使用redis的场景
高并发(redis支持更高并发,缓解数据库压力)、高性能(结果放入缓存,查询更快)、redis锁。
Redis为什么这么快
- 基于内存的操作
- 用多路复用IO来处理客户端请求,避免线程上下文切换
-
数据类型
底层数据结构
redis的数据结构有:SDS、链表、字典、跳表、整数集合、压缩列表,这里讲下重要的一些数据结构。
SDS
数据结构
free(空闲大小)、len(使用大小)、指向字符串缓冲区的指针
和C语言字符串的对比
c字符串需要遍历才能知道长度,sds有len属性,可以直接获取
- sds扩容会先比较free是否足够,不够的话,自动扩容,可以避免缓冲区溢出
- sds扩容,可以不必每次都创建新字符串,扩容是会利用空闲的空间。
- c字符串以空字符作为结尾,不能存图片、文本等,sds有len属性,二进制安全。
链表
redis中的链表数据结构是双向链表。字典
redis中的字典是包含了两个哈希表的,一个存数据,一个是扩容用的,redis的哈希表也是用链地址法来解决哈希冲突的,然后有个比较重要的特点,redis的字典是用渐进式扩容的来扩容的,也就是达到一定条件就扩容一部分,这样可以避免数据量太大,一次扩容耗费太多时间。跳表
原来一个有序链表,我们查询一个节点需要遍历才能找到,跳表就是优化这种查询的。我们对有序链表的一些节点进行拔高,建立一层层的索引链表,然后查询某个节点的时候,先在顶层的索引链表查询,然后在符合的区间内进行下沉,这样就可以利用索引加快查询。
这里有个问题是,哪些节点进行拔高,拔高多少层?在redis中的实现很简单,每次创建一个节点的时候,随机一个0~31的数,是多少就拔高多少层。数据类型和数据结构对应关系
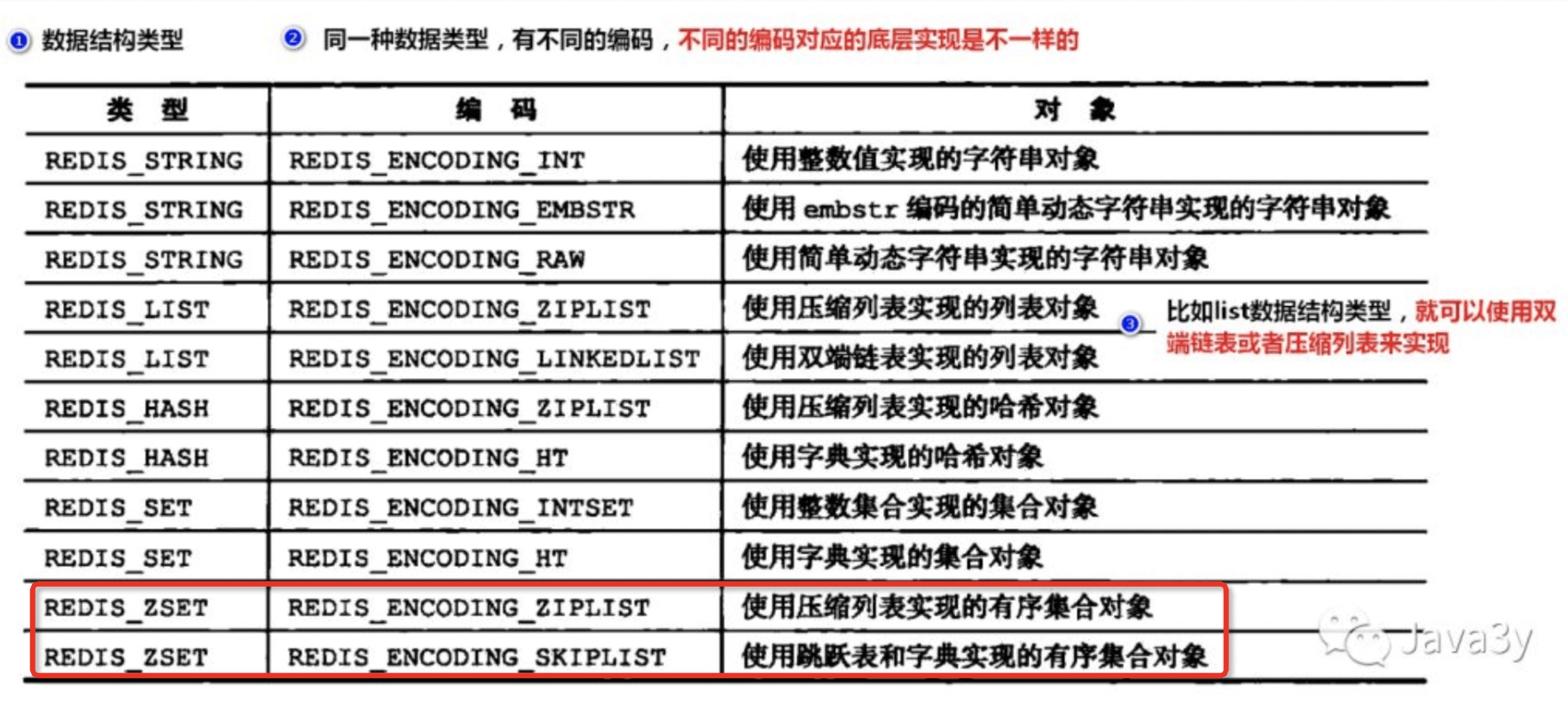
这里关注一下Zset就好了,Zset有两种编码,一种使用压缩列表实现的,一种是用字典+跳表组合实现的。那为什么要用字典+跳表的组合呢?
因为字典按值查询时,我们根据hash计算O(1)的复杂度就能找到元素,但范围查询字典表现就很差;而跳表按值查询O(logN)但复杂度,但范围查询快,所以综合了这两种数据结构。过期策略
Redis中就算key过期了,也不一定会立刻删除这个key,Redis中是通过惰性删除+定期删除两种过期策略结合的。
惰性删除是指,key过期了并不会被删除,而是在后面又用到这个key的时候,才把他删除。
定期删除是,每隔100ms,删除一部分过期的key。内存淘汰机制
内存是有限的,所以redis肯定需要内存淘汰机制,我们一般用的就是LRU,也就是淘汰最近最少使用的key。
持久化方案
Redis是支持数据持久化的,不然的话服务重启了,数据就丢失了,有两种持久化方案:AOF和RDB。
| 持久化方案 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| AOF | 存储的是写命令 | 丢失数据少(默认配置只丢失一秒的数据) | 重启恢复慢 |
| RDB | 存储的是数据库某一时刻的快照状态 | 丢失数据多(在定时持久化执行之前的数据都会丢失) | 重启恢复快 |
这两种方式可以一起用,如果一起用,恢复时以AOF为准,因为数据更全。
RDB的两种方式
- SAVE命令。SAVE命令会阻塞Redis服务器进程,服务器不能接收任何请求,直到RDB文件创建完毕为止。
BGSAVE命令。BGSAVE命令会创建出一个子进程,由子进程来负责创建RDB文件,服务器进程可以继续接收请求。
AOF写入步骤
写命令写入AOF缓冲区,然后写线程就可以返回了,保证了写入效率;
- 后台定时任务把缓冲区内容刷到pagecache;
-
AOF重写
AOF一直追加写命令,会使得文件很大,但其实很多写命令是可以去掉了的,例如往一个list中add多个元素,其实用一个写命令就可以搞定,这时候就会用到AOF重写。
AOF重写是基于当前数据库状态来写的,写到一个新的AOF文件中,但是由于需要处理这段时间新的写命令,所以需要一个AOF重写缓冲区来记录,最后会把这个缓冲区的数据也写到写的AOF文件中。Redis主从架构
redis主从架构支持更高的并发量,以及读的高可用。master只写,salve只读。
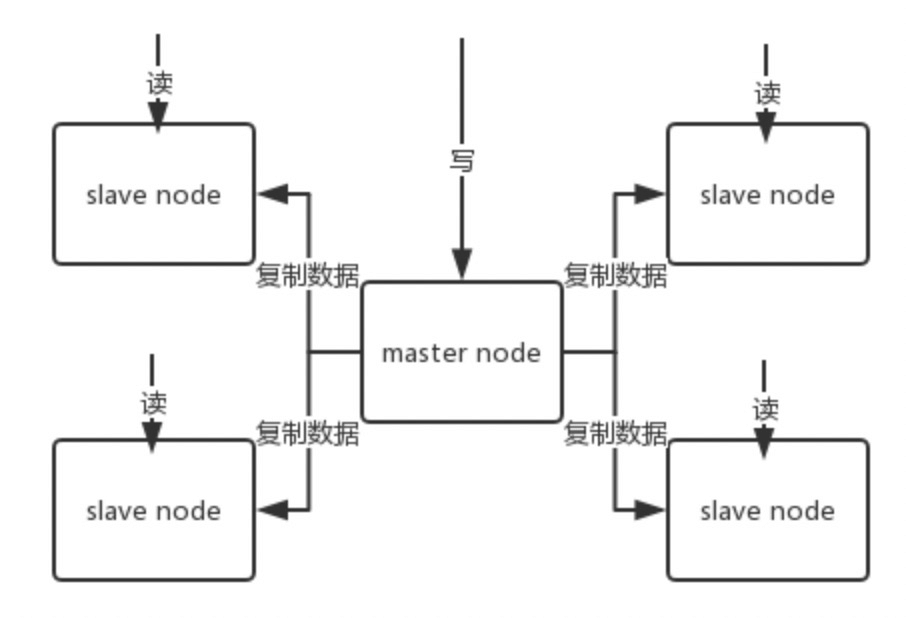
主从复制
主从复制分为两个步骤:
同步。
同步分为两种:对于服务刚启动,会进行全量的同步,后面重启会进行,部分同步。全量同步和部分同步的区别就是同步的数据量不同,部分同步只同步salve和master缺失的部分(实现原理就是根据记录的偏移量进行同步)。
- 命令传播
同步完成之后,就会进行命令传播,也就是master写命令之后,会把写命令在传播给salve,salve进行写操作。
主从复制的时候,对于过期key的处理是这样的:master过期淘汰了某个key,那么会模拟一条del命令,在传播给salve,salve进行del删除操作。
哨兵机制
主从架构中,salve挂了,可以从别的salve中读,实现了读的高可用。但如果master挂了,那整个集群就不能写入了,所以才有了哨兵模式,哨兵模式的redis集群,实现了写的高可用。哨兵机制中,主要要关注master挂了之后,怎么去实现主备切换的。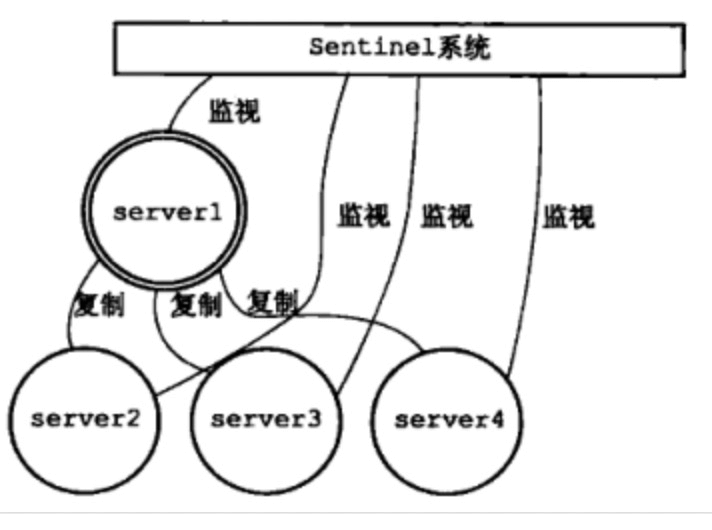
主备切换
原理:哨兵集群中的每台哨兵,会和其他的哨兵以及主从redis实例维持连接,当发现master挂了,那么就会在哨兵集群内选出一个领导者,然后进行主备切换,把某台salve提升为master。
具体步骤如下:
- 哨兵和其他实例都用ping-pong进行心跳连接,如果发现master不返回pong,那么这台哨兵就主观认为master下线了,如果哨兵集群中超过半数的都认为master下线了,那么master就是客观下线。
- 当哨兵集群觉得客观下线了,那么会在哨兵集群中选出一个领导者进行主备切换,这里如何选出领导者呢?每台主观认为master下线的哨兵,都向集群中其他哨兵发送消息,要求选举他为领导者,如果集群中超过半数的都选了这台哨兵,那么他就是领导者。(如果没选出,重新进行新一轮投票)
哨兵领导者会选一台salve,把他设为新的master,其他salve复制新的master的数据,然后原来的master上线之后,自动成为salve。
主备切换数据丢失问题
如果数据写到master,还没有同步到salve就挂了,那么这部分数据在salve上是没有的,这时候进行主备切换,数据就丢失了;
因为脑裂问题导致数据丢失。master因为网络原因和哨兵连接断开了,但其实master还存活的,这时候客户端的写命令还是写到了master上,但哨兵认为他挂了,选举了新的master,旧的master后面会成为新的master的salve,同步新的master的数据,那么这期间客户端写到旧的master上的数据就丢失了。
集群
哨兵机制的redis集群只支持一个master,这样写能力还是没有提高,所以有了redis集群。
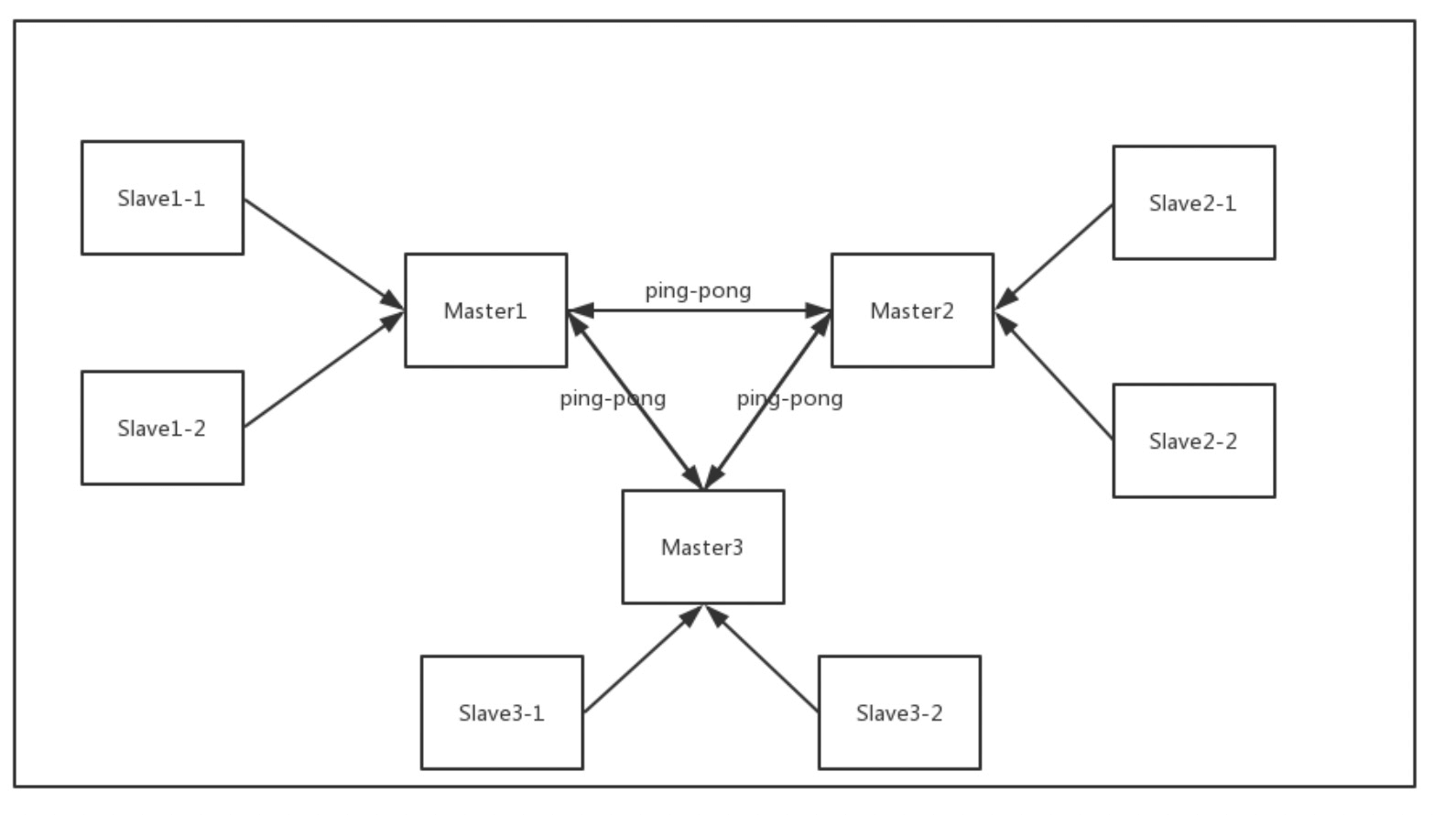
分片设计
集群模式中,整个集群的master会瓜分2个槽点,如果槽点有缺失集群就是不可用的,然后客户端请求过来,某台redis实例会进行取模计算,如果是本实例就自己处理,如果不是,返回客户端一个错误命令,里面会包含正确的实例的IP、槽点信息,然后客户端再发起请求。
如果集群进行扩容等操作,那么就是重新分配槽点,并把槽点对应的数据进行迁移。主从切换
集群模式中没有哨兵的概念,集群中的master之间会一直维护着心跳连接,当某个master没有收到另一个master A的心跳返回,就主观认为A下线了;
- 如果集群中超过半数的master都主观认为A下线了,那么A就是客观下线,那么会有一个master向集群所有节点广播下线的消息;
A的每一台salve收到A下线的消息之后,就会向其他master发送消息,要求选举他为新的master,当超过半数的master选举这个salve为新的master之后,那么就选举成功,成为了新的master,如果没有成功,需要进行新一轮投票。
集群和哨兵主从切换的区别
哨兵机制中哨兵做集群的监控,集群模式中主节点自己做监控
- 哨兵机制是选出一个领头的哨兵去进行主从切换,集群模式是master投票选出一台salve成为新的主节点
三种集群方案的对比
| 架构方案 | 特点 | | —- | —- | | 主从架构 | 实现了读的高可用和读的高并发;但master挂了集群不能写入。 | | 哨兵机制 | 在主从架构的基础上,实现了读的高可用和读的高并发,通过主从切换实现了写的高可用。 | | 集群 | 在主从架构的基础上,实现了读的高可用和读的高并发,通过数据分片存储,实现了写的高并发,通过主从切换实现了写的高可用。 |
缓冲雪崩
缓存雪崩是说,同一时刻缓存都过期了,或者 Redis 服务整个挂了,导致查询压力都直接到了 MySQL,MySQL 处理不了这么多的并发量,导致数据库崩溃。
解决方案
- 同一时刻大量缓存过期
在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。 - Redis 挂了
事前:用 主从+哨兵,或 Redis 集群的架构方式设计,实现高可用,避免 Redis 服务挂掉;
事中:万一 Redis 真的挂了,用本地缓存或限流降级的方式,减少数据库并发压力;
事后:Redis 持久化,重启 Redis 恢复之前缓存的数据。缓冲穿透
访问一个数据库中不存在的数据,这样永远也不会被放入缓存,如果大量这种请求也会让数据库崩溃。解决方案
- 就算数据库中没有这个数据,也把他放入缓存,一般设置个较短的过期时间。
- 用布隆过滤器来判断查询的数据是否一定不存在,不存在的话就不用查询了。
如果恶意攻击查询很多不存在的key,那第一种方案都放入redis也不合适,这种情况选布隆过滤器;如果相反都情况,用第一种方案。
布隆过滤器
布隆过滤器就是一个大的二进制数组,数据库的数据,通过多次hash的方式放在这个数组中,放进去了相应的位置就是1。
当我们查询一个数据在数据库有没有的时候,就对查询的key进行多次hash,然后看在数组中是不是都是1,只要有一个是0,就说明数据不存在。
布隆过滤器能确定一定不存在,但不能确定是否存在。因为即使都是1,也可能不存在的。当数组不够大,hash次数太多,都可能让数组都是1,这样就失去意义了,误判率很高。但如果数组太大,那占用空间很大,如果hash次数少,那误判率高。
缓存击穿
缓存击穿是说,当一个key失效时,正好有大量都请求去访问这个key,那这时这些请求可能都判断缓存中没有,就都去数据库查询了,造成了数据库的压力。
解决方案
这种情况就只会在并发量巨大的时候会出现,我们可以在查询数据库的时候进行一个加锁的保护,这样只有一个线程去访问了数据库,别的后面都能从缓存中获取到。
加锁是在缓存中没取到,到db中取之前加锁的
Object obj = redis.get(key);if(obj!=null)return obj;else{tryLock(){//查询db,并放入缓存//返回结果}}
但上面这种方案相当于串行化了去db查询的请求,试想一下,如果有很大的并发量,请求都判断缓存中没有,那么所有的请求都需要一个个的去db中查询,性能极差。
可以用下面这种方案进行优化,简单来说就是,获取到锁的请求去db查询并放入缓存,其他没有获取到的锁请求不断尝试从缓存中获取。
if(tryLock()){//查询db,并放入缓存//返回结果}else{//不断尝试从redis中获取,取到了返回,没取到线程等待10ms然后再尝试while(true){Object obj = redis.get(key);if(obj!=null)return obj;Thread.sleep(10);}}
缓存和数据库双写一致性
首先一般是采用更新数据库,删缓存的操作,而不是更新缓存,原因有二:
- 更新缓存需要考虑更多的情况,比如并发,更加复杂;
- 可能缓存更新了多次,但都没有查询,那频繁更新这个缓存浪费了,不如直接删除,在下次查询到的时候再写入缓存。
先删缓存再更新数据库存在的问题
并发情况下,A先删缓存,还未更新数据库,此时B过来查询,发现缓存中没有,就把数据库中的旧值写到缓存,这样就造成缓存和数据库中数据不一致的问题。
一般推荐,先更新数据库再删缓存,这种情况出现问题的概率很低。
但先更新数据再删缓存可能存在:更新数据库成功,缓存删除失败的情况。这时候在缓存失效之前,获取的数据就是脏数据。

若有收获,就点个赞吧
0 人点赞
