这个DSL语句是可以并集交集查询字词,(含有虹桥跟如家的元素都能查询出来)
全文查询
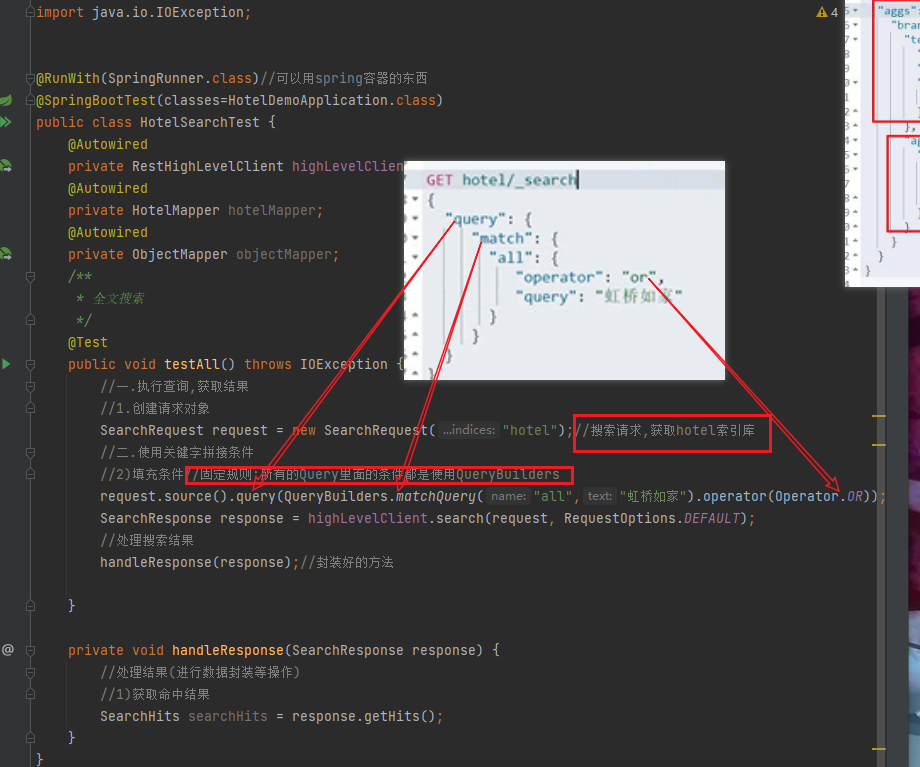
1.第一步先创建请求,搜索需要查询的索引库
2.填充条件,highLevelClient.search(request, RequestOptions.DEFAULT);就是把查询到的数据响应回来(接收响应的数据)
3.获取响应里的数据,数量有多少,然后把获取回来的全部元素转换成对象
4.把对象传回前端
精确搜索
,范围搜索
精确搜索// term查询GET /indexName/_search{"query": {"term": {"FIELD": {#(元素例如品牌)"value": "VALUE"#(如家酒店)}}}}范围搜索// range查询GET /indexName/_search{"query": {"range": {"FIELD": {"gte": 10, // 这里的gte代表大于等于,gt则代表大于"lte": 20 // lte代表小于等于,lt则代表小于}}}}
/**
*精确搜索
*/
@Test
public void TermAndRange() throws IOException {
//创建请求
SearchRequest request = new SearchRequest("hotel");
//填写DSL语句查询圆形方位内的酒店(地理位置搜索)
request.source().query(QueryBuilders.geoBoundingBoxQuery("location").setCorners(new GeoPoint("31.1,121.5"),new GeoPoint("30.9,121.7")));
//精确搜索
//request.source().query(QueryBuilders.termQuery("brand", "如家"));
//给钱就加分语句
request.source()
.query(QueryBuilders
.functionScoreQuery(QueryBuilders.matchQuery("brand", "如家"),
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD", "true"),//functions中的filter部分
ScoreFunctionBuilders.weightFactorFunction(10) // functions中的weight部分
)
}
).boostMode(CombineFunction.SUM));// boost_model部分
//范围搜索
request.source().query(QueryBuilders.rangeQuery("price").gte(200).lte(400));
//需求,搜索名字包含"如家",价格不高于400,在坐标31.21,121.5
周围10km范围内的酒店.
//填写DSL语句
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("name","如家"));
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("price").gte(500));
boolQueryBuilder.filter(QueryBuilders.geoDistanceQuery("location")
.distance("10km").point(new GeoPoint(31.21,121.5)));
request.source().query(boolQueryBuilder);
//地理搜索地址ip排序
//搜索全部
request.source().query(QueryBuilders.matchAllQuery());
//查地理位置然后排序
request.source().sort(SortBuilders
.geoDistanceSort("location"
,new GeoPoint("39.76,116.33")).order(SortOrder.DESC)
.unit(DistanceUnit.KILOMETERS));
//获取距离位置值
Object[] sortValues = hit.getSortValues();
System.out.println(sortValues[0]+"公里");
list.add(hotelDoc);
//写DSl语句
//查询全部
request.source().query(QueryBuilders.matchAllQuery());
//分页
request.source().from(5).size(10);
//填写DSL语句
request.source().query(QueryBuilders.matchAllQuery());
//设置高亮
request.source().highlighter(new HighlightBuilder()
.field("name").preTags("<font color='red'>").postTags("</font>").requireFieldMatch(false));
SearchResponse response = highLevelClient.search(request, RequestOptions.DEFAULT);
//接收响应
SearchResponse response = highLevelClient.search(request, RequestOptions.DEFAULT);
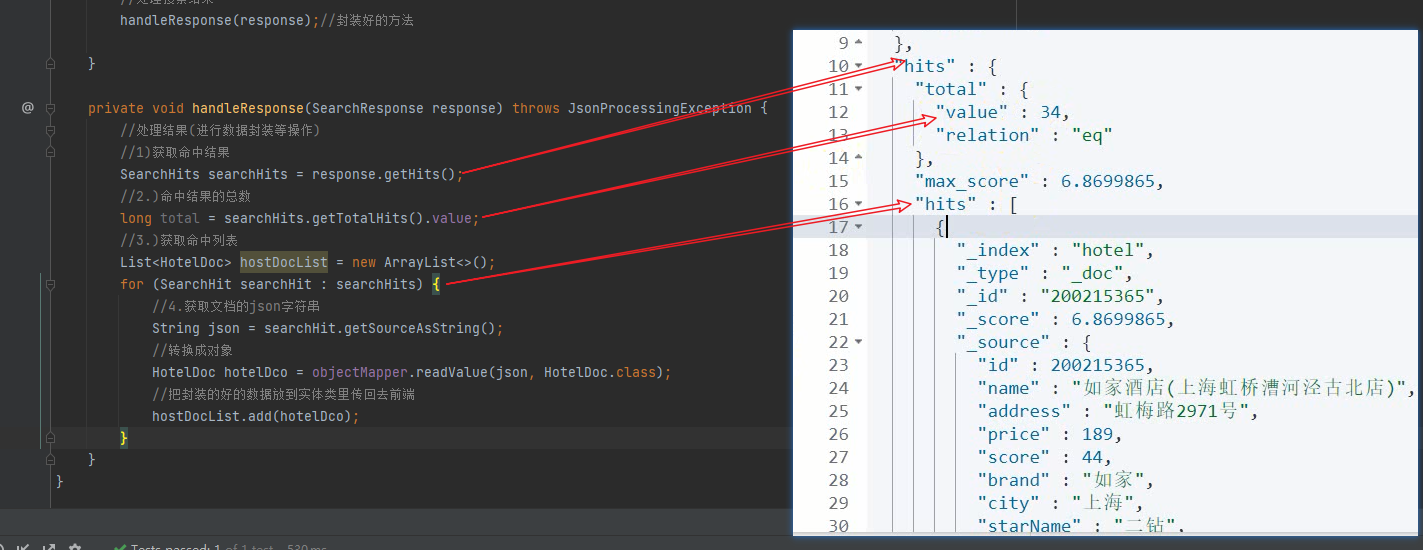
//获取命中数据
SearchHits hits = response.getHits();
List<HotelDoc> list = new ArrayList<>();
for (SearchHit hit : hits) {
//转换成String类型
String json = hit.getSourceAsString();
//转成对象
HotelDoc hotelDoc = objectMapper.readValue(json, HotelDoc.class);
list.add(hotelDoc);
}
list.forEach(System.out::println);
地理位置查询
使用场景
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
DSL语句
矩形范围查询
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
#top_lef左上
#右下bottom_right
#矩形位置查询
GET hotel/_search
{
"query": {
"geo_bounding_box": {
"location":{
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right":{
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
语法说明:
需求,查询以31.21,121.5坐标为圆心,以15km为半径的范围内数据以内的的酒店
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
4)复合查询-算分函数查询
使用场景
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:
TF (词条频率): 描述某一词在一篇文档中出现的频繁程度。 出现越多,分值越高,反之,分值越低。
IDF(逆文档频率): 词条出现的文档数量越多,分值越低,反之,分值越高 。
掏钱加分的方法(算分函数)
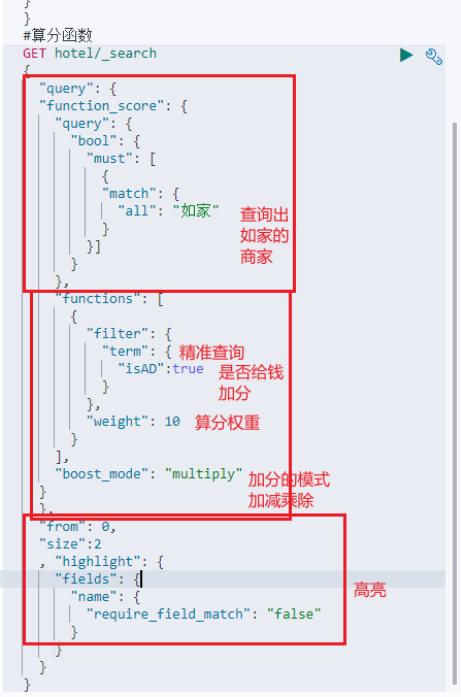
#算分函数
GET hotel/_search
{
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"match": {
"all": "如家"
}
}]
}
},
"functions": [
{
"filter": {
"term": {
"isAD":true
}
},
"weight": 10
}
],
"boost_mode": "multiply"
}
},
"from": 0,
"size":2
, "highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
DLS语句
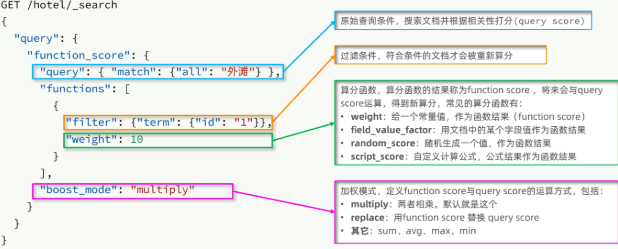
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
需求:给“如家”这个品牌的酒店排名靠前一些
翻译一下这个需求,转换为之前说的四个要点:
- 原始条件:不确定,可以任意变化
- 过滤条件:brand = “如家”
- 算分函数:可以简单粗暴,直接给固定的算分结果,weight
- 运算模式:比如求和
因此最终的DSL语句如下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分权重为2
}
],
"boost_mode": "sum" // 加权模式,求和
}
}
}

5)复合查询-布尔查询
使用场景
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
must:必须匹配每个子查询,类似“与”,(并且and,参与算分)
should:选择性匹配子查询,类似“或”(或or)
must_not:必须不匹配,不参与算分,类似“非”()
filter:必须匹配,不参与算分(并且and,不会加分)

GET hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "如家"
}
}
}
],
"must_not":[
{"range":{"price":{"gte":500}}}
],
"filter":[
{
"geo_distance":{
"distance": "10km",
"location": "31.21,121.5"
}
}
]
}
}
}
05、搜索结果处理(排序,升序,降序)
1)排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。\
普通字段排序
keyword、数值、日期类型排序的语法基本一致。
DSL语法:
#排序
#需求查询如家酒店,按价格倒序显示
GET hotel/_search
{
"query": {
"match": {
"name": "希尔顿"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
#需求,查询指定坐标,按照位置近到远升序排序
GET hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"_geo_distance": {
"location": "39.76,116.33",
"order": "desc",
"unit":"km"
}
}
]
}
2)分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始,从0开始的
size:总共查询几个文档(类似于mysql中的limit ?, ?)
分页DSL
# 需求,每页显示50条 GET hotel/_search { "query": { "match_all": { } }, "from": 5 , "size": 10 }3)高亮显示
高亮DSL:
``` GET /hotel/_search { “query”: { “match”: {//match_all(查询所有)
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询} }, “highlight”: { “fields”: { // 指定要高亮的字段
"FIELD": {//"name" "pre_tags": "<em>", // 用来标记高亮字段的前置标签 "post_tags": "</em>" // 用来标记高亮字段的后置标签 // "require_field_match": "false" }} } }
高亮显示

pre_tags: 显示前缀
post_tags: 显示后缀
fields: 需求高亮的字段名
require_field_match: 现在指定的field名称是否必须要包含在搜索条件中
需求:按照name高亮显示 (只要name中包含关键词,关键词都会进行高亮)
GET hotel/_search { “query”: { “match”: { “name”: “如家” } }, “highlight”: { “pre_tags”: ““, “post_tags”: ““, “fields”: { “name”: { “require_field_match”: “true” } } } } ```

若有收获,就点个赞吧
0 人点赞
