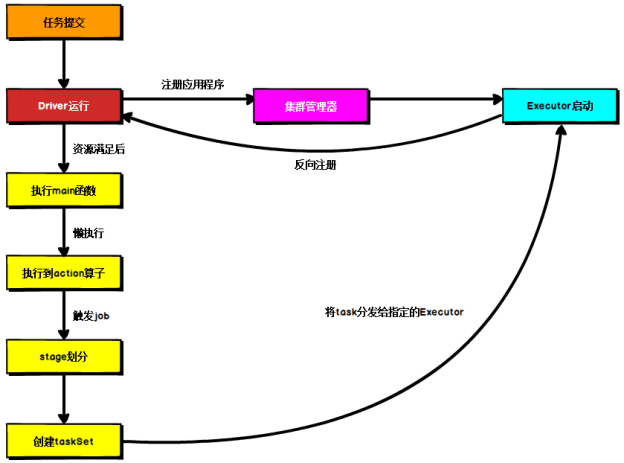
一个Spark应用程序包括Job、Stage以及Task三个概念(计算题)
Job 是以 Action 方法为界,遇到一个 Action 方法则触发一个 Job
Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle)为界
Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task
4、通讯架构
(1)概述
基于Actor模型,独立实体之间通过消息来进行通信
Endpoint端点(Client/Master/Worker)有1个InBox和N个OutBox
(N>=1,N 取 决于当前 Endpoint 与多少其他的 Endpoint 进行通信,一个与其通讯的其他 Endpoint对应一个 OutBox)

Endpoint 接收到的消息被写入 InBox,发送出去的消息写入 OutBox 并被发送到其他 Endpoint 的 InBox 中。
(2)高层架构
实际还有一个dispatcher分发器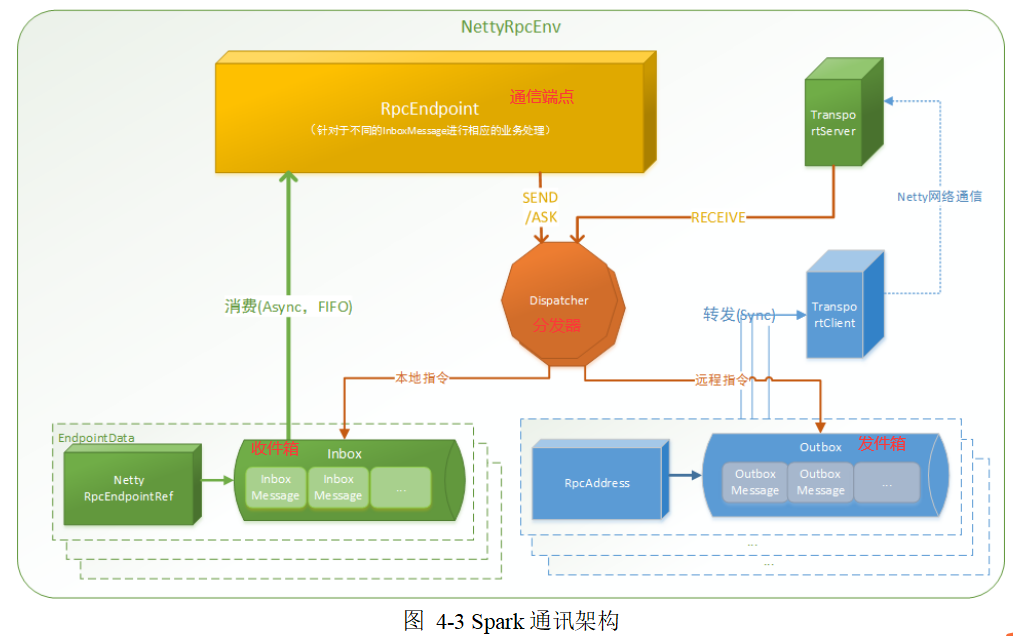
5、任务调度机制
(1)任务提交
Driver线程初始化SparkContext对象,准备运行所需的上下文;保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源;根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
(2)调度概述
Driver会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务
一个Spark应用程序包括Job、Stage以及Task三个概念
Spark的任务调度分为Stage级的调度,以及Task级的调度
Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG
DAGScheduler负责Stage级的调度,TaskScheduler负责Task级的调度
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver
(3)Stage 级
从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交
(4)Task级调度
调度方式
Task的调度是由TaskScheduler来完成
TaskSetManager 负责监控管理同一个 Stage 中的 Tasks
调度策略
一种是 FIFO(TaskSetManager),也是默认的调度策略,另一 种是 FAIR。
FAIR 模式中有一个 rootPool 和多个子 Pool,各个子 Pool 中存储着所有待分配 的 TaskSetMagager,公平的排序算法
通过 minShare 和 weight 这两个参数控制比较过程,可以做到 让 minShare 使用率和权重使用率少(实际运行 task 比例较少)的先运行。
本地化调度
根据task位置,确定locality本地化存放级别(task和数据分别在什么位置):进程、节点、机架等【task优先位置与其对应的partition对应的优先位置一致】
失败重试与黑名单机制
TaskSetManager知道Task的失败与成功状态,未超过最大重试次数,放回待调度的Task池子
黑名单:记录task失败时的Executor Id 和 Host
6、Shuffle机制
(1)ShuffleMapStage (结束对应写磁盘)与 ResultStage(结束对应job结束)
Shuffle 操作时,map 端的 task 个数和 partition 个数一致,即 map task 为 N 个
(2)HashShuffle
优化前:写到内存缓冲区,满后溢写到磁盘
spark.shuffle. consolidateFiles开启优化
优化后:shuffleFileGroup 会对应一批磁盘文件,task会复用,合并磁盘文件
(3)SortShuffle
普通运行机制:达到阈值后,根据key排序后merge临时文件,再写入磁盘
小于spark.shuffle.sort. bypassMergeThreshold值(默认200)时,使用bypass运行机制
bypass运行机制:每个task创建一个临时磁盘文件,无需排序,根据key的hash值写入磁盘
7、内存管理
(1)内存规划
堆内:申请释放
堆外:工作节点内存中开辟空间,配置offHeap启用,用于存储序列化后的数据
(2)空间分配
静态分配:启动前配置、运行期固定
统一内存管理:存储和执行共享同一块空间,并可动态占用
(3)存储内存管理
持久化机制(storge模块)
RDD缓存与展开
淘汰与落盘
(4)执行内存管理
Shuffle Write:多种排序
Shuffle Read:聚合
8、作业提交
(1)提交方式
使用Shell脚本进行提交-bin/spark-submit
或
使用Scala编程提交打印结果
(2)重要参数
executor-cores —每个executor使用的内核数,默认为1,建议2-5个
num-executors —启动executors的数量,默认为2
executor-memory —executor内存大小,默认1G
driver-cores — driver使用内核数,默认为1
driver-memory —driver内存大小,默认512M
(3)提交示例
spark-submit \
—master local[5] \
—driver-cores 2 \
—driver-memory 8g \
—executor-cores 4 \
—num-executors 10 \
—executor-memory 8g \
—class PackageName.ClassName XXXX.jar \
—name “Spark Job Name” \
InputPath \
OutputPath
9、作业提交流程
(1)Yarn-client模式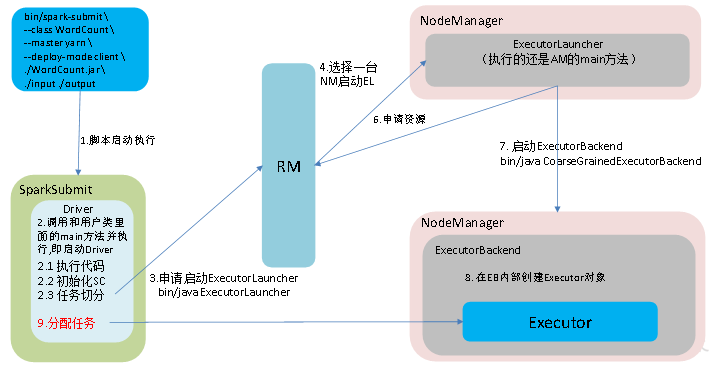
(2)Yarn Cluster模式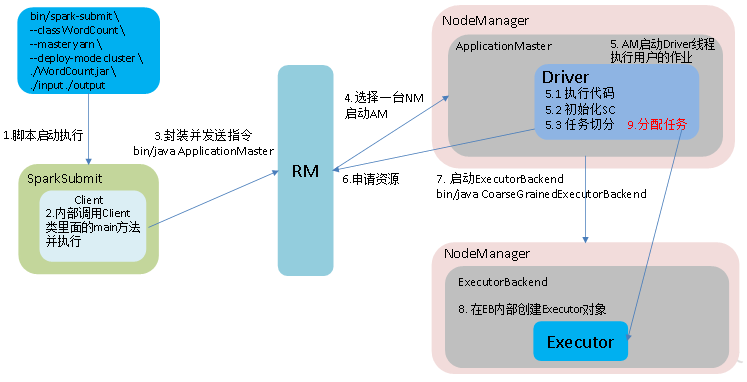
11、Repartition和Coalesce
(1)关系
用来改变RDD的partition数量,repartition底层调用的就是coalesce方法:coalesce (numPartitions, shuffle = true)
(2)区别
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
12、共享变量(累加器和广播变量)
(1)共享变量:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,使用驱动器程序中定义的变量,集群中每个任务都会得到这些变量的一份副本,更新这些副本的值也不会影响驱动器中的对应变量。【类似于外部表】
(2)累加器(accumulator)
多个节点共同操作,但只有Driver可以读取累加器的值
是Spark中提供的一种分布式的变量机制,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
包括系统累加器和自定义累加器
sc.longAccumulator(“sum1”)
(3)广播变量
用来高效分发较大的只读对象,例如sc.broadcast(list)
每个均拷贝一份
13、减少数据库连接数
使用foreachPartition代替foreach,在foreachPartition内获取数据库的连接
二、Spark Core-RDD
1、RDD概念
(1)概念
RDD:弹性分布数据集
只有调用action/collect才会执行RDD计算,即延迟计算
(2)特性
分区(是并行计算的粒度)、计算逻辑(分区计算函数)、依赖关系(RDD流水线的转换)
2、RDD编程
(1)创建
集合中创建:parallelize和makeRDD
外部存储系统的数据集创建:textFile,如本地,或hdfs即hdfs://hadoop102:9000/input
其他RDD创建:
(2)分区:按照CPU核数
自定义分区方式:
从集合中创建:sc.makeRDD(Array(1, 2, 3, 4), 3)
从文件中读取后创建:val rdd: RDD[String] = sc.textFile(“input/3.txt”,3)
3、Transformation转换算子
Value类型、双Value类型和Key-Value类型
(1)Value类型
map映射(一次处理一个元素)
mapPartitions()以分区为单位执行(一次处理一个分区)
mapPartitionsWithIndexindex, item()处理完后带分区号,形成元组
flatMap()压平(多个集合数据放入一个大的集合)
glom()分区转换数组(将一个分区的数据变为一个数组)【例如求最大值:rdd.glom.map(.max)】
groupBy()分组(参数是分组条件,如%2,或groupBy(t=>t._1))
filter()过滤(参数是过滤条件)
sample()采样(按概率传参,选择放回或不放回抽样)
distinct(n)去重,并设置去重操作的分区数(去重后修改分区个数)
coalesce(n)重新设置分区(可选是否使用shuffle),shuffle即数据打乱重组【库尔莱sei】
repartition()重新分区(使用shuffle),实际上调用的是coalesce
sortBy()排序,参数为排序规则,修改第二个参数为false则为降序,缺省为升序
pipe(“/opt/module/spark/pipe.sh”)调用脚本,将脚本作用于RDD上
(2)双Value类型交互【两个RDD的操作】
A.union(B)并集
A.subtract (B)差集
A.intersection(B)交集
zip()拉链,两个RDD组合到一起形成一个(k,v)RDD,一个作为k,一个作为v
(3)key-value类型:用在key-value类型的 RDD 上
partitionBy(分区器)按照K重新分区,内部可以传递分区器,如HashPartitioner或自定义分区器
reduceByKey(参数)按照K聚合V,如相同k的进行相加,可以写成(x,y) => x+y
groupByKey()按照K重新分组,相同k的值进行分组
aggregateByKey()多个参数,分别按照K处理分区内和分区间的逻辑,如aggregateByKey(0)(math.max(, ), + )为取出每个分区相同key对应值的最大值,然后相加
foldByKey()分区内和分区间相同的aggregateByKey()【汇总合计,例如取每个分区的最大值并相加】
combineByKey()相同K,把V合并成一个集合。
sortByKey(T/F)按照K进行排序
mapValues()只对V进行操作,如参数传递_ + “|||”
join()连接,相同key对应的多个value关联,将value变成集合,如 rdd.join(rdd1).
cogroup() 类似全连接,在同一个RDD中对key聚合,同一k的多个v分别位于不同的集合
4、Action行为算子
reduce()聚合,例如reduce(+)
collect()以数组形式返回,
count()返回元素个数
first()返回第一个元素
take(n):返回前n个元素构成的数组,如val takeResult: Array[Int] = rdd.take(2)
takeOrdered(n)返回该RDD排序后前n个元素组成的数组
aggregate(初始值)(分区内逻辑,分区间的逻辑),例如val result: Int = rdd.aggregate(10)( + , + )
fold()折叠操作,即分区内和分区间的逻辑相同,是aggregate的简化,例如元素相加可以写成rdd.fold(0)(+)
countByKey()统计每种key的个数,返回map,如val result: collection.Map[Int, Long] = rdd.countByKey()
save相关的算子:saveAsTextFile、saveAsSequenceFile、saveAsObjectFile
foreach()遍历RDD的每个元素
5、RDD依赖关系
(1)概念
RDD之间的关系也被称为“血统”,或Lineage,可以用于恢复丢失的分区
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies用来解决数据容错时的高效性以及划分任务时候起到重要作用。
(2)操作
查看血缘关系println(fileRDD.toDebugString)
查看依赖关系:fileRDD.dependencies,包含一对一、shuffle
(3)分类
窄依赖:一个父RDD的Partition最多被子RDD的一个Partition使用
宽依赖:一个RDD可能传递到多个RDD,引起shuffle,能够引起shuffle的算子主要包括:reduceBykey、groupByKey、…ByKey
(4)job调度与执行图任务划分
程序运行在驱动节点, 发送指令到执行器节点。启动一个 SparkContext 的时候, 就开启了一个 Spark 应用,针对每个action,Spark 调度器就创建一个执行图
任务划分:中间分为:Application、Job、Stage和Task(最后一个RDD的分区个数),每一层都是1对n的关系,可以通过http://localhost:4040/jobs/查看
(5)Stage
根据RDD依赖关系将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
(6)Task
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
6、reduceByKey与groupByKey区别
reduceByKey:按key聚合,shuffle之前combine(预聚合),返回结果是RDD[k,v]。
groupByKey:按key分组,直接进行shuffle。
建议使用reduceByKey,不影响业务逻辑即可
7、缓存与检查点机制
(1)共同点:均做RDD持久化
(2)cache
基于内存,不会截断血缘关系,使用计算过程中的结果缓存至内存
(3)checkpoint
checkpoint:RDD中间结果写入磁盘,截断血缘关系。ck前必须没有任何任务提交才会生效,ck过程会额外提交一次任务。
二、Spark SQL
1、概述
(1)介绍
将Spark SQL转换成RDD,提交到集群执行【hive】
并提供2个编程抽象:DataFrame&DataSet
(2)特点
整合SQL和spark
统一的数据访问方式
兼容hive,可以直接运行SQL或hql
标准数据连接JDBC/ODBC
2、RDD、DataFrame、DataSet比较
(1)RDD
编译器类型安全(检查错误)
集群间通信与IO需要序列化与反序列化,带来性能开销
(2)DataFrame
每行结构存在schema中
以RDD为基础,每一列都带有名称和类型
序列化和反序列化时无需考虑结构部分
懒执行,但通过查询计划优化(先过滤后join)【基于关系代数的等价变换】,能获得高性能
(3)DataSet
与off-heap进行交互,按需访问数据,无需反序列化整个对象
(4)转换
3、查询起始点
老版本有两种:SQLContext 和 HiveContext
SparkSession是Spark最新的SQL查询起始点
SparkSession内部封装了sparkContext,实际上是由sparkContext完成计算
4、DataFrame
(1)创建DataFrame
数据源、json、其他RDD转换【spark.read.xxx】
(2)SQL风格语法
SQL查询并显示:
val sqlDF = spark.sql(“SELECT * FROM people”)
sqlDF.show
(3)DSL风格语法
特定领域语言(domain-specific language, DSL)
查看DataFrame的Schema信息:df.printSchema
查看某一列或所有列:
df.select(“name”).show()
df.select(“*”).show
df.select($”name”,$”age” + 1).show —涉及运算,列名用$
(4)与RDD转换为DataFrame
df.rdd
toDF(“name”,”age”).show
5、DataSet
(1)创建
Seq(1,2,3,4,5,6).toDS
(2)转换
peopleRDD.toDS
dS.rdd
ds.toDF
6、用户自定义函数
(1)UDF:输入一行,返回一个结果
//注册UDF,功能为在数据前添加字符串
spark.udf.register(“addName”,(x:String)=> “Name:”+x)
(2)UDAF(User Defined Aggregate Function)用户自定义聚合函数:输入多行,返回一行【用户自定义聚合函数】
需求:求平均年龄
RDD算子方式实现:makeRDD.map.reduce
自定义累加器方式实现
自定义聚合函数实现-弱类型:临时视图使用自定义函数查询
自定义聚合函数实现-强类型
(3)UDTF:输入一行,返回多行
用flatMap即可实现该功能
7、数据加载与保存
(1)通用方式
加载数据
spark.read.加载
format加载指定数据类型:spark.read.format(“json”).load
文件上反引号直接查询:spark.sql(“select * from json./opt/module/ spark-local/people.json“).show
保存数据
write直接保存
指定保存数据类型:df.write.mode(“append/覆盖/忽略”).json(“/opt/module /spark-local/output”)
修改数据源
默认:Parquet列式存储
配置项spark.sql.sources.default,可修改默认数据源格式
(2)json文件
自动推测JSON数据集的结构,并将它加载为一个Dataset[Row].
peopleDF.createOrReplaceTempView(“people”)
val teenagerNamesDF = spark.sql(“SELECT name FROM people WHERE age BETWEEN 13 AND 19”)
teenagerNamesDF.show()
(3)MySQL
通过JDBC读写数据
可以选择通用load/write.format方法或jdbc方法
(4)Hive
使用内嵌hive:直接使用spark.sql(“show tables”).show
使用外部hive:配置、启动
运行Spark SQL CLI,执行bin/spark-sql
代码中操作hive
6、append和overwrite
append在原有分区上进行追加
overwrite在原有分区上进行全量刷新
7、coalesce和repartition
(1)共同点
用于改变分区
(2)区别
coalesce用于缩小分区且不会进行shuffle,通过减少分区来减少文件个数
repartition用于增大分区(提供并行度)会进行shuffle
8、cache缓存级别
DataFrame的cache默认采用 MEMORY_AND_DISK
RDD cache 默认采用MEMORY_ONLY
9、缓存及释放
缓存:(1)dataFrame.cache (2)sparkSession.catalog.cacheTable(“tableName”)
释放缓存:(1)dataFrame.unpersist (2)sparkSession.catalog.uncacheTable(“tableName”)
10、shuffle并行度
由参数spark.sql.shuffle.partitions 决定
默认并行度200
11、kryo序列化
(1)介绍
比java序列化更快更紧凑
(2)RDD
spark默认的序列化是java序列化,因为spark并不支持所有序列化类型,每次使用都必须进行注册。
(3)DataFrames和DataSet
自动实现了kryo序列化,无需注册。
12、创建临时表
(1)普通临时表
DataFrame.createTempView(“people”) —session范围内有效
(2)全局临时表
DataFrame.createGlobalTempView()
DataFrame.createOrReplaceTempView()
13、BroadCast 广播join
(1)原理
将小表数据查询出来聚合到driver端,再广播到各个executor端,使表与表join时
进行本地join,避免进行网络传输产生shuffle。
(2)使用场景
大表join小表 只能广播小表
14、注册UDF函数
SparkSession.udf.register 方法进行注册
15、join与left join
(1)join
join和sql中的inner join操作很相似,返回结果是前面一个集合和后面一个集合中匹配成功的,过滤掉关联不上的。
(2)left join
left join类似于SQL中的左外关联left outer join,返回结果以第一个RDD为主,关联不上的记录为空。
(3)left semi join
部分场景下可以使用left semi join替代left join:
left semi join遇到右表重复记录,左表会跳过,性能更高,而left join 则会一直遍历。
但是left semi join中select的结果中只出现左表列名,因为右表只有 join key 参与关联计算
三、Spark Streaming
1、概述
(1)介绍
对大量数据源的流式处理(在线+实时),使用spark算子进行运算
实质:流式数据通过批处理间隔,汇总到一定量后进行操作
使用了离散化流(discretized stream)称为DStreams,是由RDD组成的数据序列
(2)特点
易用、容错、易整合到Spark体系
微量批处理、延迟高
2、架构
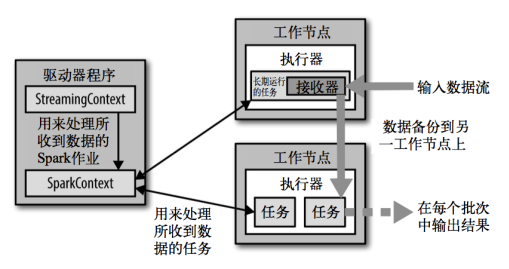 输入后备份数据到另一节点,并通过sparkcontext在另一个节点上处理并输出节点
输入后备份数据到另一节点,并通过sparkcontext在另一个节点上处理并输出节点
3、背压机制
spark.streaming.receiver.maxRate可以限制接收速率,但会导致资源利用率下降
使用背压机制(即Spark Streaming Backpressure)可以根据作业执行信息动态调整数据Receiver接收率
spark.streaming.backpressure.enabled配置背压机制是否开启
接收速率与开启配置同时使用
4、DStream入门
(1)介绍
DStream是持续性的数据流和经过各种Spark算子操作后的结果数据流
内部是一系列连续的RDD
(2)案例:实时wordcount
netcat向9999端口发送数据,spark接收
val socketDS: DStream[String] = ssc.socketTextStream读取broker指定端口
flatMap(.split(“ “)).map((,1)).reduceByKey(+).print()
(3)StreamingContext重用
停止StreamingContext时不让SparkContext停止
应该用:stop(false)
5、DStream创建
(1)RDD队列
val rddQueue = new mutable.QueueRDD[Int]
ssc.queueStream(queueOfRDDs)
每一个RDD都被作为一个DStream
循环放入RDD数据:rddQueue += ssc.sparkContext.makeRDD(1 to 5, 10)
(2)自定义数据源
继承Receiver,并实现onStart、onStop方法,从而自定义数据源采集
实现监控某个端口号,获取该端口号内容
(3)kafka数据源
以Kafka消息创建出 DStream
核心类:KafkaUtils(高级API)、KafkaCluster(低级API)
分别实现wordcount
6、DStream转换
(1)无状态转换-批次内部转化
转化DStream中的每一个RDD
lineDStream.transform(rdd => {… value})
(2)有状态转换
val ssc = new StreamingContext(conf, Seconds(3)):3秒接受一次数据(批次大小)
UpdateStateByKey:历史结果应用到当前批次,更新并保留状态
步骤:定义状态、定义状态更新函数,使用检查点保存状态
Window Operations:计算应用到一个指定的窗口内的所有 RDD
两个参数:窗口时长、滑动步长(批次大小的整数倍,2,1)
其他方法:
7、DStream输出
print()
saveAsTextFiles(prefix, [suffix])
saveAsObjectFiles(prefix, [suffix])
saveAsHadoopFiles(prefix, [suffix])
foreachRDD(func)
8、首次运行不丢数据
通过改变kafka参数
auto.offset.reset参数设置成earliest
从最初始偏移量开始消费数据
9、精准一次消费
(1)手动维护偏移量
(2)处理完业务数据后,再进行提交偏移量操作
极端情况下,如在提交偏移量时断网或停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或精确性非常高的场景会使用事务保证精准一次消费
10、每秒消费的速度
通过spark.streaming.kafka.maxRatePerPartition参数
设置Spark Streaming从kafka分区每秒拉取的条数
11、stage耗时
Spark Streaming stage耗时由最慢的task决定,所以数据倾斜时某个task运行慢会导致整个Spark Streaming都运行非常慢。
12、正常关闭
spark.streaming.stopGracefullyOnShutdown参数设置成ture,Spark会在JVM关闭时正常关闭StreamingContext,而不是立马关闭
关闭命令:
yarn application -kill 后面跟 applicationid
13、默认分区个数
与对接的kafka topic分区个数一致,Spark Streaming一般不会使用repartition算子增大分区,因为repartition会进行shuffle增加耗时
14、消费kafka数据的方式
(1)基于Receiver的方式【借助zk和spark】
Receiver使用Kafka的高层Consumer API实现。
获取的数据存储在Spark Executor内存中(如果突然数据暴增,大量batch堆积,容易出现内存溢出),Spark Streaming启动的job处理那些数据。
要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
(2)基于Direct的方式
在Spark 1.3中引入,能够确保更健壮的机制。这种方式会周期性查询Kafka,获得每个topic+partition的最新offset,定义每个batch的offset的范围。
当处理数据的job启动时,会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点:
简化并行读取:Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。在Kafka partition和RDD partition之间,有一对一的映射关系。
高性能:保证零数据丢失,在基于receiver的方式中(效率低下),需要开启WAL预写日志机制。数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份。而基于direct的方式,不依赖Receiver,只要Kafka复制,就可以通过Kafka的副本进行恢复。
恢复过程通过事务机制控制(一次且仅一次)。
(3)对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
15、窗口函数的原理
在Spark Streaming计算批次大小的基础上再次封装,每次计算多个批次的数据,同时还需要传递一个滑动步长的参数,设置下一次从什么地方开始计算。
四、数据倾斜
1、表现
多条数据集中到某台机器
1)hadoop中的数据倾斜表现:
- 有一个多几个Reduce卡住,卡在99.99%,一直不能结束。
- 各种container报错OOM
- 异常的Reducer读写的数据量极大,至少远远超过其它正常的Reducer
- 伴随着数据倾斜,会出现任务被kill等表现。
2)hive中数据倾斜
一般都发生在Sql中group by和join on上,而且和数据逻辑绑定比较深。
3)Spark中的数据倾斜
Spark中的数据倾斜,包括Spark Streaming和Spark Sql,表现主要有下面几种:
- Executor lost,OOM,Shuffle过程出错;
- Driver OOM;
- 单个Executor执行时间特别久,整体任务卡在某个阶段不能结束;
- 正常运行的任务突然失败;
2、产生原因
以Spark和Hive的使用场景为例
做数据运算的时候会涉及到count distinct、group by、join on等操作,这些都会触发Shuffle动作。一旦触发Shuffle,所有相同key的值就会被拉到一个或几个Reducer节点上,容易发生单点计算问题,导致数据倾斜。
原因有以下几个方面:
1)key分布不均匀;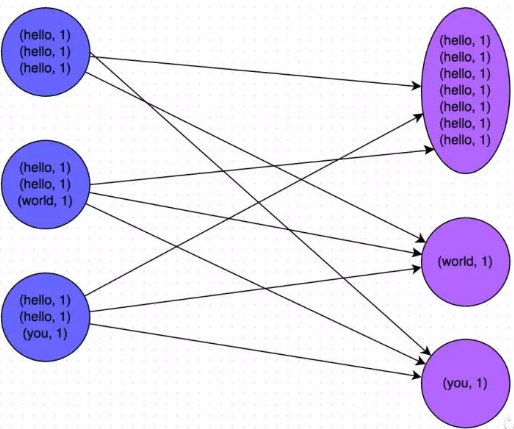
2)建表时考虑不周
我们举一个例子,就说数据默认值的设计吧,假设我们有两张表:
user(用户信息表):userid,register_ip
ip(IP表):ip,register_user_cnt
这可能是两个不同的人开发的数据表。如果我们的数据规范不太完善的话,会出现一种情况:
user表中的register_ip字段,如果获取不到这个信息,我们默认为null;
但是在ip表中,我们在统计这个值的时候,为了方便,我们把获取不到ip的用户,统一认为他们的ip为0。
两边其实都没有错的,但是一旦在做关联的阶段,也就是sql的on阶段卡死。
3)某部分业务数据激增
比如订单场景,我们在某一天在北京和上海两个城市多了强力的推广,结果可能是这两个城市的订单量增长了10000%,其余城市的数据量不变。
然后我们要统计不同城市的订单情况,这样,一做group操作,可能直接就数据倾斜了。
3、解决思路
(1)解决方案一:聚合原数据-避免shuffle、增大key的粒度
(2)解决方案二:过滤导致倾斜的key
(3)解决方案三:提高shuffle操作中的reduce并行度(分散多个key):让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据
(4)解决方案四:使用随机key实现双重聚合:加前缀第一次聚合后,去掉前缀在进行局部聚合
(5)解决方案五:将reduce join转换为map join,采用广播小RDD全量数据+map算子来实现
(6)解决方案六:sample采样对倾斜key单独join到一个单独的RDD,shuffle时会被分散到多个task
(7)解决方案七:使用随机数以及扩容进行join,将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理
4、定位数据倾斜代码
数据倾斜只发生在shuffle过程
触发shuffle操作的算子:
distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
5、Spark数据倾斜的解决方案
(1)使用Hive ETL预处理数据:数据预聚合
(2)过滤少数导致倾斜的key:where子句
(3)提高shuffle操作并行度:将key分配给更多的task
(4)两阶段聚合:先加前缀局部聚合再全局聚合
(5)reduce join转为map join:map可以避免shuffle过程
(6)采样倾斜key拆分join
(7)随机前缀和扩容RDD
(8)多种方案组合
HiveETL预处理和过滤少数导致倾斜的k,预处理一部分数据,并过滤一部分数据来缓解;
其次可以对某些shuffle操作提升并行度,优化其性能;
最后还可以针对不同的聚合或join操作,选择一种方案来优化其性能。
(9)总结
五、实战
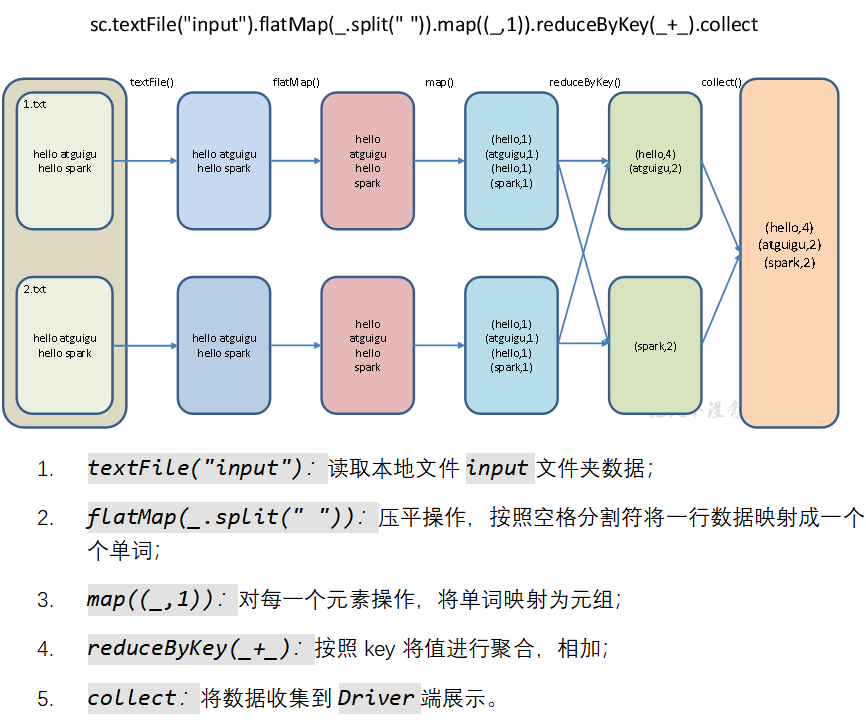
1、wordcount流程
object WordCount {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkConf对象, 并设置 App名字, 并设置为 local 模式
val conf: SparkConf = new SparkConf().setAppName(“WordCount”).setMaster(“local[*]”)
// 2. 创建SparkContext对象
val sc = new SparkContext(conf)
// 3. 使用sc创建RDD并执行相应的transformation和action
val wordAndCount: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource(“words.txt”).getPath)
.flatMap(.split(“ “))
.map((, 1))
.reduceByKey( + )
.collect()
wordAndCount.foreach(println)
// 4. 关闭连接
sc.stop()
}
}
六、调优
1、Spark reduce缓存调优shuffle
spark.reducer.maxSizeInFilght 此参数为reduce task能够拉取多少数据量的一个参数默认48MB,当集群资源足够时,增大此参数可减少reduce拉取数据量的次数,从而达到优化shuffle的效果,一般调大为96MB,资源够大可继续往上跳。
spark.shuffle.file.buffer 此参数为每个shuffle文件输出流的内存缓冲区大小,调大此参数可以减少在创建shuffle文件时进行磁盘搜索和系统调用的次数,默认参数为32k 一般调大为64k。
2、调优前后的性能对比
几百个文件有几百个map,读取之后进行join操作,会非常的慢。
可以进行coalesce操作,比如240个map,我们合成60个map,也就是窄依赖。这样再shuffle,过程产生的文件数会大大减少。提高join的时间性能。
3、常规调优
(1)最优资源配置:Executor数量、Executor内存大小、CPU核心数量&Driver内存
(2)RDD优化:RDD复用、RDD持久化(序列化、副本机制)、尽早地过滤
(3)并行度调节:各个stage的task的数量,应该设置为Spark作业总CPUcore数量的2~3倍
(4)广播大变量:每个Executor保存一个副本。初始只有一个副本,需要则从BlockManager上拉取,此Executor的所有task共用此广播变量,这让变量产生的副本数量大大减少
(5)Kryo序列化:比java的序列化性能高,
(6)调节本地化等待时长:valconf=newSparkConf().set(“spark.locality.wait”,”6”)
4、算子调优
(1)mapPartitions:针对一个分区的数据,建立一个数据库连接(数据量大容易OOM)
(2)foreachPartition优化数据库操作:将RDD的每个分区作为遍历对象,一次处理一整个分区的数据,但可能OOM
(3)filter与coalesce的配合使用:filter操作之后,使用coalesce算子针对每个partition的数据量各不相同的情况,压缩partition的数量,而且让每个partition的数据量尽量均匀紧凑,
(4)repartition解决SparkSQL低并行度问题:使用repartition算子,去重新进行分区,避免了SparkSQL所在的stage只能用少量的task去处理大量数据并执行复杂的算法逻辑
(5)reduceByKey本地聚合:有map端聚合的特性,使得网络传输的数据量减小
5、Shuffle调优
(1)调节map端缓冲区大小:避免频繁的磁盘IO操作
(2)调节reduce端拉取数据缓冲区大小:增加拉取数据缓冲区的大小,可以减少拉取数据的次数
(3)调节reduce端拉取数据重试次数:避免由于JVM的fullgc或者网络不稳定等因素导致的数据拉取失败
(4)调节reduce端拉取数据等待间隔通过加大间隔时长(比如60s),以增加shuffle操作的稳定性。
(5)调节SortShuffle排序操作阈值:参数调大一些,大于shuffle read task的数量,那么此时map-side就不会进行排序,减少性能开销
6、JVM调优
(1)降低cache操作的内存占比:可以通过spark.storage.memoryFraction参数进行指定
(2)调节Executor堆外内存:会避免掉某些JVM OOM的异常问题,同时,可以提升整体Spark作业的性能。
(3)调节连接等待时长↓:GC时,Spark的Executor进程就会停止工作,无法提供相应,此时,由于没有响应,无法建立网络连接,会导致网络连接超时,避免部分的XX文件拉取失败、XX文件lost等报错
7、TroubleShooting
(1)故障排除一:控制reduce端缓冲大小以避免OOM
(2)故障排除二:JVM GC导致的shuffle文件拉取失败,增加重试次数和等待时间
(3)故障排除三:解决各种序列化导致的报错:自定义类等必须可以序列化
(4)故障排除四:解决算子函数返回NULL导致的问题:返回特殊值、filter后调用coalesce算子进行优化
(5)故障排除五:解决YARN-CLIENT模式导致的网卡流量激增问题:YARN-client(测试环境)模式下,Driver启动在本地机器上,而Driver负责所有的任务调度,需要与YARN集群上的多个Executor进行频繁的通信,生产环境下的YARN-cluster模式不会产生
(6)故障排除六:解决YARN-CLUSTER模式的JVM栈内存溢出无法执行问题:增加PermGen的容量,参数设置
(7)故障排除七:解决SparkSQL导致的JVM栈内存溢出:将一条sql语句拆分为多条sql语句来执行
(8)故障排除八:持久化与checkpoint的使用:对这个RDD进行checkpoint,持久化到HDFS上
七、实战
1、各省广告点击top3

(1)RDD实现
//7. 对相同省份中的广告进行排序(降序),取前三名
val mapValuesRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues {
datas => {
datas.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(3)
} }
(2)DStream实现
结构化、聚合、结构转换、分组
dataDS.map{line => {ab_c,1}}
mapDS1.groupByKey()
datas.toList.sortBy(-._2).take(3)
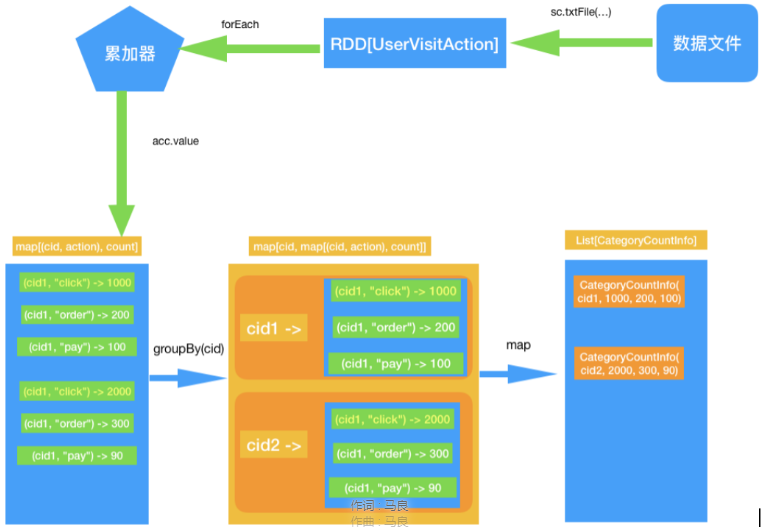
2、Top10品类
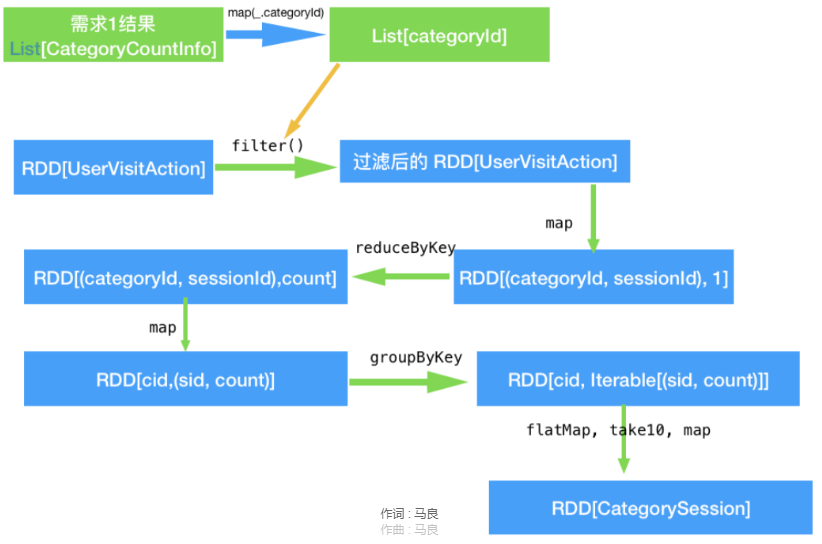
3、Top品类点击排名前10的Id
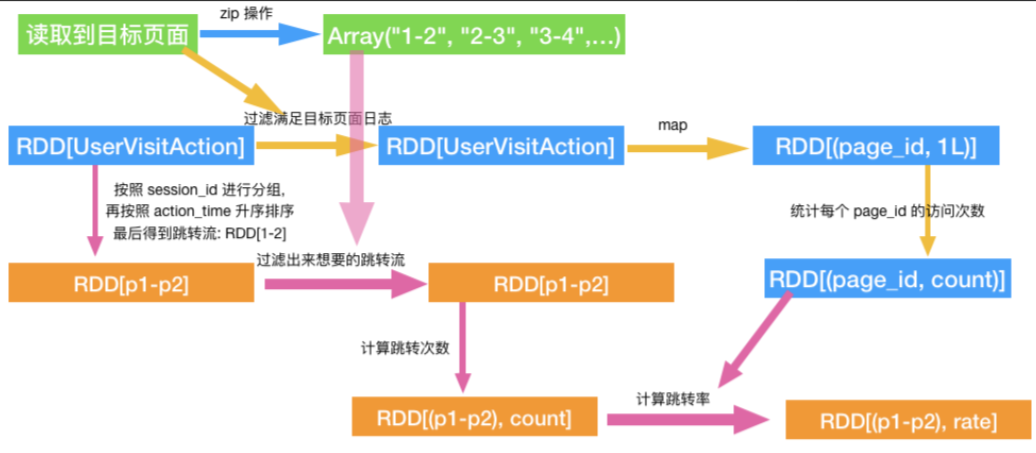
4、单跳转化率
5、TopN的获取
方法1:
(1)按key对数据聚合(groupByKey)
(2)将value转为数组,利用scala的sortBy或者sortWith进行排序,(mapValues)数据量太大会OOM。
方法2:
(1)取出所有key
(2)对key进行迭代,取出key利用spark的排序算子进行排序
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
6、最近一小时点击量
定义窗口,在窗口内聚合
6s更新一次点击量
最近一小时-窗口大小为1小时,滑动步长为6s
dataDS.window(Seconds(12),Seconds(3))
windowDS.map(a, 1)
val resDS: DStream[((String, String), Int)] = mapDS.reduceByKey(+)

若有收获,就点个赞吧
0 人点赞
