RPC本质
抛开Dubbo不讲,最简单的一个RPC其实就是:
- consumer端根据IP、port用Netty客户端发出请求,请求数据中带有调用的接口名;
- provider端收到请求后,根据接口名,找到接口实现类,执行业务处理;
- provider处理完之后,把结果响应回consumer,这样就完成了RPC的一次调用。
但是只是这样肯定不行,存在很多问题,比如怎么感知provider?调用超时、失败怎么办?代码侵入太大怎么办?所以Dubbo的话,我认为在这个的基础上,有了代理、服务注册发现、容错处理、负载均衡等等。
服务注册发现机制
provider
provider启动之后会进行spring配置的解析,然后发起服务暴露,这时候provider主要做两件事:
- 启动Netty服务端,监听客户端(consumer)的请求;
- 向注册中心注册自己的服务,在zk上创建节点,并和注册中心维持心跳连接。
provider服务注册实现方式,就是在zk上创建节点,节点中包含了服务的元信息,包括IP、端口、接口名、版本号等等。
consumer
consumer启动之后也会进行Spring配置的解析,然后发起服务引用,这时候consumer主要做两件事:
- 启动Netty客户端,后面发起RPC调用的时候用;
- 向注册中心注册自己的服务,并订阅节点信息,当节点发生变化时,会通知consumer,consumer再拉取最新当节点信息;
consumer会在本地对节点信息做一个副本,调用时走副本,并有一个定时任务去获取最新的节点信息。
容错机制
Dubbo默认的容错机制是fail-over 失败重试,因为有重试所以我们需要考虑处理幂等的情况,所以fail-over适合读的场景或provider方实现了幂等。
- fail-fast 快速失败,失败后就返回异常,适合写的场景。
- fail-safe 失败安全,就算调用失败也不会抛异常,适合记日志一些不重要的业务。
此外还有像fork(调用多个有一个成功就可以),广播(都成功才可以)等。
协议
序列化
线程派发策略
| 策略 | 用途 |
|---|---|
| all | 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件等,默认 |
| direct | 所有消息都不派发到线程池,全部在 IO 线程上直接执行 |
| message | 只有请求和响应消息派发到线程池,其它消息均在 IO 线程上执行 |
| execution | 只有请求消息派发到线程池,不含响应。其它消息均在 IO 线程上执行 |
| connection | 在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池 |
线程池
| 线程池类型 | 说明 |
|---|---|
| fixed | 固定大小线程池,默认线程数200,启动时建立,不会关闭,一直存在 |
| cached | 缓存线程池,空闲一分钟自动删除,需要时重建 |
| limited | 可伸缩线程池,但只会扩大不会缩小。这么做的目的是避免收缩的时候来大流量带来性能问题 |
| eager | 优先创建 worker 线程池。任务数大于 corePoolSize 小于 maxPoolSize,创建 worker 处理,线程数大于 maxPoolSize ,任务放入阻塞队列,阻塞队列满了走拒绝策略。 |
负载均衡
- 随机加权负载均衡
- 加权轮询负载均衡
- 最小活跃数负载均衡
对于调用的活跃数的检测统计是基于过滤器实现的,每次调用(不管调用是否成功)都会调用次数自增。
- 一致性hash负载均衡
把provider的IP等信息hash计算之后放在一个环(TreeMap)上,然后对于consumer的请求,对请求的信息做hash之后在环上顺时针的找最近的provider,找到的就是要调用的provider。这种方式可以让同一个consumer的请求一直调用在同一台provider上。
此外为了防止环上分配不均的问题,dubbo采用了虚拟节点的方式来解决。
SPI
SPI的作用
通过策略模式来提高扩展性。大概使用姿势是这样的:
- 在配置文件中META-INF,用接口的全限定名作为文件名,文件内容写接口实现类的全限定名;
- 调用
ServiceLoader.load(接口.class)方法就会去加载配置文件,然后用反射的方式(Class.forName)实例化实现类。
大概梳理一下,SPI也就是提供了功能的接口,但具体实现自己扩展,而如何扩展呢?就是通过策略模式,在接口名的配置文件中配置实现类,通过反射的方式加载实现类。
Dubbo SPI的实现原理
@SPI
@adaptive
注解在接口方法上,会用javasist根据参数自动生成一个类,然后在使用的时候,生成的类会根据参数URL选择不用的实现类去处理(实现类会在配置文件中配置)。
注解在实现类上,不会生成类,调用loader.getAdaptiveExtension()会返回这个类。
利用@adaptive注解,可以在程序运行时,根据传入参数的不同,动态选择不用的实现类处理
@activate
通常获取扩展实现只能获取到一个实现类,但例如拦截器等场景通常需要我们可以扩展一系列的功能,而 @activate 注解就是为了这种场景而生的。@activate 可以注解在很多实现类上,然后通过 group 或 value 在URL参数中自动激活不同的多个实现类。
和JDK SPI的区别
Dubbo SPI的原理的话,我觉得跟JDK SPI也没什么区别,但是Dubbo SPI功能会更强大一点,具体来说,以下几点:
- Java SPI 每次都会把所有实现类都加载并实例化(是在迭代器迭代的时候创建实例),而 Dubbo SPI 是分两段创建实例,先进行类加载,然后在使用到具体实现的时候才实例化,并且 Dubbo SPI 大量使用缓存,会把 Class 对象和实例对象都缓存起来,性能更好;
- Java SPI 在类加载失败的时候难以定位异常;
- Dubbo SPI 还支持 IOC 和 AOP 。
IOC SPI实现原理
遍历方法 setXXX(class),如果有这种方法的就去进行注入,注入有两种方式:IOC和Spring,IOC从配置文件中找,Spring从Bean容器中找。AOP SPI实现原理
Dubbo在解析配置文件中的每行配置信息时,会判断这行配置对应类的构造方法的传入参数类型,是不是扩展接口,如果是的话就把这行配置对应的类放入缓存,然后后面创建实例的时候,会遍历缓存,通过构造方法传参的方式,对扩展类进行了包装。
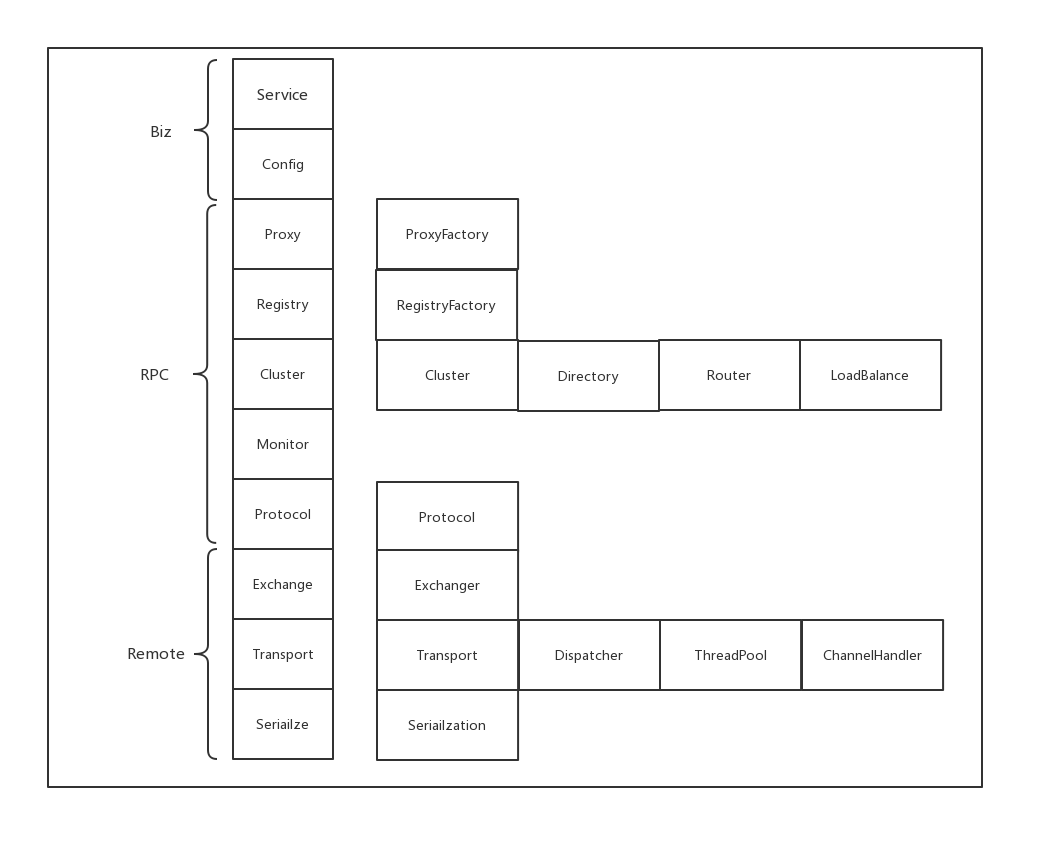
这样后面在调用这个扩展类的时候,先进行包装类的处理,然后在进行扩展类的处理,实现了AOP。十层架构

若有收获,就点个赞吧
0 人点赞
