创建模型,为用户提供良好的初始数据集用于提出新问题。
要让非技术人员轻松地询问有关您的数据的问题,您可以做的最有价值的事情就是将您的数据放入一种使提问变得直观的形状。
数据通常很混乱,尤其是对于初创公司。或者甚至不凌乱:它可能非常标准化数据为交易优化,而不是分析。这意味着您可以拥有一个数据库,其中包含分布在大量表中的客户数据,这使得尚不熟悉数据库的人很难找到他们正在寻找的信息(假设他们甚至知道联接如何工作)。
模型作为构建块
为了使您的数据对您的团队更直观,您可以在查询构建器或 SQL 编辑器中提出一个问题,以在 Metabase 中创建派生表,称为模型,可以将来自不同表的数据汇总在一起。您可以添加自定义的计算列,并使用元数据注释所有列,以便人们可以将查询构建器中的数据作为起点。
如果您已经是经验丰富的 Metabaser,您知道您可以从已保存问题的结果. 您可以将模型视为一种特殊类型的已保存问题,但这是卖空它们。
为什么不运行 ETL 作业在数据库中创建模型?
型号和ETL不是相互排斥的。您可以(并且应该)利用两者。只是为了说明原因:
- 模型将用于对数据建模的工具交到了解业务领域的人手中。这是一个大问题。是的,数据工程师会更多地了解数据管道中的管道,但他们不一定知道特定团队面临的问题以及应该如何定义这些问题的各个部分(例如,什么是活跃用户? )。您组织中的各个团队应该定义您的业务,并且他们应该能够根据团队工作方式、新产品供应、市场变化等方面的变化来改进这些定义。使用模型,人们不必通过数据团队来添加新的计算列或更新定义。那个和不同的团队会有不同的定义:你的销售团队可能有不同的客户模型,而不是你的营销或成功团队。
- 模型很灵活。您可以即时创建模型、修改它们、切换它们——它们基本上只是查询+描述。他们是元数据库中的一等公民,所以你可以将他们组织成收藏品,链接到它们,然后选择它们作为新问题的起点,或将它们添加到仪表板。您还可以将它们存档,或将它们更改回已保存的问题(尽管您会丢失元数据)。相比之下,ETL 的工作量要大得多,而且通常由了解您的数据管道、知道如何编写代码、安排工作等的人来管理。有一些很棒的工具可以帮助您编写 ETL,但对于需要灵活解决方案的问题,它们通常是重量级的解决方案。
- 模型是提高数据库性能的垫脚石。在 Metabase 中试验模型后,您可以将最流行的模型“提升”为数据库中的物化视图。这里的物化意味着编写一个 ETL 作业来创建并定期更新数据库中与您的模型匹配的表(具有相同的列集),以便每次运行时都不需要为查询计算结果;数据库可以像从原始数据表中一样获取结果。在数据库中实现表后,您可以使用简单的方法替换 Metabase 中模型的原始查询SELECT * FROM materialized_model,或者只是删除模型并像对待数据库中的任何其他表一样对待物化表。(请注意,如果您更改模型的基础查询,则需要更新每列的元数据)。
模型示例
在考虑要在模型中包含哪些列时,最好先列出您希望人们提出的问题类型,然后在模型中添加有助于回答这些问题的列。假设我们要为客户建模。通常,我们可能想要定义一个活跃客户,也许是在过去一个月中至少访问过我们网站一次的人,或者我们想要定义活跃客户。但为了简单起见,我们将使用 Metabase 中包含的示例数据库为基本客户定义一个模型。我们预计希望了解有关我们客户的一些信息:
- 他们居住的地方,包括州和邮编。
- 他们的来源(他们是如何发现我们的)。
- 他们在我们身上花了多少钱。
- 他们下了多少订单。
- 每个订单的平均总数。
在现实生活模型中,您可能有更多想要回答的问题,这需要更多列来回答(例如客户的年龄、他们在网站上花费了多长时间、添加的项目以及从购物车中删除,或您认为您的团队想要提出问题的所有其他数据点)。模型的想法是获取所有样板代码,将所有这些数据集中在一起,这样人们就可以开始使用他们真正感兴趣的数据。
所以这是我们的问题,使用查询构建器构建:
图 1。笔记本编辑器中的查询。
对于我们的数据,我们选择了Orders表格,将其加入People表格,汇总订单总额,计算行数,并使用自定义表达式计算平均订单总额= Sum([Total]) / Count:接下来我们按以下方式分组:User_ID、People.Created_At、State、Zip和Source。
我们保存那个问题,点击问题标题调出问题侧边栏(您可能需要刷新浏览器),然后点击模型图标(三角形堆叠的三个构建块)将问题变成模型。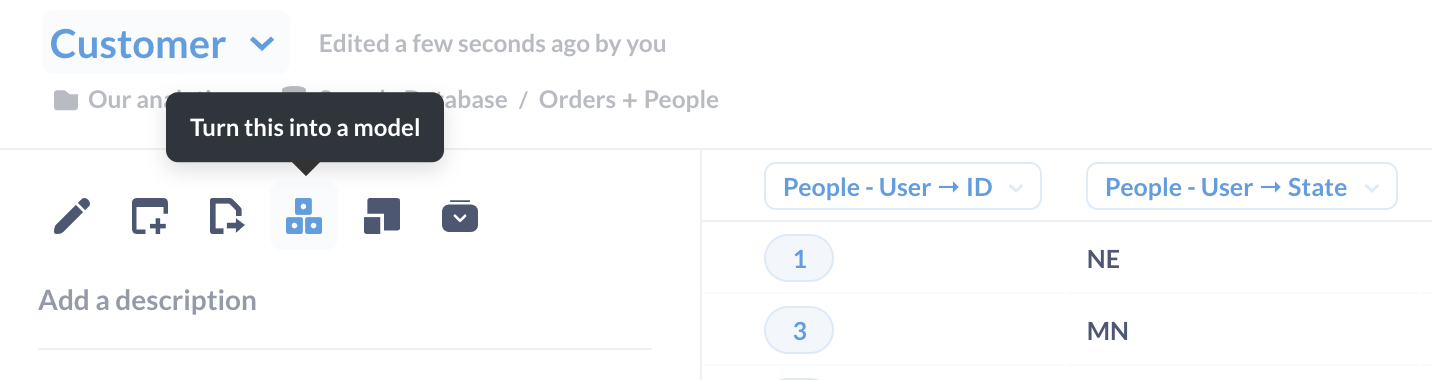
图 2。将问题转化为模型。
向模型添加元数据是关键
这是模型的超能力,对于使用 SQL 查询构建的模型特别有用,因为 Metabase 不知道 SQL 查询返回的列类型。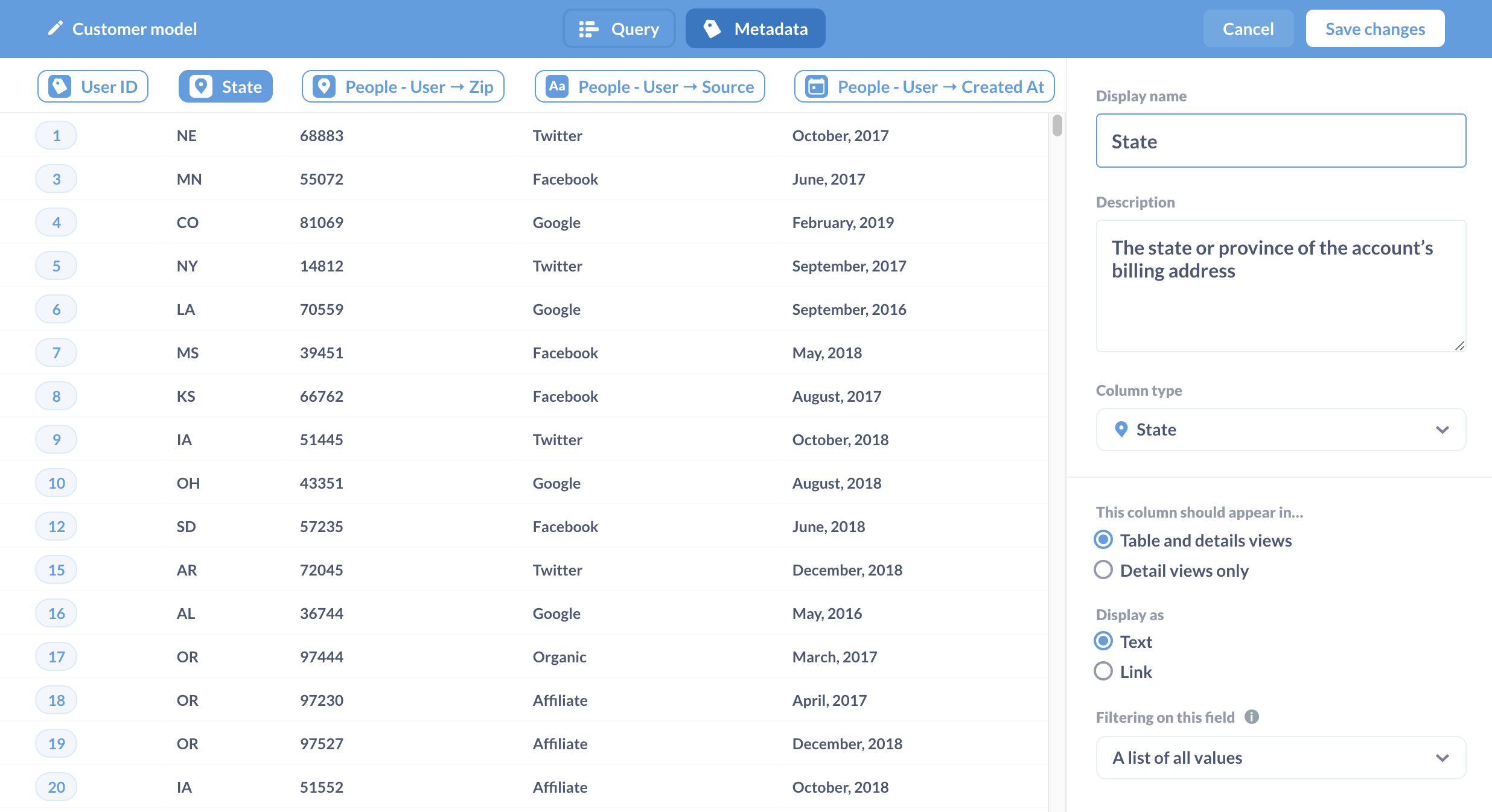
图 3。重命名列、添加描述并为每列设置元数据。
单击模型的名称将弹出模型侧边栏,这为我们提供了自定义元数据的选项。在这里,我们可以给列提供更友好的名称,为列添加描述(将在悬停时显示),并告诉 Metabase 该列包含什么类型的数据。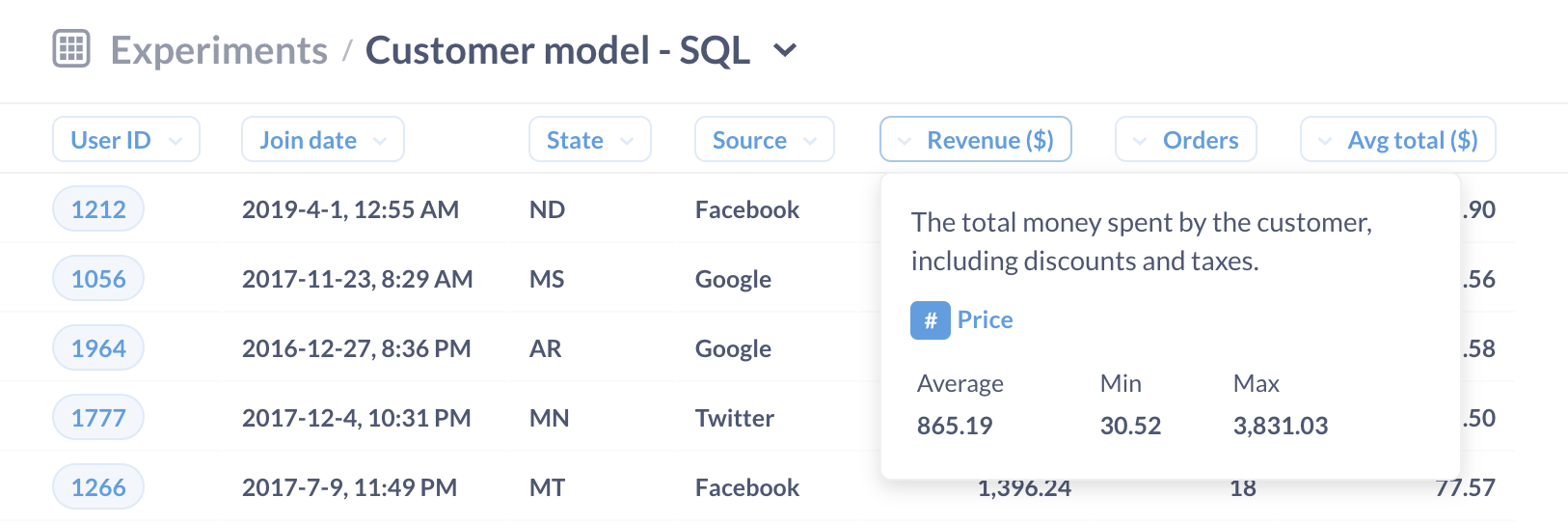
图 4。将鼠标悬停在列上将触发带有列描述的弹出窗口。
如果我们改为使用 SQL 查询来创建相同的客户模型(请参阅模型示例上),像这样:
SELECTorders.user_id AS id,people.created_at AS join_date,people.state AS state,people.source AS source,Sum(orders.total) AS total,Count(*) AS order_count,Sum(orders.total)/Count(*) AS avg_totalFROM ordersLEFT JOIN peopleON orders.user_id = people.idGROUP BYid,city,state,zip,source
在我们进入并告诉 Metabase 结果中的每一列是什么类型的数据之前,Metabase 将无法发挥其通常的魔力。因此,请务必为每列设置类型,以便 Metabase 能够在图表上显示操作菜单,并知道它应该为该列使用哪种过滤器(例如,数字过滤器对于数字的选项与,比如说,一个日期或一个类别)。
跳过 SQL 变量
这是一个值得一提的微妙点。如果您习惯于使用保存的问题和 SQL 变量(如字段过滤器)创建“模型”,以便人们可以接受这些问题并将它们连接到仪表板过滤器,那么模型在这里采用不同的方法。模型不适用于变量,因为它们不需要。一旦您告诉 Metabase 模型的列类型,您就可以从该模型开始一个问题,保存它,并能够将它连接到仪表板过滤器。无需在 SQL 代码中放置变量。
如果您将模型添加到仪表板,您会注意到无法将其任何列映射到仪表板过滤器,即使您已为这些过滤器设置了类型。要使用模型获得相同的结果,您可以:
- 创建一个没有变量的模型。
- 根据模型保存问题。
- 将该问题添加到仪表板。
- 向仪表板添加过滤器
- 将过滤器映射到问题的相应列。
有关更多信息,请参阅仪表板过滤器.
进一步阅读
查看我们的文档以了解如何创建和管理模型.

若有收获,就点个赞吧
0 人点赞
