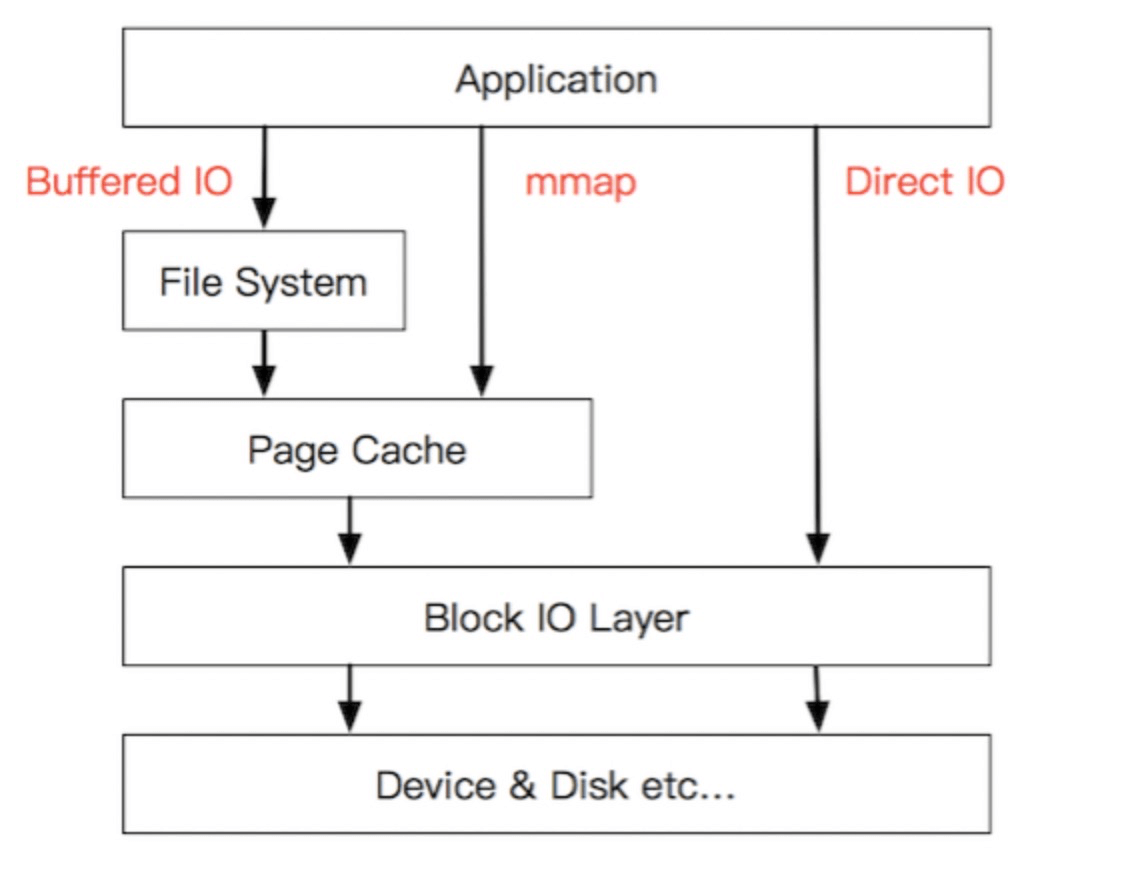
Buffer IO和Direct IO
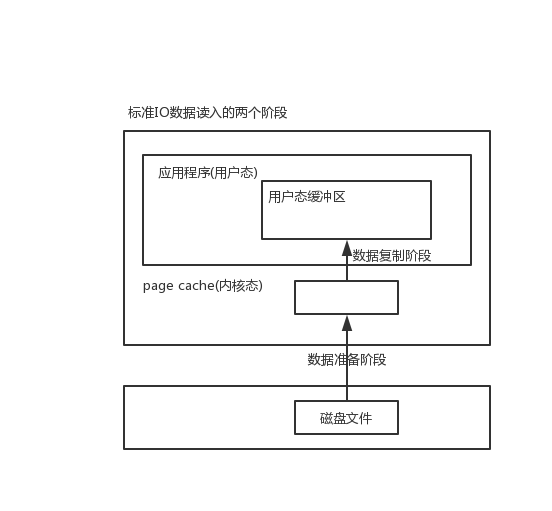
- buffer IO 也就是标准 IO。数据读写会利用 page cache,读先读到内核态的 page cache,然后在从内核态复制到用户态的缓冲区中;写的话用户态缓冲区写到 page cache,就算完成了,操作系统会把 page cache 中的脏页写到磁盘文件中。在Java中,就是磁盘->page cache(堆外内存)->堆内内存。
- direct IO 不经过 page cache,直接读写磁盘文件,这样没有了 page cache 的拷贝,但page cache的功能也丢失了,这种方式使用很少,Java 中的 DirectByteBuffer 并不是 DirectIO。
Buffer IO充分利用了操作系统page cache的预读功能,在读数据的时候,预读块数据,增快后面的读数据效率;在写数据的时候,应用程序写到page cache就可以返回,减少写磁盘的时间。
5种IO模型
前面说了标准 IO,需要把磁盘数据复制到内核态(DMA 和网络 socket),然后再从内核态复制到用户态。这两个阶段的不同处理方式就有了 5 种 IO 模型。
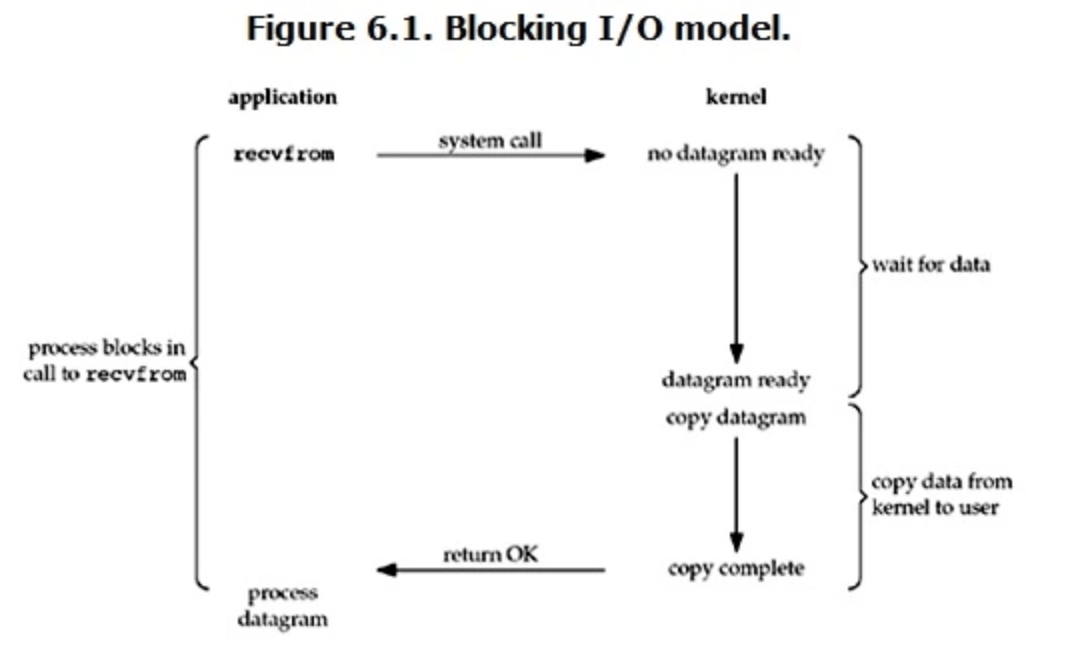
阻塞IO
- Linux 默认的就是阻塞 IO;
- 这种方式在数据准备和内核态复制到用户态这两个阶段都是阻塞的。
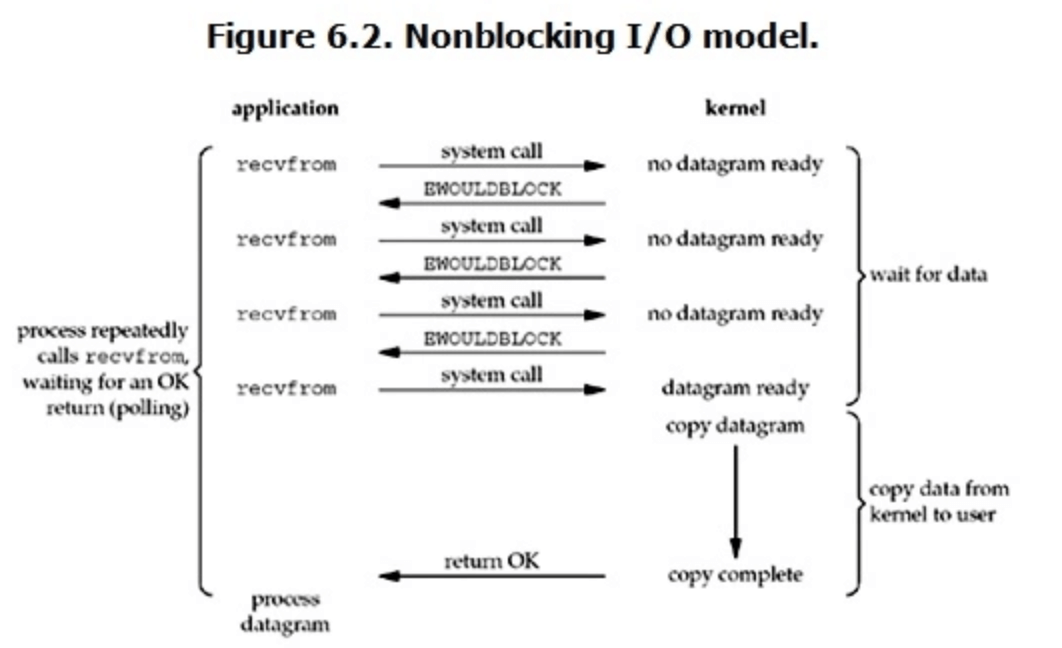
非阻塞IO
- 设置 socket 参数为 non-blocking,就是非阻塞 IO 了;
- 用户线程发起非阻塞 IO 之后,不管数据有没有准备好,都立即返回,在数据准备阶段是非阻塞的;
- 一般用户线程需要不断去询问数据是否准备好了,如果准备好了,那就进入数据拷贝阶段,这阶段还是阻塞的。
多路复用IO
- 多路复用 IO 就是调用 select()/poll/epoll() 函数,这些函数最大的特点就是可以实现一个线程监听多个连接;
- 线程执行了 select() 等函数之后,就阻塞了,当 select() 上注册的连接,有连接准备好了数据, select() 函数就会返回,这样就可以获取到那些数据准备好了的连接。所以其实在数据准备阶段也是阻塞的;
- 获取到数据准备好的连接之后,我们就可以进入拷贝阶段了,这阶段也是阻塞的;
- 多路复用 IO 整体上都是阻塞的,但和阻塞 IO 最大的区别就是,调用 select() 等函数之后,我们可以一个线程监听多个连接。
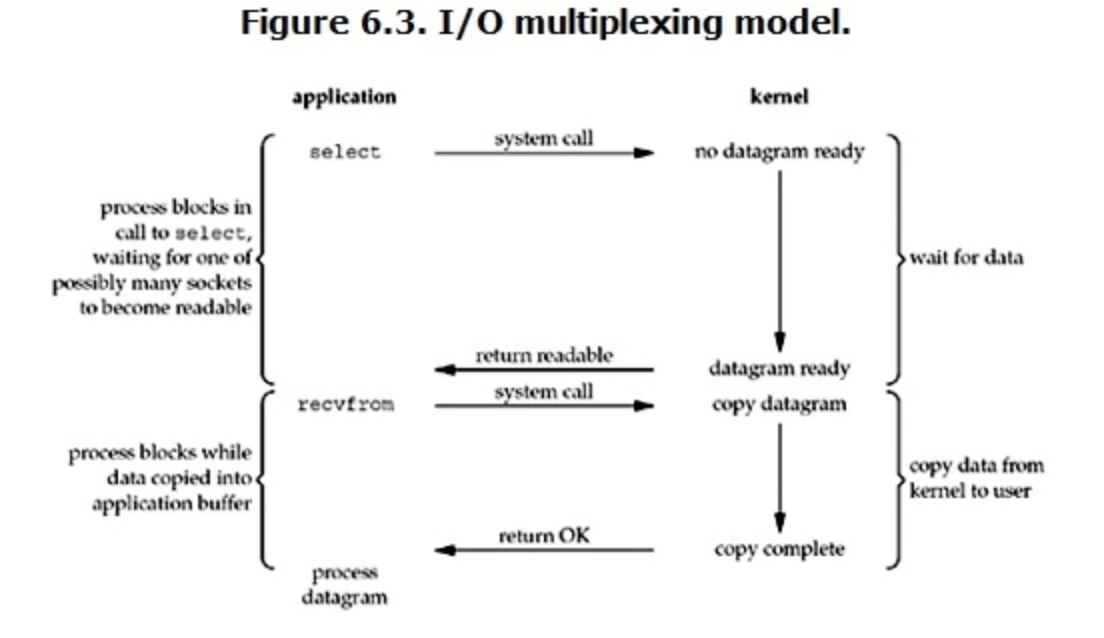
select、poll、epoll
- select() 连接数有最大描述符限制,且获取数据准备好的连接时,需要遍历所有注册的连接;
- poll() 连接数没有最大描述符限制,也需要遍历所有注册的连接来获取数据准备好的连接;
- epoll() 连接数没有最大描述符限制,采用通知的方式获取数据准备好的连接。因此在大量连接数的情况下,前两者遍历消耗性能更多,epoll() 更适合。
信号驱动IO
用的很少。异步IO
两个阶段都是非阻塞的,现在还不成熟。同步异步/阻塞非阻塞
阻塞/非阻塞:两个阶段线程都阻塞,才是阻塞,只要有一个阶段不是阻塞的就是非阻塞。阻塞 IO 是阻塞的,其他都是非阻塞的。
同步/异步:两个阶段都不阻塞,才是异步,只要有一个阶段是阻塞的,就是同步。异步 IO 是异步的,其他的都是同步的。Java NIO
Java 中实现了 阻塞 IO(BIO)、多路复用 IO(NIO)、异步 IO(AIO)。
Java NIO 中的三个组件:selector 多路复用器、channel 管道、buffer 缓冲区。buffer
buffer 就是用户态的缓冲区,就是一个内存块。channel
socket = 连接 = channel。channel 可以双向读写。selector
一般把 channel 注册在 selector 上,然后调用 selector.select() ,线程就阻塞了,如果注册在上面的连接有数据准备好了的,原本阻塞的线程就可以接着往下走,进行数据拷贝等操作。反应器模式
selector 只是实现了一个线程监听多个连接,如果我们真的只是用一个线程去实现,数据复制还是在这个线程去处理,那性能是很差的,因此就有了反应器模式实现的多路复用 IO。
用一个线程去监听连接,当有连接数据准备好了,监听线程把后续的处理交给别的线程去完成数据拷贝。零拷贝
磁盘文件发送出去的场景,其实并不需要在用户态和内核态来回去拷贝(只需要从磁盘到网卡),零拷贝就是没有这种拷贝的优化机制。零拷贝有两种实现方式:sendfile() 和 mmap()。Java中读数据BIO、NIO两种主要方式都是通过:磁盘->内核态(page Cache)->用户态的堆外内存->堆内内存。DiectBuffer是在堆内持有堆外内存的引用,减少了堆外到堆内的数据拷贝,也是零拷贝的一种。 为什么不是直接从page Cache到堆内内存?因为堆内受GC管理,内存地址经常变化。
sendfile()
sendfile() 对应的 Java API 就是 Channel.transferTo() 。
实现原理:可以把内核态缓冲区的数据指定目的,然后直接复制过去。
例如:把磁盘文件发送到网络上的场景,先把磁盘文件复制到内核态的缓冲区,然后调用sendfile(),可以直接从内核态复制到网卡,发送到网络。
但这种方式不能修改数据。
mmap()
mmap() 对应的 Java API 就是 MappedByteBuffer。
实现原理:在用户态空间中指定一块虚拟空间,映射了磁盘文件,然后应用程序在用户态操作虚拟地址,计算机通过内存管理 MMU,把用户态的虚拟地址映射到内核态的真实物理地址(page cache),这时候如果内核态中 page cache 数据还没加载,就会把磁盘文件读到内核态,然后进行相应的操作。
这种方式可以不把文件复制到用户态,而通过虚拟映射的方式实现操作文件。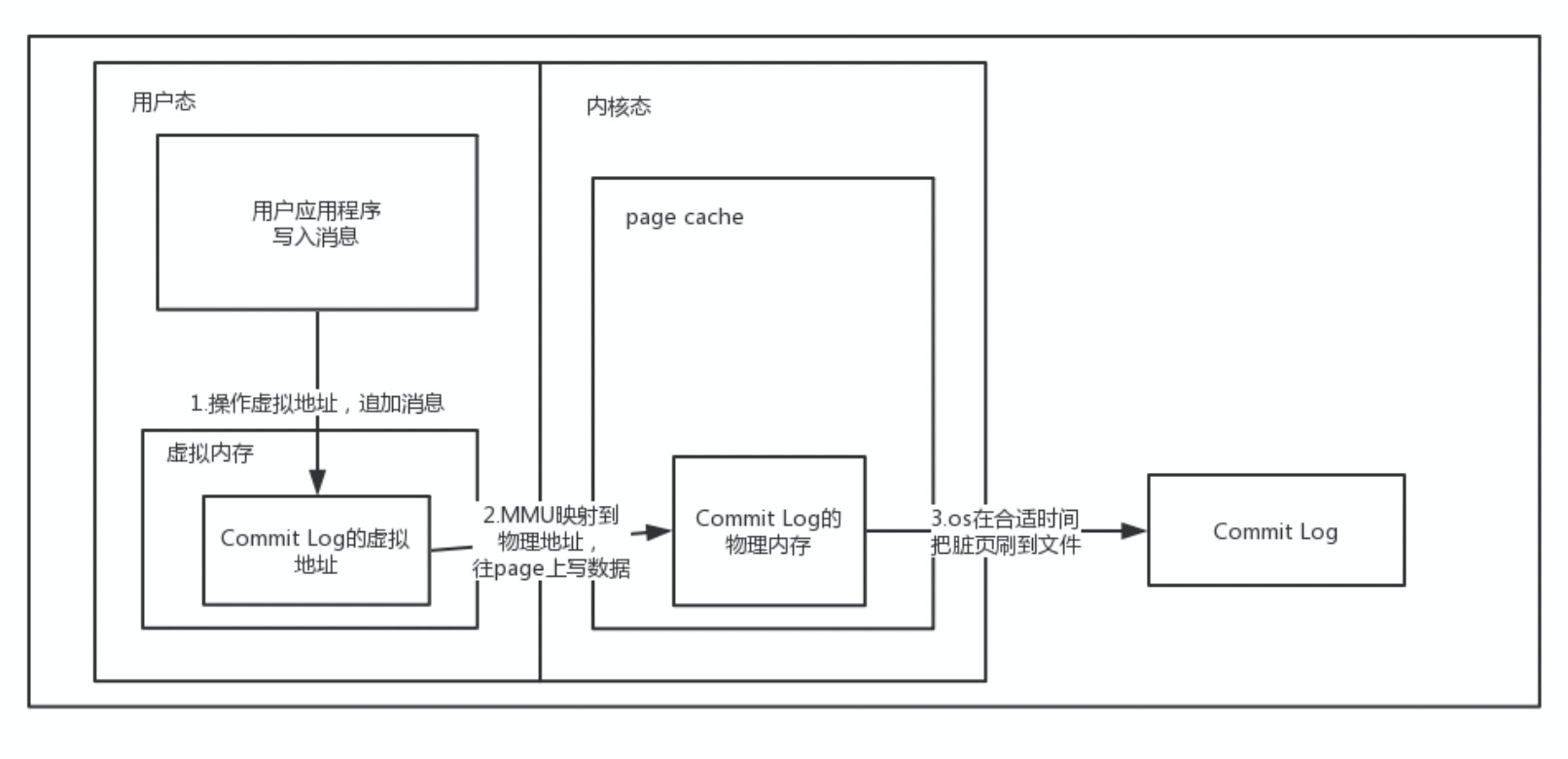
DirectByteBuffer
DirectByteBuffer的内存是在哪的?
什么是虚拟内存?
现代计算机都支持多任务处理,这样计算机同时运行多个进程,需要考虑多进程内存操作的问题。虚拟内存就是用来解决多进程内存管理的问题的。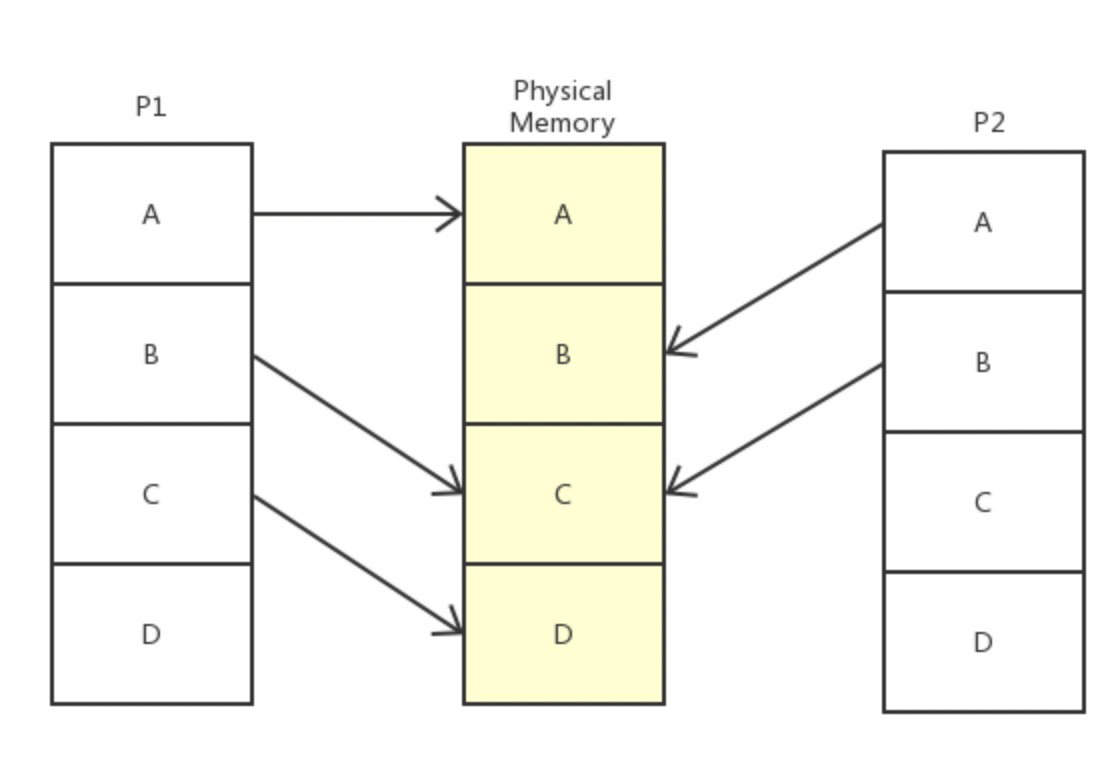
操作系统有一块物理内存(中间的部分),有两个进程(实际会更多)P1 和 P2,操作系统偷偷地分别告诉 P1 和 P2,我的整个内存都是你的,随便用,管够。可事实上呢,操作系统只是给它们画了个大饼,这些内存说是都给了 P1 和 P2,实际上只给了它们一个序号而已。只有当 P1 和 P2 真正开始使用这些内存时,系统才开始使用辗转挪移,拼凑出各个块给进程用,P2 以为自己在用 A 内存,实际上已经被系统悄悄重定向到真正的 B 去了,甚至,当 P1 和 P2 共用了 C 内存,他们也不知道。
分页和页表
前面说了虚拟内存让进程以为自己获得了整个内存,但实际只有在进程使用到的时候,操作系统才会去“临时”拼出一份内存给进程,进程以为操作的内存和实际的物理内存是需要有一个对应关系的,这个对应关系就是对照表。
首先需要知道,这个对照表的目的是建立进程“以为”操作的内存和实际物理内存的映射关系,那如果以byte建立关系,这个表需要很大很大,所以,这张对照表的对照内存单元是“页”,一般页以4K为单元,通过页的方式,可以减少对照表的大小,也因此,操作系统会对内存进行“分页”,而这个对照表就是“页表”。

若有收获,就点个赞吧
0 人点赞
